
多层卷积神经网络深度学习算法可移植性分析
2020-07-28 02:40:24肖堃
哈尔滨工程大学学报 2020年3期
肖堃
(电子科技大学 计算机科学与工程学院,四川 成都 611731)
深度学习从大类上可以归入神经网络,不过在具体实现中有许多变化。深度学习的核心是特征学习,旨在通过分层网络获取分层次的特征信息,从而解决以往需要人工设计特征的重要难题[1-2]。深度学习是一个框架,包含卷积神经网络、稀疏编码器、自动编码器等多个重要算法。针对不同问题,需要选取的网络模型达到的处理效果也各不相同[3]。
由于图像特征数目过少,可能无法精确地实现分类,即欠拟合,也不会由于提取的特征数目过多,导致分类过程中过于注重某个特征出现分类错误,即过拟合。卷积神经网络不需要做大量的特征提取和特征选择工作,只需要在其训练完成后,将需要处理的问题输入,即可得到一个较好的拟合效果[4-5]。
针对当前方法在图像识别领域应用过程中容易受到物体形状、位移、尺度、光照、背景等因素的影响导致识别准确率不高,鲁棒性较低、方法可移植性较差的缺点,本文提出了基于多层卷积神经网络深度学习算法的图像识别方法,并分析了该方法在图像识别领域的可移植性。
1 多层卷积神经网络深度学习算法下的图像识别
1.1 模型训练过程
多层卷积神经网络深度学习模型是由多层感知机演变而来的,主要包括输入图像局部感受野、图像权值共享及图像时间/空间下采样3个部分,这3部分操作的最终目的是为了保证多层卷积神经网络能够学习到输入图像的更多细节特征,大大减少了神经元个数,使得输入图像具有形状、尺度及位移不变性,同时又能够减少输入图像的分辨率,降低计算复杂性,缩小搜索空间,更有利于图像识别[6-7]。
本文使用了6层卷积神经模型,包括卷积层、池化层、卷积层、池化层、下采样层、全连接层以及输出层,如图1所示。并采用3×3的卷积核进行了10次迭代。

图1 卷积神经网络结构Fig.1 Structure of convolutional neural network
训练过程包括数据训练和对应的类别标签训练。在模型初始化设置过程中,多层卷积神经网络深度学习模型的参数多为一些较小的、各部分相同的随机数,不仅能够保证模型不会进入过于饱和状态,而且还能保证模型具有较强的学习能力。多层卷积神经网络深度学习模型的训练方法与BP神经网络(BP neural network)模型的训练方法类似,主要分为2步:1)模型的前向传播,将训练图像数据中的任意一个样本(Xp,Yp)输入模型中,通过多层卷积神经网络深度学习,计算得到模型输出层的实际输出值,即最终的识别结果[8-9],具体计算公式描述为:
Op=Fn(L(F2(F1(OpW1)W2))LWn)
(1)
式中:F1、F2、LFn和W1、W2、LWn分别表示多层卷积神经网络深度学习模型中的一组滤波器及其对应权值;n为模型中包含的训练数据个数。
根据式(1)计算得到模型输出层的实际输出值Op与期望输出值Yp之间的误差大小,采用极小化规则反向传播方法调整多层卷积神经网络深度学习模型中的对应参数。具体过程如下:
1)极小化规则反向传播方法。
①前向传播。
采用平方误差代价函数计算模型输出层的实际输出值Op与期望输出值Yp之间的误差大小。假设训练的输入图像数据有N个,对应的类别标签有C个,则可得模型训练整体误差En的计算公式:
(2)
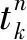
如果只考虑单个训练数据,则可得多层卷积神经网络深度学习模型中第n个训练数据的误差为:
(3)
根据上述计算可得当前模型第l层的输出值为:
Xl=f(ul)
(4)
ul=WlXl-1+b
(5)
式中:f(g)为模型输出激活函数,用于获得待识别图像特征图;Wl为模型第l层训练数据的权值矩阵;Xl-1为当前模型第l-1层的输出;b为模型偏置项。 ②模型反向传播过程中,模型中每个神经元对于误差偏置项的灵敏度计算公式:
(6)
(7)
式中:∂E/∂u为模型误差对于输入图像数据u的导数。则可得模型反向传播过程中第l层神经元偏置项灵敏度计算公式为:
δl=(Wl+1)Tδl+1⊙f(ul)
(8)
式中:δl+1为模型第l+1层神经元偏置项灵敏度;⊙表示模型中每个元素相乘。
对于误差函数,模型输出层的偏置项灵敏度与上述计算略有不同,表示为:
δl=f(ul)⊙(yn-tn)
(9)
在上述计算基础上,采用delta法则,实时更新多层卷积神经网络深度学习模型的各神经元权值,计算公式为:
(10)
(11)
式中η为模型的学习率。
2)模型中下采样层权值更新。
对于模型中的下采样层,输入的特征图数目与输出的特征图数目相等,即:
(12)
下采样层神经元偏置项灵敏度,即对输入图像做降采样处理:
(13)
式中down(·)表示下采样函数。
模型中下采样层权值更新方法与卷积层权值更新方法类似,计算公式为:
(14)
1.2 多层卷积神经网络深度学习
在上述多层卷积神经网络深度学习模型训练完成基础上,为了提高该模型在图像识别过程中的准确率,引入Fisher准则,提出了基于类内距离和类间距离的能量函数[10-11],计算公式为:
J=R+γJ1-ηJ2
(15)
式中:R为多层卷积神经网络深度学习模型的代价函数;γ为能量函数调节参数;J1为待识别图像样本之间的相似度函数;J2为待识别图像类别标签之间的相似度函数。
在充分考虑类内距离J1和类间距离能量函数J2的基础上,计算模型输出层各个输出单元的残差,使得模型权值能更加快速收敛到有利于图像识别的最优值[12],计算公式为:
(16)
(17)
式中M(i′)为待识别图像第i′类样本的均值。根据式(17)即可找到有利于图像识别的最优权值,将该权值计算结果代入式(17)中,即可获得图像识别结果,该理论分析结果证明多层卷积神经网络深度学习算法具有可移植性。
2 可移植性测试
硬件环境:3.4 GHz双核处理器,4 GB内存,M40显卡,Ubuntu14.04操作系统。
软件环境:C++编译器。
为检验多层卷积神经网络深度学习算法在图像识别领域应用的可移植性,随机选取PASCAL VOC2007数据库中的2 750张图片,6个类别标签作为测试集,如表1所示。

表1 实验测试数据集Table 1 Experimental test data set
选取识别准确率、鲁棒性、以及识别耗时3项指标作为评价指标,识别表1中的6种图像类型,测试基于多层卷积神经网络深度学习算法的图像识别方法的有效性,测试结果如表2所示。
从表2中可以看出,采用多层卷积神经网络深度学习算法识别6种不同类型图像的平均准确率为96.3%;识别6种不同类型图像的平均鲁棒性为96.8%;识别6种不同类型图像的平均耗时为17.8 ms。这是由于所提方法在训练完多层卷积神经网络深度学习模型基础上,引入Fisher准则,并提出了基于类内距离和类间距离的能量函数,使得模型权值能够更加快速收敛到有利于图像识别的最优值,大大提高了6种不同类型图像识别准确率和鲁棒性,同时加快了识别速度,平均识别耗时均达到毫秒级。假设道路上发生交通事故,所提方法具有毫秒级处理速度,有利于决策者及时作出应对措施,避免交通事故造成的经济损失和人员伤亡。
为了进一步检验所提方法的有效性和可移植性,选取比较复杂的人脸图像和容易受光照、背景、位移等影响的车辆图像作为训练样本,训练样本中喜欢、愤怒、悲伤、快乐4种表情各200张,受背景干扰、光照干扰、噪声干扰和雾霾干扰的车辆各250张,其中部分样本示例如图2和图3所示,采用所提方法识别4类人脸图像和4类不同类型干扰车辆图像,测试结果如图4和图5所示。

图2 人脸图像训练样本Fig.2 Face image training sample

图3 车辆图像训练样本Fig.3 Vehicle image training sample
分析图4和图5的实验结果可以发现,采用所提方法无论是识别具有复杂表情的人脸图像训练样本,还是具有各种干扰因素影响的车辆图像训练样本均取得了较好的成果,识别准确率和鲁棒性均较高,识别耗时较少。这是由于所提方法构建的识别模型中包括输入图像局部感受野、图像权值共享以及图像时间/空间下采样3个部分,这3部分操作保证了多层卷积神经网络能够学习到输入图像的更多细节特征,大大减少神经元个数,使得输入图像具有形状、尺度以及位移不变性,同时又能够减少输入图像的分辨率、降低计算复杂性、缩小搜索空间,更有利于识别。通过多层卷积神经网络深度学习算法对样本数据进行多次迭代训练,通过分类器输出训练后的实验样本,降低了原始数据的偏置程度,以提高实验结果的准确性。
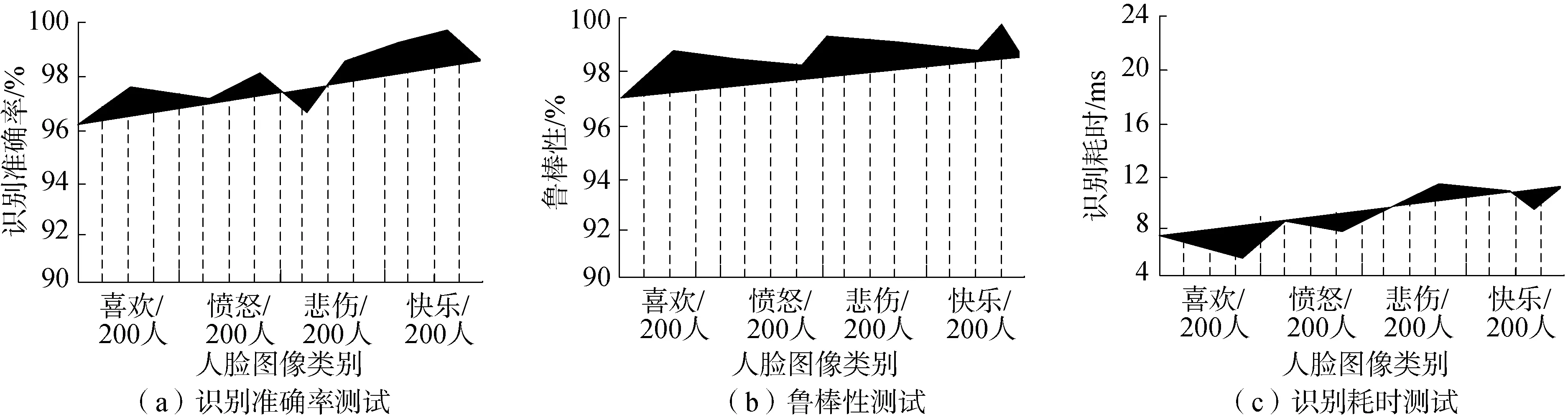
图4 人脸图像训练样本的识别结果Fig.4 Recognition results of face image training samples
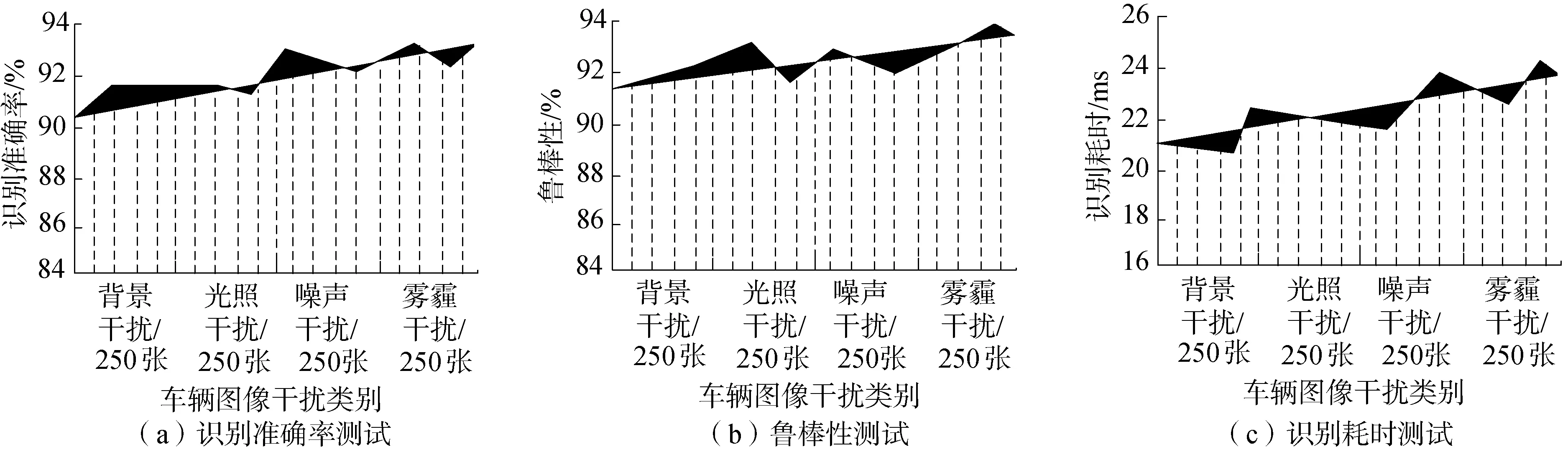
图5 车辆图像训练样本的识别结果Fig.5 Recognition results of vehicle image training samples
上述实验结果表明,多层卷积神经网络深度学习算法应用在图像识别领域具有可移植性,这与上述理论分析结果一致。
3 结论
1)本文提出了基于多层卷积神经网络深度学习算法的图像识别方法,利用模型权值共享、更新、下采样等操作对输入图像做降采样处理,有效降低了计算复杂度。
2)利用delta法则、Fisher准则以及基于类内距离和类间距离的能量约束函数实时调整多层卷积神经网络深度学习模型参数,计算模型输出层各个输出单元的残差,让模型权值能够更加快速收敛到有利于图像识别的最优值。
3)本文实现了所提出的算法,并随机选取PASCAL VOC2007数据库中的图片,从理论和实验两方面证明了所提方法的可移植性。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
科技创新与应用(2020年6期)2020-02-29 10:39:27
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
自动化学报(2017年7期)2017-04-18 13:41:02
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
