
智能推送技术在在线学习平台中的应用
2020-07-09 22:03金毛玉张洁刘凯
现代信息科技 2020年23期
金毛玉 张洁 刘凯


摘 要:通过实施协作过滤技术,对智能推送技术在在线学习平台中的应用进行了研究,可以成功解决在线学习平台上的智能推送问题,并使用智能推送技术为用户提供更好的在线学习方式。通过该研究,不仅可以调查用户的需求,还可以指导用户在线学习,为不同的用户开发个性化的在线学习推荐服务。该研究主要工作是根据现有的在线学习管理系统和学院的实际情况,设计并实现适合该学院的在线学习推荐子系统,并为学院的学生提供个性化的在线学习推荐服务。
关键词:MySQL数据库;在线学习平台;智能推送
中图分类号:TP311.52 文献标识码:A 文章编号:2096-4706(2020)23-0141-03
Application of Intelligent Push Technology in Online Learning Platform
JIN Maoyu,ZHANG Jie,LIU Kai
(Tianjin Normal University,Tianjin 300387,China)
Abstract:The application of intelligent push technology in online learning platforms has been studied by implementing collaborative filtering technology,which can successfully solve the problem of intelligent push on online learning platforms and use intelligent push technology to provide users with better ways of learning online. This research not only allows investigating usersneeds,but also can instructs users in learning online to develop personalized online learning recommendation services for different users. The main work of the research is to design and implement an online learning recommendation subsystem that is suitable for the college based on the existing online learning management system and the actual situation of the college,and to provide personalized online learning recommendation services for the colleges students.
Keywords:MySQL database;online learning platform;intelligent push
0 引 言
在知识更新迅速的信息社会,信息和知识老化速度的加快都是前所未有的,构建终身学习体系,是国家在信息社会立于不败之地的前提,也是当前社会环境下个人发展的关键。学习型社会的形成,为信息技术的飞速发展、多媒体技术的进步创造了良好环境。在线学习是个性化推荐系统的一个应用方向,可以帮助用户在大规模的视频资源中快速找到满足自己需求的视频。在这种网络信息良莠不齐的情况下,个性化推荐系统相比于搜索引擎,就能满足用户的要求,该系统不需要用户被动查找所需的视频,而是向用户主动推送用户可能感兴趣和有需求的视频。推荐系统通过对用户的历史访问记录进行分析,挖掘出用户潜在的需求,并向其推荐与之相關的视频,使得用户寻找自己所需视频的过程变得便捷。
1 协同过滤算法
1.1 相似度计算
在协同过滤建模中,我们首先要确定如何计算相似度。通常情况下,人们使用泊松相关系数和余弦相似度计量法作为相似度的计算方法。因为泊松系数考虑了评分风格差异对相似度的影响,所以使用泊松系数计算所得的相似度更符合实际情况。
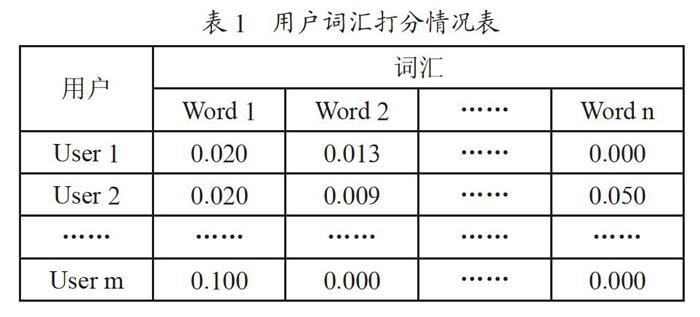
在输入法系统中,不存在用户对词汇进行打分的步骤,所以我们将词频权重作为用户对一个词语打分的具体实现。词频权重指的是在一定范围内该词汇使用频数占所有词汇使用频数的百分比。词频权重的取值范围为[0,1]。
如表1所示n×m的矩阵中,Word为输入法系统中的词汇,User为输入法用户。矩阵中的项代表用户m的个人词库中词汇n的词频权重。若项的值为0,代表对应用户词库中没有相应词汇。
那么根据泊松系数,两个用户之间的相似度计算公式[5]为:
(1)
其中,Sim(u,v)为用户u和用户v的相似度。Iu和Iv分别为用户u和用户v个人词库中所有词汇集合。rui和rvi分别为用户u和用户v的个人词库中词汇i的词频权重。和为用户u和用户v都使用过的词汇集合Iu∩Iv中各个词汇的词频权重的平均值。根据该公式,用户相似度的取值区间为[-1,1],且Sim(u,v)的值越大表示用户u和用户v之间的相似度越高。
1.2 用户聚类
为了使计算机能够自动感知出具有相同输入偏好的用户,并确定其域的范围,我们需要对用户进行自底向上的层次聚类处理。
首先,将所有用户分成若干个组,每个用户就是一个组。
然后,对所有用户组作循环处理。依次计算当前用户组与其他用户组之间的相似度,找到本轮循环中相似度最大且超过预定阈值的两个用户组,将其合并。重复执行本次操作,直到用户组两两之间的相似度都低于预定阈值,循环结束,聚类操作完成。
伪代码为:
threshold = x;
user = {u1,u2...um};
while(true){
maxSim = maxGroupSim(ui,uj);
if( maxSim >= threshold ){
temp = merge(ui ,uj);
user = (user ∪ temp) - (ui ∪ uj);
}else{
return user;
}
}
其中maxGroupSim的作用是求取與当前用户组偏好最相似的用户组的相似度。由于用户组中可能存在多个相似用户,所以用户组之间的相似度计算公式[5]为:
(2)
其中i和j为两个用户组,|i|和|j|分别为这两个用户组里用户的个数,u和v分别表示两个用户组的任意一个用户。GroupSim通过对两个用户组内的所有用户相似度取平均值来计算用户组之间相似度。
2 在线学习推荐系统需求分析
在线学习系统经过多年的自动化建设,已积累了大量的视频浏览信息,为实现视频个性化推荐奠定了一定的物质基础。
经过多年的发展,联合过滤技术已经建立了较为完整的技术体系,实现了令人满意的进步,尤其是在数据生产、数据挖掘、数据分析和互联网处理技术方面。这为在线学习推荐系统奠定了技术基础。通过使用数据挖掘技术从数据库中收集历史数据,可以确定各种视频资源的相关性。我们通过数据挖掘技术分析读者的喜好,并根据他们的观看行为个性化地推荐视频。同时,您可以采用有针对性的网站管理策略,以便为视频学习网站提供更好的客户资源。
3 详细设计与实现
3.1 数据库和Java Web的连接
JDBC(Java数据库连接性)是用于实现SQL语音的Java API。它可以提供对由多个用Java编写的类和接口组成的相关数据库的统一访问,JDBC为工具/数据库开发人员提供了标准的API。基于此,可以创建高级工具和界面。数据库开发人员可以使用纯Java API来构建数据库应用程序。图1显示了JDBC驱动程序连接图。
将与JDBC数据库相对应的JAR文件复制到Web应用程序的WEB-INF\lib目录中。MySQL驱动程序包含文件MySql-connector-java.jar。该文件应位于Web浏览器的WEB-INF\lib目录中。
连接为Connection con=DriverManager.getConnection("jdbc: odbc:bbs")。通过getConnection生成提示包括URL,登录名,密码。配置文件如图2所示(其中,jdbc.username和jdbc.password的值应与数据库设置匹配)。
3.2 在线学习管理
管理员起到教学管理员的作用,使系统更接近实际的在线学习系统。管理员登录系统后,输入关键字可以查询在线学习信息,并进行管理。此时,默认情况下,该页面上显示所需的的在线学习视频资源。如图3所示。
单击添加视频按钮,将视频添加到视频列表的顶部。可以转到此页面并添加视频信息。此功能的详细代码在Video UpdateServlet.java中实现。
视频信息录入时需录入包括书名、作者、出版社、ISBN、价格、关键字、图片和备注在内的所有信息。所有在线学习资源都显示在视频列表,如果管理员要编辑(编辑或删除)视频,则选择该视频点击编辑按钮进入编辑界面。
3.4 协同过滤算法的视频推荐
3.4.1 用户数据收集
推荐系统属于协同过滤的电商系统之一,推荐系统是基于海量的数据挖掘之上的一套电子商务系统。因此在推荐系统构建之前,需要对户偏好特征数据进行分析。
若想要构建一套较为理想的推荐系统,使其能够根据不同的数据给出不同的推荐结果。首先需要寻找一种数据结构使系统能够记录用户的观看行为并是程序方便操作,在此使用了Python中的dict(字典)结构,存放的用户观看记录的数据形式为:User:{item1:N,item2:N,item3:N···}。
从记录有用户数据的user_by文件中逐条读入用户观看记录,对每一条用户观看记录,将同一个用户的记录叠加到字典的以该人名为key值下的子级字典中。如此便形成了一个用户观看视频记录的数据集。其偏好数据为用户对某种视频的观看次数记录。用户对某视频观看次数越多,代表着用户越依赖(需要)该种视频。在相似度计算中,同样对该视频有依赖程度的用户在相似性上便高于其他用户,由此该相似用户过去观看的视频可能也更加适合于该用户。
3.4.2 相似性计算
将收集到的用户偏好数据输入到系统中后,系统将数据转化为机器能识别的代表用户偏好的数据,即转变为程序中使用的字典结构。系统用余弦相似度计量法与泊松相关系数法来处理这些偏好数据记录,计算出相似度,再将每个人两两比对来判断其相似程度,根据相似程度来决定是否推荐给当前用户。在前面章节中,我们介绍了推荐系统的相似性计算的几种主要方法,在这里我们使用了余弦相似度计量法与泊松相关系数。
3.4.3 寻找匹配结果
通过上述的相似性算法的计算后,我们得到了两个用户之间的相似程度。接下来主要是提取出评分较高(相似程度较高)的几个用户,找出与用户最为匹配的推荐结果。针对视频推荐系统,可以通过泊松系数计算出与目标用户有相似偏好的使用者。这些视频观看者的视频学习偏好与目标用户较为相似,则两者可能具有较为相似的学习方向,就可以通过这些相似的对视频的偏好来给目标用户推荐视频。在给某用户推荐视频时候,首先推荐系统会计算出一张相似度表,该表中含有与目标用户较为相似的用户,从这张表中我们可以挑选出最匹配的一些用户,给目标用户推荐和他兴趣相似的这些用户喜欢的视频资源。
3.4.4 做出推荐
在通过相似性计算得出与目标用户较为相似的几个邻居用户后,我们可以参考这些相似程度较高的邻居的偏好视频数据。對目标用户进行视频推荐。推荐目标用户尚未学习的视频。
将描述喜好的这几个字词与每个视频中的关键字进行比较,并使用余弦相似度计量法与泊松相关系数来计算每个视频和用户个人资料之间的相似度。系统推荐与当前用户非常相似度高的视频。
4 结 论
使用相关推荐算法对高校在线学习平台数据库中所保存的读者行为信息数据进行归纳和整理,分析读者在利用在线学习平台资源过程中所隐含的、有价值的信息和数据,从而达到学习资源的最大化。
参考文献:
[1] LI W J,XU Y Y,DONG Q,et al. TaDb:A time-aware diffusion-based recommender algorithm [J].International Journal of Modern Physics C,2015,26(9):1-12.
[2] CANDILLIER L,MEYER F,FESSANT F. Designing Specific Weighted Similarity Measures to Improve Collaborative Filtering Systems [C]//ICDM 2008:Advances in Data Mining.Medical Applications,E-Commerce,Marketing,and Theoretical Aspects.Leipzig:Springer,2008:242-255.
[3] AHN H J. A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem [J].Information Sciences,2008,178(1):37-51.
[4] WEI S Y,YE N,ZHANG Q Q. Time-Aware Collaborative Filtering for Recommender Systems [C]//CCPR 2012:Pattern Recognition.Beijing:Springer,2008:242-255.
[5] 周伟,汪少华,杨云.基于数据挖掘和读者行为分析的图书馆荐书系统的研究与设计 [J].图书情报研究,2014,7(4):38-44.
[6] 杨丹丹.利用大数据分析法提高图书馆读者决策采购(PDA)效能探析 [J].图书馆工作与研究,2015(1):60-62.
[7] 张志广,张潇.基于高校图书馆文献采访分布式数据库挖掘的合作协同模式 [J].农业图书情报学刊,2015,27(6):65-68.
作者简介:金毛玉(1998—),女,汉族,浙江江山人,本科在读,研究方向:计算机科学与技术。
