
基于协同训练的分布式深度协同过滤模型
2020-07-01 05:35:56高浩元许建强
应用技术学报 2020年2期
高浩元, 许建强
(1. 中国科学院大学 人工智能学院, 北京 100049; 2. 上海应用技术大学 理学院, 上海 201418)
如今的互联网行业,个性化推荐已经成为一个越来越重要的技术,而如今的推荐系统主要是基于大数据和各类机器学习、协同过滤等人工智能算法和数学模型来实现的,无论是监督学习、关联规则还是协同过滤的推荐思路都需要一定的训练数据,而这些数据就必须包含着用户与对应产品关联的信息(如用户曾经看过哪个产品等)。国内外目前常用的推荐系统包括传统的基于物品(Item)或用户(User)的协同过滤算法[1-2]、基于矩阵分解的算法[3-4]以及基于深度学习的算法[5-7]等。
半监督学习能将未标记的数据利用起来,在一定程度上改善最终的推荐效果。目前在推荐算法中常用的半监督学习方法包括基于图和随机游走的模型[8]、基于协同训练和主动学习的模型[9-10]、基于半监督支持向量机的模型等[11]。
在一些分布式计算的场景中,数据被存储在多个结点上的,分布式机器学习算法运行的过程中,各结点之间不会对任意一个特定的数据样本进行交换,而只会交换一些计算所得的参数。根据文献调研,基于consensus算法使用分布式梯度下降构建分布式神经网络解决半监督推荐问题的研究尚未见报道,本文就尝试使用该方法对该问题进行研究,并创造性地提出了使用Metropolis算法结合深度协同过滤(neural collaborative filtering,NCF)模型[7]构建分布式推荐系统的思路。
在本文中,首先对整个推荐系统的整体结构进行了概述。然后介绍了基于consensus算法的分布式神经网络模型和目前常用的半监督学习方法及其在推荐系统中的应用,在此基础上提出了一种基于协同训练的分布式半监督学习模型。最后在MovieLens公开数据集[12]上对该推荐系统进行测试,并与独立协同过滤、分布式隐语义(latent factor model, LFM)模型及分布式多层感知机(multilayer perceptron, MLP)模型等作了对比。
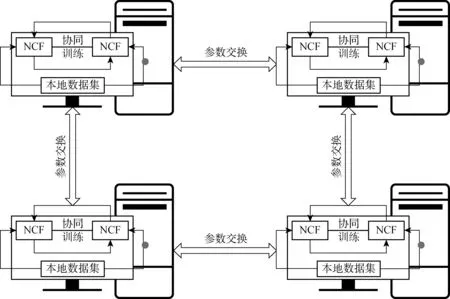
图1 推荐系统结构总览Fig.1 The structure of the recommendation system
1 推荐系统结构概览
本文所要解决的问题是,当用户对物品的行为数据分布在不同的服务器上时,如何在各服务器不交换特定数据样本信息的情况下,使各服务器能协同构建推荐系统,充分利用整个系统中每个服务器的所有信息进行推荐,同时使用半监督学习中的协同训练算法提升预测准确度。
本文中提出的推荐系统模型的具体架构如图1所示。用户对物品的行为数据被分别存储在网络中的各个结点上。在每个结点上构建一个NCF模型,其输入部分由LFM模型和MLP模型两部分组成,每一部分都分别将物品和用户的独热编码向量输入进一个embedding层并将其转化为一个稠密的、低维的隐语义向量,再在LFM模型和MLP模型中分别使用Element-wise Product和神经网络层将隐语义向量进行融合,最终将两个模型学习到的特征向量一同输入到尾端的全连接神经网络层中,并使用sigmoid函数作为输出函数,将用户对物品感兴趣的概率值作为输出,使用交叉熵损失函数对整个模型进行基于梯度下降法的训练。
在每个结点使用梯度下降训练神经网络的过程中,结点之间通过metropolis算法进行参数交换,实现梯度向量的consensus,以实现分布式的NCF模型。根据以上流程,以不同的隐层数量和结点数量构建2个不同结构的NCF模型,并对2个模型进行协同训练(Co-training),对未标记数据进行预测,筛选出其中置信度高的数据提供给对方模型作为训练数据(负样本),以使得最后的预测结果更加精准。对于Co-training与NCF模型结合的中心化模型,将其命名为Co-NCF模型,而整个分布式半监督推荐系统(distirbuted co-training neural collaborative filtering, DISCONNECT)模型。
2 NCF模型
基于前馈神经网络的推荐算法有许多不同的类型。目前,一种常见的结构被称为NCF模型。NCF模型使用一个针对二分类问题的神经网络模型来对用户是否会对物品感兴趣进行预测。若完全使用MLP模型对用户对于物品的兴趣进行预测,则其输入层输入的特征向量是由用户和物品通过某些embedding算法映射得到的向量,而输出层的输出值是一个介于0和1之间的标量,即当前被预测用户对被预测物品可能感兴趣的概率值。而在NCF模型中,构建一个前馈神经网络,其中结合了MLP模型和LFM模型,物品和用户的独热向量(若物品为3号物品,则其独热向量为[0,0,1,0,…,0,0])分别输入2个模型中进行embedding和融合,最终使用一个神经网络进行结合,如图2所示。在上述2个模型中,都可使用真实标记与预测的概率值构建交叉熵损失函数, 之后使用梯度下降法进行训练。
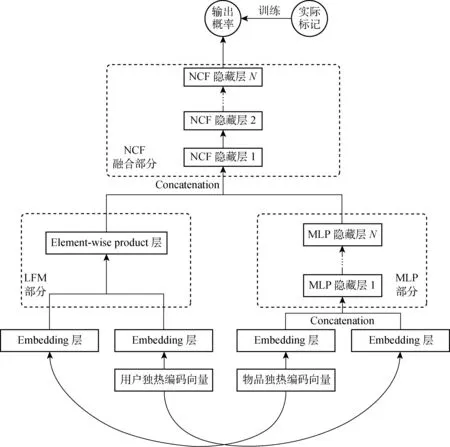
图2 NCF模型结构概览Fig.2 The structure of the NCF model
NCF模型相对于传统的协同过滤算法来说,有着更高的预测准确率,这是由于经过embedding层转化的稠密的向量包含的信息量更大,从其中学到的信息也就更多,并且该模型相当于使用stacking集成方法结合了LFM和MLP模型提取出的特征,所以其表现能够超越这2个模型单独的预测效果。同时,基于神经网络的推荐算法相对于其他推荐算法(基于矩阵分解或图模型),可以容易地使用分布式梯度下降(或分布式随机梯度下降)算法实现分布式训练。
3 基于consensus算法的分布式神经网络模型
当数据被分布式存储在各个结点上,且各结点只能与其邻居结点进行通信(通常整个网络的拓扑结构是一个联通图,即其中任一结点最少有一个邻居结点),由于数据安全、通信效率等问题的考虑,要求结点之间的通信不能对特定的数据样本进行交换。在以上情况下,要进行个性化推荐,就需要构建分布式的推荐系统。
本文引入consensus算法,通过各个结点与其邻居结点的通信,在一定迭代次数以后,最终可以实现每个结点对同一个参数达到共识的目标。consensus算法分为maximum consensus、average consensus等类型[13-14],其中maximum consensus最后希望所有结点对该参数达到一致的值是各结点初始的该参数中的最大值,而average consensus希望得到初始参数值的平均值。例如,若有3个结点,每个结点所保存的参数向量分别为[1,1,4],若使用maximum consensus,则最终希望3个结点保存的参数向量均为[4,4,4],而在average consensus中最终3个结点保存的参数向量均为[2,2,2]。本文中,使用的是average consensus算法中的Metropolis算法[15]。Metropolis算法对参数的更新公式如下:
基于该算法可以将梯度下降法改造为分布式梯度下降法[16],其算法伪代码如下:

Algorithm 1 Distributed Gradient DesecentRequire: Each agent initial the local parameter wi(0) fort=1:Tdo fori=1:Ndo Calculate the local gradient xi(t) vi(t)=Consensusj∈Ni(xj(t)) wi(t)=wi(t-1)-αvi(t) end for end for
分布式梯度下降法用来对分布式神经网络进行训练。具体来说就是针对一个由许多结点组成的通信网络,这些结点组成的图是一个联通图,结点之间的拓扑关系是非时变的,每个结点只能与它的邻居结点进行通信。每个结点上存储着一个神经网络,而整个数据集被分散存储在各个结点上。各个结点的目的是,基于自己所知的部分训练数据集,对自己本地存储的神经网络进行训练,在训练过程中以某种方式与自己的邻居结点交换某些参数值,使得最终各个结点训练得到的神经网络参数达到一致,并且训练出的神经网络效果足够接近当数据被存储在同一台主机上时训练神经网络的效果。
根据算法1的伪代码,分布式梯度下降的思路非常简单。初始状态下,每个结点对自己本地的神经网络参数进行初始化,同时将训练数据输入神经网络进行前向传播,计算得到本地的梯度值之和。之后,各结点对梯度值进行交换通信,直至梯度值达到consensus,接着各结点按照consensus所得的梯度值进行梯度下降法,更新神经网络的参数值。由于神经网络更新前的参数值和更新所使用的梯度值都是一致的,故各结点更新后所得到的神经网络参数值仍是一致的,且在某个精度水平上等价于中心化梯度下降法的训练结果。重复以上过程,直至达到训练停止条件(可设置为consensus后得到的梯度值小于某阈值时)。
4 基于半监督学习的分布式推荐系统
半监督学习是将有标注的数据与无标注的数据结合起来对模型进行训练的方法。通常,在无标注的数据中也包含有许多的信息,半监督学习将这些信息与有标注数据结合起来使用,实现了对数据价值的最大化利用。半监督学习是近年来关注的热点,这是由于有标注数据通常是少量的,而剩下的无标注数据数量更大。
半监督学习中有许多基于不同思想的方法,其中包括主动学习、混合聚类、协同训练以及一些特定机器学习算法的半监督学习版本(如半监督学习支持向量机等)。这些方法中,在分布式系统中,较为适用的是协同训练。在此对协同训练的思想和算法流程进行阐述。
协同训练中,首先将数据集按照某种视图进行分割。如,某数据集中每个样本的特征值有6个,则可以取其中前3个特征值,放入一个模型中训练,再取其中后3个特征值,放入另一个模型中训练,然后在这两个训练出来的模型上分别对无标注数据进行预测。根据预测的置信度,筛选出2个模型各自预测中置信度最高的那些样本,作为训练数据提供给另一个模型。视图的划分是为了使2个参与协同训练的模型具有足够高的多样性,若不对视图进行划分,也可使用相异的模型,如朴素贝叶斯与逻辑回归,或2个结构不同的神经网络模型。最终通过该方法能分别训练出2个预测模型,之后对于所有的未标记数据,选取对其预测置信度较高的模型的预测结果作为其最终标记。协同训练的流程如图3所示。
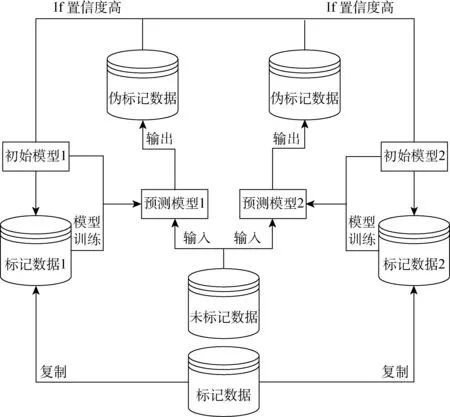
图3 协同训练结构概览Fig.3 The structure of collaborative training
在本文的模型中,数据被分别存储在各个结点上。对于单个结点来说,模型首先根据给出的网络结构构建2个不同结构的NCF模型,之后,对于每一个用户,将训练数据中其已有行为的记录标记为正例,即其标签为1。对于每一个用户,根据文献[7]中的方法,采样4倍于其正例数量的负例,即标签为0的样本。不同于文献[7]的是,在采样负例时,使用传统的协同过滤算法,基于该结点有限的本地数据,来对该用户和已有的所有物品计算相关概率,并根据概率值从小到大进行排序。从排序数据中,选取前K条作为负样本,K为需要采样的负例数量。
使用初始化的训练集分别对2个NCF模型进行训练,在训练过程中通过Metropolis算法与其他结点交换信息,使用分布式梯度下降法训练。
初始化2个模型后,分别使用2个模型基于结点本地数据,对每个用户对于所有物品的兴趣概率进行计算并排序,选出概率最小的K个样本作为负例提供给对方模型作为下一轮的训练负例。
之后使用新生成的训练集对2个模型进行训练,训练过程中同样使用Metropolis算法进行通信,以构建分布式梯度下降算法。训练后再次进行预测并更新双方的训练集。重复以上过程直到达到最大迭代次数。最后在测试集上测试模型时,分别使用2个模型进行预测,并在输出结果中选择置信度较高的(偏离0.5更大的)结果作为预测概率。
5 在MovieLens数据集上测试
MovieLens是一个由美国 Minnesota 大学计算机科学与工程学院创办的电影推荐系统,主要用于研究实验而非商业用途。MovieLens数据集分为几个版本,本文中使用的是MovieLens 1MB数据集,其中包含来自 6 040 名用户对 3 706 部电影的 1 000 209 条评分信息,其中每名用户至少进行过20次评分。另外,MovieLens 1MB还提供了电影的一些基本信息,包括电影名称、上映时间(年月)、电影类型等。
选取的基准模型是独立协同过滤算法(即各结点分别使用其本地存储的部分数据进行协同过滤预测)、分布式LFM模型、分布式MLP模型和分布式NCF模型。在测试中,分别选取item-based和 user-based的协同过滤算法,而相似度度量使用余弦相似度公式。
在测试中,对于各模型的超参数,参考文献[7]中表现较好的网络结构。对于LFM模型,设置embedding的维度为16;对于MLP模型,embedding维度为32,设置其网络结构为[64,32,16];对于NCF模型,设置MLP部分embedding维度为32,网络结构为[64,32,16];设置LFM部分embedding维度为16,设置最后融合部分的网络结构为[32,16,8]。
对于Co-NCF模型的2个模型中,模型1使用上述提到的NCF模型结构,模型2使用的结构如下:设置MLP部分embedding层维度为32,网络结构为[32,32,32,16,16,16,8],设置LFM部分embedding层维度为16,并通过一个MLP隐藏层映射为维度8的向量,最后NCF融合部分的结构为[16,16,8,8,4,4]。这2种网络结构分别代表了深度较高、宽度较小的网络和深度较低、宽度较大的网络,这2种网络结构的优势不同,故能够为模型带来多样性,使得协同训练方法的优势得到充分地发挥。所有梯度下降的batch-size设为 1 024,学习步长为 0.000 1。
在测试过程中,使用leave-one-out评判指标,即,对于任意一个用户,保留其时间上最晚的一条行为记录作为测试集,而使用剩余所有的样本行为记录作为训练集[17]。对于每个用户,随机采样100个用户没有过行为的物品,将其与那一条测试数据混合。在对模型进行测试时,让模型对这101条数据按照相关性自大到小进行排序,并检测前10条数据中是否包含测试数据。对于所有用户,都执行以上操作,最终计算出命中的比率,称其为命中率指标(hit ratio, HR)[18]。
表1为在MovieLens 1MB上基于4种结点拓扑结构对模型预测效果测试的HR结果。由表1可见,对于使用分布式梯度下降来训练的模型,即LFM、MLP、NCF和Co-NCF来说,分布式的算法基本上能达到与中心化算法相同的预测精度,且其预测水平不会随着数据分布的分散程度(即结点的数量)越高而越差,而是基本保持稳定的。这点上显著强于传统的协同过滤算法,从表中可以看出,无论是Item CF还是User CF,当结点数越来越多时,预测精度下降十分显著。分析认为,这是由于在传统的协同过滤算法中,当数据被分布存储在各结点时,结点之间的训练过程是独立的,无法共享信息,相当于每个结点只能使用自己本地有限的数据。要改进该算法,就必然要允许结点之间对特定的样本进行交换,而这不符合在论文开头提出的安全性原则。相反地,基于consensus算法的分布式梯度下降可以让每个结点存储的模型,在实际上都使用了所有结点的数据来进行训练,所以其表现能和中心化的算法有同样的精度。
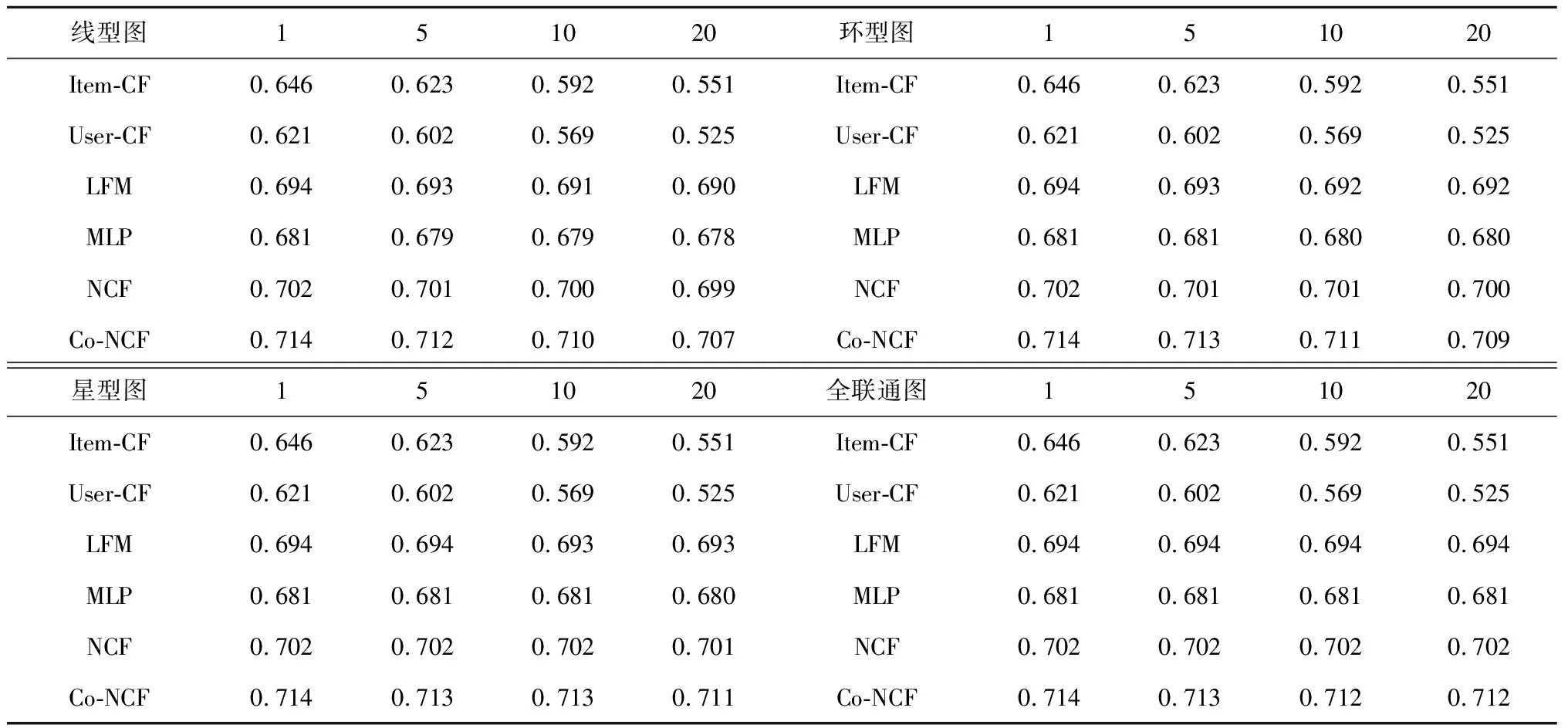
表1 各拓扑结构、结点数量下各模型的HR结果Tab.1 The results of HR with different topology and number of nodes
横向对比各个算法的预测精度可以发现,无论是在何种拓扑结构下,多少个结点数情况下,模型NCF都要优于LFM和MLP模型。据分析,这是由于NCF模型的构建过程实际上是将LFM和MLP模型的预测结果使用机器学习中的Stacking方法进行集成的结果。而Co-NCF模型在任一情况下皆优于NCF模型,可见使用协同训练方法后,确实提升了NCF模型的预测能力。
6 结 语
本文提出了使用Co-training与NCF模型结合的Co-NCF模型,并且探讨了使用基于consensus算法的分布式梯度下降法来构建分布式推荐系统的可能性,进而提出了DISCONNECT模型,即使用Consensus-based分布式梯度下降与Co-NCF模型结合而构建的分布式推荐系统。在MovieLens数据集上使用HR 10作为评判指标的测试表明, DISCONNECT模型无论是在中心化情况还是分布式情况下都优于现有的NCF模型和协同过滤算法。同时也表明,Co-NCF算法在不同结点数和拓扑结构下,其预测精度基本不变,在分布式和中心化上能达到同样好的表现水平。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
数学物理学报(2018年1期)2018-03-26 08:16:42
能源(2017年10期)2017-12-20 05:54:07
能源(2017年5期)2017-07-06 09:25:54
雷达与对抗(2015年3期)2015-12-09 02:38:50
自动化博览(2014年12期)2014-02-28 22:34:27
河南科技(2014年3期)2014-02-27 14:05:45
电子设计工程(2014年12期)2014-02-27 11:58:23
