
基于多层感知机的密封继电器PIND信号识别
2020-07-14 10:43蒋爱平杨世华薛永越王国涛
宇航计测技术 2020年2期
李 响 蒋爱平 杨世华 薛永越 王国涛,2
(1.黑龙江大学电子工程学院,哈尔滨 150008;2.哈尔滨工业大学电器与电子可靠性研究所,哈尔滨 150001;3.上海航天设备制造总厂有限公司,上海 200245)
1 引 言
在密封电子元器件的生产过程中,由于设计水平工艺条件的限制,会由于各种外界原因,引入材质不同大小不一的多余物颗粒[1]。某些多余物颗粒在航天继电器使用之前的各项检测中未被检测出来,残留在腔体内部的某个部位未被发现。在航天使用的过程中,由于受到外界环境的影响被激活,游离于腔体内,对器件产生严重危害[2~4]。一旦未检测出密封继电器内的多余物就会造成不可预知的影响。在目前的设计水平、工艺条件下很难完全避免多余物的产生。因此,在密封电子元器件使用之前对其进行多余物检测可以较好地提高设备和模块的工作可靠性,降低故障率。
现阶段使用的相关鉴定方法主要包括:显微镜观察法、X光照相法、MATARA方法及微粒碰撞噪声检测(Particle Impact Noise Detection,PIND)法等[5]。其中,PIND检测方法是目前主要的检测方法,经常用于各种密封电子元器件的出厂检测[6]。经过长期的发展和完善,该检测方法日渐成熟,但是PIND方法的检测精度并不理想,有多种影响因素,其中组件信号干扰是导致检测精度不高的重要原因[7]。组件信号是在外部正弦振动激励下,试件内部可动部件产生受迫振动而检测到的固有机械信号。
学者前期在对PIND试验方法进行拓展研究时,发现组件信号具有时域上周期性的变化[8]。高宏亮在前人研究的基础上,进一步针对航天继电器多余物检测中组件信号展开了研究,同样认为组件脉冲总是等周期的出现。基于该特性,认为得到对应脉冲发生时刻序列近似为等差序列,时间间隔序列则近似为常数序列[9]。乌英嘎等对组件信号频谱特性做过进一步的研究,认为组件信号的频谱相对于多余物信号较窄[10]。
目前针对组件信号与多余物信号的检测方法,只是依靠单一时域特性(周期性)的相似度进行聚类。但大量实验数据表明,单个组件信号脉冲特征不论在时域还是频域和多余物信号脉冲特征的相似程度较高,区分二者较为困难;另外,以往对密封电子元器件组件信号的研究和分类不够深入,认为组件信号的表现形式仅为不同周期内连续存在的单组脉冲序列,而实际上要复杂的多;这些因素都会导致某些组件信号被误判为多余物信号。并且跟据检测现场的统计结果,目前广泛使用的4511系列和DZJC系列多余物检测系统,对多余物信号和组件信号的识别准确率约为75%,误判率较高。为降低组件信号和多余物信号的误识别率,提高多余物检测精度,本文在总结前人研究的基础上,分析现存有待解决的问题,提出了以下的识别方法。
文中提出一种基于多层感知机神经网络的多维条件下密封继电器PIND信号识别方法,首先对多余物信号和组件信号的产生原理进行分析并其进行信号特征提取和选择。然后建立了基于多层感知机的密封继电器PIND信号识别模型,并根据多维条件下影响密封继电器PIND信号检测准确度变动数据的具体特征,对神经网络模型采取网络结构优化和参数针对性调整。最后使用测试样本集进行改进后模型的验证,实验结果验证了该模型的准确性和有效性。
2 试验数据的获取
本文使用的数据集是由元器件生产方提供的检测数据和研究人员自行采集的试验数据共同组成的。所有试验数据均使用哈尔滨工业大学设计的DZJC-III型多余物自动检测系统采集,该系统如图1所示。在检测系统中对传入的被检测声音信号进行处理,建立检测信号的数据样本集[7]。

图1 DZJC-III型多余物自动检测系统
3 多余物信号与组件信号的特征分析
3.1 多余物信号与组件信号介绍
多余物信号是已经被激活多余物微粒与密封电子元器件内部相关组成机构或密封内壁碰撞产生的。振动发声信号是通过声发射传感器以一定的电压量表现出来的信号。在每次碰撞过程中,随机产生一个单边震荡衰减的脉冲。多余物信号主要表现为随机性的尖峰脉冲序列,单个脉冲呈单边振荡衰减趋势,即脉冲初始幅值上升速度快,当其达到一定峰值迅速衰减。
组件信号是密封电子元器件可动组件自行振动激活所产生的信号。组件信号主要表现为具有周期性尖峰脉冲序列,必须具有一定的起振过程才能使可动部件被激活,当外界冲击消失,其又需要一定的时间才能回到静止状态。典型的多余物信号脉冲序列和组件信号脉冲序列如图2所示。
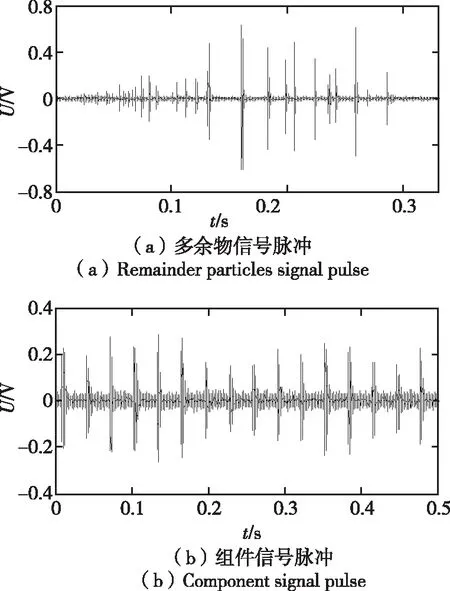
图2 典型多余物信号脉冲序列和组件信号脉冲序列
由于多余物信号和组件信号有以上的差异,可以利用这些差异对二者进行区分,分别从时域和频域两方面计算信号特征。
3.2 多余物信号与组件信号的特征选择
对检测系统提取到的脉冲信号由MATLAB程序,将脉冲处理成可用的数据,对数据清洗,去除异常值后进行特征选择。
在特征选择中我们主要从以下角度考虑:特征是否发散;特征越发散对样本的群分能力越强。特征与目标的相关性;与目标相关性高的特征,应当优先选择。总的来说特征选择是选择与目标相关性强、且特征彼此间相关性弱的特征子集[11,12]。
我们分别从时域和频域两方面统计收集了近年来常用的且具有代表性的14个特征,并对这14个特征进行特征选择。本文选用了两种方法分别是卡方检验和基于树模型的特征选择方法。卡方检验法的目标就是检验特征与分类目标的相关性程度。卡方检验值越大,相关性越强。选用基于树模型的特征选择方法目的是计算每个特征对模型的重要程度。试验结果如图3所示。由图可知特征zerorate在卡方检验中得分最高,说明其与分类目标的相关性最强。MSFcha特征对于模型分类准确度影响最为重要。

图3 特征选择结果图
本文还尝试采用PCA对数据特征进行了数据降维,用处理后的四维特征数据进行模型训练后发现,虽然整体的准确率有所提高,但是多余物信号的召回率、精度、以及F1-score值都明显低于经过卡方检验和基于树模型所选出的特征所进行训练后的结果。在分类器模型评价时,仅选用准确率这一单一评价指标不足以表明分类器的提升程度和整体性能。并且PCA方法所获得的主成分特征的物理意义不明确,对后续研究的特征工程不能给出很好的启示作用。因此本文在特征选择方面没有使用PCA方法。
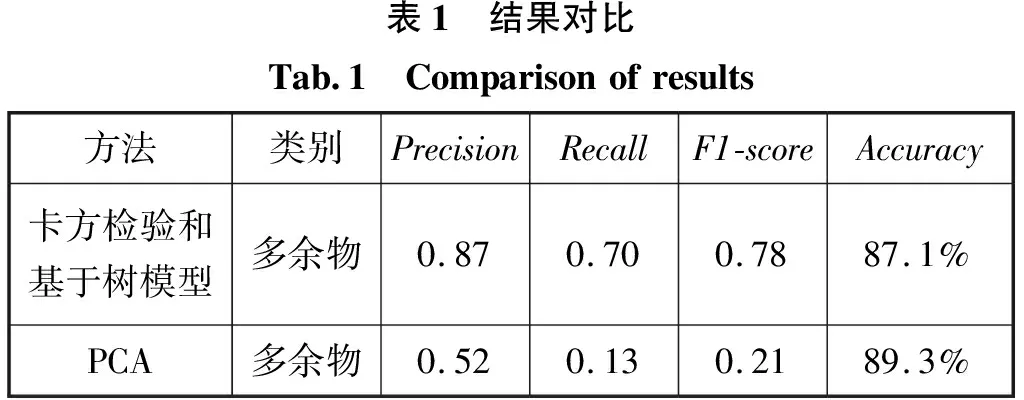
表1 结果对比Tab.1 Comparisonofresults方法类别PrecisionRecallF1-scoreAccuracy卡方检验和基于树模型多余物0.870.700.7887.1%PCA多余物0.520.130.2189.3%
如表1所示,通过对比分析试验结果且综合考虑各个特征的区分度和计算速度,选取出了以下四个特征分别为频谱质心s、频率均方根MSFcha、峰值因子bf、过零率Zerorate。
频谱质心s表现了信号脉冲的集中程度和集中位置如公式(1)所示:
(1)
式中:f2——频谱下限截止频率;f1——频谱下限截止频率;f——信号脉冲;X(f)——信号的频率幅度谱。
频率均方根MSFcha即对单个脉冲的频谱数据计算其具体的方差,其表示频率对于其中心频率的离散程度如公式(2)所示:
(2)
式中:PSD——已知功率谱密度的离散信号;N2、N1——分别是起始和终止信号。
峰值因子bf表现了峰值在波形中的极端程度如公式(3)所示:
(3)
式中:Vmax——PIND信号的峰值电压;VRMS——PIND信号的电压有效值。
过零率Zerorate表示单位时间内信号通过零点的次数如公式(4)所示:
(4)
式中:N——一帧的长度;sgn[]——符号函数;Sω(n)——输入信号。
4 模型的构建与测试
卷积神经网络(Convolutional Neural Networks)适合处理大型图像等复杂的情况,特征维数多,数据量大的样本。本文样本数据数量以及特征维数较少,使用复杂的模型使得网络结构复杂化,不仅增加了网络模型的训练时间,同时也更容易使模型出现过拟合现象。相对比多层感知机模型结构更灵活,所实现功能更适合于本文样本数据。
多层感知机(Multilayer Perceptron,MLP)的结构如图4所示,除了第一层的输入层和最后一层的输出层,它中间可以有多个隐含层,不同层之间是全连接的。多层感知机是一种误差反向传播的多层前馈神经网络算法。在隐含层中通过选用不同的激活函数能够给神经元引入非线性因素,这样可以将神经网络运用到更多的非线性模型中。

图4 多层感知机结构图
4.1 试验数据
本文使用的数据集是由元器件生产方提供的检测数据和研究人员自行采集的试验数据共同组成的。每条数据由四个特征值和一个分类标签组成,经过预处理后共包括196297组数据,其中多余物数据63611组,组件数据132686组,按3∶1的比例随机抽取出训练集和测试集。数据集的具体描述如表2所示。

表2 样本数据信息Tab.2 Sampledatainformation多余物个数组件个数总数训练集4770799515147222测试集159043317149075总数63611132686196297
在训练模型过程中要输入多维特征数据,但由于特征性质的不同,特征的数值范围会相差很大,一些过大或过小的数据会影响模型的训练,从而影响分类结果。此外,数据分布范围很广也会影响训练结果。所以在训练模型前需要对原始特征数据集进行标准化处理,以保证模型训练结果的准确性。本文将特征中的数值进行标准差标准化,即转换为标准的正态分布。其转化函数为
X*=(x-μ)/σ
(5)
式中:X*——标准化后的值;x——原始数据值;μ——原始数据的均值;σ——原始数据的标准差。
最后得到的新的数据的均值就是0,方差1。
4.2 评价指标
在分类器模型评价时,仅选用准确率这一单一评价指标不足以表明分类器的提升程度和整体性能,所以选用召回率(Recall)、精度(Precision)作为评价指标。
Accuracy=(TP+TN)/(TP+FN+FP+TN)
(6)
式中:Accuracy——准确率;TP——被正确分类的正类样本数量;TN——被正确分类的负类样本的数量;FN——被错误分类的正类样本的数量;FP——被错误分类的负类样本的数量。
Recall=TP/(TP+FN)
(7)
Precision=TP/(TP+FP)
(8)
则精度和召回率的调和均值F1-score:
F1-score=2×(Precision×Recall)/(precision+Recall)
(9)
由于召回率体现了分类模型对正类样本的识别能力。在信号识别领域更加侧重的是信号被正确检测出的概率,也就是分类器模型评价指标中的召回率。而F1-score相当于精度和召回率的综合评价指标,它体现了分类模型的稳健程度。综上考虑,本文在评价分类模型性能时更加注重召回率和F1-score值的变化。
4.3 超参数的选择
超参数是用来确定模型的一些参数。对于神经网络模型的训练来说,超参数的选取起着极其重要的作用[13]。为了使网络模型的结构最优,分类的准确度最高,整体性能最好,本文对隐含层的层数、单层的节点数量(hidden-layer-sizes)、隐含层激活函数(activation)和权重优化算法(solver)这四个常用影响参数进行调优。文中采用网格搜索法搜索多层感知机模型的最佳结构,选取使模型性能最好的超参数组合。
首先对隐含层的层数进行纵向对比选择,不同隐含层数对分类结果的影响如表3所示。
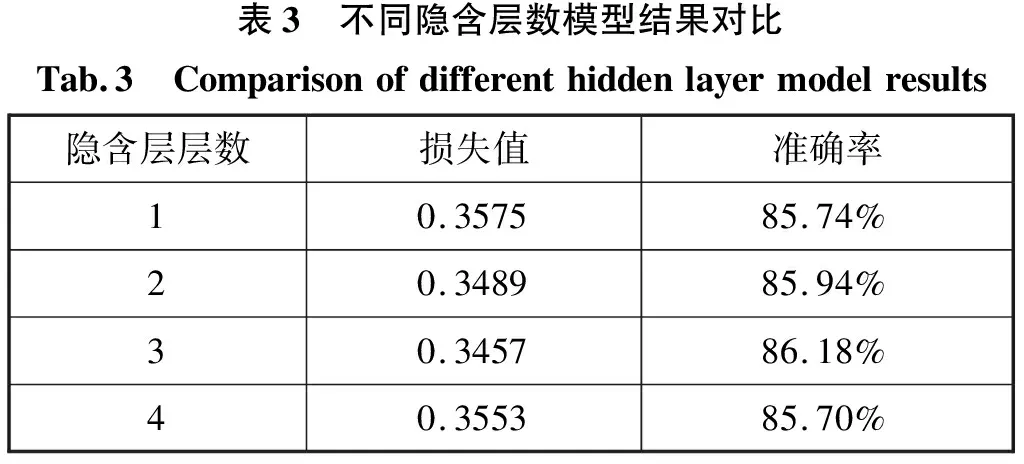
表3 不同隐含层数模型结果对比Tab.3 Comparisonofdifferenthiddenlayermodelresults隐含层层数损失值准确率10.357585.74%20.348985.94%30.345786.18%40.355385.70%
表3比较了隐含层的层数对感知机模型分类性能的影响。从表中可以看出,随着层数的增加,由损失函数计算出的当前损失值在逐渐减小,但当层数为4时损失值上升。同时随着层数的增加准确率也在不断的上升,但在层数为4时准确率下降。这是因为随着隐含层层数的增加使得网络结构复杂化,不仅增加了网络模型的训练时间,同时也更容易使模型出现过拟合现象。结合实验情况和实际情况综合考虑,在隐含层数为2和3时总体性能接近。3层隐含层模型结构较复杂,训练时间较长但性能提升效果不明显,所以最终选择隐含层层数为两层。
然后对单层神经元节点数目进行选择,在这里我们先对单层神经元个数范围进行粗略选择。运用网格搜索法在神经元节点个数范围为[20,211]内进行粗略寻优,初步确定神经元节点个数的最佳范围。实验结果如图5所示。

图5 单一层神经元节点个数性能对比
由图5可以看出神经元节点个数为512时模型整体准确率最高,所以我们可以初步确定神经元节点个数最佳范围为[450,550]。
最后采用网格搜索法对隐含层激活函数和权重优化算法以及精细范围神经元个数进行寻优。
采用交叉验证方法对训练样本进行测试[14],如表4所示。本文设置K=3,即3折交叉验证。经过网格搜索法和交叉验证法对多层感知机在二分类任务中的超参数组合得到调优结果。效果最好超参数(activation,solver,hidden-layer-sizes)分别为(relu,lbfgs,527),在测试集上能达到的最高分类准确率为87.1%。

表4 参数范围选取Tab.4 Parameterrangeselection优化参数名称优化参数范围隐含层激活函数(activation)‘tanh’,‘relu’,‘logistic’权重优化算法(solver)‘sgd’,‘adam’,‘lbfgs’单层的节点数量(hidden-layer-sizes)(450,550)
4.4 试验结果
本文设定神经网络隐含层层数为2,单层神经元个数为527,隐含层激活函数为relu,权重优化算法为lbfgs的超参数组合对49075组测试集数据进行分类。为了验证算法的有效性,同时也使用了机器学习中常用分类算法决策树(DecisionTree)算法进行测试。测试结果如表5所示。
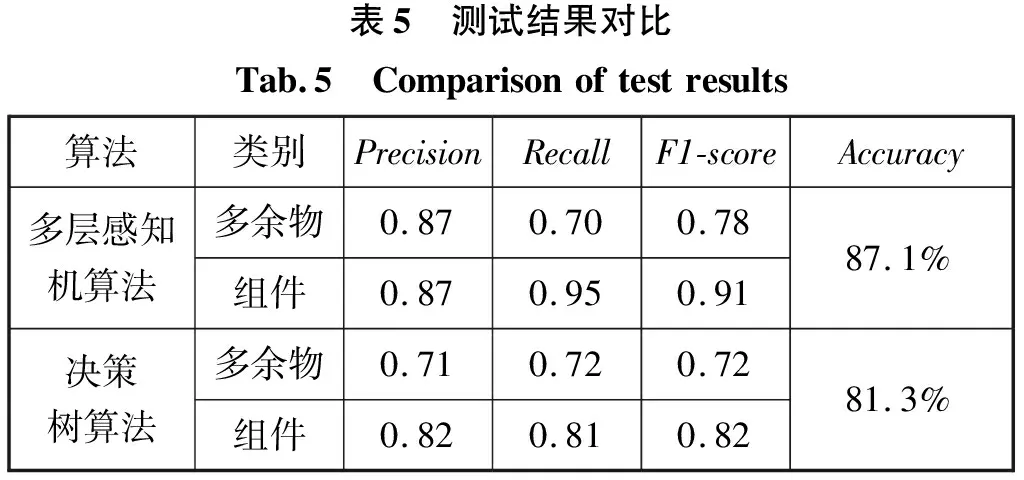
表5 测试结果对比Tab.5 Comparisonoftestresults算法类别PrecisionRecallF1-scoreAccuracy多层感知机算法多余物0.870.700.78组件0.870.950.9187.1%决策树算法多余物0.710.720.72组件0.820.810.8281.3%
通过对比决策树算法证明了运用多层感知机算法检测信号的模型是可靠的。由表5可知运用多层感知机算法对信号进行检测其分类准确率达到87.1%,对多余物和组件信号的检测精度均为0.87,其中组件信号召回率为0.95高于多余物信号召回率为0.7。组件信号F1-score值为0.91高于多余物信号F1-score值为0.78。经初步分析,笔者认为此结果是由于多余物信号样本与组件信号样本数据集不平衡所导致,在后续的研究中会对其进行深入研究。总体来说分类模型的稳健程度较好。
5 结束语
本文提出的基于多层感知机的航天继电器内组件信号识别方法,选取了组件信号和多余物信号时域和频域上的频谱质心、频率均方根、峰值因子、过零率作为特征量。经实验分析后选择了神经网络隐含层层数为2,单层神经元个数为527,隐含层激活函数为relu,权重优化算法为lbfgs的超参数组合建立分类模型。通过试验验证其分类准确率达到87.1%,远高于现有组件信号识别方法的准确率75%,证明了本文提出的方法可以更好的识别组件信号和多余物信号,解决实际工程问题。
在后续的工作和研究中,可基于当前的研究工作对多层感知机的内部其他超参数选择继续研究,从而实现减少识别误差、提高精度、降低运行时间、更为理想的分类效果等。还可以通过选用不同优化参数的算法组合,实现更加精准、更加快速确定最优解,最终实现分类器的优化。
猜你喜欢
商用汽车(2021年4期)2021-10-13
计算机与网络(2021年8期)2021-06-20
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
发明与创新·中学生(2021年4期)2021-04-20
舰船科学技术(2021年12期)2021-03-29
健康体检与管理(2021年10期)2021-01-03
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
