
Scratch算法练习
2020-06-30 17:02Intoweb
电脑报 2020年16期
Intoweb
1. 为什么要做算法练习
对于计算机来说,针对一个问题选择合适的解决方案的方法就是算法。算法可以是一系列的数学计算,也可以是一系列的操作步骤。总之,它存在的意义就是为了有针对性地解决问题。每个问题都有它独特的一面,正所谓算法没有最好的,只有最合适的。
软件开发领域日新月异,编程语言会推陈出新,掌握的技术可能会淘汰,但算法却是软件不变的核心内容。因此,学好算法能够有效提高编程能力,以后也能更好地学习新语言。
2. 什么是众数
找众数(Mode)是计算机程序设计入门的经典算法练习之一。在一组数据中出现次数最多的数值,叫众数(Mode),多用于统计目标没有明显次序(如非数值性资料)无法良好定义算术平均数和中位数的情况。
例如:1,2,6,6,4,6的众数是6。
有时众数在一组数中有好几个,如果有两个或两个以上数值出现次数都是最多的,那么这几个数值都是这组数据的众数。
例如:1,2,2,3,3,4的众数是2和3。
如果所有数值出现的次数都一样,那么这组数据没有众数。
例如:1,1,2,2,3,3列表共6项3种数值,出现次数最多是2次,列表数字出现次数的平均数也为2,所以没有众数。
现有一个长度为n的序列,请你编程求出它的众数。当然众数可能有多个,降低难度要求只需要输出其中一个就可以了。
3. 算法分析
找众数的算法有很多种比如“观察法”、“金氏插入法”、“皮尔逊经验法”等。由于题目只要求找到一个众数即可,参考这些经典算法后有以下几种思路供你参考。
1) 方法一:每次取出列表第一项,统计该项数值在列表中出现的次数,记录下来,然后将该项删除。这样依次重复统计每项数值出现的次数,直到列表为空。
用专门变量记录出现次数最多的那个数值,这个数值可能就是数列中的众数。
除此之外,我们还需要排除所有数值出现次数相同的情况,如果这个数值出现的次数>列表数值出现次数的平均数,则代表众数存在,否则就没有众数。数值出现次数的平均数=列表项目总数÷列表中数值的种类。
这种方法由于会删除原列表1,所以是一种破坏型的方法。可以新增备份列表2解决这个问题。
2) 方法二:统计列表1中每一项数值出现的次数,一一对应存储到列表2中,然后从列表2中找到最大的那个数,那么该项对应列表1的数就可能是众数。
再看列表2中所有数是不是都一样,只要有一个不一样,那么列表1就存在众数。
3) 方法三:先排序,然后找出那个重复最多的数就是众数了。这种方法用到了排序,排序有很多种算法,本文不再详述,你可以根据以前介绍过的排序方法想想看如何实现。
4. 方法一代码分析
依次对比并记录重复次数最多的数值,并删除对比过的数值(如图1)。
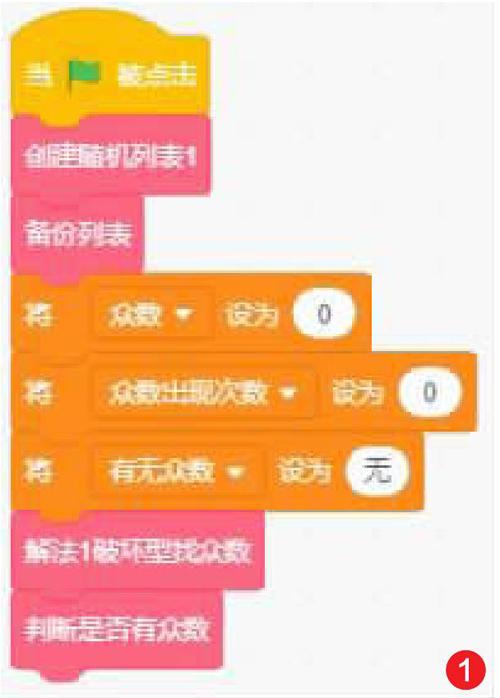
1) 创建变量:众数、众数出现次数、有无众数用来记录成果。列表长度、搜索项、搜索项次数、数字种类作为中间变量。index作为临时变量。
2) 创建列表1,将随机数加入这个列表。将列表1复制到备份列表2。解决找众数过程中列表1会被删除的问题(如图2)。
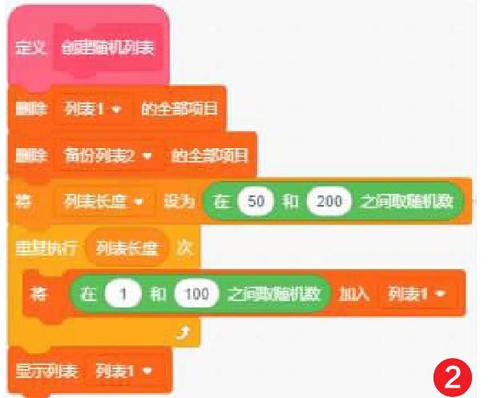
3) 初始化各个变量,有无众数设为“无”,列表长度为列表1项目数。
4) 把列表1第1项设为“搜索项”,依次比对整个列表,记录该搜索项出现的次数,并删除所有与该搜索项相同的数值。这样重复删除直到列表1为空时就比对完成了。
5) 如果新的搜索项出现次数大于众数出现次数,将众数设为该搜索项,将众数出现次数设为搜索项次数。当列表被清空时,众数就是表中出现次数最多的数值了(如图3)。

6) 判断有无众数。如果众数出现次数大于数字出现的平均数就可以判断有众数了。如果有众数就用连接块整合输出最终结果即可(如图4,5)。

5. 方法二代码分析
统计列表中每一项数值出现的次数,从中找到最大数,它对应列表中的项就是众数(如图6)。

1) 定義变量:众数是第几项、众数出现次数、有无众数用来记录众数。搜索项、搜索项次数、列表长度、index用来统计列表每项出现的次数。
2) 生成随机列表1,建立列表2用于存储列表1每项在列表中重复出现的次数。
3) 统计列表某一项在列表中出现的次数。把列表搜索项依次比对整个表格,将重复出现次数记录在搜索项次数中并存入列表2(如图7)。

4) 完成统计后列表2中记录了每项重复出现的次数,下面找出列表2中最大的项(如图8)。
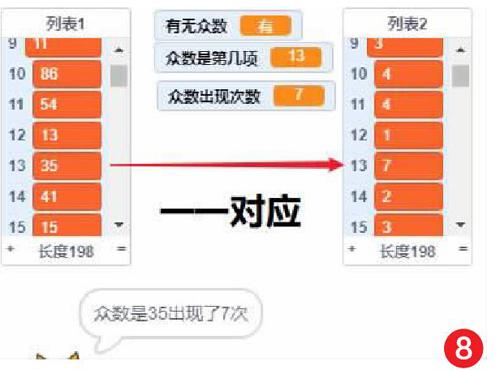
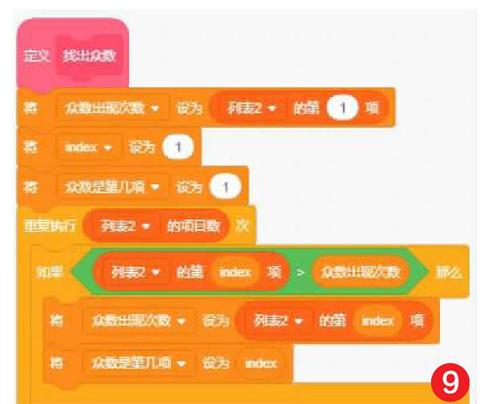
5) 找到列表2中最大的一项。从列表2第一项开始找到较大的项记录在“众数出现次数”中,重复“列表项目数”次就对比了全部项,这时“众数出现次数”就是列表中最大的项,这项的顺序位置记录在“众数是第几项”中对应到列表1中就找到这个列表的众数了(如图9)。
6) 在比对列表2中最大数的同时,我们还要同时判断列表是否有众数。只要列表2中的数值有一次出现不相等,就代表列表1有众数(如图10)。

7) 输出结果,完成循环。如果有众数,用连接块将结果说出来就可以了(如图11)。

通過对两种找众数算法的简析,我们练习了两种找众数的算法。你可以根据对这个问题的理解继续改进算法或找到新的算法,还可以试试看能不能找到列表中所有的众数。

猜你喜欢
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
小天使·五年级语数英综合(2017年11期)2017-11-30
中学生数理化·教与学(2017年4期)2017-04-22
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·中考版(2015年10期)2015-09-10
小说月刊(2012年3期)2012-05-08
