
基于随机权神经网络集成模型的实时遥测数据处理
2020-06-29 12:13
计算机测量与控制 2020年6期
(中国人民解放军92941部队,辽宁 葫芦岛 125000)
0 引言
遥测数据主要用于获取飞行器状态和轨迹信息以对其进行安全控制,高精度的遥测数据处理结果是评估的重要依据。遥测数据处理具有数据量大、数据结构复杂、高维度及高实时性等特征,同时遥测数据易受测量设备和空间环境等影响产生数据漂移变化,其表现可能是数据的突变形式,也有可能是缓慢的线性变化等,变化趋势不易判断,因此建立一种高精度的在线遥测数据预测模型十分必要[1]。
目前机器学习快速发展,并广泛应用于各类复杂场景中的数据建模,通常的有监督学习方法假设数据的概率分布在训练集和实际数据集间不会发生变化,而实际应用场景中的数据的分布由于过程进化特性常常是不稳定的,会随时间而变化,进而造成随时间推移模型的预测精度下降[2]。因此要建立的遥测数据预测模型不仅要求预测结果具有较高的精度,而且能对数据分布变化敏感,可以快速适应数据漂移的变化,同时算法要满足在飞行规定的时间内完成数据处理,
考虑到以往使用单一预测模型存在的不稳定性,而集成算法模型能有效解决模型的泛化性和可信度[3],因此提出一种基于随机权神经网络(NNRW)的装袋(bagging)集成方法[4],用于解决遥测数据流的在线回归预测问题。集成模型的关键是基模型的选择[5],选择随机权神经网络作为基模型,其输入层和隐层间权值随机初始化,在优化过程中保持不变,而对隐藏层和输出层间的权值进行优化,同传统神经网络训练算法相比,这样可极大降低训练复杂度[6]。选择装袋集成方法,通过随机有放回的取样方式保证训练出的基模型间的独立性,保证所训练基模型的多样性,通过基模型定点更新策略保证集成模型对数据漂移的适应。仿真实验表明基于具有高精度和高效性[7]随机权神经网络和装袋集成学习机制可实现基模型的并行训练,该集成方法满足对数据处理的实时性和精度要求,通过基模型更新机制,减小数据漂移对模型预测精度的影响。
1 随机权神经网络的装袋集成模型
该集成学习模型采用装袋集成方法,通过随机采样方法对原始数据集抽取出多个训练集,随机性抽样保证了各训练集各自独立又包含有数据集的共同特征,进而训练得到具有多样性的随机权神经网络基模型池,从池中选择最优的基模型用于预测输出。该集成方法通过样本的随机性,保证训练出的随机权神经网络基模型具有多样性[8],通过赋予高精度的基模型更大的输出权值,联合多个高精度基模型的加权输出实现对输出数据预测,保证最终数据预测结果的精度。同时为应对输入数据存在的漂移现象,当数据出现漂移或模型预测精度下降,对构成输出的基模型采用更新机制,通过新增数据训练获得新的基模型,对集成模型中输出性能较差的基模型进行替换,保证用于预测的基模型为最优。为满足遥测数据处理要求,保证该集成模型数据处理的实时性,由于随机权神经网络的结构和学习过程简单,在对新增数据在线学习过程中可将若干神经网络同时训练,极大缩减了集成模型的构造时间。
1.1 随机权神经网络(NNRW)基模型
基模型的设计要求具有较高的预测精度以及计算效率,以满足实时遥测数据处理的要求,因此选择单隐藏层前向反馈神经网络结构的随机权神经网络作为基模型,基模型原理如图1所示。
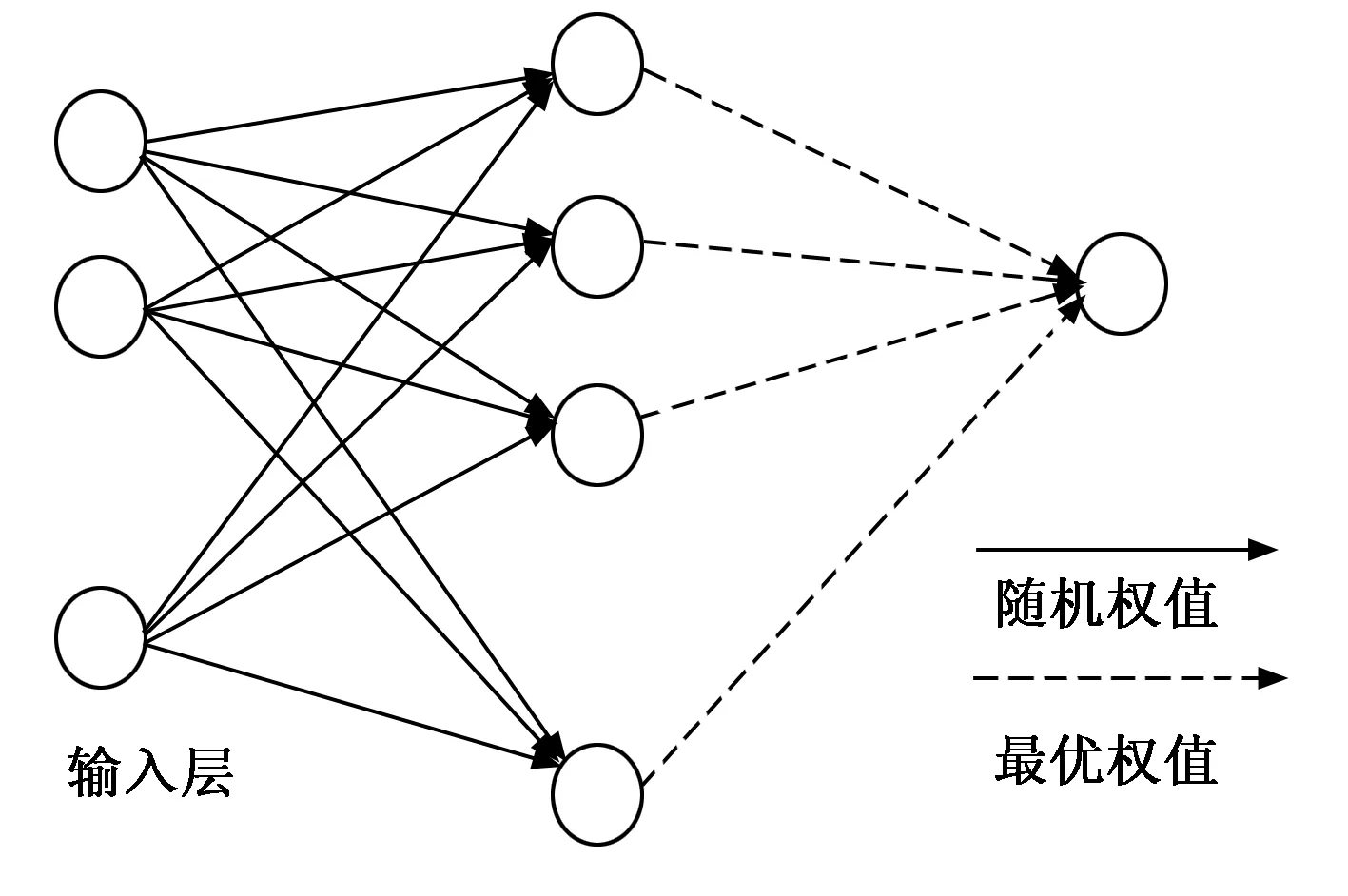
图1 单隐层前馈神经网络基模型
图1中输入层和隐藏层间的权值随机选择,在训练过程中保持不变,而隐藏层与输出层间的权值通过训练获得。学习算法选择岭回归,学习函数如式(1)所示:
T=g(X·WH+B)·Wo
(1)
式中,T为目标向量,X为输入训练向量,WH为输入层到隐藏层的权重向量,B为偏置向量,Wo为隐藏层到输出层权重向量。(g)·为激活函数,如式(2)所示:
(2)
由于WH和B为随机选择向量,且在训练过程中保持不变,训练函数变为线性系统,如式(3)所示:
T=H·Wo
(3)
其中:H为隐藏层输出,通过式(4)计算:
H=g(X·WH+B)
(4)
最优向量Wo满足式(5):
(5)
C为小的常数,I为作为惩罚项的单位矩阵。
随机权神经网络通过随机选取内权与偏置值,将网络参数需要计算的问题转化成线性方程,通过不同的组合进行求解,采用广义逆求解方程组的最小二乘解作为网络外权,通过外权与内权的结合计算,避免了其他传统算法的缺点,极大地减少了训练时间,有效避免了陷入局部最小循环的问题。
1.2 随机权神经网络的装袋集成算法
由于遥测数据含有多维信息,进行该类数据处理的模型通常极其复杂,另外遥测数据具有高的数据吞吐量,因此要求数据处理具有较高的实时性,为满足模型实现在线对数据进行预测计算的要求[9],将随机权神经网络和装袋集成方法进行联合,其模型复杂度为O(M(N3)),模型中的每个随机权神经网络基模型可单独立优化,各基模型优化可并行执行。集成模型的多样性通过装袋集成方法的自助采样(bootstrapping)算法实现,自助采样不仅产生新的训练数据集用于基模型的训练,并且能保证从训练集中抽取出特征属性,特征属性的数量用于构建每个基模型,特征属性的数量根据总特征量的百分比得出。
集成算法的具体原理如下:
1.2.1 基模型的选择优化
集成模型中包含多个基模型,它们利用对原始训练集的采样集进行训练获得各自的最优参数,因此能保证基模型的多样性,每个基模型都可以对输入数据集进行预测,但集成模型的输出只由所选择的最优Q个基模型决定,给定修剪率p∈(0,1],参加预测的基模型的数量Q满足式(6):
Q=p*M
(6)
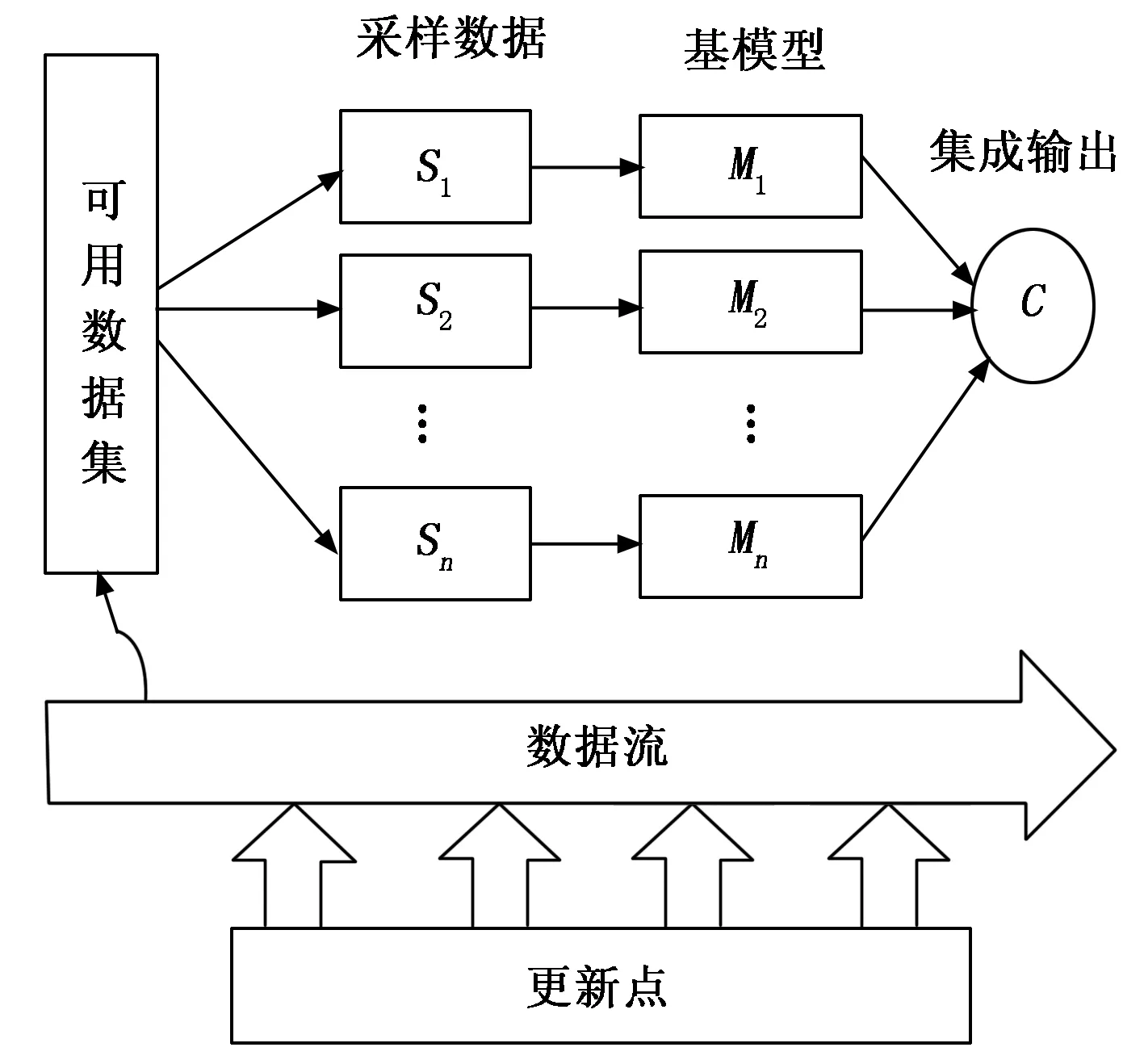
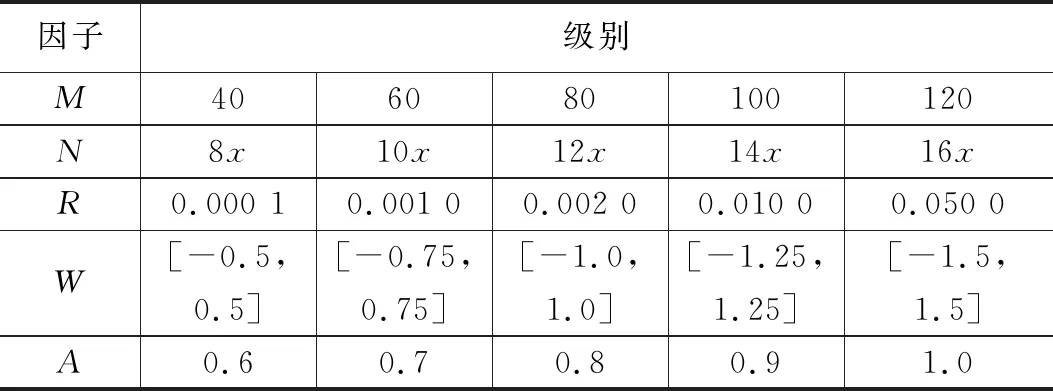
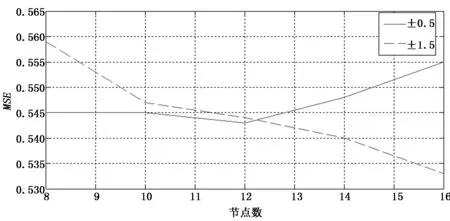
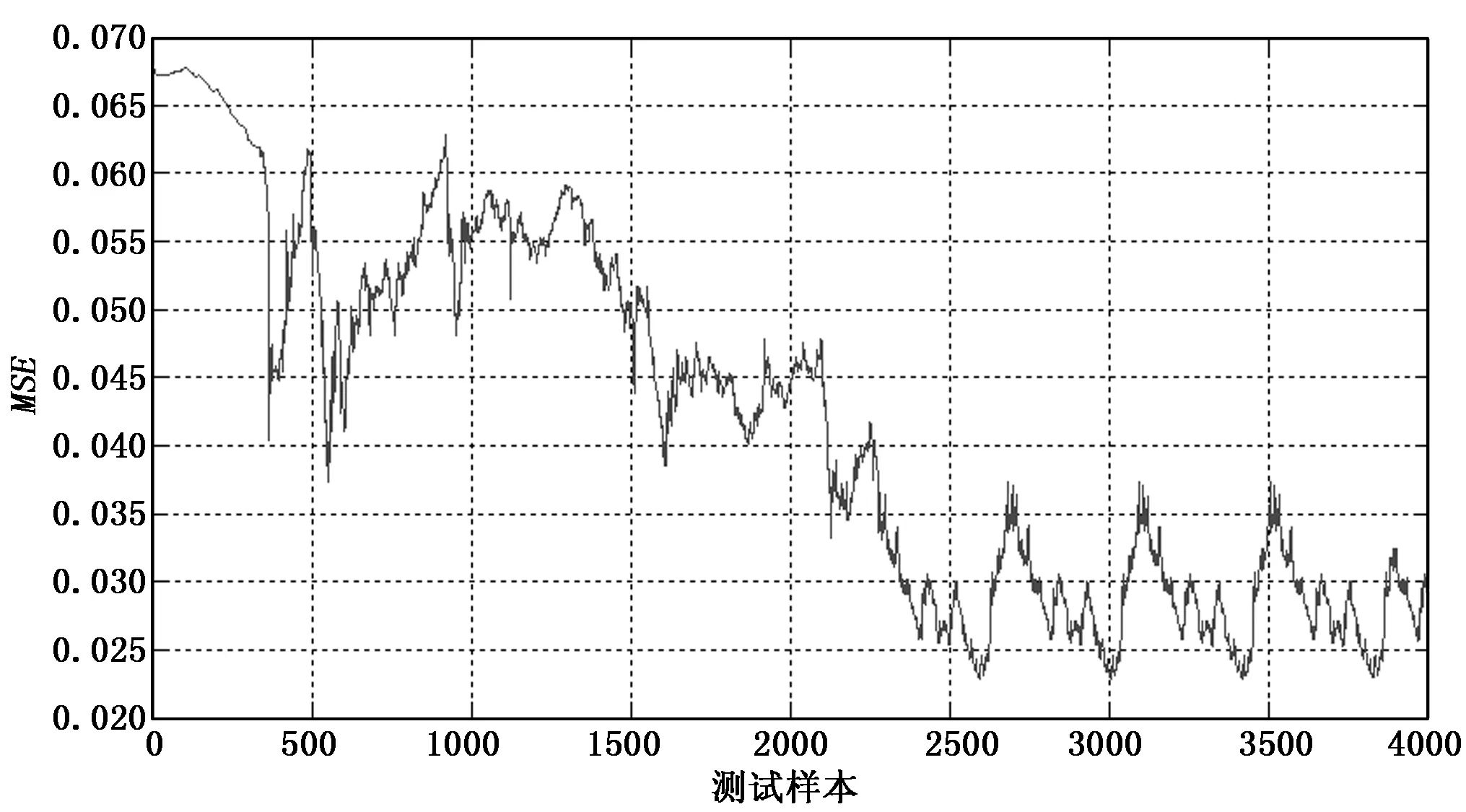
对每个数据集C,对具有最小输出误差的Q个模型(Q 由于输入数据存在数据漂移现象,势必造成集成模型的预测精度下降,当集成模型中某个基模型精度较差时,对该基模型暂时免于激活,而从处于失效状态而随时跟踪数据的基模型中选择预测精度较佳者进行替换。 1.2.2 最优权值确定 集成模型的输出结果为所选择最优的Q个基模型加权输出和。该权值直接影响集成模型性能,同时过于复杂的优化方法会增加算法的计算时间。因此选择的方法为集成模型中的每个基模型根据其在最近数据块的预测精度被分配权重。给定当前数据集C,输出由M个基模型(m=1,2,…,M)集成,每个基模型的权值计算如式(7)所示: (7) msem为第m个基模型在当前数据集C上计算得到的均方误差。数据样本xn的集成输出yE如式(8)所示: (8) 由式(8)可知,当基模型的预测输出的均方误差值较大时,则在集成模型的输出中所占比例相应较小。当预测均方误差值较小,则分配较大权重。 1.2.3 基模型的更新 为解决输入数据的漂移问题,参与集成输出的基模型需要进行更新,另外当基模型数量不满足设计要求时需要使用最新的数据集中的标记数据训练出新的基模型,在输入数据集中随机划分出70%用于训练,30%用于验证。如果新的模型精度好于已存在模型中精度最差者,则进行模型更新,这个过程一直重复进行,直到新模型的数量达到设计要求。给定替换率为r∈(0,1],新模型的数量Mnew计算如式(9)所示: Mnew=round(r*M) (9) 更新机制不仅保证集成模型与最近的数据同步,而且作为一种自然选择机制,能不断剔除低性能的基模型。 1.2.4 集成算法工作流程 随机权神经网络集成模型工作原理如图2所示。 图2 随机神经网络集成模型原理 将飞行遥测数据作为数据流,初始要求提供足够可用数据集用于构建一个原始的集成模型,该可用数据集作为原始数据集,采样数据S为对可用数据集进行有放回的随机采样获得,每个采样集用来训练得到一个作为基模型M的随机权神经网络,通过对N个基模型训练获得基模型池,选择最优的Q个基模型进行加权输出实现对输入数据的预测。初始集成模型构建完成之后开始对输入数据流进行预测,同时上述更新机制开始工作,由于在数据流中设置有更新点标志,当检测到更新点标志时,表示可用数据集为新增的数据集,一部分基模型对新增数据进行在线学习,当判断集成模型预测性能下降时对预测性能较差的基模型进行更新操作。 模型的超参数包括基模型的个数,每个神经网络内隐层层节点的个数,惩罚因子,随机权重值的范围等,超参数的选择优化对模型精度起着关键作用,而且超参间还具有相互作用,例如,在超参数A为1级别,算法精度随超参数B从1~2变化时提高,同时在A为2级别,算法精度随超参数B从1~2变化时降低,因此在超参数较多的情况下,增加了优化过程的复杂性。目前用于数据流预测的机器学习算法中,还缺乏系统的方法对超参数进行优化,一些方法如手动调整,网格搜索,贝叶斯超参数优化等,缺乏对某个超参数的重要性和超参数间的相互作用的考虑[10]。 鉴于使用全因子的实验设计(DOE)方法进行超参数调整能识别显著的超参数间的相互作用,因此提出采用全因子设计方法对集成模型的超参数进行调整,将初始可用数据集的前1 000个数据随机划分为70%用于训练,30%用于测试。具体过程分两步进行,首先对所有超参数在预定义的5个级别进行穷尽组合计算,通过对每个超参数的灵敏度进行分析,以及对超参数之间的相互作用的分析识别出重要的超参数和优化方式。之后开展新实验进行超参数的微调,通过将具有低重要性的超参数保持在固定水平,缩小参数的搜索空间,进而保证了算法的实时性。模型超参数具体设置如表1所示。 表1 超参数预设值表参数 其中,M为构成集成模型的基模型数量;N为基模型中隐藏层节点数量,N为输入数量的函数,具体为A因子与输入数量的积;R为惩罚因子,用于在优化过程中惩罚大的权值;W为随机权值分布区间,该参数确定初始化随机权值均匀分布在该区间内,模型精度起关键作用;A为特征属性数量,用于随机选择输入的一部分用于基模型进行训练。 选取飞行器位置、速度、弹道等10个属性的仿真数据作为训练集,其中飞行弹道为目标输出,其他参数作为输入向量集,利用本文提出的方法建立预测模型。 为评估模型对数据漂移的响应,基于遥测数据构造5 000采样点的数据集,将数据特征属性的变量域划分为10级,用前7级构造数据集的前2 000点,之后每隔1 000点扩展变量范围,人为形成数据的漂移现象。 每个超参数都决定模型的性能,但重要性不同,用于超参数优化的数据集为起始的1 000点数据,将前1 000点数据划分为两部分,70%用于训练,30%用于验证。每个超参数按表1划分的5个级别,共进行10次优化过程处理,经统计分析对超参数重要性进行评定,从而确定超参数优化顺序。根据F0显著性统计确定最重要的3个超参数顺序为随机权值范围W、基模型数量M和神经网络中的节点数N,获取参数最优设置如表2所示。 表2 最优超参数设置 通过超参数优化过程,也证明了隐藏层节点数量和随机权值范围间相互影响,如图3所示。 图3 超参数间相互关系 为评估集成模型性能,基于余下4 000点数据集进行仿真测试,测试结果的MSE曲线如图4所示。 图4 模型预测误差曲线 由图4可见,在漂移点出现后,模型仍具有较高的预测精度,说明该模型具有明显的抑制数据漂移的作用。 集成模型不仅提升了数据预测的精度,借助超参数最优化和基模型更新策略,也极大缩减了模型更新时间,模型更新时间可控制在0.02 s内完成。 针对遥测数据预测模型中,要求处理满足实时性和抑制数据漂移的问题,提出一种采用随机权值神经网络和bagging集成相联合的集成方法,通过随机的bootstrap采样保证训练集和随机权神经网络基模型的独立性和多样性,利用随机权神经网络的高效性,降低基模型训练的复杂性,缩短了基模型训练时间,提高了集成模型的处理速度,通过基模型的多样性和在线更新机制,提高了在数据出现漂移时模型预测的精度。通过对飞行遥测数据的仿真实验,结果表明该模型对遥测数据的预测精度得到了提升,对数据漂移现象具有抑制作用,同时该方法具有快速性等特点。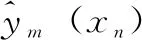
2 集成模型超参数的优化
3 仿真及分析
3.1 超参数优化仿真及分析

3.2 遥测数据仿真分析
4 结束语
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
成都信息工程大学学报(2022年3期)2022-07-21
探测与控制学报(2022年1期)2022-03-21
计算机测量与控制(2021年9期)2021-10-08
计算机测量与控制(2020年3期)2020-04-07
华人时刊(2016年16期)2016-04-05
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
现代电子技术(2009年7期)2009-06-25
