
基于随机森林的溢漏实时判断方法研究
2020-07-21 01:56:50史肖燕周英操赵莉萍蒋宏伟
钻采工艺 2020年1期
史肖燕, 周英操, 赵莉萍, 蒋宏伟
(中国石油集团工程技术研究院有限公司)
井漏和溢流是影响钻井施工安全最为常见的两种井下复杂事故。井漏和溢流不仅会带来严重的储层损害,增加勘探开发投入成本,造成油气开发效率低下,一旦控制不力,还会诱发卡钻、井塌、井喷等重大恶性事故,造成损失及负面社会影响。因此,钻井过程中溢流、漏失的实时识别判断具有重要意义。
目前,国内外在溢流、漏失监测方面展开了较多研究,形成的技术主要有:井口监测技术、井下随钻监测技术和人工智能监测技术。井口监测技术成熟,能比较准确地监测出溢流和漏失,但这种方法的监测结果存在滞后性,不能很好地解决高压气井、深水钻井等特殊环境下的井下溢流、漏失监测问题。井下随钻监测方法能够快速、早期监测到溢流和漏失,但成本较高,并且随钻测量仪器存在失效的风险。随着信息技术和人工智能技术快速发展,国内外研究人员把人工智能技术应用到溢流、漏失的监测中,监测结果更为准确,但这些人工智能的方法普遍存在着建模较为复杂,推广较难的问题。
近年来,以数据为驱动的机器学习算法在社会各领域得到了广泛的应用,其中最重要的算法之一随机森林具有建模较为简单、调节参数少、预测准确率高和强鲁棒性的特点。本文采用随机森林的方法对钻井实时测量数据进行建模,来对溢流、漏失进行实时识别判断。
一、随机森林方法
随机森林由Breiman L在2001年提出,是一个可处理高维度与非线性样本的分类器组合模型。大量的理论和实证研究都证明了随机森林具有很高的预测准确率,对异常值和噪声具有很好的容忍度,并且不容易出现过拟合。因此,自其被提出以来,在医学、生物信息、管理学等领域得到了广泛应用。随机森林分类的基本思想[1-2]:首先,利用自助法(Bootstrap)抽样技术从原始训练集抽取k个样本集;然后,对k个样本集分别建立k个决策树模型,得到k种分类结果;最后,对每个新记录根据k种分类结果进行投票表决决定其最终分类。
二、基于随机森林的溢漏实时判断方法
在钻井过程中,当有溢流、漏失发生时,在钻井测量参数上会有所体现;例如溢流发生时,进出口流量之差会增加,立压降低,大钩负载缓增;漏失发生时,进出口流量之差减少,立管压力降低,井底环压降低;由此可见,钻井测量参数与溢流、漏失存在着相关关系。可把溢流、漏失的识别问题建模成以钻井测量参数为自变量,是否发生溢流、漏失为结果变量的分类模型。本文选用随机森林方法对溢流、漏失的实时识别进行分类建模,通过大量历史数据对随机森林进行训练,并对新的实时输入数据作出是否发生溢流、漏失的分类。
基于随机森林的溢流、漏失实时判断方法的流程如图1所示。

图1 基于随机森林的溢流、漏失实时判断方法的流程图
1. 生成原始数据集
随机森林是有监督的机器学习算法,用于训练算法的样本数据需要有输入变量和结果变量。在本文的模型中,输入变量即以时间为索引的钻井测量参数,结果变量为是否发生溢流或漏失。因为溢流、漏失的信息一般以文本的方式记录在井史数据中,因此需要对文本数据进行自动识别,并根据文本中溢流、漏失事故的发生和持续时间,生成以时间为索引的溢流、漏失数据;合并以时间为索引的钻井测量参数和溢流、漏失数据,即可生成用于随机森林算法的原始数据集。生成的原始数据集是以时间为索引的多维特征数据和分类结果,特征包括:入口流量、出口流量、PWD环空压力、PWD环空温度、大钩载荷、井深、钻头深度、总池体积、立管压力、转速、钻压、钻井液出口密度和钻井液出口温度;数据的分类结果为离散值:0代表无事故发生,1代表有溢流发生,2代表有漏失发生。
2. 数据预处理
本文的原始数据集是以时间先后为顺序排列的数据集,很难直接用于溢流、漏失实时识别的建模,为了让数据适合于随机森林的建模,需要对数据进行预处理。
首先,溢流、漏失的发生导致原始数据集中各特征数据发生变化,因此各特征数据的相对变化量能更好的应用于随机森林中决策树的创建,而且使用特征数据的相对变化量,可综合多口井的数据,形成更大数据量的历史数据集。对于某一特征数据,相对变化量的计算公式为:
(1)
式中:A(Ti)—特征数据列A在Ti时间点的值;A(Ti-1)—特征数据列A在Ti-1时间点的值。
其次,在不同的工况下,当溢流和漏失发生时,各特征数据的变化情况不同,因此根据原始数据集中的数据,对工况进行自动识别,有助于下一步决策树的生成。本文自动识别的工况包括:钻进、起钻、下钻和其它(包括接单跟,卸单根和钻井液循环等)。钻井工况计算方法为:
在时间Ti,若HDEP(Ti)=BDEP(Ti),HDEP(Ti)> HDEP(Ti-1),则钻井状态DS(Ti)为钻进。
在时间Ti,若HDEP(Ti)>BDEP(Ti),BDEP(Ti)>BDEP(Ti-1),则钻井状态DS(Ti)为下钻。
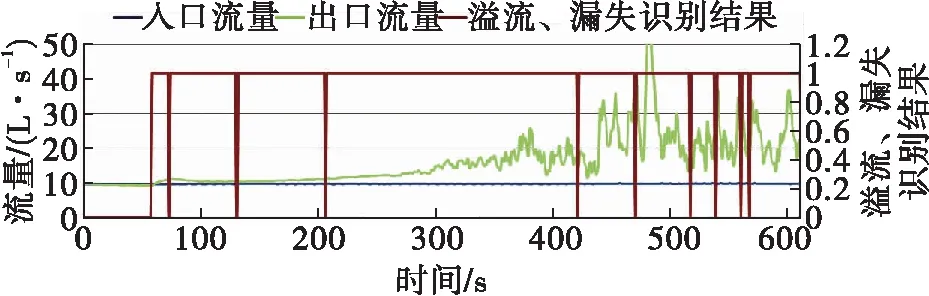
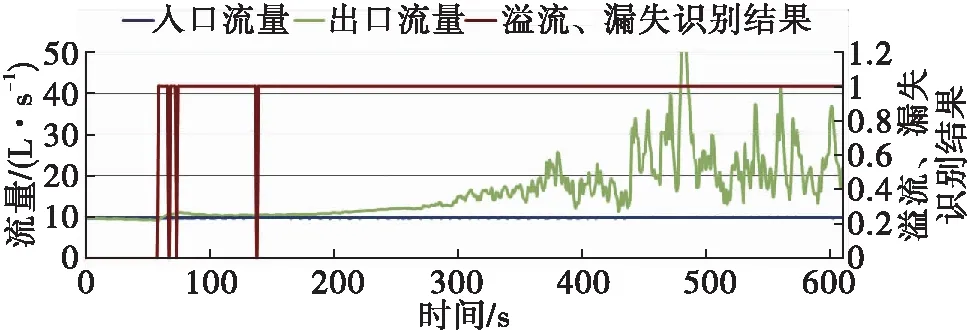
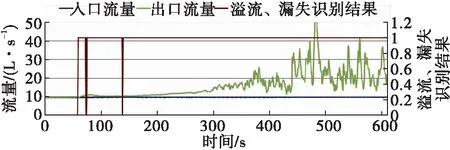
在时间Ti,若HDEP(Ti)>BDEP(Ti),BDEP(Ti) 否则, 钻井状态为其它。 其中,HDEP(Ti)为Ti时刻的井深,HDEP(Ti-1)为Ti-1时刻的井深,BDEP(Ti)为Ti时刻的钻头深度,BDEP(Ti-1)为Ti-1时刻的钻头深度。 再次,把相关特征数据进行简单的计算,能与溢流、漏失的发生建立更直接的关系,例如出口流量和入口流量之差,可更直接反应是否有溢流、漏失发生。因此把出入口流量差加入到输入特征集中。 对于预处理之后的溢流、漏失数据集,随机森林采用Bootstrap重采样方法,生成k个用于决策树生成的样本集,k由所需建立的决策树的数量确定。随机森林中决策树的数量对预测结果有重要影响,本文将在现场实例中进行讨论。Bootstrap方法的基本思想为[3]:从容量为N的原始样本集中进行有放回的重复采样,采样样本的容量也为N,每个观测对象被抽到的概率为1/N,每次采样构成的子样本集称为Bootstrap样本集。 对于上述步骤生成的每一个样本集,随机森林采用CART决策树来对训练数据进行分类。CART算法采用一种二分递归分割的技术,总是将当前样本集分割为两个子样本集,使得生成的决策树的每个非叶节点都只有两个分支,因此CART算法生成的决策树是结构简洁的二叉树,可用于分类和回归任务。在创建分类树递归过程中,CART每次都选择当前数据集中具有最小gini信息增益的特征作为节点划分决策树。gini指数是一种不等性度量,可用来度量任何不均匀分布,是介于0~1之间的数,0代表完全相等,1代表完全不想等。分类度量时,总体内包含的类别越杂乱,gini指数就越大。gini指数的计算公式为: (2) 式中:pj—类别j在样本T中出现的频率; nj—样本T中类别j的个数。 在每个节点分裂时,计算不同特征和不同阈值相对应的gini信息增益,选择最小的gini指数对应的特征和阈值,对特征空间进行二元分裂。对节点进行二元分裂时,gini信息增益的计算公式为: (3) 式中:s1—T1中样本的个数;s2—T2中样本的个数。 不同于传统的CART树,随机森林在CART树的创建过程中,采用了随机特征的选择,即在每一个结点随机选择一小组输入变量(m个特征,m<总待选特征个数)进行分割,如图2所示。 图2 决策树创建过程中的特征选择 对于新的输入样本,随机森林根据CART算法所生成的k棵决策树的投票结果,判断是否有溢流、漏失发生。 本文以塔里木油田的某复杂井为例,用基于随机森林的智能方法对溢流、漏失进行实时识别。用于随机森林算法训练的历史数据从该井的邻井数据中获取,训练数据集包括正常钻井样本,溢流样本和漏失样本。 对该井的钻井测量参数进行实时监测的开始时间为2018年2月11日21∶08,如图3所示。从21∶09开始,该井停止钻进,并打开泵进行循环。由图3可见从21∶09开始,出口流量大于入口流量;总池体积从21∶19分开始明显增加,到21∶25达到峰值,为147.9 m3,增量为0.9 m3,可判断有溢流发生。 图3 钻井实时测量参数 图4为用随机森林的方法对溢流进行实时识别的结果,0代表正常工况,1代表溢流工况,2代表漏失工况。由图4可见,系统自动在溢流发生初期(21∶09)即对溢流进行了自动识别,这比用传统的总池体积增加法来判断溢流提早了16 min,实现了溢流监测的及时性;在21∶24,出口流量等于入口流量,溢流结束,系统亦进行了自动识别,识别的结果为正常工况。 图4 基于随机森林的溢流实时识别 从2018年2月16日00∶16开始,对该井的钻井测量参数进行实时监测,如图5所示。从00∶16开始,该井边钻边漏,出口流量小于入口流量。从00∶35开始,总池体积明显减少,到00∶39,总池体积从原来的129.3 m3降低到128.1 m3,减少了1.2 m3,可判断漏失发生。 图6为用随机森林的方法对漏失进行实时识别的结果。由图6可见,系统自动在溢流发生初期(00∶16)即对漏失进行了自动识别,这比用传统的总池体积减少法来判断漏失提早了23 min,实现了漏失监测的及时性。 图5 钻井实时测量参数 图6 基于随机森林的漏失实时识别 用随机森林的方法建模时,一个重要参数为决策树的数量,此参数的选择对于随机森林的预测准确性有重要影响。因此本文对此参数的选择进行讨论。 图7~图10展示了用不同的决策树数量,对发生在2月11日20∶17开始的溢流进行识别的结果。由图7可见,当决策树数量为10时,溢流的识别结果里有较多的错误,随着决策树数量的增加,溢流识别结果越来越准确,到决策树数量为100时,识别结果趋于稳定。因此选用100为决策树数量可得到较为准确的预测结果。 图7 决策树数量为10时的溢流识别图 图8 决策树数量为20时的溢流识别图 本文还用随机森林的方法对用于溢流漏失识别的14个输入特征的重要性进行分析,其中,流入流出差对于溢流漏失识别的重要性最高,这符合当前主要的溢流、漏失识别的判断依据;重要程度接近于0的钻压变化量、转速变化量、泵冲变化量和出口温度变化量可从用于随机森林建模的输入特征中剔除,以提高计算速度。 图9 决策树数量为50时的溢流识别图 图10 决策树数量为100时的溢流识别图 (1)随机森林作为新兴起的集成学习算法,具有预测准确度高、对噪声的容忍度大,计算速度快等优点,这些优点使其适用于溢流、漏失的实时识别判断。 (2)现场实例显示,通过对钻井实时测量数据的合理预处理,结合随机森林的方法,溢流、漏失可在早期被准确识别。 (3)由于随机森林可以处理大量的特征数据(输入数据),并可在决定类别时,评估特征的重要性;本文利用随机森林对初选的特征进行重要性分析,结果表明钻井液流入流出差对于溢流、漏失的判断具有重要影响。3. 生成子数据集
4. 用CART树进行分类
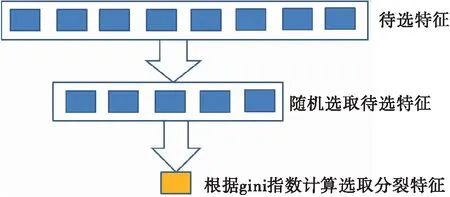
5. 溢流、漏失识别
三、现场实例
1. 实验数据
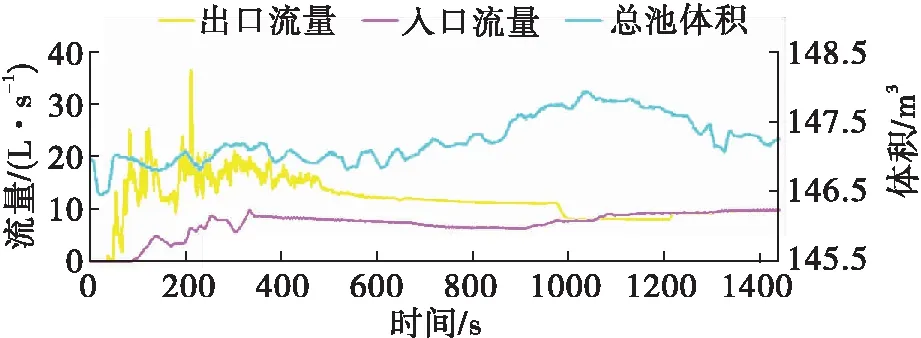
2. 溢流识别

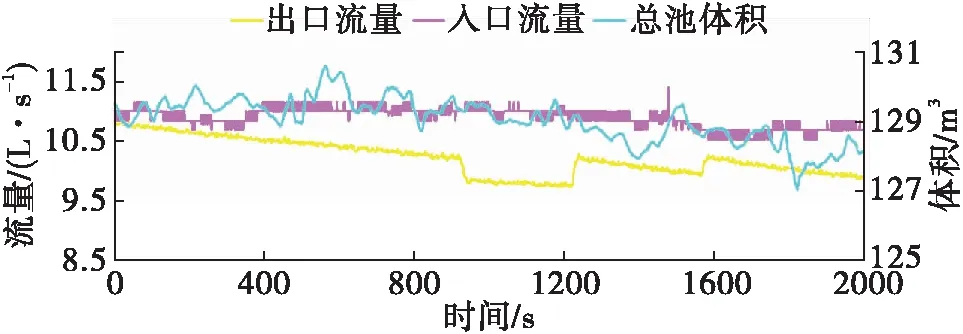
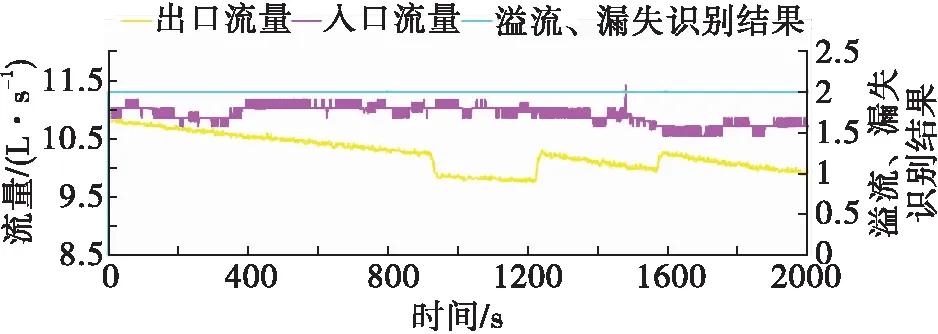
3. 漏失识别
4. 建模参数的选择
5. 变量的重要性分析

四、结论
猜你喜欢
海洋石油(2021年3期)2021-11-05 07:42:54
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
小哥白尼(趣味科学)(2019年5期)2019-08-27 02:46:54
电子制作(2018年16期)2018-09-26 03:27:06
录井工程(2017年3期)2018-01-22 08:40:07
西南石油大学学报(自然科学版)(2016年2期)2016-12-01 06:01:48
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
西南石油大学学报(自然科学版)(2015年5期)2015-04-16 05:12:31
西南石油大学学报(自然科学版)(2015年5期)2015-04-16 05:12:28
天然气与石油(2015年2期)2015-02-28 17:01:12
