
高校云计算数据处理中虚拟机迁移 与轮转模式研究
2020-07-31 07:44任群
井冈山大学学报(自然科学版) 2020年3期
任 群
(亳州学院电子与信息工程系,安徽,亳州236800)
0 引言
云计算作为新一代的信息技术手段,在高校的信息化建设、教育信息整合等方面发挥着重要作用。随着大数据和人工智能时代的到来,高校对于数据处理、存储等需求也逐渐扩大。一方面,高校云计算中心能满足高校进行学生、教学等日常管理的需求,有利于优化教育信息化建设工作。例如,云计算技术可以改善高校财务绩效管理,降低管理成本,从而优化资源配置,提升高校综合管理水平[1]。另一方面,高校云计算中心所提供的强大计算能力和丰富存储资源能满足学生、教师进行学习科研等方面的需求。例如,医学院的教师学生可以利用云计算技术实现医学图像的检索,以满足临床和医学研究的需求[2-3]。但随着高校的发展和生源不断地扩展,各种数据信息和需求不断提高,实现高效的数据处理为高校云计算中心带来了巨大的压力。虚拟机迁移技术是云计算中心实现负载均衡、提升性能的重要手段,同时高效的任务调度策略是提高数据处理效率的关键。在海量数据的处理过程中,由于数据量过大,采用单个虚拟机进行数据处理会消耗大量时间,效率低。因此通常会采用数据并行的方法,将庞大的数据集划分成多个小规模的数据块,并将小数据块输入到虚拟机中进行数据处理。虚拟机对数据块进行处理后将处理结果传输到参数虚拟机上,参数虚拟机对所有虚拟机的结果进行汇总操作(如求平均值),并将汇总结果传输到虚拟机上,以更新虚拟机的本地结果,便于进行下一步操作。因此,为了减少对结果汇总和更新的影响,虚拟机迁移过程需要考虑虚拟机之间的数据依赖特征。国内外的研究者从不同的角度出发,开展了关于虚拟机迁移的研究,取得了大量的研究成果。例如,Fu 等人从降低能耗的角度出发,探讨虚拟机迁移问题[4-6];部分研究在进行虚拟机迁移时考虑了服务器的容量约束[7-12];还有研究者研究了动态虚拟机迁移的相关问题[13-16]。但是现有的研究并没考虑分布式数据处理过程中虚拟机之间的数据依赖特征。如果将处理同一个数据集的虚拟机放置或迁移到不同的地方,则进行结果汇总和更新时会产生较高的延迟。虚拟机之间的数据依赖性是影响虚拟机迁移性能的关键因素,数据依赖性较强的虚拟机应该被迁移至同一个或距离近的服务器中。因此,为了提高高校云计算数据处理任务的效率,特别是对计算能力要求高且数据量巨大的处理任务(如图像识别),本文结合数据处理任务所具有的数据依赖特点,设计虚拟机迁移和任务调度算法。对于任务调度策略,同步调度的方式能够确保数据处理结果的准确性,但是其调度效率并不高[17]。异步调度的方式虽然具有较高的计算效率,但并不能保证计算准确性[18]。因此,兼顾同步和异步的优点,基于round robin 轮转算法,提出了基于轮转模式的调度算法。
1 基于数据依赖的虚拟机迁移建模

2 基于启发式的虚拟机迁移算法设计
优化问题(2)是属于多背包问题,是一个NP完全问题[19]。为了提高求解问题的效率,提出一种基于数据依赖的虚拟机迁移算法(Data Aware Virtual Machine Migration Algorithm,简称为DataAware)。DataAware 是一种基于启发式的贪心算法,通过逐次地将VM 迁移至服务器,以减少每一步迁移所产生的成本。DataAware 同时考虑了虚拟机的数据依赖性和网络拓扑。
DataAware 的基本过程如算法1 所示。对于每个负载重的虚拟机,其所有汇入数据流的总通信权重iD的计算公式为:

虚拟机迁移时需要考虑网络拓扑以及服务器的负载(CPU、内存等)情况。网络拓扑和负载这两种启发式信息可以辅助虚拟机进行迁移决策,即与负载较轻的服务器距离更近的服务器将优先作为虚拟机迁移的候选目的地。加入启发式规则来改进DataAware 算法能进一步减少数据中心网络传输的流量。第一个启发式规则通过多次迭代来计算多个迁移影响因子的值。每次迭代都会尝试进一步最小化迁移影响,并且当总迁移影响的减少速率小于预定义阈值或已达到最大迭代次数时,该算法将停止。第二个启发式规则在每次迭代时,对于给定的候选目的服务器,将考虑到其他虚拟机的预期迁移影响。HeurImpact 的运算如算法2 所示,它将这些启发式信息结合到迁移影响因子的估计中。HeurImpact 算法的计算是基于依赖集合Depand(Vi)中的每个虚拟机Vj的成本。该成本取决于两个虚拟机Vi与Vj之间的通信的权重和服务器Pk之间的距离。

算法2 HeurImpact 算法 输入:虚拟机V ,服务器P 输出:迁移影响因子I 1: TC←∑ ; 2: 1I ← max max kl ij VC j TC dβ × ; 3: TD←/( )∑ ; 4: 2I ← TD / max( | |)Pβ × ; 5: I←α×1I +(1 )α- × 2I ; 6: return I ; kl P Rβ ×l i
接下来探讨基于启发式的虚拟机迁移算法(即算法1)的复杂度。对于算法1,第1、2 行的时间复杂度为O(| Φ |2),空间复杂度为0,其中O( · )表示渐进复杂度,| Φ |表示负载过重的虚拟机集合的基数;第3 行的时间复杂度为O(| Φ |log2| Φ |),空间复杂度为O(| Φ |log2| Φ |);第4 行的时间复杂度为O(1),空间复杂度为0;第5 至17 行的时间复杂度为O( | Φ ||P|),空间复杂度为O(1)。因此,当负载过重的虚拟机数量大于服务器数量时,算法1 的时间复杂度为O(| Φ |2);反之,算法1 的时间复杂度为O( | Φ ||P|)。 而 算 法 1 的 空 间 复 杂 度 则 为O(| Φ |log2| Φ |)。
3 同步更新轮转模式设计
在本节中,提出了一种基于round robin 轮转的调度算法,称为同步并行轮转(Synchronous Parallel Round robin,简称为SPR)模式,以缓解数据处理任务调度的通信瓶颈。在round robin 轮转算法中,每个任务能够获得相同的传输时间,并轮流以一定的顺序循坏地执行。Round robin 轮转算法的示例如图1 所示。每个任务分别获得相同的传输时间间隔T,并分别按顺序地在其时间间隔内进行传输。提出的轮转模式需要实现两个目标:最小化网络争用以加速任务调度以及控制参数陈旧系数以保证数据处理的效率。具体而言,为了最小化网络争用,SPR 方案强制执行连续更新之间的时间间隔,以便在整个数据处理过程中均匀地为每个任务分配时间。同时,为了最小化参数陈旧性,SPR 以固定的循环顺序进行任务调度。在分布式数据处理的过程中,SPR 能减少在数据处理结果汇总和更新过程中网络争用出现的概率,提高数据处理的效率。
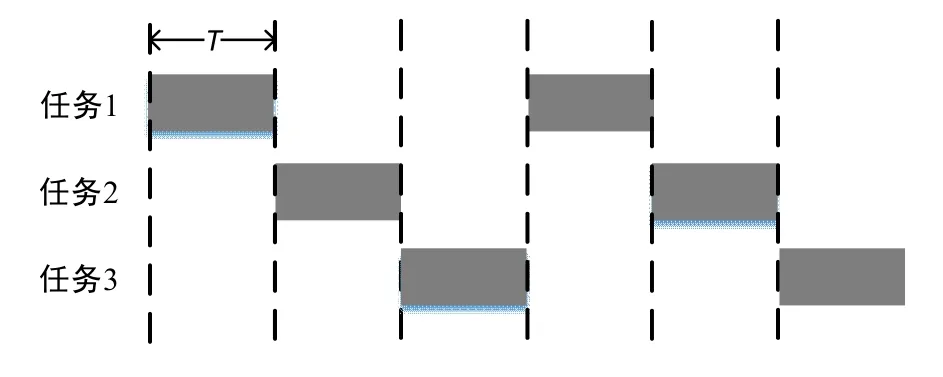
图1 Round robin 轮转算法示例 Fig.1 Illustration example of round robin algorithm
为了最大限度地减少网络争用,将最大限度地减少同时与服务器通信的竞争计算节点数量。这可以通过在整个处理过程中均匀地错开计算节点和服务器之间的通信来实现。为此,SPR 方案强制执行计算节点的两次连续数据更新之间的时间间隔。更确切地说,假设N为计算节点的数量,T为训练迭代的时间。在具有统一batch 大小的同构群集中,每个GPU 计算节点处理相同数量的数据样本,因此每个计算节点具有相同的时间T。服务器节点期望能在T时间段内接收到N次更新,并且两次连续更新之间的时间间隔是 /T N。
以三个计算节点为例,三个计算节点迭代地更新他们的梯度,并从服务器中获得最新的参数。在SPR 中,这三个计算节点与服务器单独同步,每个计算节点之间以 /3T的时间间隔轮流进行更新。相比之下,对于同步的方案,所有的计算节点会同时争用带宽,从而造成严重的网络拥塞,并使通信时间增加。
虽然强制执行上述更新间隔可以减轻通信瓶颈,但是由此产生的更新异步会影响收敛。 接下来,通过控制计算节点的更新顺序,SPR 可以最小化这种异步对收敛的负面影响。
在异步方案下,计算节点采用本地的数据进行计算,不会看到其他节点的计算结果。因此,计算节点是基于陈旧的参数进行更新的,陈旧的参数会使计算结果偏离最优[5]。特别是,当计算节点错过的更新越多,其计算结果的误差越大。因此,为了得到更精确的结果,需要尽量减少参数的陈旧性。参数陈旧性被定义为计算节点可能错过的最大更新次数。
对最快的计算节点和最慢的计算节点之间的进度差距(即迭代次数)进行限制,类似于SSP[5]。在进度差距为1 的SSP 中,用表示在计算节点i在第k次迭代产生的结果。计算节点1 最快完成第k次迭代,当只有其他计算节点均完成第k次迭代后,节点1 才可以继续进行第 1k+ 次迭代。但是,如果计算节点1 是最后一个完成第 1k+ 次迭代,此时进度差距就变成4 了(即节点1 错过了4次更新)。


4 实验评估
评估了不同大小数据中心网络中DataAware 迁移方案的有效性和扩展性。使用Matlab 2016a 软件进行数值仿真实验,将DataAware 与经典的黑盒灰盒迁移(BGVM)方案[7]、较新的基于流量的迁移(NTVMM)方案[8]、动态迁移方案(LVMM)[13]、最优(Optimal)方案[20]进行比较。实验采用由虚拟机迁移所产生网络流量的减少量作为指标来评估各个方案的效率。其中,各个方案的减少量计算方式为:将采用随机虚拟机迁移所产生的总流量分别减去上述各个方案所产生的流量。随机虚拟机迁移是指以随机的方式选择物理作为虚拟机的宿主。Optimal 方案的目标是最小化迁移流量,并满足相应的约束条件(即服务器需要满足虚拟机的对资源的需求)。Optimal 采用CPLEX 非线性求解器进行求解。虽然Optimal 能够获得最优的虚拟机迁移方案,但是在大规模的网络中,求解出最优的虚拟机迁移方案会造成巨大的开销(包括通信开销和计算开销),因此此处将Optimal 方案作为基准来评估方案的性能。BGVM 方案根据虚拟机的CPU、内存和网络输出/出入的使用情况来判断哪里出现了资源短缺,然后使用启发式算法计算迁移方案,将虚拟机迁移至资源占用最少的服务器上。NTVMM 方案根据由虚拟机迁移产生的流量来决定合适迁移方案,首先选择合适的待迁移虚拟机,然后选择能满足虚拟机资源需求的服务器,从而实现减少迁移流量的目标。LVMM 方案针对内存写入密集型的工作负载,通过识别伪装页面来减少虚拟机迁移过程中不必要的数据传输。
实验的参数设置如下。对于小型的网络拓扑,服务器和虚拟机的数量分别为10 和12。对于大规模的网络拓扑,服务器的数量为100,虚拟机的数量从20 增加至100。小型拓扑为Fat-tree 数据中心网络拓扑[21],大型的拓扑为VL2 数据中心网络拓扑[22]。每个服务器配置有4 个显存为12 GB 的NVIDIA Titan Xp 显卡,处理器为Intel Xeon Gold 6154 3.00 GHz,内存为96GB。此处以图像处理为例,模拟学生需要使用高校云计算中心所提供的计算资源进行图像处理任务。所使用的数据集为CIFAR-10[23],机器学习平台为TensorFlow,图像数据处理模型为AlexNet[24]和ResNet32[25]。虚拟机迁移的请求服从均值为0.3,方差为0.2 的正态分布,服务器的CPU 资源服从均值为0.8、方差为0.4 的正态分布,服务器的内存服从均值为0.6、方差为0.3 的正态分布。
DataAware、BGVM、NTVMM、LVMM 与Optimal 方案的对比结果,如表1 所示。DataAware算法的结果最接近最佳方案的结果;而没有考虑应用程序数据依赖性的BGVM、NTVMM、LVMM 性能并不理想。在大规模的网络拓扑中,由于Optimal所需的计算时间太长,因此仅比较DataAware、BGVM、NTVMM 和LVMM 的性能。

表1 四种方案的目标函数值对比实验数据 Table 1 Comparisonal experiment results among the objective function value of four schemes
表 2 展示了大规模网络下 DataAware、NTVMM、LVMM 和BGVM 的表现。表2 是流量减少量的累积分布函数的对比。从表中可以看出,DataAware 在大规模网络中始终优于 BGVM、LVMM 和NTVMM。
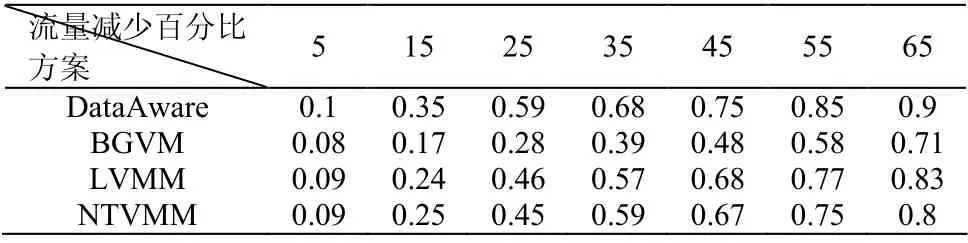
表2 流量减少的累计分布函数实验数据 Table 2 Experimental results of cumulative distribution function of reduced flow
表3 展示了不同虚拟机数量下四种算法平均的网络流量减少量。从表中可以看出, DataAware 算法能够最大限度地减少网络流量。
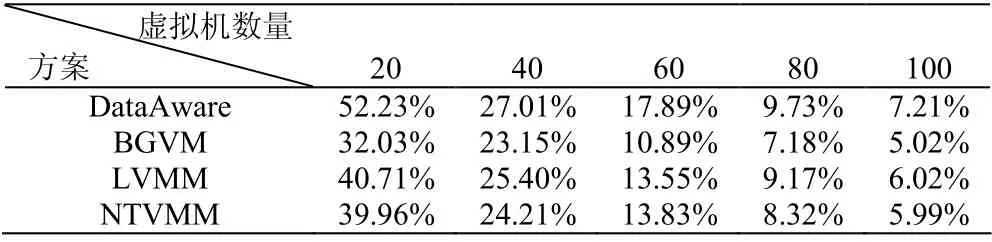
表3 虚拟机数量与流量减少的关系实验数据 Talble 3 Experimental results on the results on the relationship between the number of virtual machines and traffic reduction
5 结论
面向高校云计算中心,设计了基于数据依赖性的虚拟机迁移方案DataAware。 DataAware 在进行虚拟器迁移时不仅考虑了服务器的资源约束,还考虑了数据之间的依赖性,进一步减少了虚拟机迁移产生的额外网络流量。与此同时,为了进一步提高数据处理的性能,降低网络传输的压力,设计了同步更新轮转模式SPR。SPR 以轮转的模式控制数据的传输,在确保数据处理精度的同时提高了数据处理任务调度的效率。未来的工作将在真实的高校云计算中心中实现两种算法,在真实的应用流量下评估算法的性能。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23
数字通信世界(2020年3期)2020-04-06
制造技术与机床(2019年4期)2019-04-04
中国惯性技术学报(2019年6期)2019-03-04
电子制作(2018年23期)2018-12-26
汽车维修技师(2017年7期)2017-12-05
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
汽车维修技师(2017年10期)2017-03-17
现代防御技术(2016年1期)2016-06-01
火控雷达技术(2016年3期)2016-02-06
