
融合CEEMD_MPE和GK模糊聚类的故障识别方法
2020-07-16 03:50赵荣珍孙泽金
振动工程学报 2020年3期
关键词:故障诊断
赵荣珍 孙泽金

摘要:针对转子故障信号非线性、非平稳性的特点,提出了一种基于互补集合经验模态分解、多尺度排列熵和GK聚类的故障特征提取和识别方法。首先采用互补集合经验模态分解对故障信号进行分解,依据相关系数原则,选取相关系数最大的模态分量作为分析对象;然后利用多尺度排列熵量化模态分量的故障特征作为特征向量;最后,将经过PCA(Principal Component Analysis)降维后的低维特征集输入到GK模糊聚类算法中进行故障识别分类。将所提方法应用于典型转子实验台的故障特征集,通过分类系数与划分熵对分类效果进行检验,并与其他模式组合方法进行比较。结果表明,本文所提方法能够更有效提取故障特征。
关键词:故障诊断;互补集合经验模态分解;多尺度排列熵;GK模糊聚类
中图分类号:TH165+。3;TH133.33+1文献标志码:A 文章编号:1004-4523(2020)03-0629-07
DOI:10.16385/j.cnki.issn.1004-4523.2020.03.023
引言
在对转子故障诊断研究中,对转子振动信号进行分析,从而提取出有用的故障特征信息是常用的手段之一。在实际中,采集到的转子振动信号多是非线性、非平稳的,而传统的故障特征提取方法在处理这类振动信号时,相对比较困难。
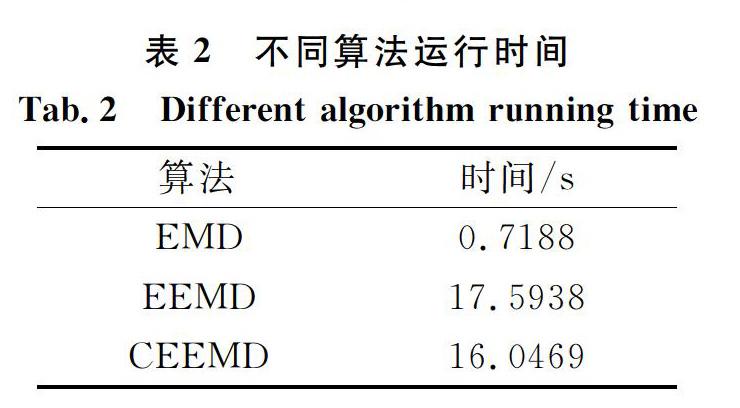
对于故障的非平稳复杂信号,需同时在时域与频域进行分析与处理。常用的时频分析方法有固有时间尺度分解(Intrinsic Time-scalc Decomposi-tion,ITD)、小波变换(Wavelct Transform,WT)等。但上述方法存在一定的缺陷,比如ItD分解后分量波形易出现失真的情况;WT只能对信号的低频部分进行处理,而不能精确提取高频信息,而且小波基函数不具有唯一性,不同的小波基波形差异很大,其规则性也有很大的差异,因此,对于同一个信号选用不同的基函数进行处理得到的结果往往也不同。经验模态分解(Empirical M0dc Decom-position,EMD)在处理非线性、非平稳信号时无需选择基函数,可以自适应地将信号分解成若干本征模态分量(Intrinsic M0dc Function,IMF),非常适合处理此类信号。然而,EMD存在以下问题:①模态混叠;②端点效应。针对上述问题,Wu等借助辅助噪声对EMD进行了改进,提出了集合经验模态分解(Ensemblc Empirical M0dc Decomposi-tion,EEMD),通过在原始信号中添加高斯白噪声,使信号分解具备抗噪特性。但EEMD在一定程度上存在白噪声残留带来重构误差的问题,而且计算运行的时间大大地延长。Yeh等提出了互补集合经验模态分解(Complementary Ensemblc Em-pirical M0dc Decomposition,CEEMD),在EEMD的基础上将添加的白噪声采用正、负成对的形式,将重构信号中的残余分量抵消,减少了计算时间。
经过CEEMD分解,原始信号中的故障特征信息存在于得到的本征模态分量中,为量化这些故障特征,引入熵理论。排列熵(Permutation Entropy,PE)是一种用来检测随机性和动力学突变的方法,其计算简单、抗噪能力强。Yan等证实将排列熵引入旋转机械振动信号特征提取中的结果表明可以有效地对不同状态下的滚动轴承的工况特征进行表达。但是,在单一尺度上描述时间序列的不规则性往往存在一定的局限性,为此文献在排列熵的基础上提出多尺度排列熵(Multi-scalc Permuta-tion Entropy,MPE)算法用于衡量时间序列在不同尺度下的复杂性和随机性,使鲁棒性得到加强。
文献在轴承故障诊断上运用多尺度排列熵提取故障特征,取得了良好的诊断效果。对CEEMD方法分解得到的各模态分量进行MPE分析,能够使转子的故障特征信息得到更好的表达。
故障诊断的实质是模式识别,聚类分析是模式识别的常用方法之一,常用的有模糊C均值(FuzzyC-Mean,FCM)、GK(Gustafson-Kessel)聚类等。其中FCM仅适用于球形分布的数据,这使得它在聚类分析时具有一定的局限性;GK聚类通过自适应距离范数和协方差矩阵获取目标函数,所以它对分布不均匀的数据点都能够很好的表达,适用于变量间存在相关性的数据集的聚类分析。
基于上述分析,本研究结合CEEMD算法与MPE的优点,提出将CEEMD算法与MPE结合用于转子的故障特征提取,并用GK模糊聚类算法進行转子故障的识别的方法,并通过实验验证它的有效性。
1 方法基本理论
1.1 互补集合经验模态分解
CEEMD是Yeh在EEMD基础上提出的一种改进的方法。EEMD是对EMD分解方法的改进,它通过在原始信号中加入均匀的高斯白噪声解决了原算法造成的模式混叠问题。针对EEMD方法迭代次数多、运算效率慢的问题,CEEMD分解方法进一步做出了改进。在原有方法的基础上加入的辅助噪声都是正负对形式,可以抵消处理后得到信号的噪声影响,迭代次数也相应减少,运算效率得到极大提升。具体步骤如下:
1)在原始信号x(t)中添加N组正负对形式的白噪声n(t),得到两组模态分量;
2)对信号采用EMD方法进行分解,每个信号都可分解为一系列IMF分量,其中Cij为第i个信号的第j个IMF分量。
3)通过多组分量组合得到分解结果式中 Cj为CEEMD分解得到的第j个分量。n为加入白噪声的次数。
1.2 多尺度排列熵
MPE的基本思想是将原始时间序列进行粗粒化处理,在多个尺度上计算时间序列的排列熵,然后计算各个不同尺度下的排列熵,即多尺度排列熵。具体计算步骤参考文献。
2 基于GK模糊聚类的模式识别
GK模糊聚类算法的具体步骤如下:
对于一个给定的数集X=[x1,s2,…,xn],设利用隶属度划分矩阵U=[βjk]x×n作为判据,可将X聚成c类(2≤c≤n)。其中,βjk表示第j个样本隶属于第i个类别的程度。n为样本数目,βjk为聚类中心式中
D表示任意数据点xi到聚类中心vi的距离。
对给定终止容许误差c>0,若迭代次数l=0,1,2,…,如果||Ul+2-Ul||≤ε,则迭代终止,否则增加迭代次数,使l=l+1,重复上述步骤,直到满足条件。
3 故障识别方法的设计
本研究所提出的基于CEEMD、多尺度排列熵和GK模糊聚类相结合的新的故障诊断方法,充分利用CEEMD可以自适应处理信号和排列熵,计算简单、抗噪性好的优势,通过相关系数筛选出CEEMD分解后的最优模态分量,计算最优模态分量的多个尺度的排列熵作为特征向量。针对用此方式得到的熵值特征向量存在着高维度的新问题,利用PCA进行降维,从而获取低维敏感的特征向量,最后输入到GK模糊聚类算法中,具体步骤如下:
a)对采集的振动信号进行CEEMD分解,得到若干IMF分量。
b)对若干个IMF分量进行相关性分析,相关系数最大的即为最优模态分量,EMD分解后的模态分量与原信号的相关性约等于各分量的自相关系数,以此筛选出最优模态分量,剔除无关模态分量。
c)计算筛选出的最优模态分量的多尺度排列熵值,选取12个尺度的排列熵将其作为特征向量。
d)利用PCA对特征向量进行维数约简。
c)将约简后的低维、敏感特征向量作为GK模糊聚类算法的输入,并采用聚类评价指标对聚类结果进行判定。
转子故障信号诊断流程图如图1所示。
4 实验分析
本项工作所使用的故障数据集源自图2所示的双跨度转子试验台。该实验台安装了13个电涡流传感器。其中,前12个传感器用于采集不同截面下的转子的振动信号(即前12个通道),最后一个传感器(即最后一个通道)用于采集系统中转子的转速信号。实验数据选取在采样频率为5000Hz,驱动电机转速为2800r/min下采集的振动信号。在实验数据处理时,本实验选择前12个通道的数据进行处理。模拟如下四种典型故障:支座松动、动静碰摩、质量不平衡和轴系不对中,以及正常状态下的实验。每种状态取50组样本,数据长度为2048.
由于篇幅限制,本研究以不对中状态进行分析,其原始振动信息如图3所示。本文根据Yeh等针对CEEMD添加参数的研究,选择CEEMD添加的白噪声幅值为0.15,添加白噪声对数为50.图4为原始振信号经CEEMD自适应分解后得到12个IMF分量。分别计算各阶IMF与原信号的相关系数,得到表1.由此可以得出,IMF与原始振动信号的相关系数最大为1.0000,因此选择IMFl为最优分量进行下一步故障分类和识别。
在计算多尺度排列熵时,需对以下4个参数进行设定:时间序列长度N、嵌入维数f、时延因子r和尺度因子s。嵌入维数一般取3-7,若厂太小,重构序列中可能包含的状态会太少,难以检测出时间序列的动态突变;若厂太大,将无法反映时间序列的细微变化。本文选取f=4.延迟时间r对时间序列的计算影响较小,尺度因子s的最大值一般取大于10即可。图5为不同时延下排列熵数值变化情况,可以看出时延对信号的影响较小,因此取r=1.尺度因子取s=12,計算12个粗粒向量的排列熵,得到5种状态结果如图6所示。
图6是5种状态随尺度因子s增大时最优模态分量的多尺度排列熵变化情况。可以看出,不同状态的MPE值不同,这是因为当转子发生故障时,振动信号的变化随机性使排列熵值发生变化。当尺度因子s=1,即单一尺度排列熵时,正常状态熵值与故障状态熵值相差不明显,很难区分故障状态,因而需要对最优分量进行多尺度分析,故本文选取12个尺度的熵值当作特征向量。
对转子5种状态分别进行CEEMD分解并通过相关性分析选出最优模态分量,在多个尺度下计算最优模态分量的排列熵。选取12个尺度排列熵作为特征向量,得到5组50×12×12的排列熵。采用PCA降维算法将特征向量从144维降到3维。因为有5种不同状态,所以聚类中心个数设定为5个,迭代终止容差ε=0.0001.将经PCA降维后的特征向量输入GK聚类算法,其2维等高线聚类图如图7所示,其中“O”代表聚类中心。
图7中,V1,V2,V3,V4,V5分别代表{不对中、不平衡、碰摩、松动、正常}共5种状态的聚类中心。从图7可以看出转子的5种状态明显被分开,且均聚集在聚类中心附近,聚集紧密,没有出现混叠的现象,间距较大。通过计算各样本的平均隶属度,分别将各个样本归属于某一特定类别,同类别的状态依附在各聚类中心附近,实现故障状态的分类。为说明本文提出方法的有效性,本文直接对原始振动信号进行多尺度排列熵计算和CEEMD分解后提取单一尺度排列熵作对比实验,并把结果输入到FCM,GK聚类算法中,结果如图8所示。
由图8可知:1)将图8(a)和(b)与图8(c),(d)和(c)进行对比可以得出,直接对原始信号进行多尺度排列熵提取得到的特征向量经FCM,GK聚类算法处理的聚类效果不理想,而经CEEMD多尺度排列熵提取的特征向量聚类效果较好。显然,这是原始信号经CEEMD处理,保留了更多故障信息的结果。2)图8(d)与8(e)聚类效果不佳。这是因为单一尺度排列熵并不能很好地表征故障状态,而且经过CEEMD后并没有筛选出最优模态分量,没有去除冗余信息,这对聚类效果造成了一定的不利影响为进一步说明方法的有效性,再进行CEEMD,EEMD和EMD多尺度排列熵对比实验,在对比实验中对于EEMD和EMD分解信号同样依据相关系数原则,选出相关系数最大的模态分量作为分析对象进行实验,并把结果输入到GK聚类算法中,结果如图9所示。
通过图7与图9对比分析和表2可以得出结论:CEEMD多尺度排列熵组合较其他组合模型,其聚类结果的类内紧致性最好,聚类中心基本吻合。这是因为EMD处理后各模态之间会存在混叠现象,从而导致提取出的故障信息不准确,使得聚类效果不好;而EEMD虽然改进了EMD中存在的模态分量的混叠现象,但某种程度上仍存在,而且其计算度复杂、迭代次数多也都影响聚类的效果。
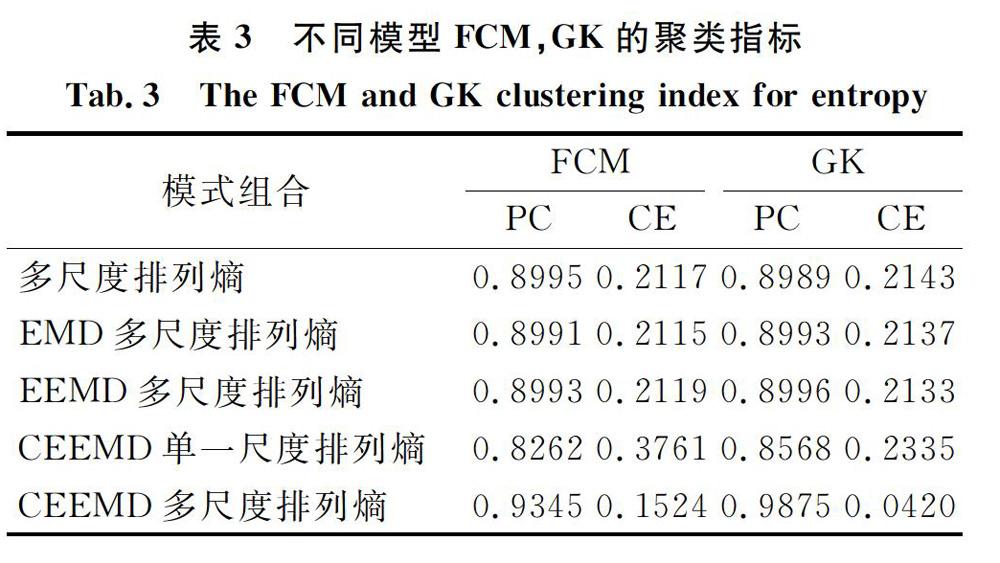
最后,聚类效果通过聚类评价指标——划分系数(Partition Coefficient,PC)和划分熵(Classifica-tion Entropy,CE)对图7-9中不同模型聚类效果进行评估。划分系数PC越接近于1,划分熵CE接近于0,聚类效果越好。根据表3可得出如下推论:1)GK聚类相对于FCM聚类方法效果更好。这是因为FCM聚类的聚类形状为圆球形,它仅反映超球形数据结构的标准距离范围规范;GK聚类的聚类形状为椭球形,这有助于降低GK聚类方法对数据类型的限制,扩大该聚类的应用范围。2)CEEMD多尺度排列熵组合在GK聚类中PC值最大,达到了0.9875,CE值最小为0.0420.由此看出,CEEMD多尺度排列熵组合较其他组合模式具有一定优势,因此本文提出的方法较好。
5 结论
CEEMD通过加入正、负成对的辅助噪声,既解决了传统EMD方法中模态混叠的问题,同时又消除了重构信号中的残余辅助噪声,克服了EEMD方法分解结果中白噪声中和不彻底的问题,并且加入的噪声集合次数低,解决了運算时间长、效率低的问题。与相关系数准则结合,筛选出相关系数最大的模态分量作为研究对象,有效地降低了噪声干扰,保留了故障冲击成分。在此基础上,提出了一种CEEMD分解、多尺度排列熵、GK聚类算法相结合的故障诊断方法,并把它应用到转子故障诊断中。该方法首先采用CEEMD对原始信号进行分解、得到一系列本征模态分量,通过计算各个本征模态分量与原始信号的相关系数,筛选最优模态分量达到剔除冗余信息的目的,对最优模态分量进行多尺度的排列熵计算,对于得到的多尺度排列熵特征向量存在高维度和数据无法可视化问题,采用PCA进行降维之后再输入到GK聚类算法中。实验结果表明,本研究提出的故障诊断方法在处理非线性、非平稳性的信号时,能够有效地提取出有用的故障信息,能够较好地区分转子的不同状态,各故障数据类内聚集紧凑,类间无重叠,是一种有效的自适应故障特征提取和故障数据聚类与分类方法,为处理非线性、非平稳性信号提供了一种新的解决思路。
猜你喜欢
电子乐园·下旬刊(2022年6期)2022-05-16
今日自动化(2022年1期)2022-03-07
内燃机与配件(2022年2期)2022-01-17
内燃机与配件(2022年2期)2022-01-17
科学与财富(2020年3期)2020-04-02
科学导报·学术(2019年14期)2019-09-10
振动工程学报(2019年2期)2019-05-13
中国新通信(2016年16期)2016-10-18
科技视界(2016年21期)2016-10-17
科学与财富(2016年28期)2016-10-14
