
面向云测试的主机预测技术
2020-07-06 07:57李昌建刘坤晋文明钱巨
计算技术与自动化 2020年2期
李昌建 刘坤 晋文明 钱巨

摘 要:云测试用于云上管理和执行测试任务。由于云上的计算资源能够较为方便的扩展,而负载测试通常需要大量计算资源,因此负载测试非常契合基于云的测试方法。为了保证负载测试能够按照测试计划成功发起,并且不会出现资源不足或闲置,需要在测试执行前确定云上虚拟主机数目,而现有的研究还缺少此类技术。为此,提出了一种面向脚本化负载测试的云主机预测技术,在负载测试开始前执行小规模的负载测试,收集计算资源与测试负载的基础数据,在此基础上使用机器学习方法进行数据训练并预测主机数量。结果表明:提出的主机预测方法能够较好地预测出负载测试所需主机数目。
关键词:云测试;负载测试;测试脚本;主机预测
中图分类号:TP311 文献标识码:A
文章编号:1003—6199(2020)02—0150—05
Abstract:Cloud testing refers to manage and perform testing activities on the cloud. Since computing resources in a cloud can be elastically allocated and load testing often needs large computing resources,it is very suitable for cloud-based methods. In cloud-based load testing,in order to ensure that the loads can be successfully launched according to a test plan without insufficient computing resources and avoid unnecessary wastes on such resources,it is necessary to determine the number of virtual hosts in the cloud used for creating test clients before the testing is performed. However,there lack such technique in the existing research. Therefore,this paper proposes a cloud host number prediction technique for scripted-based load testing. The new approach does small-scale load testing to gather basic data. Then,machine learning methods will be applied to train data and predict the required number of hosts. The results show that the proposed approach is effective for cloud-based load testing.
Key words:cloud testing;load testing;test script;host prediction
負载测试根据指定的性能要求和应用场景,模拟用户操作,对待测系统施加不同的测试负载,监控系统在不同负载情况下的性能指标数据(响应时间、吞吐率和资源利用等),从而评估系统的性能[1]。传统负载测试主要利用本地集群来发起测试,在此方面已经有一些相对成熟的负载测试工具,如Load Runner[2]、Apache Jmeter[3]等,极大方便了负载测试的展开。然而,传统负载测试需要相关技术人员来搭建测试环境、安装部署测试工具,测试过程繁琐。搭建测试环境所需的硬件服务器对中小型企业也是一笔不小的成本,而在测试结束后如无其他计算需求,易使得服务器处于闲置状态,浪费资源。另一方面,若负载规模增长时需要更多的计算资源。计算资源指操作系统及应用程序运行所需的CPU资源、内存资源、网络资源及磁盘资源等,受制于硬件的成本,而不易对计算资源进行扩展。
云测试是解决负载测试难题的一种有效途径。它将测试活动迁移到云上去,用户通过互联网上传测试配置后,由云上的主机执行测试活动。用户只需按需要购买测试服务,而不需要购买昂贵的硬件,且可较为方便对计算资源进行扩展以发起更高的测试负载。在此方面, Ali等[4]提出了基于云的Web应用的性能测试即服务的架构。Banzai[5]提出了D-Cloud云测试系统,通过在虚拟机上注入故障进行容错性测试,解决分布式系统部署后测试困难的问题。在工业界,阿里云性能测试PTS[6]支持以JMeter脚本编写的测试用例,可以轻松模拟大量用户访问业务的场景,任务随时发起,免去搭建和维护成本。腾讯的压测大师LM[7]通过用户定义的URL和Cookies创建多用户的并发场景对软件进行测试,用户无需考虑负载发起主机配置问题。这两个测试工具利用云服务商海量的计算资源来发起测试,虽然能够有效完成测试,但并未讨论测试资源的优化问题,其发起大规模负载的成本较高,不易为中小客户使用。另外,两个测试工具依赖公有云环境来开展测试,其模式也不适用于私有云环境下的测试。
为保证云测试活动中负载测试的服务质量,以及优化虚拟主机的资源消耗,提出了一种面向基于云的测试的主机预测技术,通过小规模负载从测试活动收集计算资源与负载的数据,建立机器学习模型预测测试负载所需的主机数目。
1 预测总体流程
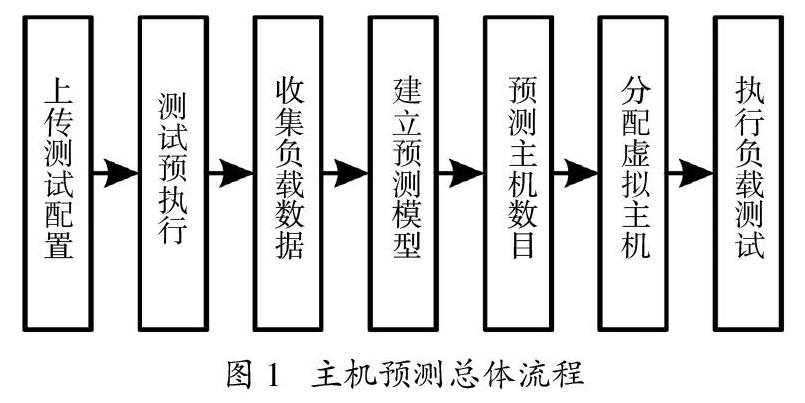
提出了面向云的负载主机的预测总体方法,总体方法通过测试预执行过程收集小规模的负载测试执行数据,通过对负载测试数据进行处理后训练主机预测模型,再使用预测模型预测完成目标负载所需的虚拟主机数,分配好主机数后执行负载测试,最后在负载测试完成后對测试结果进评估,整体预测流程如图3.1所示,以下是对预测流程的介绍。
首先,上传负载测试配置,测试配置包括测试脚本与测试脚本需要执行的负载规模。接着使用已经上传的测试脚本在单台虚拟机上进行小规模负载测试预执行活动,收集测试执行过程中虚拟机的计算资源数据R(包括CPU使用率、内存消耗、网络带宽等性能数据)虚拟机上的负载执行数据LOAD。接着将虚拟主机的性能数据与负载数据按照数据收集的时间点进组合,得到资源与负载融合数据。资源与负载融合数据中的一条数据
接着使用机器学习相关方法对融合后的数据进行学习,建立脚本负载预测模型,模型的输入为脚本的负载规模load,输出为测试达到负载规模load所需要的虚拟主机数目n,即
由于主机数目对负载的变化不十分敏感,本文采用计算资源作为中间变量进行主机数目预测,可通过已收集数据学习计算资源与测试负载的映射关系预测消耗的计算资源为r时可达到的测试负载load,即
在选定虚拟主机配置后虚拟主机的计算资源可用固定的数值表示(如2核CPU,4 GB内存,3 M带宽,40 GB存储等),利用上式求得单机的最大可支持负载,当测试负载超过单机的最大可支持负载时则认为负载测试需要增加新的虚拟主机。
在完成虚拟主机数目n的预测后在云中的测试集群分配n台虚拟主机,接着将测试任务发送给 n台虚拟主机,虚拟主机上运行测试负载并对生成负载的待测应用程序进行监控,收集测试执行信息。最后,对测试结果进行分析,比较不同机器学习方法的预测效果。
2 数据收集
在测试预执行阶段在虚拟主机上收集计算资源与负载的数据,按照时间点将计算资源数据与负载数据构造成资源负载融合数据,以方便使用机器学习方法训练数据。
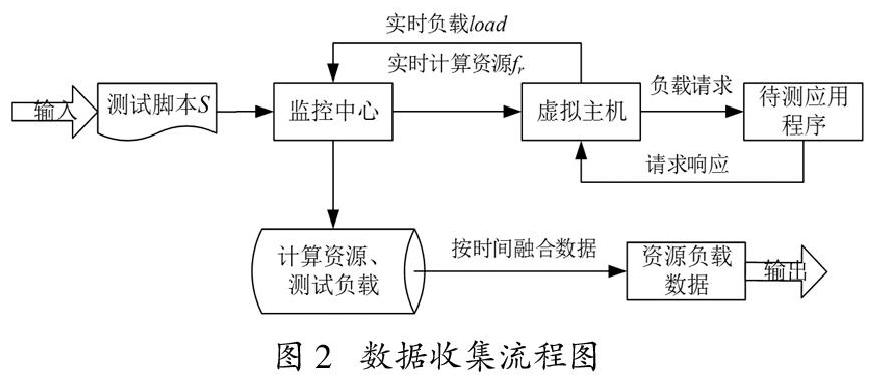
使用测试脚本在单台虚拟机上执行小规模的负载测试活动并实时收集计算资源数据和负载数据,数据收集的输入是负载测试脚本,输出是测试脚本对应的资源负载融合数据。图2给出了负载测试中数据收集的流程图。
首先监控中心模块发起负载测试任务,测试脚本执行任务被发送到虚拟主机中进行。虚拟主机按照监控中心模块下达的测试任务,向待测试应用程序发送业务请求信息,并接收待测应用程序发出的请求响应。测试执行过程中,通过预先安装在虚拟主机上的工具监控虚拟主机的CPU使用率、内存消耗等实时计算资源数据,虚拟主机的负载测试过程中记录负载规模与其发生时间的数据被当作实时负载数据。
监控中心模块通过Web服务接口收集虚拟主机的实时计算资源数据与实时负载数据。将实时计算资源数据[R,Tr]与实时负载数据[LOAD,Tl]作为输入,如果计算资源数据中某一时刻tr对应计算资源为r,而在实时负载数据中同一时刻tl(tr = tl)对应的负载为load,则将计算资源r与负载load组合成资源与负载的数据对
3 负载预测学习方法
本研究需要在资源与负载间关系的基础上预测出一个负载与计算资源映射的函数模型M(r)→load。该函数模型具有以下特点:
(1)输入与输出均是数值型数据,不包含有字符、枚举等类型数据;
(2)输入与输出呈非递减增长,即要得到更多的测试负载需要消耗更多的计算资源;
上述问题本质上是一个数值预测的回归学习问题,当前存在多种支持回归学习的方法,典型方法包括线性回归、支持向量机、神经网络等。由于计算资源与负载的变化关系尚不确定,由单一学习方法进行预测不能保证预测的准确性。使用了当前比较流行的回归学习方法[8]进行数据训练,在后面的内容中通过实验比较不同学习方法对计算资源的学习能力。
3.1 幂函数拟合
幂函数的曲线特征是,曲线变化前期增长比较缓慢,后期增长比较迅速。将计算资源r(如CPU使用率、内存消耗大小、网络带宽等)与测试负载的关系可用幂函数标示,即
其中w0及w1为幂函数的参数。在训练过程中,对上述式子两边取对数,可得
令X = w1ln(r),Y = ln(load)将上式转化为一次函数形式,经数据训练得到拟合函数:
3.2 支持向量回归拟合
支持向量回归(SVR)[9]是支持向量机(SVM)的在数值回归预测问题上的应用,通过使预测误差最小化来寻找最接近训练数据点的函数。支持向量回归的输入是一组可数值预测回归的特征向量集,输出是一组描述训练数据内数据回归关系的函数,即
将资源与负载融合数据作为特征向量,训练得到负载与计算资源的支持向量回归模型。
3.3 多层感知器拟合
多层感知器是一种前馈型神经网络[10],其拓扑结构包括一个输入层、一个输出层和一到多个隐藏层,如图3所示。多层感知器在复杂问题的求解,有不错的表现。
在使用多层感知器进行训练时,通过神经元输出的实际值与目标值的误差来调整神经元的连接权重,直至最终结果满足误差要求。
在使用多层感知器时输入层的输入是计算资源数据向量,目标值是测试负载的向量形式,训练结束后得到资源预测的多层感知器模型,利用该模型计算未知负载下的计算资源。
4 主机预测方案
主机预测方案使用单机计算资源作为输入,预测单机支持的最大测试负载规模,再根据负载规模求得主机数目。包括模型训练和主机数目预测两个步骤。
模型训练以计算资源预测负载,把资源与负载融合数据作为训练数据,以测试负载load作为训练目标,使用负载学习预测方法得到预测模型M,得到预测函数,即:
在预测主机数目时,对于主机的计算资源来说,计算资源不能得到完全的使用,如CPU资源利用率超过80%时,会造成资源紧张的情况,此时为主机增加更多的测试任务会影响测试正常发起或是测试结果的处理等情况。本文使用最大资源利用率maxr表示测试主机正常工作条件下计算资源能达到的最大利用率,主机最大可用计算资源ra与主机计算资源rh的换算关系:
将单台主机的最大可用计算资源ra带入到预测函数得到单台主机可支持的负载loadh,计算过程为
当负载规模超过单台主机支持的负载时,使用目标负载除以单台主机可支持的负载得到主机数目n,若所得数值存在小数部分,则对数值进行向上取整处理以保证计算资源能满足负载测试的需要,即
5 实 验
实验选取开源应用程序录制6个测试脚本,虚拟机选择2核4 GB的配置,最大资源利用率为80%,通过测试预执行过程收集计算资源与负载数据得到资源与负载融合数据。按照本文所述预测方案,分别使用三种学习方法预测发起1万负载所需要的主机数,并将预测的结果写入到表1中,其中EXP指幂函数拟合方法、SVR指支持向量回归拟合方法、MLP指多层感知器拟合方法,n为当前学习方法预测得出的主机数目,t为训练及预测过程的总时间,单位为秒,N为实际负载测试工作时最优主机数目,S为测试脚本,s1-s6为具体的脚本编号。
从实验结果来看,幂函数拟合方法进行主机预测效果相对较差,在实际主机需求增多时,预测的主机数目与实际数目相差较大;其次多层感知器拟合方法与支持向量回归拟合方法预测的效果相对幂函数拟合方法有所提升,其中多层感知器算法进行预测时训练及预测总消耗时间比其他方法的总消耗时间更多。
6 结 论
提出了一种面向云测试的主机预测技術,可运用于确定云上负载测试需要的主机数目,避免人工估计主机的主机数目偏少引起的测试失败或是主机数目过多造成的资源浪费的问题。实验结果表明,提出的方法在使用支持向量回归及多层感知器算法时能有效预测出主机数目。
参考文献
[1] MENASCE′ D A. Load testing of web sites[J]. IEEE Internet Computing,2002,6(4):70-74.
[2] Load Runner [EB/OL](2018-10-23)[2019-05-04]. https://www.microfocus.com/zh-cn/products/loadrunner-load-testing/overview.
[3] Apache Jmeter [EB/OL](2018-12-21)[2019-05-04]. https://jmeter.apache.org
[4] ALI A,BADR N. Performance testing as a service for web applications[C]//2015 IEEE Seventh International Conference on Intelligent Computing and Information Systems (ICICIS). IEEE,2015:356-361.
[5] BANZAI T,KOIZUMI H,KANBAYASHI R,et al. D-cloud:design of a software testing environment for reliable distributed systems using cloud computing technology[C]//2010 10th IEEE/ACM International Conference on Cluster,Cloud and Grid Computing. IEEE,2010:631-636.
[6] 阿里云性能测试工具 PTS [EB/OL](2019-01-21)[2019-05-04]. https://www.aliyun.com/product/pts
[7] 压测大师 LM [EB/OL](2019-01-21)[2019-05-04]. https://cloud.tencent.com/product/lmRapid elasticity and the cloud.
[8] 胡越,罗东阳,花奎,等. 关于深度学习的综述与讨论[J]. 智能系统学报,2019,14(01):1-19.
[9] SMOLA A J,SCH?魻LKOPF B. A tutorial on support vector regression[J]. Statistics and Computing,2004,14(3):199-222.
[10] RUMELHART D E ,HINTON G E ,WILLIAMS R J . Learning internal representations by error propagation[M]// Neurocomputing:foundations of research. MIT Press,1988.
