
基于文本相似性匹配的计算机辅助翻译软件研究
2020-07-14 01:52何斌
甘肃科技 2020年1期
何 斌
(解放军91404部队,河北 秦皇岛 066001)
查准率与响应速度是计算机辅助翻译软件最重要的两项指标。查准率的实际反应是检索反馈的原文与用户检索的原文之间的匹配程度,也就是检索反馈结果能把语料库中所有具有翻译参考价值的译文按相似度排序呈现给用户。与传统的数据库模糊查询不同,检索内容不是确定的检索关键字,实际上被检索目标与检索内容只存在文本上相似或近似。所以,诸如Like语句实现的模糊查询在计算机辅助软件的检索中并不适用。另外,与其它的检索系统一样响应速度是计算机辅助翻译软件最主要的性能指标,通常情况翻译语料库数据量较大,故查询速度的优化对计算机辅助软件的尤为重要。
针对上述问题,采用文本相似度算法实现高匹配度检索,并运用云计算和并行运行等方法优化响应速度,最终实现计算机辅助翻译软件最优的用户体验。
1 计算机辅助翻译
1.1 计算机辅助翻译
计算机辅助翻译 (Computer Assisted Translation,CAT)是通过计算机软件来实现的专业翻译解决方案,它与机器翻译(Machine Translation,MT)有着本质的区别。机器翻译依赖于计算机的自动翻译,而计算机辅助翻译是在人的参与下完成整个翻译过程。形式最简单的计算机辅助翻译只是一个数据库,译者可以纪录以前的翻译结果以便于将来再次使用以及进行方便有效的检索。计算机辅助翻译工作原理是翻译人员利用已有的原文和译文,建立起一个或多个翻译记忆库,在翻译过程中,系统将自动搜索翻译记忆库中相同或相似的翻译资源(如句子、段落等),给出参考译文,使用户避免无谓的重复劳动,只需专注于新内容的翻译。对于给出的参考译文,译者可以完全照搬,也可以修改后使用,如果觉得不满意,还可以弃之不用。简单来说计算机辅助翻译就是:TM(记忆体/语料库)+MT(机器翻译)+HT(人工翻译)。计算机辅助翻译相比人工翻译有翻译效率高、译文一致性好、翻译成本低的优势,正不断受到重视和发展。
计算机辅助翻译技术的核心就是翻译记忆技术,译者在进行翻译工作的同时,翻译记忆库在后台不断学习和自动储存新的译文,实时更新记忆体,每当相同或相近的短语出现时,系统会自动提示用户使用记忆库中最接近的译法。计算机辅助翻译软件实现的关键技术就是译文模糊匹配及查询效率。
2 计算机辅助翻译软件设计方案
2.1 软件总体设计
本方案创新性设计基于网络的多用户计算机辅助翻译软件,软件可实现多用户并发在线使用,完成一个翻译项目的多人分工并发协同工作。软件由语料库、字典数据库、译文获取模块、模糊匹配查询模块、译文插入模块、语料库自动更新模块等组成。
主要工作流程为:
第一步,翻译人员把将要翻译的工作文档(原文)输入给计算机辅助翻译软件,软件逐句读取原文。
第二步,软件自动按已读取的整句进行模糊查询,从语料库返回匹配度相近的译文,原文与译文同时显示于工作区域。
第三步,软件对当前的原文进行分词,并按分词结果逐词返回译文。
第四步,翻译人员对照语料库返回的译文、单词译文、原文进行校对。
第五步,译文校对完成后,由软件插入工作文档中原文位置之后,同时对语料库进行更新。
第六步,返回第一步。
计算机辅助翻译软件工作流程,如图1所示。
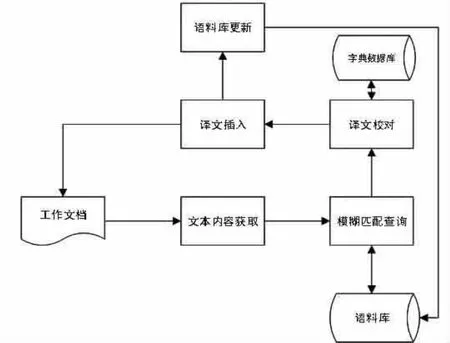
图1 计算机辅助翻译软件工作流程图
计算机辅助翻译软件采用C/S结构,语料库数据库采用Postgresql,字典数据采用SQLite,客户端采用C#进行构建。技术架构如图2所示:
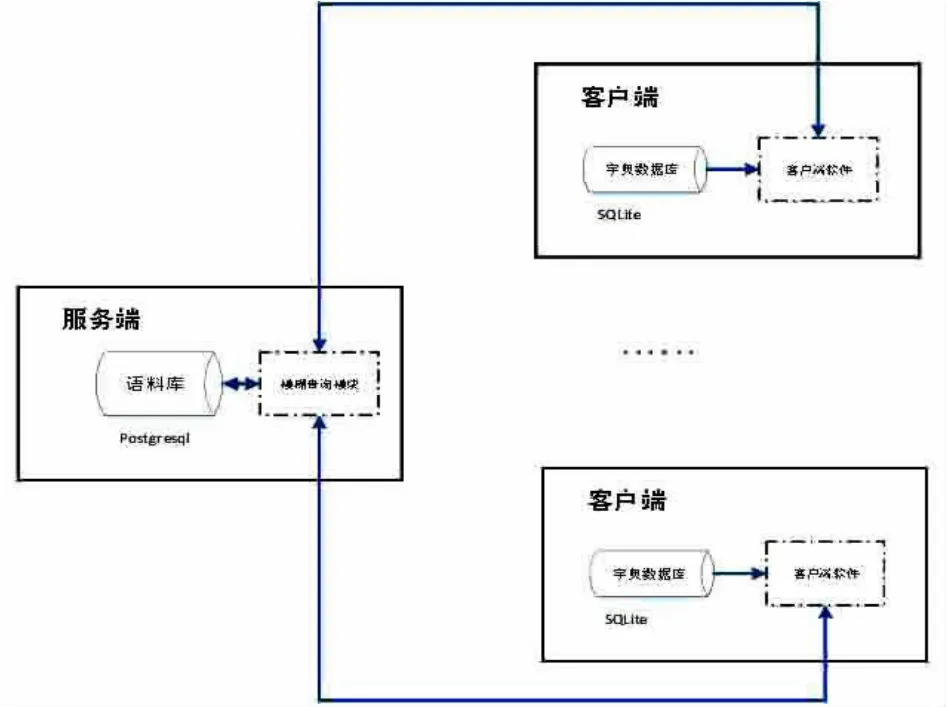
图2 计算机辅助翻译软件技术架构图
计算机辅助翻译软件人机操作界面主要分成翻译辅助区与翻译文档区两部分限组成,翻译文档区显示被翻译文档(Word文档),翻译辅助区主要为获取的原文语句获取显示、翻译结果及其它用户操作等交互界面。具体界面设置与效果如图3所示:

图3 软件人机界面
2.2 计算机辅助翻译软件实现的关键技术
计算机辅助翻译软件实现的核心是对语料库的查询,技术关键是查询速度及查询效果,查询速度越快、词条模糊匹配效果越好则用户体验就越好。
1)查询速度。信息系统的查询速度是用户体验的最关键指标,查询响应时间越短用户体验越好。据调查,数据软件查询费时0~2s则用户体验最好,费时2~8s用户可以容忍,如查询费时大于8s则用户不能忍受。所以,计算机辅助翻译软件查询响应时间必须控制在8s以下,最于2s则最优。对计算机辅助翻译软件的使用人员而言,语料库越大语料可重用性就越高,翻译工作则越高效。实际应用中语料库数据量比较大(作者当前项目的语料库的数据量大于400万条),且数据量随使用不断增长。查询响应时间一般与数据量成反比,故当数据量超过百万条后常用方法查询时间超过8s,所以必须对数据库查询方法进行优先和优化才能达到查询最优化。
2)模糊匹配。在翻译过程中,软件检索语料库,寻找合适的译文。除在重复性高的技术文档翻译中有完全匹配的情况外,绝大部分检索都为模糊匹配。实事上模糊匹配效果也是决定计算机辅助翻译工具是否好用的最重要指标。
最理想的模糊匹配模式就是从语料库中寻找译文意思相近的语句,而通用的数据库检索方法只能实现最多关键词匹配。
例:理想模糊匹配模式,翻译She like collecting stamps.语料库中如果没有类似于“She like collecting stamps too.”这样的语句,就会优先返回“She is fond of collecting stamps.”作为翻译参考。但如果按最多关键词匹配就很可能无作任何结果返回。随便说一下,原文为中文则必需在检索之前先要对原句进行中文分词,原因是计算机不会自动识别句中的词语。比如一句“结婚的和尚未结婚的”,可能分成“结婚/的/和尚/未/结婚/的”这样检索。
综上所述,模糊查询算法是软件实现最核心的关键技术,其算法优化将是整个软件易用性最大的挑战。
2.3 查询技术选择
2.3.1 基于文本相似度算法的查询
(1)文本长度过滤。在计算机辅助翻译过程中,考虑到查询目标往往与查询内容长度相近的特点,可以首先对数据进行文本长度过滤。文本长度过滤运算代价较小,可以极速缩小被查数据库库表的规模,可为下一步文本相比节省时间。
其中,source_text查询内容,p_source_text为查询目标。目标文本长度设置为查询文本长度不多于且不少于5个字符。
(2)文本相似度算法。基于词语(单词)重合的重叠相似度算法将短文本内容看成是独立关键词的集合,通过两个短文本的共现词的个数来判断两个短文本的相似性。
若两个短文本中共现词的个数越多,则两个短文本就越相似;反之,两个短文本的相似度就越低;同时,为保证两个短文本的相对相似度一致,采用相似度计算公式1:
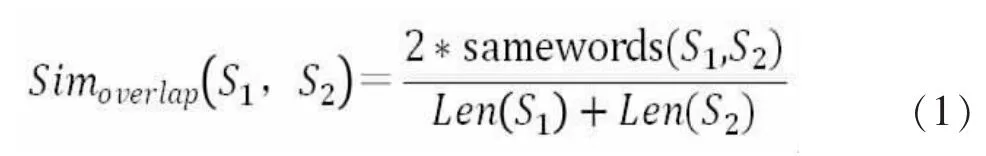
基中samewords(S1,S2)表示S1与S2中都出现的关键词个数;Len(S1)表示中的关键词个数,Len(S2)表示S2中的关键词个数。经本软件测试用户调查统计得知,S1与S2的比调整为85%用户体验满意度最高。
2.3.2 快速查询技术优化
为提升翻译人员的使用体验,减小翻译实时翻译时间。在查询算法上的优化同时还考虑其它方法进行查询时间的缩短。
1)云计算。一般来讲,用于计算机翻译的办公计算机在性能方面有着较大的差异,进而导致计算机辅助翻译软件呼应时间不同带给用户不同的用户体验。为减小由于用户计算机不同带来的差异,在软件设计时把大部分计算工作放在服务器上完成,用户端只完成数据信息的传递与显示。这种“云计算”的设计架构在最大程度提高计算机辅助翻译软件性能的同时也让每一位用户享有比较接近的用户体验。
2)并行运算查询。并行运算的设计也是为提升性能的考虑。由于数据库表大的原因上经过上述优化后查询速度依然不理想,所以需要把数据库拆分成若干个小数据库进行并行查询而后对查询结果进行合并,从而最大程度缩短查询时间。并行运算时间成本原理如图4所示:
图中并行运算时间成本公式2。
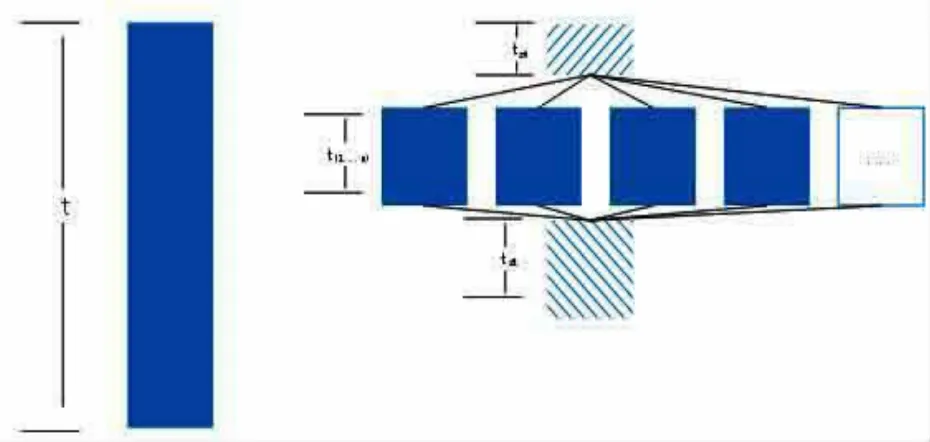
图4 并行运算时间成本示意图
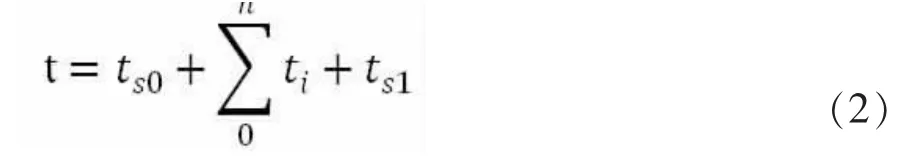
其中t为整个计算过程时间,tS0为并行计算任务拆分花费时间,ti为单项个并行任务计算时间,ts1为计算结果合并时间。tS0、tS1随任务拆分数量n增加而增加,所以并不是并行数量越大越好。对同一检索条件下不同并行数的测试,本方案最终选择n=10为最优并行查询数,实验结果比对见表1。
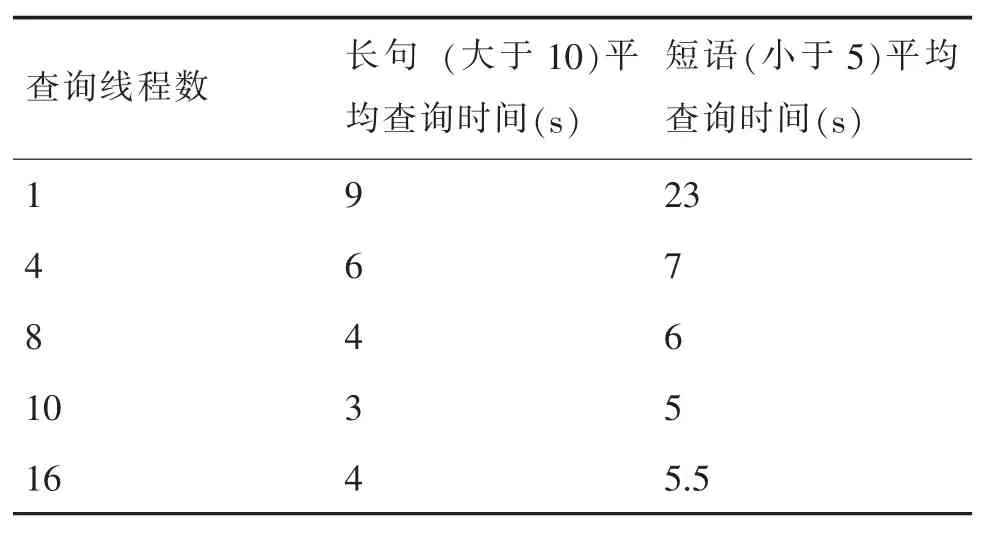
表1 同一检索条件下并行查询的耗时比较
3 结束语
本文设计并实现了多用户网络计算机辅助翻译软件,采用网络语料库结合本地字典数据库的方法实现了多人在线并行翻译工作。实验结果表明,综合运用了文本长度过滤、相似度匹配、并行运算等方法使翻译语句查询响应时间控制在用户可接受范围内,同时翻译的查准率较为理想。在实际应用中,本软件设计功能、性能满足多人同时在线翻译的并行工作。下一步,将对语料库进行进一步优化,并持续改进查询算法,使系统查询响应时间进一步缩短。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
天津外国语大学学报(2020年1期)2020-03-25
电子制作(2019年13期)2020-01-14
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
