
基于机器学习的冠心病诊断支持模型构建与实现
2020-07-20 05:57高政源朱付保
无线互联科技 2020年9期
姚 妮,高政源,王 强,朱付保
(郑州轻工业大学 计算机与通信工程学院,河南 郑州 450000)
随着当今社会的飞速发展,人们生活水平不断提高,生活方式逐渐改变,心血管疾病数量也不断增加。根据世界卫生组织的统计数据,心血管疾病已逐渐成为影响人们身体健康的“头号杀手”,而其中的冠心病更是倍受人们关注。世界卫生组织将冠心病分为5大类[1],分别是心绞痛、无症状心肌缺血(隐匿性冠心病)、缺血性心力衰竭(缺血性心脏病)、心机梗死和猝死。
在冠心病的诊断过程中,不仅需要病人的基本信息,还需要病人的家族病史、血压、临床症状、心肌灌注显影图等大量复杂的临床变量。由于数据量庞大,人工诊断操作对于心脏科医生的水平要求非常高,有时甚至需要多名专家联合会诊,也为冠心病多变量相互作用的研究提供了新的机遇。
在当前大数据的挖掘处理过程中,机器学习算法[2]发挥着重要的作用,其中逻辑回归是一种广义的线性回归模型,决策树是一种自上而下的树形分类结构,随机森林是利用多棵决策树形成的集成分类器。文章首先对通过心肌灌注显像(Myocardial Perfusion Imaging,MPI)所得到的患者心脏参数及医生诊断的临床数据进行筛选、填充和离散化,形成数据集,然后通过信息增益特征评估方法,按特征对于目标变量“双源CT积分”的重要程度进行排序,再利用机器学习中的逻辑回归、决策树、随机森林3种机器学习算法,使用最优的特征量构建分类识别模型,并使用测试集中的测试数据进行预测性能评估,根据评估结果形成最优识别模型。
1 基于机器学习的特征选择及建模
1.1 机器学习环境WEKA
怀卡托智能分析环境(Waikato Environment for Knowledge Analysis,WEKA)[4]是一款基于Java的开源机器学习软件,不仅包括对数据预处理、分类、回归、聚类、关联规则分析的函数库,而且是个公开、免费、非商业化的数据挖掘工作平台。
1.2 特征选择算法信息增益
信息增益(Information Gain)[5]是一种常用的特征选择方法,依据各个特征,根据整个分类系统带来信息量的多少来显示特征的重要性。这个信息量即特征重要性的直观体现就是信息熵,简称熵,其具体的计算过程如式(1)所示:

如果有变量X,其存在的类别数有n种,且每一种类别取到的概率值为Pi,那么X的熵就定义为:
使用信息增益的方法,可以对特征对于整个分类系统的贡献做出排序,并针对不同的算法逐个删除排名最后的特征属性,观察模型准确率的变化,并进行记录,以得到使相应算法准确率最高的特征序列。
1.3 机器学习建模
文章使用信息增益算法对患者特征重要性进行排序,使用逻辑回归、决策树、随机森林3种算法对诊断模型进行对比建模。
1.3.1 逻辑回归
逻辑回归[6]是一种广义的线性回归分析模型,常用于大量数据的挖掘、复杂疾病的诊断以及股价预测、经济走势等方面。逻辑回归算法的基本原理:针对某些分类问题或者是回归问题来建立合适的代价函数,通过优化的方法迭代求解得出最优的模型参数,最后对模型的好坏进行验证操作。
1.3.2 决策树
决策树[7]是用来对数据集实例进行分类的一种树型结构,从数据的特征(或属性)出发,以特征为基础,对不同类别进行划分。决策树算法规则可以看作为if-then规则的集合,同时也可以认为是定义在特征空间与类空间上的条件概率分布。决策树算法学习的本质就是根据已有的训练数据集总结、归纳出一组较好的分类规则。
1.3.3 随机森林
随机森林[8]是指利用多棵树对数据集样本进行训练和预测的一种分类器,是一个包含多个决策树的分类器,使用机器学习中常见的bagging思想,使用组成森林的每棵数的输出类别的投票结果决定该分类器的输出类别。
2 特征选择
2.1 研究人群及数据预处理
选取某医院完整冠心病患者数据621例,其中,训练数据集521例,测试集100例,测试集与训练集独立同分布。所有研究对象资料完整,包含MPI[9]参数左心腔短暂性缺血性扩张(Transient Ischemic Dilation,TID)、肺/心放射性比值(Lung/Heart Ratio,LHR)、左心室负荷总积分(Summed Stress Score,SSS)等共17个,医生临床诊断信息性别(Gender)、年龄(Age)、高血压(Hypertension)、缓解方式(Mitigation mode)等共19个。
经过在医生指导下的筛选、填充及离散化处理,数据集的分布状况如表1所示。
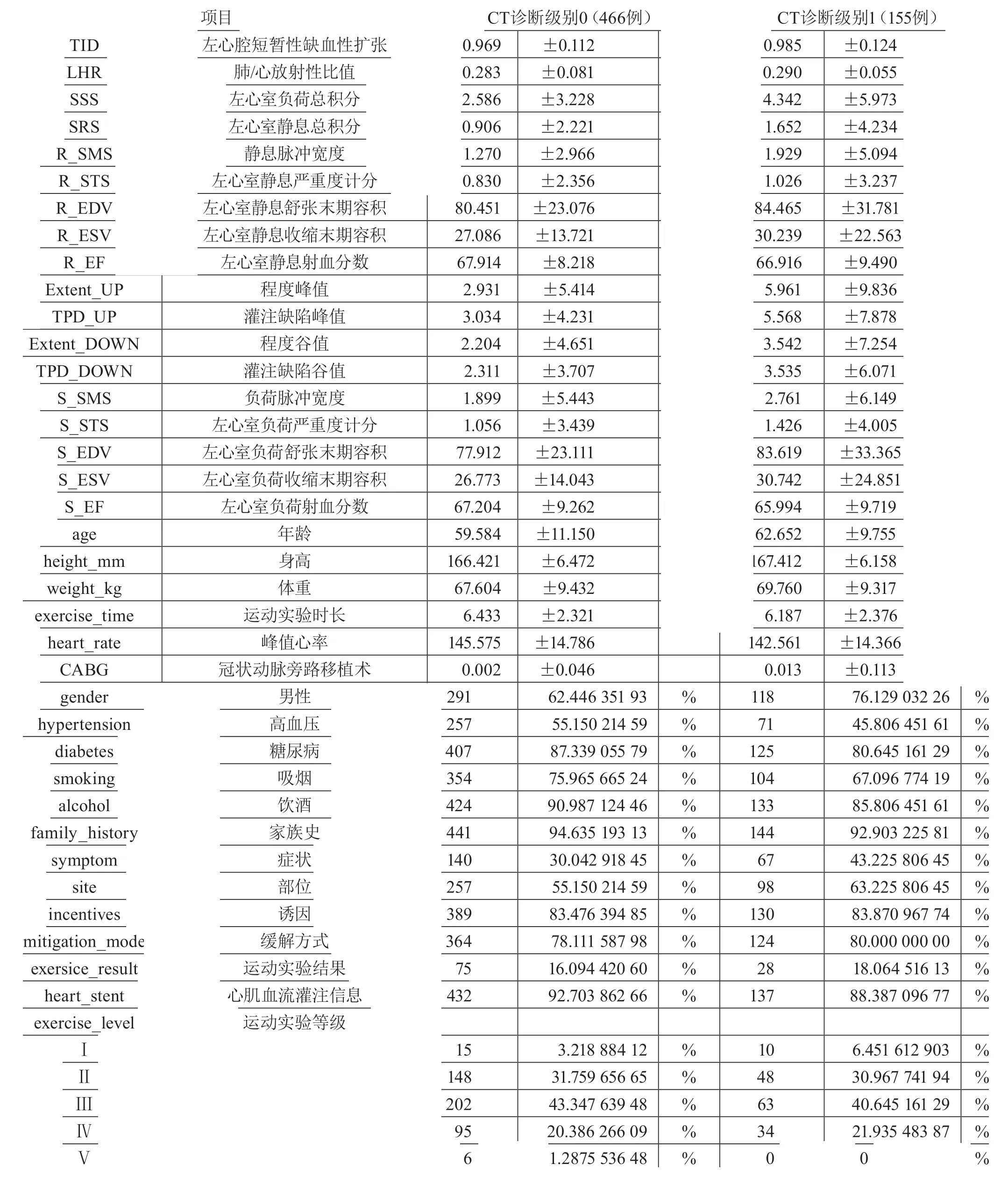
表1 数据统计分布 例 % x±s
2.2 信息增益对于逻辑回归、决策树及随机森林的特征选择
采用信息增益对数据进行特征排序,再选择针对不同的算法逐个删除排名最后的特征属性,观察模型准确率的变化,以选择适应算法的最优特征数量。
逻辑回归算法测试未经过特征选择的模型准确率如图1所示,测试结果为74.09%。采用根据特征选择结果逐一删除属性的方式,逐一测试模型准确率并记录。实验初始,随着特征选择排名靠后的属性删除的个数的增加,模型准确率也逐渐上升,当模型准确率达到一定限度后,再次删除时,准确率又会逐渐下降,在删除“峰值心率”属性、保留了17个特征后,模型的准确率达到了77.74%。相比未经过特征选择的数据集来说,模型准确率提高了约3.65%。
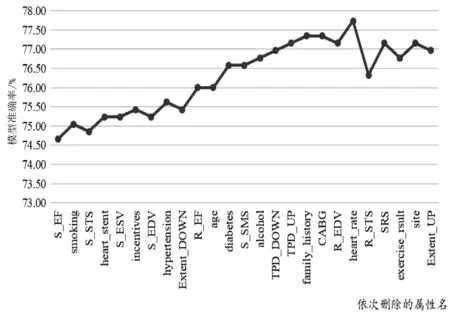
图1 逻辑回归算法模型删除属性准确率折线图
决策树算法测试未经过特征选择的模型准确率如图2所示,测试结果为64.88%,采用根据特征选择结果逐一删除属性的方式,逐一测试模型准确率并记录。初步按照特征排序结果进行属性删除时,随着特征选择排名靠后的属性删除个数的逐渐增加,模型准确率也先随之上升,达到峰值后开始下降,在删除“静息脉冲宽度”属性、保留14个特征时,应用于决策树算法的模型准确率达到峰值77.74%,模型准确率相对没有做特征选择之前提高了12.86%。
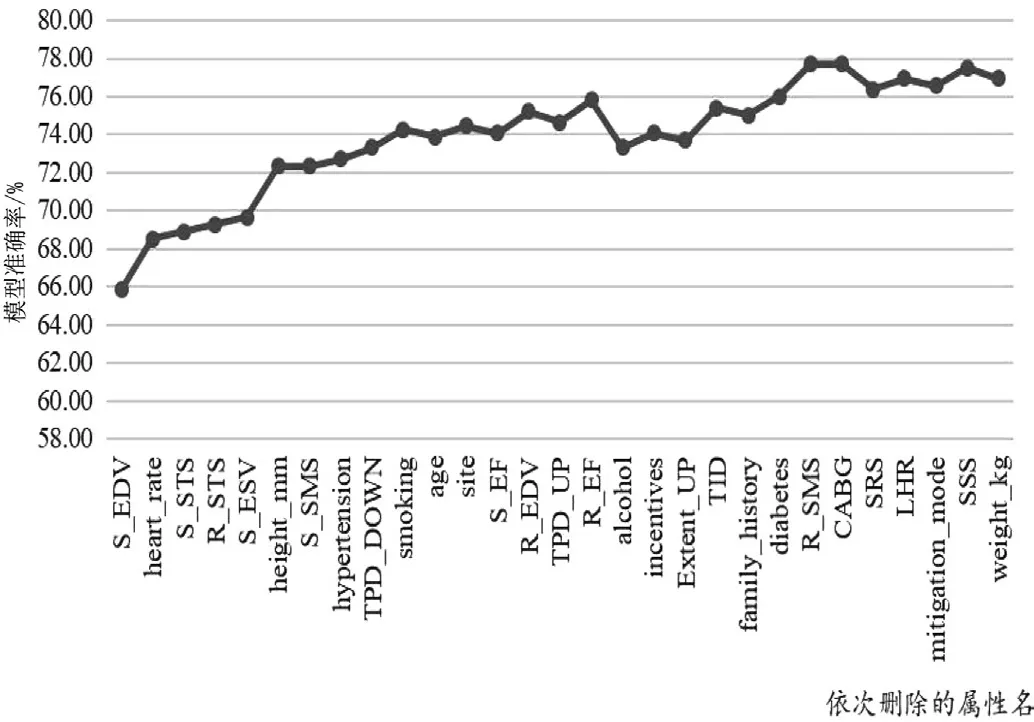
图2 决策树算法模型依次删除属性准确率折线图
随机森林算法测试未经过特征选择的模型准确率如图3所示,测试结果为75.23%,采用根据特征选择结果逐一删除属性的方式,逐一测试模型准确率并记录。初步按照特征排序结果进行属性删除时,随着特征选择排名靠后的属性删除个数的逐渐增加,模型准确率在震荡过程中逐步上升,在删除“家族史”属性、保留25个特征时,应用于该算法的模型准确率达到峰值77.16%,模型准确率相对没有做特征选择之前提高了1.92%左右。
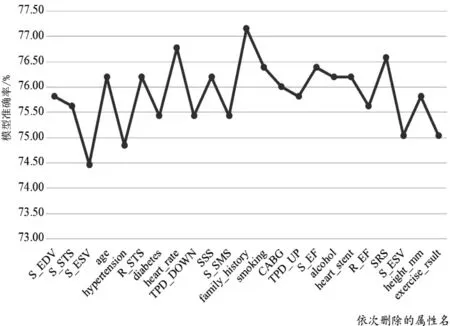
图3 随机森林算法模型依次删除属性模型准确率折线图
通过对3种算法特征选择前后的模型准确率对比,如图4所示,特征选择前后的模型准确率均有所上升,其中决策树算法的特征选择成效最为明显。但3种算法产生的预测模型的模型准确率相差不大,为选取最优的分类算法,先在训练集上使用不用模型及其相应筛选出的特征进行训练,再通过测试集来测试分类结果。
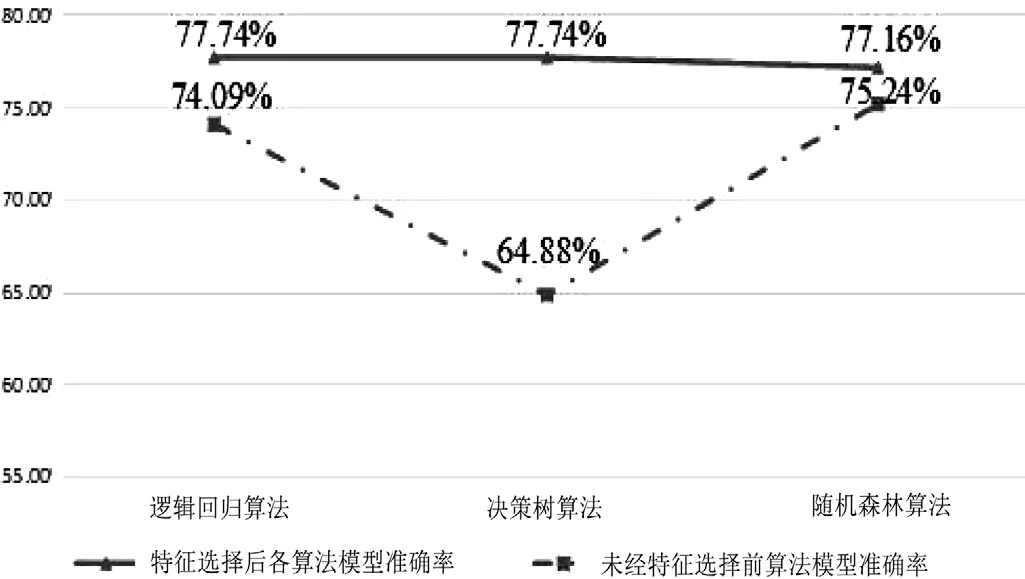
图4 三种算法对特征选择前后的数据构建模型的准确率对比
3 诊断模型构建
3.1 基于逻辑回归算法构建诊断模型
对于逻辑回归算法,模型准确率达到最大时保留的特征为性别、左心腔短暂性缺血性扩张、肺/心放射性比值、左心室负荷总积分、左心室静息总积分、静息脉冲宽度、左心室静息严重度计分、左心室静息收缩末期容积、程度峰值、症状、部位、缓解方式、身高、体重、运动实验时长、运动实验等级、运动实验结果,基于上述特征,采用逻辑回归算法建模,并对预先处理好的测试集的“双源CT检查结果”进行预测,该模型预测正确的实例个数为65,预测错误的实例个数为35,计算得到该算法模型对测试集预测准确率为65%。
3.2 基于决策树算法构建诊断模型
对于决策树算法,模型准确率达到最大时保留的特征为性别、肺/心放射性比值、左心室负荷总积分、左心室静息总积分、左心室静息收缩末期容积、程度谷值、症状、缓解方式、体重、运动实验时长、运动实验等级、运动实验结果、心肌血流灌注信息、冠状动脉旁路移植术,基于上述特征,采用决策树算法建模,并对预先处理好的测试集的“双源CT检查结果”进行预测,该模型预测正确的实例个数为72,预测错误的实例个数为28,计算得到该算法模型对测试集预测准确率为72%。
3.3 基于随机森林算法构建诊断模型
对于随机森林算法,模型准确率达到最大时保留的特征为性别、左心腔短暂性缺血性扩张、肺/心放射性比值、左心室负荷总积分、左心室静息总积分、静息脉冲宽度、左心室静息舒张末期容积、左心室静息收缩末期容积、左心室静息射血分数、程度峰值、灌注缺陷峰值、程度谷值、左心室负荷射血分数、吸烟、饮酒、症状部位、诱因、缓解方式、身高、体重、运动实验时长、运动实验等级、运动实验结果、心肌血流灌注信息、冠状动脉旁路移植术,基于上述特征,采用随机森林算法建模,并对预先处理好的测试集的“双源CT检查结果”进行预测,该模型预测正确的实例个数为62,预测错误的实例个数为38,计算得到该算法模型对测试集结果预测准确率为62%[9-10]。
4 结语
当前的研究表明,逻辑回归算法、决策树算法、随机森林算法可以用来预测冠心病的风险评估。本研究的创新点源在于使用“双源CT”积分作为分级标准及预测变量,并且在特征上结合了MPI的心肌灌注参数及临床诊断指标,能够更好地帮助心血管医生更为高效地对冠心病患者进行诊断。
本研究中的3个模型通过信息增益选取最适应其算法的特征,其中特征选择对决策树算法构建模型准确率影响最大,利用决策树算法构建的模型在数据集进行特征筛选后的准确率提升了12.86%左右,而对随机森林算法构建模型准确率影响最小,利用随机森林算法构建的模型在数据集进行特征筛选后的准确率仅提升了1.92%。进行特征选择后3种算法构建模型准确率相差不大,最终构建模型准确率达到最高的算法为逻辑回归算法和决策树算法,模型准确率达到了77.74%。
通过上述3种算法依次对521个训练集实例的训练结果对比以及对100个测试集实例的预测结果对比,可以发现,针对该冠心病数据集,用上述3种算法构建预测模型时,所训练出来的模型在准确率最高时相差并不是很大,基本上都维持在77%~78%,准确率最高的是逻辑回归算法和决策树算法训练的冠心病预测模型,两者的准确率都达到了77.74%。而在对测试集进行预测时,3种算法训练出来的模型所预测的结果有较大差异,随机森林算法训练出的模型对100个测试集实例的预测准确率是三者中最低的,为62%,而决策树算法训练出的模型对相同数目的测试集实例的预测准确率是3种算法中最高的,为72%。因此得出结论,在该类冠心病数据集上,决策树算法训练出的模型最适合用于该冠心病数据集“双源CT”结果的预测。
猜你喜欢
昆明医科大学学报(2021年4期)2021-07-23
江苏卫生保健(2020年9期)2020-10-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子制作(2017年23期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
西北工业大学学报(2015年4期)2016-01-19
医学研究杂志(2015年4期)2015-06-10
郑州大学学报(医学版)(2015年1期)2015-02-27
振动工程学报(2014年4期)2014-03-01
