
基于改进AFSA算法的河流突发水污染溯源①
2020-07-25 01:46:54李欣欣姜秋俚魏建勋
计算机系统应用 2020年7期
李欣欣,王 宁,姜秋俚,刘 枢,魏建勋,张 楠
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(辽宁省生态环境监测中心,沈阳 110161)
4(阜新市生态环境保护服务中心,阜新 123000)
近年来,国内外突发性重金属水污染事件屡屡发生,由于其发生的突然性和危害的严重性会威胁到广大人民的人身和财产安全,给社会经济的发展带来不可估量的损失,因此国内外对此事件的关注极高,并不断地寻求解决办法[1].在我国水资源最大的特点是地域分布不均,而我国又是人口大国,缺水状况也是我国一直在解决的问题.我国有跨国界河流40多条,涉及19个主要国家[2],一旦发生严重的事件,重金属污染物不只对水环境和人体的危害极大,甚至会影响社会治安和国际友好关系.经调查分析,突发性重金属水污染的发生主要是由企业违规排放废水和工厂事故泄漏造成的.因此在自动监测站监测到河水中重金属污染物超标时,能否快速精确的定位污染源企业或工厂,对于后续采取有效措施具有现实意义.本文研究的是由河流附近企业违规排放废水导致的突发性重金属水污染事故的追踪溯源.
水动力学反演法,根据河流的水文特征选取合适的水动力学方程,再根据真实的污染物浓度监测数据、污染源的分布数据等,通过构造相关模型并利用相关方法反演求解得到污染源的排放位置、排放时间和排放质量[2].目前,主要应用了遗传算法、粒子群算法、模拟退火算法等[3,4],但存在容易得到局部最优和搜索时间较长的问题.基于此类问题,本文选用改进后的AFSA算法,算法具有更强的跳出局部极值的能力和更快的搜索能力.
1 水动力反演
重金属污染源的追踪溯源需要水动力学反演,因此需要选择合适的水动力方程进行模拟,从而得到水动力模拟库,建立相关模型,快速准确的定位重金属污染源.
1.1 重金属污染物的时空变化
在水动力学中,模拟污染物在一维河道中的迁移变化规律可以用以下公式表示:

式(1)中,C表示河流在x断面在t时刻污染物的浓度(单位是m g/L),Dx表示河流纵向的弥散系数(单位是m2/min),ux表示河流纵向平均流速(单位m2/min),K表示污染物的衰减系数(单位是s−1)[5].
本文根据实际情况研究的是瞬时点源排放重金属污染物,故假设在河流的一个断面x处投入质量为M的重金属污染物,此时污染物的衰减系数K为0,河流的纵向平均流速为ux.此时污染物与断面的河水混合,那么方程的初始条件和边界条件是:
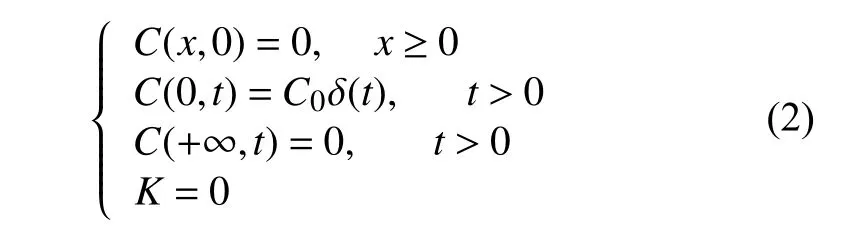
式(2)中,污染物的初始浓度为C0=M/Q,M表示瞬时投放到河流中的污染物的质量(单位是kg),Q表示单位时间内河水的流量(单位是m3/s)[5],A表示河流的断面面积(单位是m2).
通过函数 δ的特性和L aplace的变换得到式(1)在式(2)条件下的解析解,即一维河流中重金属污染物的时空变化方程:

式(3)中,C(x,t)表示污染物在下游的污染物浓度分布(单位是mg/L),x0表示污染源的位置(单位是m),t0表示污染源的排放时刻(单位是min)[5],其余同上.
通过式(3)可知,对于突发性重金属水污染的追踪溯源问题,需要确定污染源的排放位置、排放时间和排放量这3个因素.
1.2 水动力情景模拟
如果重金属水污染事故突然发生,自动监测站报警,此时已知自动监测站处的水文信息,包括监测站处河流的断面面积A、河流的纵向弥散系数Dx、河流的纵向平均流速ux以及监测站监测到的某段离散时间内污染物浓度变化数据等.记自动监测站处得到的随时间变化的污染物浓度数据为Ci(i=1,2,···,n).
根据自动监测站处的重金属污染物的污染范围信息得重金属污染源的位置范围,即根据情景,假设干流自动监测站a(xa)从未监测到污染物,而在a下游的干流自动监测站b(xb)在时刻T第一次报警,监测到了污染物,故得到污染源的排放位置范围是(xa,xb),而污染源的排放时间与自动监测站b(xb)监测到污染物的时间间隔范围是(0,tmax),其中tmax可以由以下公式表示:

通过上述过程已知污染源的位置范围和排放时间范围,由式(3)进行水动力情景模拟.为了便于情景模拟,可以将式(3)进行变形得到以下公式:

式(5)中,C(x,t)表示污染物在自动监测站a(xa)下游的污染物浓度分布,单位是g /L;x表示污染源距离自动监测站b(xb)的距离长度,单位是m;t表示污染源在自动监测站b(xb)监 测到污染物时刻前t分钟排放的污染物,单位是min,其余同上.
在位置和时间的范围内进行突发性重金属污染源的情景模拟.假设在重金属污染源的参数是[x′,t′,M′],代入式(5)得到与自动监测站b(xb)相同的一段离散时间内一系列的污染物的浓度变化数据,记为Ci′(i=1,2,···,n).
2 溯源模型建立
重金属污染源的追踪溯源需要位置、时间和质量3个参数,若将重金属污染源追踪溯源问题的3个参数作为一个整体未知参量进行求解,需要构造复杂的模型,模型的复杂会出现溯源时间过长,效率比较低等问题,故不能快速准确地找到污染源.因而本文构建两个模型进行重金属污染物的溯源,将位置和时间这两个参数作为一个整体未知参量建立时空溯源模型,将质量作为一个未知参量建立污染物排放量模型.
2.1 时空溯源模型
假定重金属污染物的排放质量是M′,将上述的自动监测站的离散时间的重金属污染物浓度变化序列值Ci(i=1,2,···,n)与水文情景模拟得到位置和时间范围内一系列的在相同离散时间内的重金属污染物浓度变化序列值Ci′(i=1,2,···,n)进行拟合度分析,利用相关系数R来判断真实值与模拟值的相关性.
在时空溯源模型中,未知参数量是位置和时间,质量设为M′.故若情景模拟的重金属污染源的位置和时间极为接近于真实重金属污染源的位置和排放时间那么相关系数R的值也极为接近1[6].根据相关系数R的值从大到小排列,R越大越大代表是重金属污染源的可能性越大,排序越靠前.相关系数的公式如下:
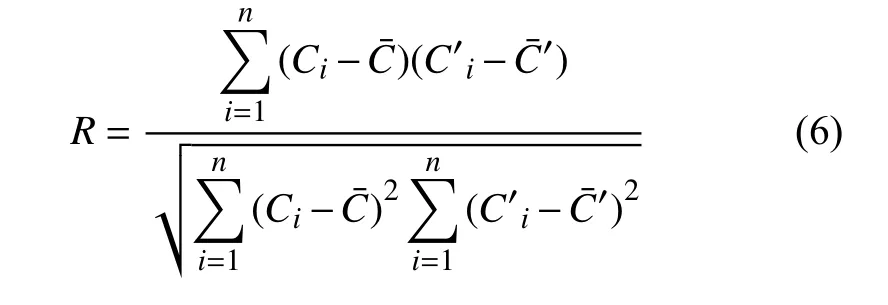

式中,Ci表示离散时间内时刻t的污染物浓度,C表示离散时间内污染物浓度的平均值,Ci′表示情景模拟的离散时间内时刻t的污染物浓度,表示情景模拟的离散时间内污染物浓度的平均值.
根据相关系数R存在最大值的性质,为了从一系列的[x′,t′,Ci′] (i=1,2,···,n)中筛选出准确的结果(x′,t′),故构建以下目标函数:

函数的约束条件为:
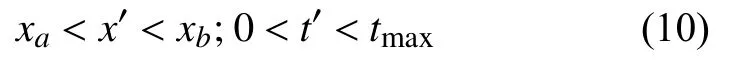
由式(4)~式(10)构成了时空溯源模型,通过时空溯源模型得到重金属污染源的位置和排放时间,再通过构建污染物排放量模型.
2.2 污染物排放量模型
通过时空溯源模型,重金属污染源的排放位置和排放时间已经确定,即可在此模型中作为已知条件,此时重金属污染物溯源的未知参数只有污染源排放污染物的质量.故由式(11)可以大致确定源强度范围.
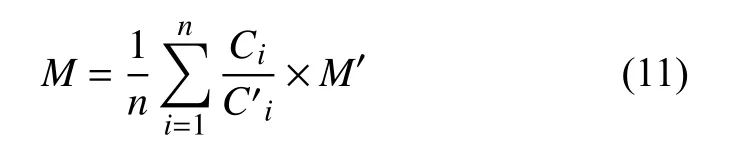
式中,M表示所求重金属污染物的质量(单位是g),表示上述过程中假设的重金属污染物的质量(单位是g)[5],其余同上.
为了确定污染源排放该重金属的总量,通过构建以下函数求最小值:
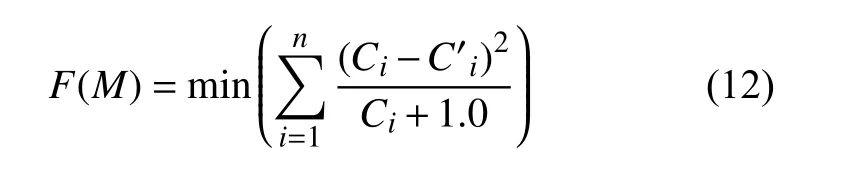
函数的约束条件为:

为了方便求解,同时空溯源模型一样将目标函数变为求最大值,目标函数的公式为:
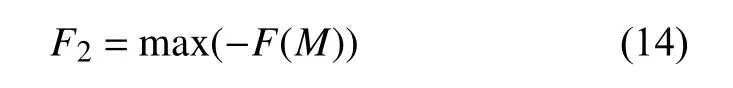
由式(11)~式(14)构成了污染物排放量模型,通过模型得到重金属污染源的排放量.
3 溯源模型求解
在上述过程中,已经把突发性水污染溯源的两个模型转化成了关于两个求最值的优化模型,本文选用改进后的AFSA算法进行模型求解.
改进的AFSA 求解时空溯源模型时,选取F=F1作为适应度目标函数,人工鱼个体状态是X=(x,t),其当前所在位置的食物浓度函数用Y=F(X)表示[7],求最大值.人工鱼群算法求解污染物排放量模型时,选取F=F2作为适应度目标函数,人工鱼个体状态是X=M,其当前所在位置的食物浓度函数用Y=F(X)表示[7],求最大值.
3.1 改进步长和视野
步长和视野范围是算法的关键参数,步长和视野范围是算法的关键参数,若希望算法的全局搜索能力更强并且收敛迅速,则需要设置较大的视野;若希望算法的局部搜索能力较强,则需要设置较小的视野.步长大则收敛快,但是步长过大会发生震荡现象,步长小则收敛慢但是求解精度高[8].故本文参考文献[9]通过式(15)动态调整视野Visual和步长Step增强算法的搜索能力和精确度[9]:
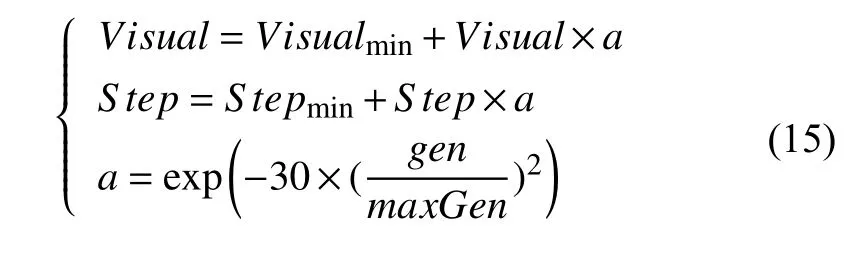
式中,Visual=xmax/4,S tep=visual/8,Visualmin=0.001、S tepmin=0.0002分别为人工鱼的视野、步长的最小值,gen表示当前的迭代次数,maxGen表示最大的迭代次数,xmax表示搜索范围的最大值[9].
3.2 改进觅食行为
在满足前进条件的前提下,只有当随机选择的状态比当前的状态好,原觅食行为才会选择向该方向移动一步,这样存在搜索速度慢的问题.故为了加快搜索速度,当前人工鱼i的状态为Xi,通过式(16)随机得到状态Xj,如果满足前进条件Yj>Yi,则将当前人工鱼i直接移动到Xj状态,如果不满足前进条件则重新按照式(16)随机得到状态Xj.反之,当达到try_number次后仍然不满足前进条件,则通过式(17)随机生成状态Xj,将当前人工鱼i直接移动到Xj状态.
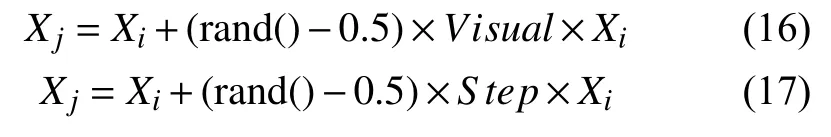
式中,i,j=1,2,···,fishnum,rand()为[0,1]之间的随机数.
3.3 改进的AFSA算法流程
图1所示的算法流程中初始化设置算法参数包括:确定人工鱼群规模fishnum、迭代次数gen、最大迭代次数maxGen、拥挤度因子δ、尝试次数try_number、个体间的距离di,j[8].
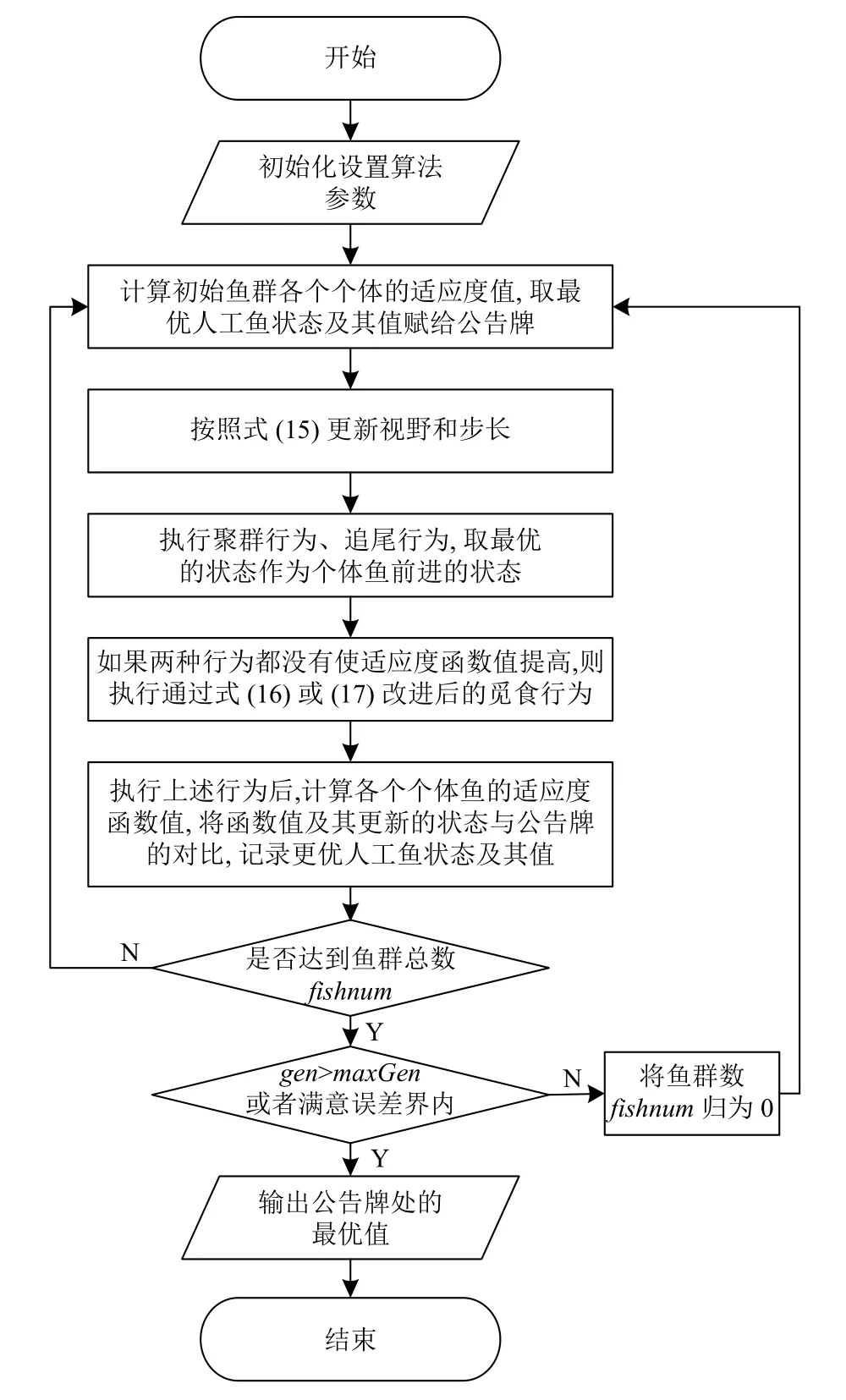
图1 改进的AFSA算法流程图
4 污染源的排查
通过调查分析,根据实际情况,通过上述模型得到污染源在一维河道的位置,排放时间以及排放量后筛选得到的涉铜企业名单,当企业距离河流越近并且企业的信誉越低,则是污染源企业的可能性越高.故用L表示企业到纳污河流的距离,用E表示企业的信誉度,其等级分为优/良(用0表示),差(用1表示).通加入权值后得到公式:
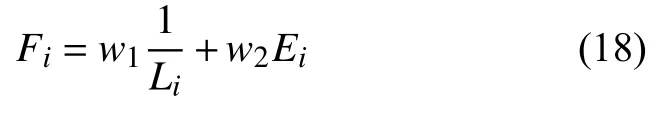
式中,w1=0.9975、w2=0.0025,Li表示企业i到河流的距离,Ei表示企业i的信誉度,Fi表示加入权值后企业i为污染源的函数值.
当上述企业名单有k个企业时,通过概率计算,将企业名单根据概率从大到小排列,从而得到相关工作人员的排查名单.概率计算公式为:
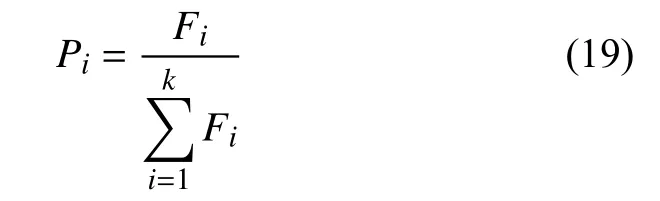
5 算法验证
本文研究的是瞬时点源突然超标排放重金属铜导致的河流重金属水污染,并利用已有的GIS进行结果展示[10].
5.1 背景
以自动监测站b处铜突发污染超标报警为例,2018年的12月16日上午11点,自动监测站b第一次铜超标报警,此时监测值为7.5 mg/L.而在同一时刻图2(黑点代表企业,三角形代表涉铜企业)标注的正常运行的自动监测站a、自动监测站c以及其他在图2中未标注的正常运行的自动监测站并没有发生铜突发污染超标报警,故污染源存在于自动监测站a和自动监测站b之间.将该时间作为初始监测时间,然后每间隔1小时监测一次,监测到下午14点结束.自动监测站b处的水文信息如表1所示.

图2 河流地图

表1 自动监测站b的水文信息
5.2 溯源结果
通过上述两个模型得到运行结果图3和图4.图3中的寻优过程图中圆的圆心坐标数据为表2中溯源结果的污染源位置和污染源排放时间,图4中的寻优过程图中圆的圆心坐标数据为表2中溯源结果的污染源排放量.表2中,污染源位置即河流中污染源的位置距离自动监测站b的距离,污染源排放时间即污染源排放时刻与自动监测站b第一次报警的时刻的时间差,污染源排放量即污染源的排放质量.
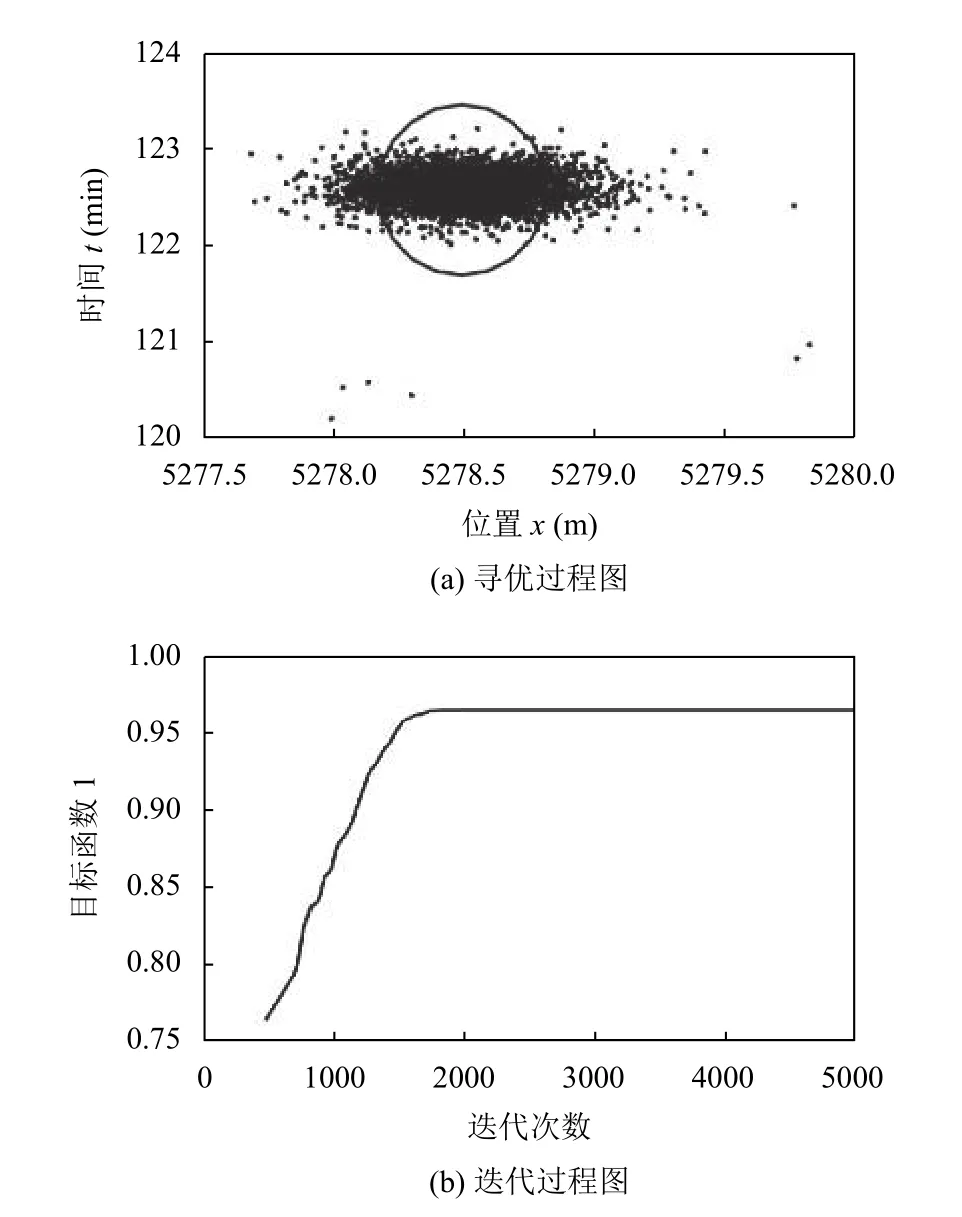
图3 目标函数1
5.3 溯源企业分析
通过上述结果可以看出上述两个模型能够快速准确地得到污染源的3个参数,之后根据这3个参数并利用GIS 地图得到图5.其中标注圆的半径通过式(20)确定.

其中,Li代表第i个涉铜企业到其纳污河流的距离(i=1,2,···,n).
图5中红色圆内涉铜污染源企业有6个,表明这6个企业可能为污染源企业,再由式(18)和式(19)计算这6个企业为污染源的概率并按照概率从小到大排列得到概率排查清单,即表3.

图4 目标函数2
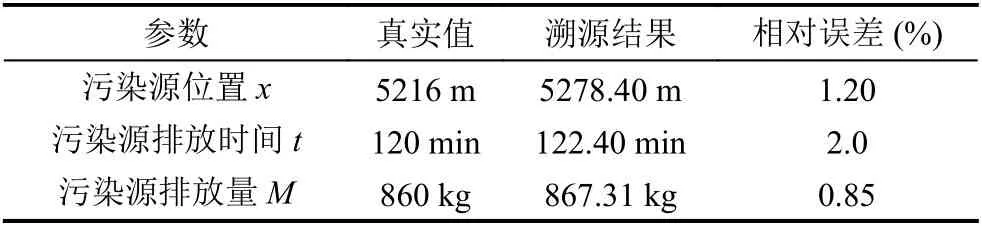
表2 溯源结果分析

图5 溯源后的河流地图

表3 概率排查清单(单位:%)
当时发生重金属铜污染后,相关工作人员通过走访排查自动监测站b的上游相关涉铜企业进行污染源企业的追踪溯源,最终确定为企业6导致此次河流重金属铜污染事故的发生,与表3中概率最大的企业一致.
6 结论
通过实验发现概率最高的企业6就是人工排查得到的污染源企业.目前已有的研究工作主要是求得污染源的排放位置,排放时间以及污染物排放量这3个参数后再通过人工排查确定污染源企业,没有明确的人工排查顺序,故排查过程耗时耗力,不能及时的找到污染源企业从而采取相应的措施处理问题.实际上这3个参数值总因为各种因素导致存在相应的误差,本文提出的方法能在水文信息较少的情况下能更加快速准确地求得污染源的3个参数,并且考虑到由于各种因素导致这3个参数的误差无法完全排除,构造相关公式并考虑到企业信誉度因素,最终为相关工作人员提供排查的概率清单,进而快速准确地找到污染源企业,及时采取措施解决突发性重金属铜水污染问题,保护好我们的水环境.
猜你喜欢
环境影响评价(2020年2期)2020-12-02 01:23:24
小太阳画报(2019年4期)2019-06-11 10:29:48
成都信息工程大学学报(2019年1期)2019-05-20 09:14:50
四川环境(2019年6期)2019-03-04 09:48:54
散文诗(2018年20期)2018-05-06 08:03:44
环境保护与循环经济(2017年4期)2018-01-22 03:27:18
中国资源综合利用(2017年4期)2018-01-22 02:46:45
中学生数理化·八年级物理人教版(2017年12期)2017-04-18 12:59:46
中国环境监察(2016年8期)2016-10-23 05:41:42
少儿科学周刊·少年版(2015年11期)2015-12-17 20:49:15
