
基于缓冲区技术的增量数据关联规则挖掘算法
2020-07-13 01:12:48刘雯婷
辽宁工业大学学报(自然科学版) 2020年2期
刘雯婷,周 军
基于缓冲区技术的增量数据关联规则挖掘算法
刘雯婷,周 军
(辽宁工业大学 电子与信息工程学院,辽宁 锦州 121001)
利用传统的FP-tree算法对增量数据进行挖掘,需要多次建树,效率较低。CAN-tree算法虽避免了多次建树,但当数据增量改变时,需多次更新树,并且伴随有数据丢失的现象发生。针对以上问题,提出了一种基于缓冲区技术的增量数据关联规则挖掘算法,算法利用缓冲区技术避免数据丢失的情况发生,有效提高关联规则的挖掘效率,实验结果表明算法是有效的。
增量数据;关联规则;缓冲区
随着互联网的飞速发展,大数据和云计算已成为学术界的热点研究对象。伴随信息时代的不断发展,各行业积累了海量数据,人们希望通能够过技术的进步来有效存储并挖掘这些数据,关联规则技术是数据挖掘中的重要部分,主要用于发现事务数据库中项与项间的隐藏联系。目前大多数的增量数据关联规则挖掘算法都是在Apriori算法[1]以及FP-Growth算法[2]上进行改进所得到的。牛海玲等[3]将Apriori算法进行并行处理,引入矩阵从而有效减少扫描数据库的次数,利用局部和全局剪枝方法来减小候选项集数目。易彤等[4]在FP-tree的基础上引入支持度函数概念,避免大量候选项集的生成。程广等[5]将FP-Growth算法与MapReduce方法相结合,提高关联规则挖掘效率。但上述这些改进算法仍存在诸多问题,需要多次扫描数据库,当数据量改变时需重新建树,在挖掘过程中,因为要保存项集信息,需多次递归生成条件FP-tree,浪费大量时间和空间。为克服上述这些问题,Leung等[6]提出了CAN-tree算法,项目按用户指定的顺序(字母序、字典序等)排序后,扫描2次数据库即可完成建树工作。邹力鵾等[7]和陈刚等[8]通过将父子节点结构改为子父节点结构,来提高构造条件模式基的速度。胡军等[9]使用数据量排序替代用户指定的排序方法,提出基于数据量排序的CAN-tree算法,减小树的规模。但上述方法依然不能解决当数据增量到来时由于到达速度过快或处理不及时所造成的数据丢失等问题。针对上述这些问题提出了基于缓冲区的关联规则挖掘算法,能够防止数据丢失并且提高频繁项集挖掘效率。
1 CAN-tree算法
1.1 算法概述
CAN-tree是Leung所提出的针对增量数据关联规则挖掘问题的算法。CAN-tree采用了前缀树结构从而让更多的相同项合并在一起。算法要求事务中的各个项按照某种用户指定的顺序(一般采用字典序、字母序等)排序后再进行构建CAN-tree,这样当新数据到来时可以直接插入到原来的CAN-tree结构中,避免了重新建树和再次扫描数据库,提高关联规则增量更新的效率。
定义1 设项的集合为={1,2,......,i},={1,2,......,t}为事务集合。每条事务t包含的项集为的子集。
定义2 项的集合成为项集,若某项集包含个项,则称其为-项集。
定义4 用户设置最小支持度阈值为minsup,若项集I出现的频率不小于minsup,则项集I为频繁项集[10]。
1.2 算法构建过程
(1)扫描事务数据库DB,获得各数据项以及支持度计数,按指定顺序将事务排序并创建根节点root。
(2)将完成排序的事务逐项按照步骤(3)的方法插入树中。
(3)遍历与事务中项目同名的路径,如果项目所对应的相同节点的父亲结点与插入的项目前项名字相同,则将与相同的结点计数进行加一操作,否则,创建一个新结点,将新结点的计数设置为1并将其链接到具有相同前项名的结点之中。
(4)将事务数据库中的所有数据进行插入操作,完成CAN-tree的构建工作。
2 AB-tree算法
2.1 提出背景
当建立FP-tree时,需扫描数据库来获取各个项的支持度计数及排序,当最小支持度或数据量发生改变时,需要重新建树。CAN-tree算法则与FP-tree算法不同,项的顺序确定后,CAN-tree结构即是唯一的,数据量发生改变或最小支持度改变时,结构不变,但数据量改变时,需要多次更新树,更改树的中每个节点的支持度计数,浪费资源,并且伴随有数据丢失的情况出现。
针对上述问题提出了一种基于缓冲区技术的AB-tree算法,通过缓冲区防止数据丢失的情况发生并且提高挖掘效率。缓冲区是指在内存中预留出指定大小的空间用来对输入(输出)的数据进行临时存储。使用缓冲区技术能减少实际物理读写次数,创建缓冲区时就分配好内存,可重复使用,有效减少动态分配和回收内存的次数。
2.1 算法伪代码
输入:数据集DB
输出:频繁项集FI
(1)data=preproccess(DB)//预处理数据集,将商品按序编码
(2)tree = createTree(data)//建立CAN-tree
(3)FI_Can = findFI(tree)//查找CAN-tree中频繁项集大于最小支持度的项集
(4)If Cache_size >= Cache_threshold: //如果缓冲区中数据的数量大于预设值
(5)FI = FUP (FI_Can. FI_AB)//通过FUP算法查找满足条件的频繁项集FI
图1和图2分别为CAN-tree算法以及AB-tree算法处理数据的流程。
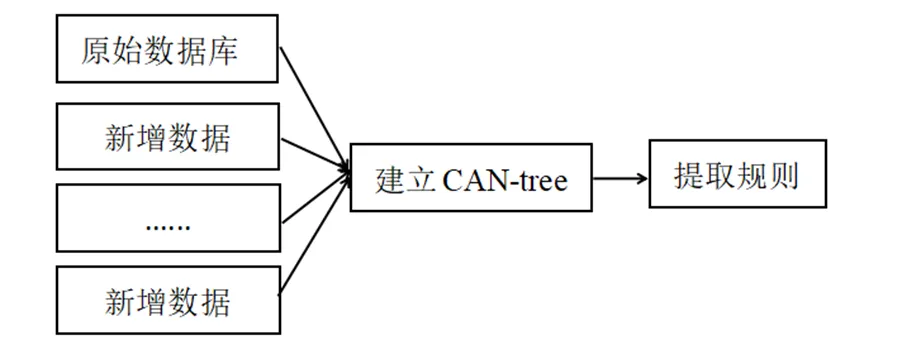
图1 CAN-tree算法处理流程

图2 AB-tree算法处理流程
从中可以看到,采用传统的CAN-tree算法时,每增加1条数据,需要更新树中节点计数,当数据大量快速到达时,容易造成数据丢失;当新数据到达时间间隔较大时,需要等待较长时间。AB-tree算法利用缓冲区技术,有效避免数据丢失现象发生,当新数据到达时间间隔较大时,由于并行处理,可以提高算法的挖掘效率。
3 实验结果及分析
3.1 建树过程
假设原始数据库如表1所示,扫描1次数据库,获得每个项集的支持度计数如表2所示并建立如图3所示的CAN-tree,设置最小支持度minsup=10%。

表1 原始数据库DB
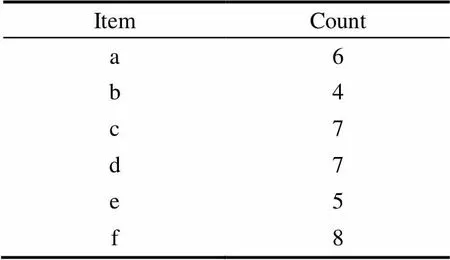
表2 项的支持度计数
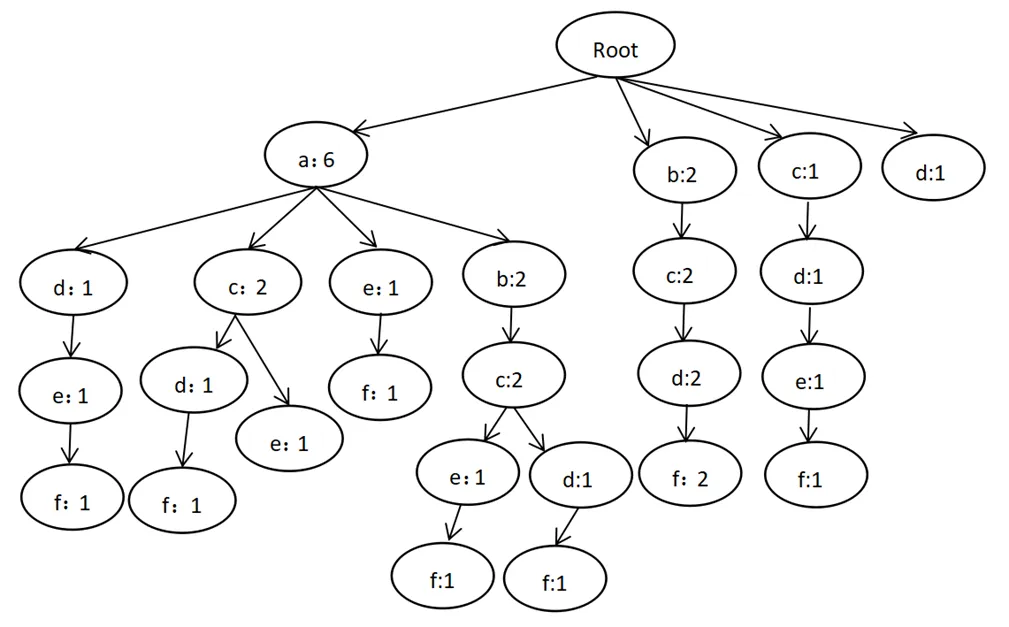
图3 CAN-tree
根据扫描数据库后得到的各项支持度计数以及最小支持度阈值(即≥3.7),求得频繁一项集为{a} {b} {c} {d} {e} {f},通过频繁一项集构造候选二项集为{a,b} {a,c} {a,d} {a,e} {a,f} {b,c} {b,d} {b,e} {b,f}{c,d} {c,e} {c,f} {d,e} {d,f}{e,f},扫描CAN-tree,得到候选二项集中每个项出现的次数并将其所占的比率与所设定的minsup进行比较,大于minsup的即为频繁二项集,上述例子中L2={{a,c} {a,e} {a,f} {b,c} {b,f} {c,d} {c,f} {d,f} {e,f}}同理,频繁三项集{c,d,f}。
3.2 增量数据的处理
随着信息时代的发展,要求对数据的处理要更加迅速准确。由于增量数据随时间变化不断更新且数据量巨大,因此只能对数据进行有限次数的扫描,而且不能将其全部放入内存之中,往往只能选中其中重要的数据将其存入计算机中[11]。许多人选择滑动窗口技术来解决增量数据的更新问题,但当窗口滑动时,要删除树中原有的旧事物中的项,需频繁更新树结构,开销巨大。为了解决上述问题,本文采用了缓冲区技术,预留出指定空间来对更新的数据进行存储,避免频繁更新树结构以及数据丢失从而提高算法效率。将新增的每一条数据存入缓冲区,设置缓冲区大小为5。新增数据库如表3所示。

表3 新增数据库db
建树与挖掘过程与原始数据库一致,最终得到频繁项集为{a} {c} {d} {e} {c,e} {d,e}。
增量数据与静态数据有所不同,具有实时性并且与静态数据挖掘相比过程更加复杂,一些在原数据库中偶然发生的事务,在接下来的时间段内很可能经常发生。本文利用频繁项集的性质:若数据库由若干部所分组成,其中一个项集是频繁项集,则它至少在一个部分中是频繁的。证明过程如下。
假设项集L为数据库DB中的频繁项集,但L在DB的每个部分中都是非频繁项集,设最小支持度为s,DB的元素总数为n,DB中每一部分的元素个数分别为12...。
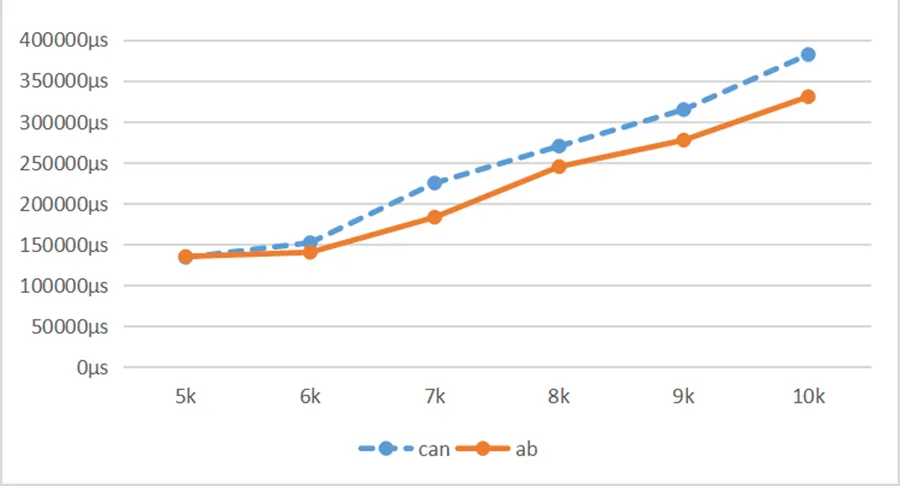
证明 设L为数据库S中的频繁项集,数据库S由原始数据库S1和新增数据库S2构成,若L在S1和S2中均为非频繁项集,则L在S1和S2中支持度分别小于s*S1、s*S2,则S的总支持度S.count 设原始数据库为DB,新增数据库为db,当数据更新时,会出现下面4种情况:(1)项集c在DB和db中均为频繁项集;(2)项集c在DB中为频繁项集,在db中为非频繁项;(3)项集c在db中为频繁项集,在DB中为非频繁项;(4)项集c在DB和db中均为非频繁项集。 在(1)的情况下,c一定为频繁项集,(4)的情况下,c一定为非频繁项集,对于情况(2)和(3),利用公式,确定c是否为频繁项集。上述例子的频繁项集为{a} {c} {d} {e} {f} {a,c} {a,e} {a,f} {c,d} {c,f} {d,f} {c,e}。 实验数据由数据模拟器产生,设置最小支持度为10%,缓冲区大小设置为1 000。实验环境如下:Intel(R) Xeon(R) CPU@2.30 GHz,内存大小为13 GB,操作系统为Linux,开发环境为Python。 实验从2方面进行,一方面比较本文算法与CAN-tree算法的建树时间,另一方面比较AB-Tree算法与CAN-tree算法挖掘关联规则的时间,从图4可以看出当数据增量式到来时,由于CAN-tree算法需要随着数据到达更新树中节点的计数,时间较长;而本文提出的算法,由于利用缓冲区技术并行计算,随着数据量增多,算法优势明显。从图5可以看出,由于本文无需构建频繁模式基,挖掘频繁项集的时间小于CAN-tree算法,并且本文算法随着数据到达的时间间隔增大,优势更加明显。 图4 算法建树时间对比图 图5 算法挖掘时间对比图 提出了一种基于缓冲区的增量数据关联规则挖掘算法,该算法的主要特点为利用缓冲区技术实现并行计算,提高挖掘效率的同时能够有效防止数据丢失的现象发生并且随着数据到达时间间隔增大,优势更加明显,实验结果表明算法有效。 [1] Agrawal R, Iminelinski T, Swami A. Mining association rules between sets of items in large databases[C]//ACM SIGMOD Record. ACM, Washington, D. C, 1993: 207-216. [2] Ghemawat S, Gobioff H, Leung Shun-tak. The Google FileSystem [C]//Proceedings of the 19th Symposium on Operating Systems Principles. New York, USA: ACM Press, 2003: 29-43. [3] 牛海玲. 鲁慧民, 刘振杰. 基于Spark的Apriori算法的改进[J]. 东北师大学报: 自然科学版, 2016(1): 84-89. [4] 易彤, 徐宝文, 吴方君. 一种基于FP树的挖掘关联规则的增量更新算法[J]. 计算机学报, 2004, 27(5): 703-710. [5] 程广, 王晓峰. 基于MapReduce的并行关联规则增量更新算法[J]. 计算机工程, 2016(2): 21-32. [6] Leung C K S, Khan Q I, Hoque T. CanTree: a tree structure for efficient incremental mining of frequent patterns[C]// Fifth IEEE International Conference on Data Mining (ICDM'05), IEEE, 2005: 8. [7] 邹力鹍, 张其善. 基于CAN-树的高效关联规则增量挖掘算法[J]. 计算机工程, 2008, 34(3): 29-31. [8] 陈刚, 闫英战, 刘秉权. 一种基于CAN-tree快速构建算法[J]. 微电子学与计算机, 2014(1): 76-82. [9] 胡军,潘皓安. 基于Can树的关联规则增量跟新算法改进[J]. 重庆邮电大学学报: 自然科学版, 2018, 30(4): 558-563. [10] Jiawei Han, Micheline Kamber, Jian Pei, 等. 数据挖掘概念与技术[M]. 机械工业出版社, 2012: 159-160. [11] Wang H, Li F, Tang D, et al. Research on data stream mining algorithm for frequent itemsets based on sliding window model[C]//IEEE, International Conference on Big Data Analysis. IEEE, 2017: 259-263. Algorithm in Mining Incremental Data Association Rules Based on Buffer Technology LIU Wen-ting, ZHOU Jun (School of Electronics & Information Engineering, Liaoning University of Technology, Jinzhou 121001, China) Using traditional FP-tree Algorithm to mine incremental data requires building trees many times, which is inefficient. Although tree algorithm can avoid building trees many times, it needs to update trees many times when the data increment changes, and the phenomenon of data loss occurs. To solve the above problems, algorithm in mining incremental data association rules based on buffer technology is proposed. The algorithm uses buffer technology to avoid data loss and effectively improve the efficiency of mining association rules. The correctness of the algorithm can be proved by experiments. incremental data; association rules; buffer technology TP301.6 A 1674-3261(2020)02-0071-04 10.15916/j.issn1674-3261.2020.02.001 2019-12-11 辽宁省科学技术基金(201602372) 刘雯婷(1995-),女,辽宁锦州人,硕士生。 周 军(1964-),女,辽宁锦州人,教授,博士。 责任编校:孙 林3.3 实验及结果分析

4 结束语
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
项目管理技术(2015年3期)2015-04-23 08:44:29
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
计算机工程与设计(2012年3期)2012-07-25 11:05:00
电视技术(2012年1期)2012-06-06 08:13:58
