
基于集成聚类的交叉口车辆行驶路径提取方法
2020-07-14 02:48:46陈阳舟卢佳程
计算机应用与软件 2020年7期
尹 卓 许 甜 陈阳舟 卢佳程
1(北京工业大学北京市交通工程重点实验室 北京 100124)2(中交第一公路勘察设计研究院有限公司 陕西 西安 710075)3(北京工业大学人工智能与自动化学院 北京 100124)
0 引 言
轨迹数据的聚类是监控场景中目标行为分析的一项具有挑战性的基础工作。针对交叉口场景而言,车辆的行驶轨迹聚类对于交叉口的安全评估具有重要的意义。例如,基于车辆行驶轨迹聚类提出不同行驶路径,可用于分析车辆事故的碰撞方式,评估事故发生的风险程度等。交叉口的车辆轨迹数据通常来自交通监控视频中车辆的识别与跟踪。虽然交叉口车辆的运动行为受到交通规则的限制,具有很强的规律性,但是基于机器学习的车辆轨迹聚类却面临着很大的挑战性。首先,交叉口场景非常容易发生遮挡,导致轨迹不连续的现象发生;其次,对于轨迹聚类而言,由于监控场景视野的缘故,聚类与聚类之间的区别不明显,使得在相似位置具有相似特性的轨迹可能对应于不同的聚类[1],甚至两个聚类的轨迹数据会存在重叠的现象;最后,交叉口的车辆常常出现的停止行为使轨迹存在大量的停止点,从而导致轨迹的冗余现象。针对交叉口场景设计车辆轨迹聚类算法,并在此基础上获取稳定的场景路径信息已成为具有挑战性的研究热点。
各种监控场景下路径提取的基础是运动目标的轨迹聚类,轨迹聚类主要分为三种方式。第一种聚类方式为基于轨迹的空间相似性。早期的代表性工作由Morris等[2-3]和Zhang等[4]完成,他们将轨迹聚类问题转化为时间序列聚类问题,并使用序列相似性距离度量(如LCSS距离等)计算轨迹之间的距离。基于轨迹相似度,采用各种聚类算法对轨迹进行聚类。例如,Morris等[3]针对DTW和LCSS等距离度量应用于模糊C-means聚类算法的效果进行了实验对比,总结了相关算法的特点与优势。Kim等[5]针对城市级别的GPS轨迹数据进行分析,使用DBSCAN聚类算法对轨迹进行聚类。他们采用LCSS距离来评估轨迹的相似性,然后借助DBSCAN中的核心点的定义,提出了聚类代表(CRS)提取算法,并在聚类代表的基础上合并相似的轨迹聚类。基于比较的聚类算法往往能够取得较好的效果[3],但是其缺点是时间与空间复杂度较高。Lee等[6]基于最小描述长度原则(MDL)设计了轨迹分段算法。他们对轨迹先根据关键点进行分段,再对分段轨迹进行聚类。由于分段轨迹的距离度量采用了针对线段的朝向角度以及垂直距离与平行欧式距离度量,该算法本质上也是基于距离的聚类方式。
第二种聚类方式主要基于统计特征。早期的代表性工作中,Li等[7]提出采用轨迹距离直方图(TDH)对轨迹进行描述,其中轨迹点的转向角被投射到了方向直方图中,因此形成了对轨迹方向的统计特征表示;Anjum等[8]拓展了相关的特征,提出了轨迹数据的一系列统计特征,并使用Mean-shift算法对轨迹进行了聚类。基于统计特征的轨迹数据聚类往往能够以较低的时间复杂度获得较为稳定而优良的聚类效果,但是轨迹的统计特征忽略了轨迹数据的时空相关性,因此聚类效果往往不如基于相似度的轨迹聚类效果。
第三种聚类方式是在轨迹建模之后再利用模型对轨迹进行分析。文献[9]使用高斯混合模型与隐马尔可夫模型对轨迹进行建模,然后对轨迹进行聚类。文献[10]则利用狄利克雷过程对轨迹进行分类与聚类,算法可以被拓展到实时方式,但是这种聚类方式的缺点在于其效果通常受到模型参数初值的影响。
在上述针对监控场景的车辆轨迹聚类方法中,缺乏对基于空间轨迹相似度比较的方法与基于统计特征的轨迹聚类方法进行集成,以发挥各自的优势。因此,为了获取更具鲁棒性的聚类结果,获取场景的路径信息,本文提出基于集成聚类的交叉口路径信息挖掘方法,通过融合不同聚类方式获取交叉口场景的路径信息。首先,对基于轨迹统计特征的聚类方法与基于距离度量的聚类方法进行集成,获得了更具鲁棒性的轨迹聚类结果;其次,针对轨迹相似度矩阵引入拉普拉斯中心性[11],并对每一个聚类的聚类原型进行提取,消除了噪声轨迹对聚类原型提取的影响;最后,引入深度优先搜索算法对聚类原型相似度邻接矩阵的连通子图进行搜索,合并冗余的聚类,生成场景的路径信息。使用获取的路径信息,可以进一步对轨迹进行分类或者异常检测等。
1 相关概念与数据预处理
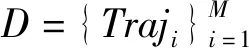
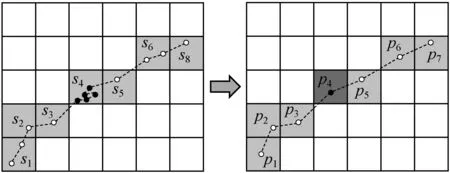
图1 轨迹数据网格化实例,深色区域被标定为停止区域
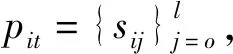
(1)

2 轨迹特征提取与距离度量
2.1 轨迹数据的直方图描述
如图2所示,轨迹的方向角度被分为了8份,每一个网格上的角度被分配到了统计图上。

图2 轨迹数据角度直方图
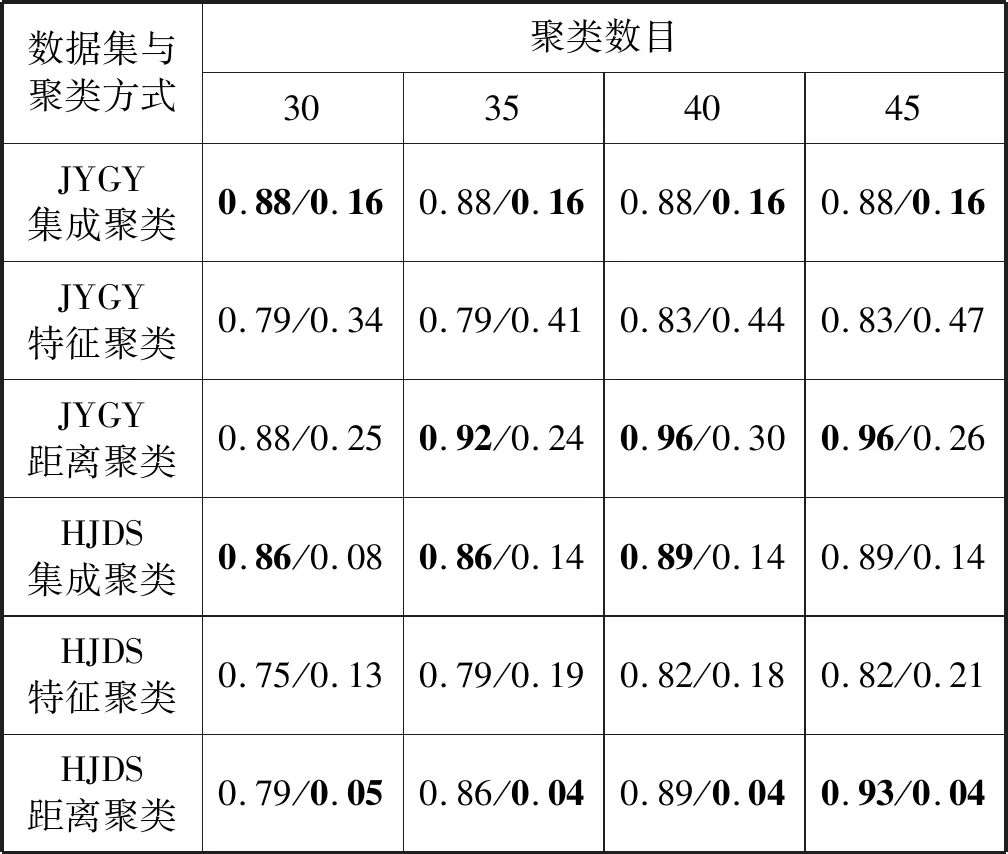
对于pij而言,若(m-1)Δα≤aij (2) 便可以得到轨迹方向落在第Im区间内的频率,并且得到一个长度为α的一个轨迹方向向量。 (3) 而轨迹的复杂度定义为: (4) 式中:ci取值在0到1的范围内。不同于文献[3],这里轨迹的复杂度计算使用了压缩后的轨迹的复杂度计算。文献[3]采用原始轨迹对轨迹复杂度进行计算,但是在存在大量停止点的情况下,利用原始轨迹计算移动总距离会受到冗余的停止点的影响,因此此处采用网格轨迹计算车辆行驶的距离,可以防止停止点对于计算的干扰。 前面从轨迹的朝向和形状两个角度给出了轨迹的特征提取方法,还提取了轨迹的以下特征:轨迹的起点与终点坐标[xi1,yi1]与[xiTi,yiTi],轨迹x与y坐标的分布特征[μix,σix]与[μiy,σiy]等。由于这里使用的都是完整的轨迹,自然轨迹的起点与终点对于轨迹聚类的判别有一定的帮助,不同起点与终点的轨迹对应于不同的运动模式。 (1) 边界条件:路径的起点位于(pi1,pj1),终点位于(piTi,pjTj)。 (2) 渐进性条件:路径上的每一个轨迹点满足条件:pi1≤…≤pik≤…≤piTi,pj1≤…≤pjl≤…≤pjTj。 (3) 步长条件:当位于(pik,pjl)点时,路径的下一步坐标在{(pi(k+1),pjl),(pik,pj(l+1)),(pi(k+1),pj(l+1))}集合内。这意味着每次路径只能沿着时间顺序移动一步。 条件(3)可以被放松为移动多步[14],这通常意味着DTW对于噪声的轨迹点具有更强的鲁棒性。假设这里存在一条累积损失值最小的路径f*,而DTW距离被定义为: DTW(Traji,Trajj)=sum(f*) (5) 即DTW距离的值为满足三个条件的累积损失值最小的一条路径的累积损失值。 图3为数据集中两条轨迹的损失矩阵的热力图。颜色越深,则两个坐标点之间的欧式距离越近。而最优的DTW距离的值为满足前面条件的累积损失最小的一条路径对应的累积损失值,也就是白色的路径。类似于DTW距离的度量方式还有LCSS距离、Frechet距离、编辑距离等。 图3 DTW距离在损失矩阵中的最优路径 现有的一系列研究中,对于交叉口场景的轨迹聚类可以粗略地分为基于统计特征聚类[7-8,14]的轨迹聚类方法与基于比较的轨迹聚类方法[5-6,9],这些方法有各自的优缺点。为了提升聚类的鲁棒性,获取更高质量的聚类,本节采用两类方法融合的集成聚类策略,即对基于特征的聚类与基于轨迹相似度的聚类进行了集成。 记联合相关矩阵为S,矩阵的元素为: (6) 式中: (7) 可以看出,联合相关矩阵元素的取值范围在0到1之间,其生成过程如图5所示。 图5 联合相关矩阵生成 (8) 式中: (9) (10) (11) (12) 权重wn的定义为: wn=ECI(clsn(Traji)) (13) 基于轨迹相似性的聚类采用谱聚类方法进行。谱聚类[15]是一种基于图的聚类算法,其思想是基于结点的相似度构建邻接矩阵与拉普拉斯矩阵,然后优化基于拉普拉斯矩阵的损失函数[15]。以DTW距离为例,首先构建轨迹数据的邻接矩阵A: Aij=e-DTW(Traji,Trajj)/2ζ2 (14) 针对轨迹特征的聚类,本文采用层次聚类算法。其优点在于对于非凸聚类也能取得优异的结果,缺点是时间复杂度较高。当进行特征聚类时,轨迹形状特征与轨迹方向直方图(TDH)描述的特征被组合以后进行聚类。其中,轨迹的形状特征需要进行Min-Max归一化后,才能送入到聚类算法中进行聚类。例如,对于第i条轨迹的复杂度di表示为: (15) 在进行归一化以后,就可以对归一化以后的特征进行聚类,从而获取特征聚类的结果。 获取了加权联合相关矩阵之后,任意一种聚类算法都可以被用来对集成以后的结果进行聚类。本文仍然采用谱聚类对轨迹集成结果进行聚类,其中加权联合相关矩阵作为谱聚类的邻接矩阵。最后一步采用谱聚类,一方面是因为谱聚类能够应对非凸聚类问题,另一方面,Liu等[20]提出的针对联合相关矩阵的谱聚类通过特征编码的方式将问题转换为加权K-means聚类问题,从而在保证同等质量的前提下降低了时间复杂度。在完成最后一步的谱聚类后,可以获得Nc个轨迹聚类。 在集成聚类之后,训练数据中的每一条轨迹都将拥有聚类标签,但是这些轨迹聚类的数目与实际路径的数目不一致。主要原因在于在不同场景中,并不知道真实的路径个数Nr,只能保证指定的聚类数目Nc>>Nr,即聚类可能存在冗余。为此,需要对聚类后的轨迹进行进一步处理,以获得场景中实际的路径数目Nr。 轨迹聚类的合并分为两步:(1) 针对每一个聚类的轨迹,提取该轨迹的聚类原型,聚类原型为该聚类中最具有代表性的轨迹。(2) 利用聚类原型将相似的聚类合并,从而得到场景的路径信息。 在聚类原型提取中,一般选取同一聚类的平均轨迹作为聚类的代表,即聚类原型。轨迹的平均需要将聚类内的轨迹进行插值得到等长轨迹才能进行。Morris等[9]借助插值的策略提取了平均轨迹,并基于平均轨迹间的DTW距离对聚类进行了合并。以平均轨迹作为聚类原型会带来两个问题:(1) 聚类不可避免地会包含少量的噪声轨迹或是分类错误的轨迹,若是该聚类样本数目比较小,则会对平均轨迹的质量产生较大的影响;(2) 平均法对轨迹的平移,伸缩变换不具有鲁棒性。Paparrizos等[16]讨论了针对时间序列聚类中的聚类中心提取问题,提出若是对时间序列进行时间方向的平移或是伸缩变换,则平均的时间序列将不具有稳定性,这里针对轨迹也是一样的效果。针对这些问题,本文引入图的拉普拉斯能量的思想[11],对聚类原型进行提取。 图G的拉普拉斯能量:给定图G的邻接矩阵A和度矩阵D,计算拉普拉斯矩阵L=D-A,则图G的拉普拉斯能量定义为: (16) 式中:λ1,λ2,…,λM是拉普拉斯矩阵的特征值。 图G的节点vi的拉普拉斯中心性:给定图G,删除连接节点vi的所有边之后的图记为Gi,则给定节点vi∈G的拉普拉斯中心性hi定义为: (17) Kij=I(Edit(Pi,Pj)≥ηe) (18) 式中:I(·)代表指示函数;Edit(Pi,Pj)代表编辑距离[22]。采用编辑距离是因为编辑距离能够被很好地归一化到0到1的区间,方便ηe的取值。在获取矩阵K之后,使用深度优先搜索对连通子图进行搜索,属于同一子图的聚类将被合并在一起,并重新根据轨迹属于路径的情况提取聚类原型。本文ηe的取值为0.9,代表聚类原型之间至少有90%的点匹配时,才将二者进行合并,这也意味着给定严格的合并条件能取得鲁棒的效果。 针对所提出的方法,采用西安市2个交叉口的轨迹数据进行实验分析。实验环境为Ubuntu 18.04 LTS系统,处理器为Intel Xeon(R) E3-1230v3,内存20 GB,软件平台使用到了基于Python的Anaconda集成环境。数据集的相关特性如表1所示。 表1 两个轨迹数据集基本信息 图6与图7显示了两个场景中提取的路径,可以看出场景具有非常复杂的运动模式。其中数据集JYGY采集于早高峰8点到9点左右,场景拥有24条路径;HJDS数据集包含28条路径。实验的评估标准采用的是V-measure[17]。V-measure是一种基于熵的聚类质量度量,取值范围在0到1之间。并且使用V-measure需要预先知道样本的聚类标签与真实类标签,V-measure值越高越好。 图6 JYGY数据集路径(24条路径) 图7 HJDS数据集路径(28条路径) 针对轨迹数据集成聚类的效果进行实验。首先对数据集分别进行基于特征的聚类与基于距离度量的聚类,从而生成一系列的基聚类。每个方法聚类的数目从30个一直到50个,所以生成的基聚类的组数N=40。这样保证了各个聚类的数目Nc大于场景潜在的路径数目Nr。在获得基聚类之后,利用所有获得的基聚类,参照式(12)构建了加权联合相关矩阵,并运用谱聚类对其进行聚类,获取了集成聚类的类标签。对于集成聚类而言,其聚类的数目从30个变化到50个,方便与之前的结果进行对比。并且针对基于距离度量的聚类算法与基于特征的聚类算法也进行了集成,用以验证集成聚类的效果并非只受到单一聚类方式集成的影响。 图8是聚类数目从30变化到50的时候,各组方法的V-measure分数的变化情况。可以看出,单独使用结合DTW距离的谱聚类时,其聚类效果并不稳定,随着聚类个数的变化聚类分数发生波动,这主要是由于对于邻接矩阵的高斯核参数调整不当造成的。但是对其进行集成聚类之后,其聚类效果与稳定性都有大幅的提升,这也说明聚类集成能够提升聚类质量。就聚类分数而言,轨迹的特征工程配合层次聚类的方法取得的结果最为稳定,随着聚类数目的变化,其V-measure分数没有发生太大的波动。但是事实上该方法在设计损失函数时,没有对聚类包含的样本数目进行约束,因此容易受到噪声的影响从而切分出单条轨迹作为聚类,并且由于前者的原因,基聚类之间的差异性也较低,导致集成结果不明显。对于两种方法结合的集成聚类算法,在聚类效果上与基于特征的集成结果类似,但是其集成后分数的稳定性高,并在部分指定聚类数目下超越了之前的所有方法。 (a) JYGY数据集聚类结果 (b) HJDS数据集聚类结果图8 两个数据集的聚类结果 集成聚类对低质量聚类的加入也具有较高的鲁棒性。图9是通过调整超参数,降低谱聚类分数之后得到的集成的结果。可以看到在谱聚类结果的质量较低的情况下,集成的结果仍然保持了非常高的准确性,表明二者结合的集成策略具有较高的精度与鲁棒性。 图9 HJDS数据集聚类融合低质聚类的结果 在获取了轨迹的各个聚类之后,对各个聚类的聚类原型进行了提取。这里已经获取了聚类的标签,因此可以依据聚类标签对实现进行谱聚类的邻接矩阵A进行分解为子图的邻接矩阵,并按照式(17),计算子图每一结点的拉普拉斯中心性,选取中心性最高的轨迹作为聚类的聚类原型。 图10与图11分别为两个场景下的任意5个轨迹聚类与其聚类原型。聚类原型通常为聚类最具代表性的轨迹,例如聚类的平均轨迹。若将每一条聚类中的轨迹视为图中的一个节点,则聚类原型理应与聚类中其他节点之间的连接的权值之和低,一般来说,这样的节点应当位于聚类的中心。由图10与图11可以看出,算法很好地找到了每一个聚类的中心,并抵御了噪声轨迹的干扰。 图10 JYGY数据集中的5个聚类与其聚类原型 图11 HJDS数据集中的5个聚类原型 在获取了各个轨迹聚类的聚类原型之后,便可以进行聚类原型的合并以获得场景的路径信息。为了对比集成方法对于场景路径获取的有效性,我们通过实验对比了各个方法聚类合并的效果。具体而言,定义命中率(HR)与冗余率(RR): (19) (20) 式(19)中:Nr代表场景实际路径的数目,Nc代表聚类原型的数目,Nh代表Nc中能够与场景实际路径匹配的聚类原型的个数。判断是否匹配的方式为对比合并以后的路径与真实路径的编辑距离是否小于预设阈值,这里阈值被设定为0.9以确保试验结果的可靠性。HR∈[0,1]越高越好,RR代表合并以后剩余的或是缺失路径的比率,越接近0越好。 表2是设定不同数据集、聚类方法与聚类数目的条件下,路径合并后的命中率与冗余率情况。其中集成聚类字样代表路径的提取方式为先进行集成聚类,从集成聚类的结果中提取聚类原型,然后进行聚类合并的操作,以下简称为集成方式;带有特征聚类或是距离字样的聚类方式和前述相似,只是获取聚类的手段是之前提到的基于特征的聚类和基于距离度量的聚类方式,以下分别简称为距离方式与特征方式。 表2 不同聚类数目,不同数据集下的路径提取命中率(HR)/冗余率(RR) 从结果上来看,就路径提取的命中率而言,集成方式与距离方式具有相似的命中率;而特征方式V-measure的分数较高,但是由于忽略了轨迹的时序特性,导致对于路径的提取效果不论是命中率还是冗余率都不如前两种方式。而在JYGY数据集上,经典方式提取的命中率高于集成方式,但是冗余率远高于集成方式,若是考虑低冗余和高命中的话,本文的集成聚类具有较强的优势。 本文提出了一种基于集成聚类的交叉口路径信息挖掘方法。利用基于距离度量的谱聚类算法与基于特征的层次聚类算法的集成,对轨迹进行聚类;针对轨迹的相似性邻接矩阵,引入了拉普拉斯中心性的思想提取了聚类的中心结点。在多个数据集实验中,本文提出的聚类方法具有较强的鲁棒性与较高的精度。在提取路径的实验中,在不降低命中率前提下本文方法具有较低的冗余率。但是,其在时间复杂度方面有待进一步改进。2.2 轨迹形状特征
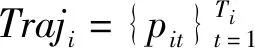
2.3 轨迹相似度
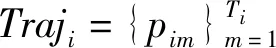

3 路径提取算法
3.1 轨迹的集成聚类策略
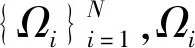
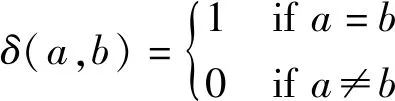
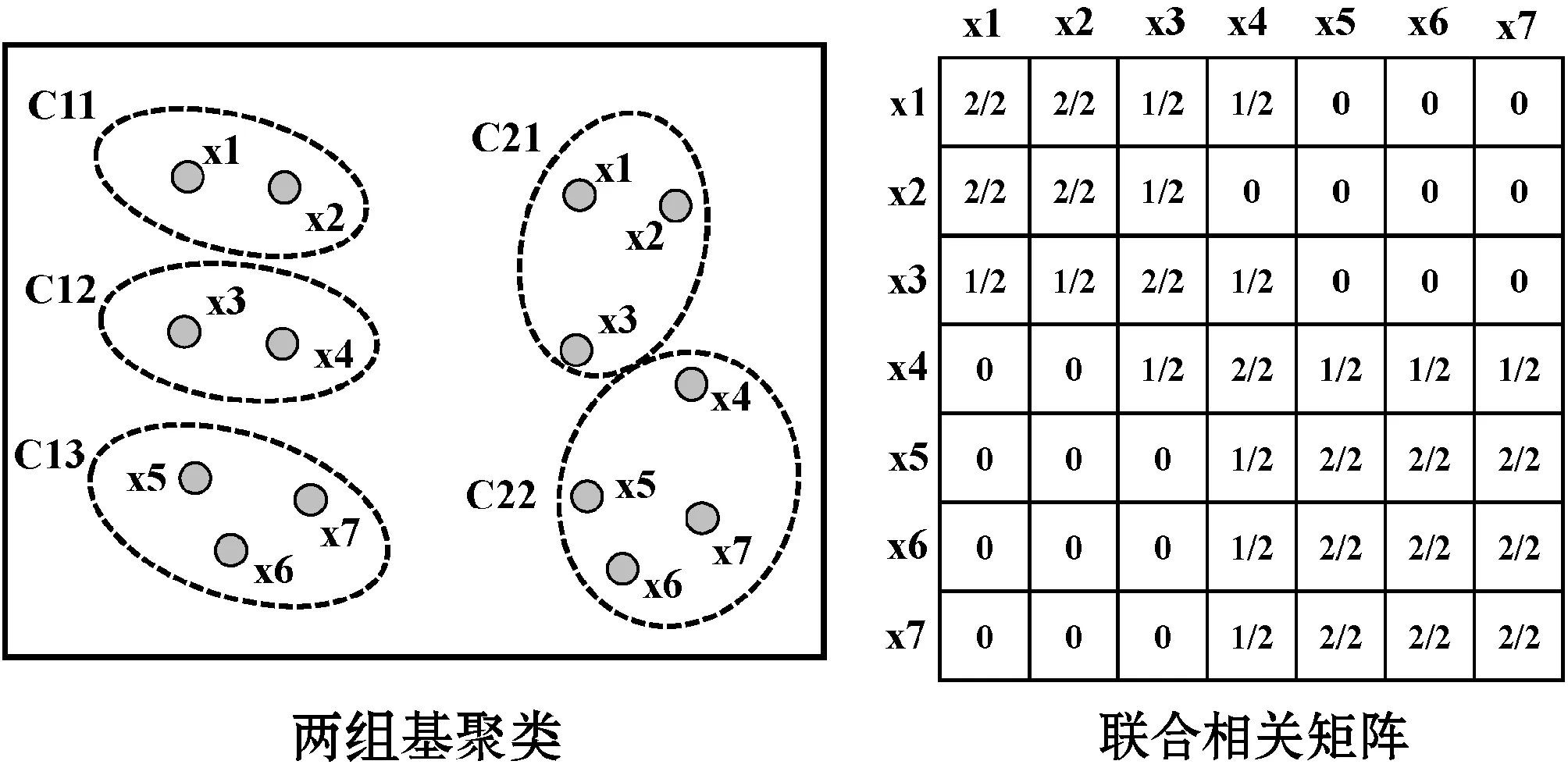
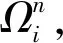


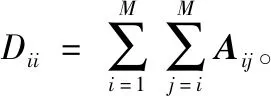
3.2 获取聚类原型
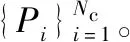
3.3 路径生成
4 实验分析
4.1 实验环境与数据集
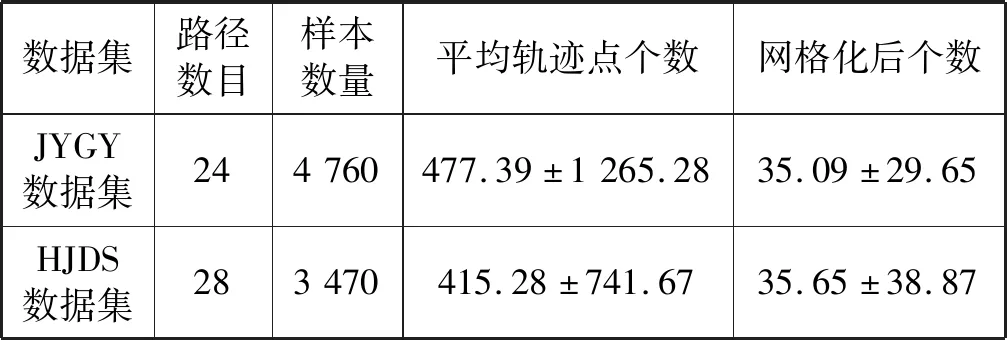


4.2 轨迹集成聚类效果
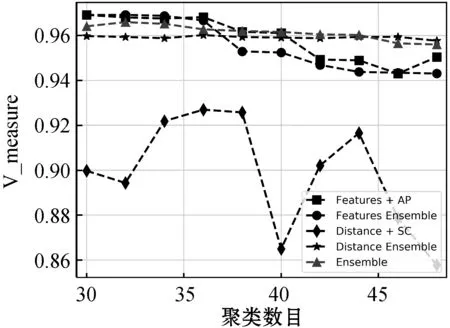
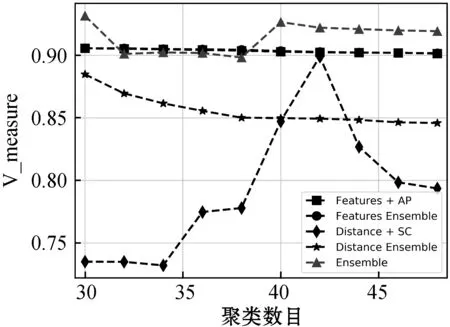
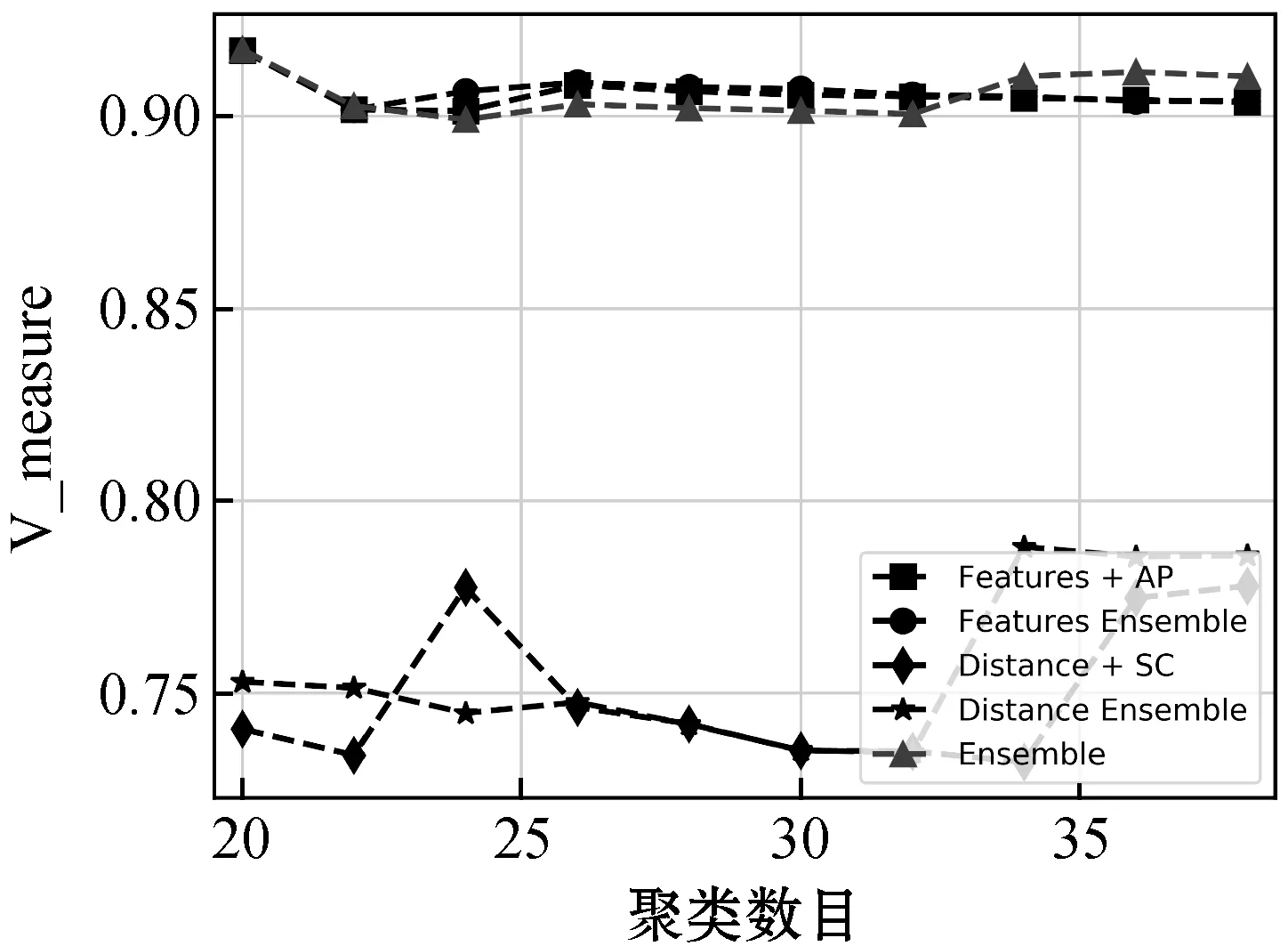
4.3 路径生成实验


5 结 语
猜你喜欢
小资CHIC!ELEGANCE(2021年45期)2021-01-11 03:51:12
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
英美文学研究论丛(2018年2期)2018-08-27 01:56:18
现代装饰(2018年5期)2018-05-26 09:09:39
电子测试(2017年15期)2017-12-18 07:19:27
中国三峡(2017年2期)2017-06-09 08:15:29
剑南文学(2016年14期)2016-08-22 03:37:42
人间(2015年20期)2016-01-04 12:47:08
智能系统学报(2015年4期)2015-12-27 09:38:39
