
大数据风控技术在互联网金融中的探索与实践
2020-07-04 08:53方昊
科学技术创新 2020年18期
方昊
(上海你我贷互联网金融信息服务有限公司,上海200122)
金融科技(fintech)在最近几年发展的风生水起,以蚂蚁金服为代表的互联网企业和以兴业数金为代表的银行系科技集团均涉及其中。金融的核心问题之一便是风险控制,所以当前众多科技企业对外服务的核心都是大数据风控系统。
1 系统设计思想
如今大量的金融机构服务的客户,特别是C 端客户,不再是28 理论中20%的优质客户,这些客户主要被银行甚至更加高端的私人银行垄断。因而他们的主要服务对象是80%的用户。如何从这些客户中筛选出优质客户,是这些金融机构面对的难题。如果仅仅依靠传统的风控系统,会面临审批周期长、拒贷率高、人工成本高等问题。
在开发这套系统之前,我们随机从目标客户中抽取了一些样本,建立了借款客户的用户画像。从画像特征中了解到他们的主要特征是金额小、频次高、借款时间短、放款审批周期短。而这些特征也印证了对上述问题的判断。
相较于传统风控系统而言,大数据风控系统强调的重心在于大数据和风控系统。传统风控系统主要是基于客户的收入水平、所在行业、负债水平建立评分卡,从而确认该客户的风险水平,所以从这方面来看,传统风控系统用的数据只是侧重反应了某一方面的状况。而大数据风控系统则是利用图像、社交活动数据、行为轨迹、地理位置等数据全方位评估用户的风险水平,规避传统风控系统的问题。任何事物都会呈现两面性,随着系统的投入使用数据会呈现出爆发式增长,并且还会出现数据变动快、系统效率变慢的问题。但是随着金融机构业务的发展,又对风控系统提出了高并发、高响应、操作简单、海量存储等更苛刻的要求。使用传统的数据处理方法已经不在适应行业的要求。因而必须要对系统做合理地切分,并且使用更新的技术方法来制作。
从系统面对场景上来看,大数据风控系统不仅仅是要与信用风险做斗争,同时还要尽量支持更多场景,比如:羊毛党、支付欺诈等,不仅如此,新的系统还要监控流程中各个环节,从而达到尽早发现、尽早防控的目的。
因此大数据风控系统,已经不再是一个系统,而是由若干个系统组成的系统集群,通过该集群的合力工作,帮助用户快速提升业绩。
2 大数据平台及大数据风控体系建设
针对上述的设计思想,本文将以嘉银金科的反欺诈系统构建为例展开探讨。目前嘉银金科的增量数据呈现出爆发式增长,增量单位为T,这些数据主要是包括行为日志、业务日志、各类json 和XML 文件、照片、活体认证资料等,从数据形态上又可分为结构化数据、半结构化数据和非结构话数据,从业务属性上将其划分成若干个数据集市,比如:订单数据、支付数据、用户属性数据等。先将数据分为实时和非实时,实时数据又区分为分钟、小时、天3 个范围,因为在实际的风控业务中,实时计算结合历史数据的计算占据了大量的场景。
2.1 大数据平台建设
在数据体系建立中,需要将数据分层,目前主要将数据分为三层,分别是数据采集和整理层、数据建模层、数据应用层。如图所示。
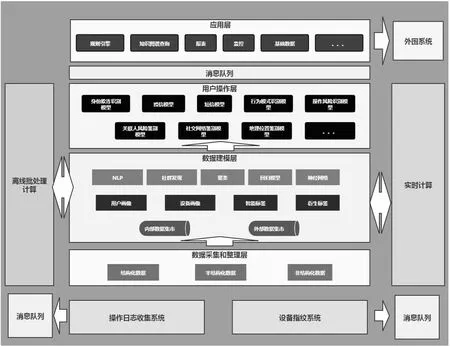
大数据风控体系架构图
2.1.1 数据采集和整理层。在该层中存放各种类型的原始数据和预处理数据,包括数据库数据、Nosql 数据、半结构化数据、各类日志等,每天系统会根据设定的任务,自动从目标系统中抽取数据,目标系统包括各类业务系统、日志系统、交易台账等,抽取好数据后会直接进入该层的数据库。再抽取完成后,系统便会根据ETL 脚本的逻辑关系,选择需要启动的脚本,将raw data 转化为product data。离线批处理采用的是Hadoop 分布式存储+分布式运算的框架,可以对海量数据进行统计分析,解决单节点极限性。目前选用的是Mapreduce/Spark 混合架构,主要是因为spark 主要在内存中处理数据成本较高。数据采集和集成工具使用的组件是StreamSets。
2.1.2 数据建模层。该层数据是存储可用于直接用于生产系统的数据,是经过数据清洗过后的干净数据。主要以业务标签数据、会员画像、设备画像等。在该层中数据将会深度介入业务,根据需求将数据切分为多个数据集市,助力业务发展。目前这些数据的主要为风控、推荐、精准营销等业务线的深度学习模型、业务分析、数据服务接口等功能服务;
在该数据层中,数据分析人员使用pythonRSAS 等工具对数据建模,为下一步的数据应用提供支撑。
2.1.3 数据应用层。根据业务线特点,将数据区分成适用于不同业务的数据应用产品,该层也存储报表、数据分析报告等产品的数据;该层数据在应用中典型的应用场景包括:数据大屏、BI 系统等。
在这里重点介绍风控体系的数据建设,风控体系数据包括了贷前、贷中、贷后,这三类数据全部融入在上述所说的体系中,其中贷前数据用于检测可能的异常行为,并在借款之前将其拒绝;贷中数据用于在借款过程中的各类模型即风险评估;贷后数据用于验证各类模型的效果,并及时提高模型的准确度。
同样还需要注意的是离线批处理功能和实时计算功能并不是集中在某个数据层中,每一层都会涉及。下面将重点阐述下实时计算功能,从目前的实际需求来看,有大量的实时计算需求,比如监控、统计。而在这些计算需求中主要是各类汇总计算包括聚合计算、排序等,更为麻烦的是这些计算逻辑需要将热数据、温数据和冷数据加总。为此在设计指标数据结构必须要考虑一致。计算结果会根据实际用途存放在不同的地方,实时存储在redis/hbase,批处理方式的结果存储在hive 中。
系统是从消息总线来获取实时数据,结合批处理的计算结果,通过约定好各类ID 将实时数据结果和批处理结果放在一起做后续的汇总计算,最终的汇总计算也是放在实时计算里实现。目前使用的实时计算工具是flink+kafka,计算逻辑是ksql 定制。
批处理的结果是从hive 中查询,一旦查询任务过多,单机是无法承受的。这就需要引入分布式技术来分摊查询任务,本系统中引入的组件是spring cloud(具体介绍可以参见https://spring.io/projects/spring-cloud)。
但是在实际开发过程中,往往会有细致的问题,目前系统中遇到的最多的两个问题是:
(1)线程计算任务分问题,在分布式计算过程中,每个计算任务消耗的资源和时间是不同的,有主机的任务较为繁忙,有些则空闲,所以还需对各个线程做监控,并实时调度,我的思路是在系统中加入一个类似通知栏功能,里面记录计算的任务数,已经完成的任务数,消耗时间等内容,当一个任务计算完成后告知通知栏。
(2)时序问题,实时计算过程中,使用的数据源是数据流,在实时计算过程中,可能会涉及双流计算甚至更多的流。由于网络等其他问题,数据流到达消息总线的顺序可能和预想的不一样,如果不考虑着这种问题,那么会引起很多错误导致系统故障。对此,我的解决方案是:引入互相检测机制,比如算某个比率,如果分子的数据到了消息总线后,以某个时间字段为准线向前扫描一个时间段的分母,如果没有找到,则等待一个时间段,在这个时间段内探听分母的数据流。反之对分母亦然。
2.2 大数据风控体系建设
在开发的大数据风控体系中,主要由三部分构成分别为操作日志收集系统、设备指纹系统、风控决策系统。
2.2.1 操作日志收集系统
所谓操作日志收集就是在客户使用系统的过程中,收集用户的操作信息,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑,包括访问数(Visits),访客数(Visitor),停留时长(Time On Site),页面浏览数(Page Views)和跳出率(Bounce Rate)。这样的信息收集可以大致分为两种:页面统计(track this virtual page view),统计操作行为(track this button by an event)。
操作日志数据是用户行为数据,具有实时性,数据质量较高,是风控系统重要数据来源之一。这些数据可粗可细,从庞杂的数据背后挖掘、分析用户的行为习惯和喜好,坏人的异常行为,正是大数据风控的价值。
App 采集到数据后,需要通过实时etl 和实时计算组件,加工成业务需要的指标,然后在与其他数据合并或者直接使用。这个项目面临的主要问题:
(1)数据量大:这里的数据量是指瞬间的数据流量大,目前每天的日志增量数据达到1T;
(2)数据容易丢失:数据依赖网络上传,采集的数据遇到网络不通或者信号较弱时,数据就会丢失,造成不必要的损失;
(3)采集环境复杂:采集端有原生界面也有H5 界面,这两种页面的编程方式和获取数据的内容完全不同;
第一点,在数据量大的情况下,减少服务提供的功能,在简化暴露给采集端的服务,只有接受数据的功能,同时引入消息总线,消息总线引入后,加大系统的并发和TPS,在消费端接入消息,加重消费端功能。这个思想也与目前小前端、大中台的想法一致。而且消息总线的引入也实时打通了行为数据和业务数据,为风控和营销提供了有力支撑。
第二点,在采集端增加缓存,当出现网络或者其他问题时,采集的数据进入缓存,待网络环境变好后,系统会自动上传缓存中的数据。
第三点,统一定义公共数据字段还有自定义字段,公共字段是指无论原生页面还是H5 页面都必须上传的,自定义字段是指只能在原生页面或者H5 页面采集的字段。APP 需要提供接口提供给H5 调用,然后统一上传。这样的好处是数据格式统一,为数据用户方提供便捷。同时也减轻不必要的数据处理工作,减少后台计算成本。
2.2.2 设备指纹系统
简单来讲,设备指纹是指由某个公司定义用来唯一标识该设备的ID,也可以说设备指纹就是设备的身份证号。
在风管技术实践中,设备指纹已经成为了基础技术。因为在互联网环境下,真人的身份和操作者的身份可能存在完全不匹配的情况,因而身份不确定性是互联网欺诈分子的根本支撑,在无法识别操作用户的情况下,想办法从各类设备着手,识别可疑上网行为,尽快发现与设备关联的异常操作,并对其做出反应。
通常来说设备指纹包括若干个固有的、较难篡改的、唯一的设备标识。比如每台移动设备在生产出厂后,都会生成一个硬件ID,比如手机在生产过程中都会被赋予一个唯一的IMEI(International Mobile Equipment Identity)编号,用于唯一标识该台设备。在比如电脑的网卡,在生产过程中会被赋予唯一的MAC 地址。这些设备唯一的标识符就可以将其视为设备指纹。通常情况下,只需简单的获取这些字段即可。但是欺诈分子在一些工具的帮助下,可以随意修改手机参数,造成原本稳定的数据变的不再稳定。
如何保证数据稳定是设备指纹的最大问题,即在用户修改了手机底层数据后,还能识别出来是相同的设备。为此通过分析海量的多维度数据得出一些可靠结论,这些数据包括操作日志、设备日志等,我使用的模型包括寻找余弦相似度和设备分来解决稳定性问题。
2.2.3 风控决策系统
风控决策系统是展现给用户的终端系统,但是在这个系统的后面运行这大量的模型支撑风控体系的运行。众所周知,在大数据风控体系下存在着各种维度的数据,从行为、交易、设备、位置等,这些数据也是风控模型的入参,风控通常使用的包括随机森林、逻辑回归、GBDT 等模型。
客户进入系统借款时,风控决策系统会对其操作和各类信息进行判断,决定其是否可以进入授信环境,当判断没有问题后。便会对其进行额度评估并给出其合适的额度。
在这一过程中,规则引擎是核心环节,鉴于当前业务发展的实际情况,必须是实施部署、实时生效,并且操作友好。引入了drools 为基础,并在此基础上做了深度定制。目前这套引擎在生产系统中起到重要作用,每天经受了高达几千万次的调用。
3 践行成果
通过对上述系统的实施,嘉银金科已经初步建立以大数据为核心的风控体系,围绕着这套体系,已经建立起两套不同性质的风控系统:
智能反欺诈系统:该系统目前承担身份欺诈、交易安全、账户安全等功能,它的定位是会员准入,只有通过该系统的认证,才能有资格进入授信环节。目前该系统平均每天的调用量高达数百万次,目前系统的各项性能指标均满足之前的设计要求,未来该系统还将继续扩容,交给B 端客户使用,形成真正意义上的Saas 系统。
智能风控系统:该系统主要承担授信功能,通过反欺诈系统的认证后,即可进入系统,该系统主要与大数据的风控集市和实时计算交互,通过机器学习模型、评分卡等功能对借款用户进行授信,整个过程最长在3 秒内完成。
4 结论
通过这些系统的建设,嘉银金科在金融科技领域已经慢慢挤入主流金融科技系统服务商,截止2019 年12 月,风控每天在为十几万C 端客户提供服务,并且还有几十家B 端客户在使用这款产品,包括银行、农信社等。为行业的发展提供了有益的尝试。
猜你喜欢
中国特种设备安全(2022年6期)2022-09-20
华人时刊(2021年13期)2021-11-27
家庭影院技术(2021年3期)2021-05-21
当代工人(2020年13期)2020-09-27
铁道通信信号(2020年5期)2020-09-21
心声歌刊(2020年4期)2020-09-07
科技传播(2019年22期)2020-01-14
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电子制作(2018年11期)2018-08-04
