
基于卷积神经网络和稳定性选择的农作物植被光谱分析方法
2020-07-01 09:29段欣荣曹见飞张宝雷王召海
山东师范大学学报(自然科学版) 2020年1期
段欣荣 曹见飞 张宝雷 王召海
(山东师范大学地理与环境学院,250358,济南)
1 引 言
农作物分类是精细化农业、可持续发展农业等领域的重要研究内容[1].遥感技术与传统的实地调查相比具有快速高效、大面积同步观测的特点,已经成为农作物精细识别的重要手段.随着遥感技术的发展,新兴的高光谱技术获得多且连续的反射光谱信息,具有更高精度农作物信息识别的潜力,同样农作物生化参数的光谱分析难度也随之增加[2,3].
同一季节的农作物植被光谱特征相似,在受自然环境的影响下存在大量的干扰信息,掩盖部分可用的特征波段,精确提取表达植被生化参数的特征波段难度较大,在多分类中该问题尤为突出.现有的农作物光谱分析方法一般通过光谱预处理方法提取特征波段,然后利用这些特征参数构建光谱信息识别模型[4-8].李喆利用微分法与包络线去除法识别敏感的特征吸收峰,提取光谱吸收特征参数,构建估算草地光合有效辐射吸收率的光谱特征参数模型[4].黄双燕等通过单因素方差分析选择农作物光谱特征变量,利用不同机器学习验证特征变量的有效性[5].Cao等提取光谱特征、纹理特征和植被指数,构建识别红树林树种的多变量支持向量机模型[6].刘小丹等采用主成分分析和连续投影算法提取特征波长,利用偏最小二乘判别分析和支持向量机鉴别杂交稻品系[7].Xie等采用改进的gramm-schmidt方法识别有效波长,利用极端学习机和判别分析光谱模型对绿豆种类进行识别[8].以上学者为解决农作物植被光谱分析中特征波段难提取的问题,提供了各种有效的思路.然而这些研究中,光谱预处理和特征选择成为识别模型构建之前必不可少的步骤,这不仅增加分类结果的不稳定性,且使得模型构建繁琐且复杂[4-9].因此,急需一种统一高效的光谱分析方法解决现有模型存在的问题.
卷积神经网络(Convolutional Neural Network,CNN)被认为是一种不依赖特征工程便可识别隐含特征的非线性函数,其权值共享及池化操作等特性使其成为高性能的分类方法,在遥感图像分类领域应用广泛[10].CNN通过卷积核池化操作可以准确的提取数据局部特征,深层次地表达分类对象的特性,近年来在医学电波检测、分子结构光谱识别等研究领域被证实,CNN卷积核池化操作对光谱信息具有抑制噪声,准确地表达光谱潜在特征[11-13].但有关这类模型较少的被推广到农作物光谱精细化识别研究中.然而CNN属于“黑盒子”,复杂的计算过程难以被解释,CNN应用研究中大多只是论述其应用结果.由Meinshausen等[14]于2010年提出的稳定性特征选择方法(Stablity Selection, STS),是一种基于二次抽样和选择算法相结合的方法,被广泛用于分类模型的特征选择可视化,为农作物植被光谱特征选择提供了新途径.本文首次整合STS和CNN,构建改进的农作物植被光谱分析统一方法.简化特征选择和光谱预处理要求,提高农作物光谱识别准确率;同时计算出表征不同农作物植被特性的特征波段;与人工定义的光谱特征波段对比,能够解释CNN光谱模型的特征表达能力以及对光谱干扰信息的抗干扰能力.
2 方 法
2.1卷积神经网络CNN在人工神经网络的基础上发展而来,是一种前馈神经网络.其是通过逐层压缩提取特征,学习识别多维数据的内部联系.相比人工神经网络,CNN具有卷积和池化层等特殊结构,通过局部连接和权值共享有效减少网络的训练权值,使得多层神经网络的优势得以体现.

图1 卷积神经网络结构
典型CNN一般由卷积层、池化层、全连接层和输出层组成(如图1).卷积层中神经元通过卷积核与输入进行局部连接,并通过对应的连接权值与局部输入进行加权求,然后通过一个非线性函数进行激活.卷积层定义为
yj=f(bj+∑ikij*xi).
(1)
式(1)中,xi和yj分别是第i个输入特征图和第j个输出特征图;kij是两个特征图之间的卷积核;*符号表示卷积;bj是第j个输出特征图的偏置;f(z)是非线性激活函数如Sigmoid函数、Tanh函数、ReLU函数等被卷积层中的全部单元共享.
紧跟卷积层的是池化层,对卷积层提取的局部特征进行下采样,减少网络中参数并提高学习网络的鲁棒性.池化层定义为
yj=f(wjDO(xi+bj)).
(2)
式(2)中,xi和yj分别是第i个输入特征图和第j个输出特征图;DO()表示采样函数,一般选用随机采样、均值采样、最大值采样等;wj为权值;bj为偏置.
本研究中不使用全连接层(多层感知器)以避免过拟合问题.将卷积-池化层输出的特征综合起来,最后由通用的Softmax多分类器进行分类识别.Softmax多分类器的分类过程可表达为,
(3)
其相当于一个压缩函数,将一个K维的映射向量的值转换成取值都介于(0,1)之间的值,且相加和为1.
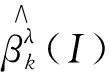
(4)
然后在路径中选取被选概率较大的变量进入最终模型Sstable,其中被选概率的阈值0<是新的调整参数,
(5)
2.3改进的光谱分析方法高精度的光谱识别和特征波段提取是光谱分析方法的两个重要方面.为了获得高效统一的农作物植被光谱分析方法,且更好的了解CNN对农作物光谱识别过程,本文通过整合STS与CNN提出一种改进的光谱分析方法.该方法计算过程如图2所示,首先以农作物植被光谱识别最优化为导向,构建最佳CNN光谱模型;样本数据训练CNN光谱模型后,获得农作物植被光谱识别结果.同时,将CNN光谱模型的卷积-池化输出作为稳定性特征选择的特征集合;利用稳定性特征选择算法重新迭代训练Softmax多分类器(CNN光谱模型的输出层),得到特征子集与分类类别的相关性得分;最后用特征子集的位置乘以卷积核步长和池化步长,反向推算出特征子集对应的光谱波段.本研究将此光谱分析方法称为CNNFS.相对于传统的CNN模型,CNNFS的优势在于将光谱分析的光谱识别和特征波段提取两个步骤整合在一起,实现了农作物植被光谱分析的统一方法.另外,CNNFS在保留CNN整个运算过程的同时计算出潜在的光谱特征波段,为解释CNN光谱模型卷积池化层提取特征能力提供了重要依据.
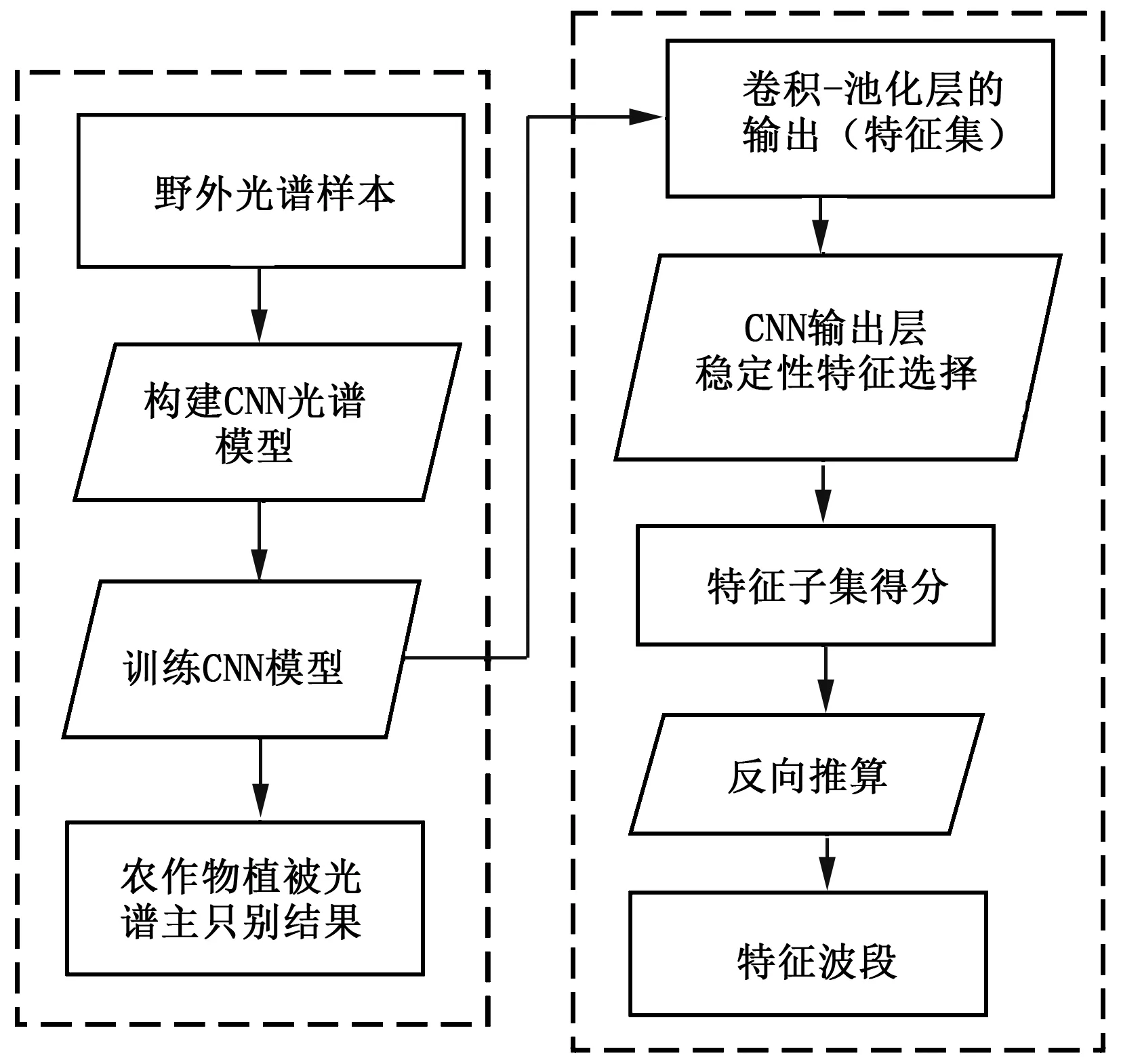
图2 改进的光谱分析方法(CNNFS)计算过程
3 实 验
3.1光谱测量与预处理选取10种同一时间生长状态下的农作物植被作为研究对象:玉米、大豆、豆角、葡萄、大枣、辣椒、秋葵、芥蓝、韭菜和草皮,每种野外选取100个新鲜样本.光谱测定使用美国ASD FieldSpec3地物光谱仪、光谱范围350~2 500 nm,采样间隔为1.377 nm(350~1 000)和2 nm(1 000~2 500 nm).光谱测量地点为山东省龙口市北部平原地区.该地区属于温带季风性气候,农作物种类繁多,分布广泛.为对应遥感应用中的光谱分析问题,光谱测量选择在2017年8月,测量环境条件选择在阴天、晴天、有风和无风等不同天气状态下,刻意增加野外光谱的不确定.自然状态下,光谱探头垂直,保持距离样本目标10 cm且连续获取10条光谱,取平均值作为原始光谱值.由于野外大气水汽吸收干扰,导致1 350~1 450 nm、1 800~1 950 nm和2 450~2 500 nm光谱反射率波动很大,对于农作物精细分类属于无用信息,将其剔除.
另外,增加农作物野外植被光谱预处理实验,分析CNN光谱分析模型在不同测量条件下的表现.野外光谱的干扰信息主要源于野外光谱采集过程中外界环境干扰,包括空气中水汽、农作物叶片上的滞尘和测量背景环境变换等,将这些干扰信息总结为仪器噪声、光谱基线和光谱散射[15].为消除干扰信息,突出光谱的特征值,选择卷积平滑(SavGol)、二阶微分变换(Deriv2)和变量标准化(SNV)3种预处理方法对原始光谱进行预处理操作,分别抑制仪器噪声、光谱基线和光谱散射的干扰影响[15,16].
3.2分类模型构建基于TensorFlow和Sklearn机器学习框架,采用python语言进行编程.将1 000个样本划分为训练集和测试集,其中70%用于训练建立模型,30%用于检验模型.为更好的选择CNN网络参数,利用随机网格搜索交叉验证框架(RGS-CV)进行训练CNN模型,并以分类正确率为导向获取最佳CNN网络结构参数(图表1).网络C1卷积层卷积核大小为1×5,数量为12,激活函数为RELU;C2卷积层卷积核为1×3,数量为16;S1、S2池化层采用均值池化方法,下采样尺度为1×2和1×4,步长为2和4;最后由Softmax多分类器输出分类结果.选用目前研究中常用的偏最小二乘判别回归(PLS-DA)、Softmax多分类器算法作为对比实验.最小二乘法判别分析是一种用于判别分析的多变量统计分析方法,适用于变量数量大于分类类别的情况[7];Softmax多分类器可视为CNN模型的最后输出层,直观判断卷积-池化层的作用.

表1 CNN网络结构参数
3.3特征波段选择基于Sklearn机器学习框架,采用python语言进行编程.将CNN模型卷积-池化输出的(16,229)矩阵作为16个特征集合,重新迭代训练Softmax多分类器,挑选出得分前10的特征子集.根据卷积池化压缩过程,反向推算出10个8 nm特征波段,最后将特征波段合并(如表2).

表2 不同预处理条件下CNNFS获取的特征波段和中心波长
4 结果与讨论
4.1CNN光谱模型评价不同分类模型和不同预处理条件下的结果如表3所示.CNN模型分类准确率比PLS-DA和Softmax平均提高了8.5%和6%.在未预处理条件下,CNN分类结果最为理想,其准确率为97%,分别高于PLS-DA、Softmax模型12%和8%;在不同的预处理条件下,CNN分类准确率仍然高于PLS-DA、Softmax模型,平均提高了7.3%和6.3%,PLS-DA的分类结果最不理想,Softmax表现中等.表明CNN模型很好的应用于农作物光谱分类识别.纵向比较来看,PLS-LDA的分类准确率在不同预处理条件下均有提高,提高范围在5%~8%之间,在全部的模型中受影响最大;其次是Softmax模型,分类准确率也增加4%~6%;CNN对预处理操作影响范围为1%~3%,在3个模型中对光谱前期预处理操作表现最不敏感.表明不同光谱预处理对不同分类模型的影响程度各异,但总体上预处理对农作物光谱识别分类具有积极的意义.CNN相对于PLS-DA、Softmax模型对预处理操作依赖性较小,即利用CNN构建农作物光谱分类模型时,可减少或者不进行光谱预处理操作.

表3 不同预处理条件下不同模型的农作物分类准确率(%)
综上所述,CNN模型能够很好的应用于农作物光谱分类识别.其优势在于CNN模型能够在较少或者无光谱前期预处理操作情况下,依然获得高准确率的分类精度,对光谱的分类识别体现出较强的鲁棒性和泛化能力.
4.2特征波段提取分析CNNFS计算的特征波段是CNN模型卷积-池化层对农作物光谱特征表达的结果.利用CNNFS方法计算农作物光谱特征波段,为便于对比描述,根据农作物光谱的经验知识选取10个对比光谱特征波段[7,17,19,20],包括可见光—Visible(VIS)波段3个:蓝谷、绿峰、红谷,近红外—Near-infrared(NIR)波段5个:红边、NIR谷1、NIR峰1、NIR谷2、NIR峰2,短波红外—Shortwave-infrare(SWIR)波段2个:SWIR峰1、SWIR峰2(如图3).
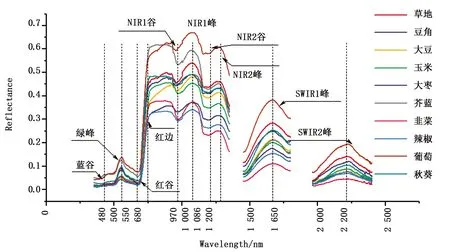
图3 人工定义农作物光谱特征波段
图4为CNNFS选择的特征波段与人工定义的特征波段的对比.结果显示CNNFS选择出的特征波段包含在人工定义特征波段内,且中心波长位置相近,表明CNNFS能够准确地提取能够区分农作物理化性质的特征波段.其中,CNNFS对原始野外光谱选择出4个特征波段的中心波长为544 nm、752 nm、972 nm、1 644 nm,对应绿峰、红边、NIR谷1、SWIR峰1四个波段.Liu[2,17]等、黄双艳[5]等研究中说明绿峰、红边、NIR谷1能够准确地表征农作物叶片的叶绿素含量、细胞结构、含水率等理化特性,是农作物光谱识别的重要特征波段,可以判断出CNN模型卷积池化层对原始农作物光谱能够精确地表达出极具代表性的农作物光谱特征,从而获得高精度的分类结果;SavGol预处理过滤掉部分噪声[16,18],但相对原始光谱提取的特征波段没有变化,可以判断SavGol去掉的部分噪声对CNNFS特征选择影响较少,即CNN模型卷积-池化对光谱噪声具有一定程度的兼容能力;Deriv2预处理方法对原始光谱基线校正后, CNNFS选择出中心波长为544 nm、748 nm、972 nm、1 084 nm、1 220 nm、1 644 nm、2 188 nm的特征波段,本实验的野外环境中使得近红外波段会受大气中水汽的影响严重[20].Cao[4]研究表明Deriv2预处理能够有效的抑制空气水汽、气溶胶及测量背景环境引起的近红外光谱基线漂移,一定程度上能够凸显近红外波段的特征,因此相对于原始光谱CNNFS选择的特征波段增加了近红外NIR谷1、NIR峰1、NIR谷2位置的特征波段,证明了基线校正能够提高CNN模型对农作物光谱分类识别准确率;同样,经过SNV预处理后CNNFS选择出中心波长在544 nm、748 nm、968 nm、1 220 nm、1 640 nm处的特征波段,相对原始光谱增加NIR谷2,本实验的野外实测现场中叶片上含有大量滞尘,导致近红外光谱产生大量光谱散射[21].Barnes[22]等研究表明SNV预处理能够有效减少光谱散射所带来的光谱误差,可以判断减少光谱散射误差同样可以提高近红外波段对农作物的信息获取能力,证明了光谱散射预处理也能够提高CNN模型的分类识别准确率.

图4 CNNFS选择的光谱特征波段与人工定义特征波段的比较(a)RAW; (b)SavGol; (c)Deriv2; (d)SNV
综上所述,特征波段中心波长位置与人工经验选择的特征波段相吻合,能够判断出本文提出的CNNFS特征波段选择方法准确有效.对于CNN模型而言,证明CNN模型独特的卷积-池化操作能够准确地表达出野外实测光谱的重要特征波段,利用这些数据特征进行分类取得更好的效果;其次,对比不同预处理条件下的特征波段计算结果,发现基线校正和光谱散射预处理有助于CNN模型的光谱特征表达,在一定程度上能够提高分类精度.然而CNN模型卷积池化层的特征表达能力不只局限于潜在特征波段的检测,其复杂的非线性计算过程,还可能获取其它有效和细致的局部抽象特征映射[11],比如波峰波谷的宽度、深度等,在以后科研工作中将对其进行深入探讨研究.
5 结 语
1) CNN光谱分析模型很好的应用于农作物识别中,分类准确率在97%~100%范围之间,比PLS-DA和Softmax平均提高了8.5%和6%.
2) CNN光谱分析模型较少的依赖光谱预处理,在较少或者未光谱预处理条件下能够获得较高的识别准确率.由于受空气水汽、叶片滞尘和测量背景环境等噪声、光谱基线和光谱散射信息的干扰,PLS-DA对光谱预处理依赖性最强,提高范围在5%~8%之间;光谱预处理对Softmax的影响次之,提高范围为4%~6%;而CNN光谱分析模型对光谱预处理操作最不敏感,提高范围为1%~3%,表现出较强的鲁棒性和泛化能力.
3) CNNFS是一种农作物植被光谱分析的高效统一方法.在保留CNN模型高精度的识别结果的基础上,选择出的特征波段与植被经验敏感波段相吻合,证明了CNNFS能够在复杂的农作物光谱数据中精准地提取出特征波段位置.根据CNNFS提取的过程,也解释了CNN光谱模型卷积池化操作精准表达特征波段的能力.
猜你喜欢
温州大学学报(自然科学版)(2022年2期)2022-05-30
航天返回与遥感(2022年2期)2022-05-12
科技创新与应用(2021年23期)2021-08-30
潍坊学院学报(2020年2期)2021-01-18
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
雷达科学与技术(2018年3期)2018-07-18
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
制导与引信(2017年3期)2017-11-02
