
一种改进的主动对话方法实现
2020-06-28 08:14贺峰
现代计算机 2020年14期
贺峰
(四川大学计算机学院,成都610065)
0 引言
随着人工智能浪潮的兴起,因为有着重大的研究价值和应用前景,对话系统逐渐成了研究的热门领域。学者们迫切的希望,机器可以理解人类语言,可以和人类对话,并成为人类的帮手。
近些年来,深度学习在很多领域中取得了越来越多的进步,例如图像识别[1]、自然语言处理[2]等。深度学习是机器学习中的一个分支,它通过构造一种神经网络结构,加上大量的数据来训练、学习这个结构。
在大数据的时代,数据量和算力的增加使得基于深度学习的方法逐渐成为了对话系统研究的主流方法。虽然学者们在对话系统领域中取得了越来越多的进步和成就,但是对话系统也有不少的缺点和不足。例如,数据驱动的算法表现受数据自身影响较大,并且,机器无法像人类一样,能够通过对话策略主动进行对话。
最近,Wu 等人[3]提出了一种新型的主动对话系统,发布了基线模型,并且给出了全新的主动对话数据集。文中通过引入显式的对话目标和对话背景知识图谱,赋予了对话系统主动对话的能力,让机器可以学习到人类主动对话的策略。
本文针对主动对话这一全新的任务,对算法进行了以下几个创新:
(1)针对对话上下文和知识表示的编码,使用全局门控进行了增强。本文在使用GRU[4]编码上下文和背景知识的同时,使用了一种全局的门控机制对编码后的信息进行过滤,进一步增强了编码的效果。
(2)针对对话上下文和知识表示编码后的融合,引入了双向注意力机制。对于主动对话这个任务来讲,如何对两种信息进行融合之后再解码是一个比较关键的问题。本文使用了一种双向的注意力机制对两种信息进行高效的融合,增强了信息融合的能力。
最后,我们通过实验来验证这两种方法的有效性。
1 主动对话研究现状
随着技术的进步和发展,构建一个更加智能的对话系统成为了自然语言处理领域里一个越来越受关注的话题,越来越多的新方法被学者们提出。但是现有的方法有一个缺点是只能被动的和人类进行对话,机器没办法去主动的进行对话,更无法去引导整个对话的进行。
为了解决这个问题,Wu 等人创建了一个全新的数据集,将一些额外的信息引入整个对话体系。更具体来讲,有两个额外的信息被引入到对话的过程之中:
(1)对话的背景知识。对话的背景知识是由一个知识图谱表示的,它由知识三元组构成,例如[‘范冰冰’,‘年龄’,‘38’]或者[‘范冰冰’,‘代表作’,‘还珠格格’]。对话的背景知识是对话进行的基础,在构建数据集时,标注者需要利用知识图谱的内容去完成一组对话。
(2)显式的对话目标。对话的目标是由对话背景知识图谱里的两个实体节点来表示的,例如“[开始]->[范冰冰]->[还珠格格]”,表示对话是从范冰冰这个主题开始到还珠格格这个主题结束。在构建数据集时,标注者需要通过对话目标来规划自己的对话策略,然后通过背景知识来构建回复。
以上两个方面构成了一组对话开始的前提,在标注数据的时候,需要依照上面两个部分的信息来生成对话。在构建数据集时,会有两位标注者分别充当对话的领导者和追随者。其中,领导者的角色就是根据对话目标和对话背景知识来引导整个对话,完成最终的对话目标。追随者只需要根据上下文对领导者的话进行回复。和以往的方法不同的是,在训练模型的时候机器模拟的不是追随者,而是模仿的领导者,也就是去主动对话的那个角色。
我们将在2.1 小节中具体介绍此方法的基线模型,分析其不足之处,并且在2.2 小节中提出针对性的改进。
2 模型算法
2.1 基线模型
基线模型由上下文编码器、知识编码器、知识选择器和解码器四个部分构成。他们的作用分别是编码上下文信息、编码知识、选择知识和解码出最后的回答。其结构如图1[3]所示。
首先上下文编码器和知识编码器分别使用了双向GRU 对各自的信息进行编码,得到了编码后的向量。接着,在解码的时候,通过注意力机制去选择与对话相关的知识。为了加强模型的知识选择能力,文中引入了知识的先验分布和后验分布。其中,先验分布是模型得出的知识选择的概率分布,而后验分布是人类推测的知识的真实选择,通过引入KLDivLoss 和BOWLoss 来强迫机器去模拟人类选择知识的行为,增强了模型的表现。最后,通过选择的知识和对话上下文信息解码得到了最终的句子。
可以看到模型中大概可以分为两个关键部分:信息编码与知识选择。
编码就是单独对上下文信息和背景知识信息进行编码,这是整个模型的基础。编码后的信息将用于之后的知识选择和解码。知识选择就是通过上述的信息,选择相应的知识来作为生成回复的依据,知识选的好坏也将直接决定模型的表现如何。
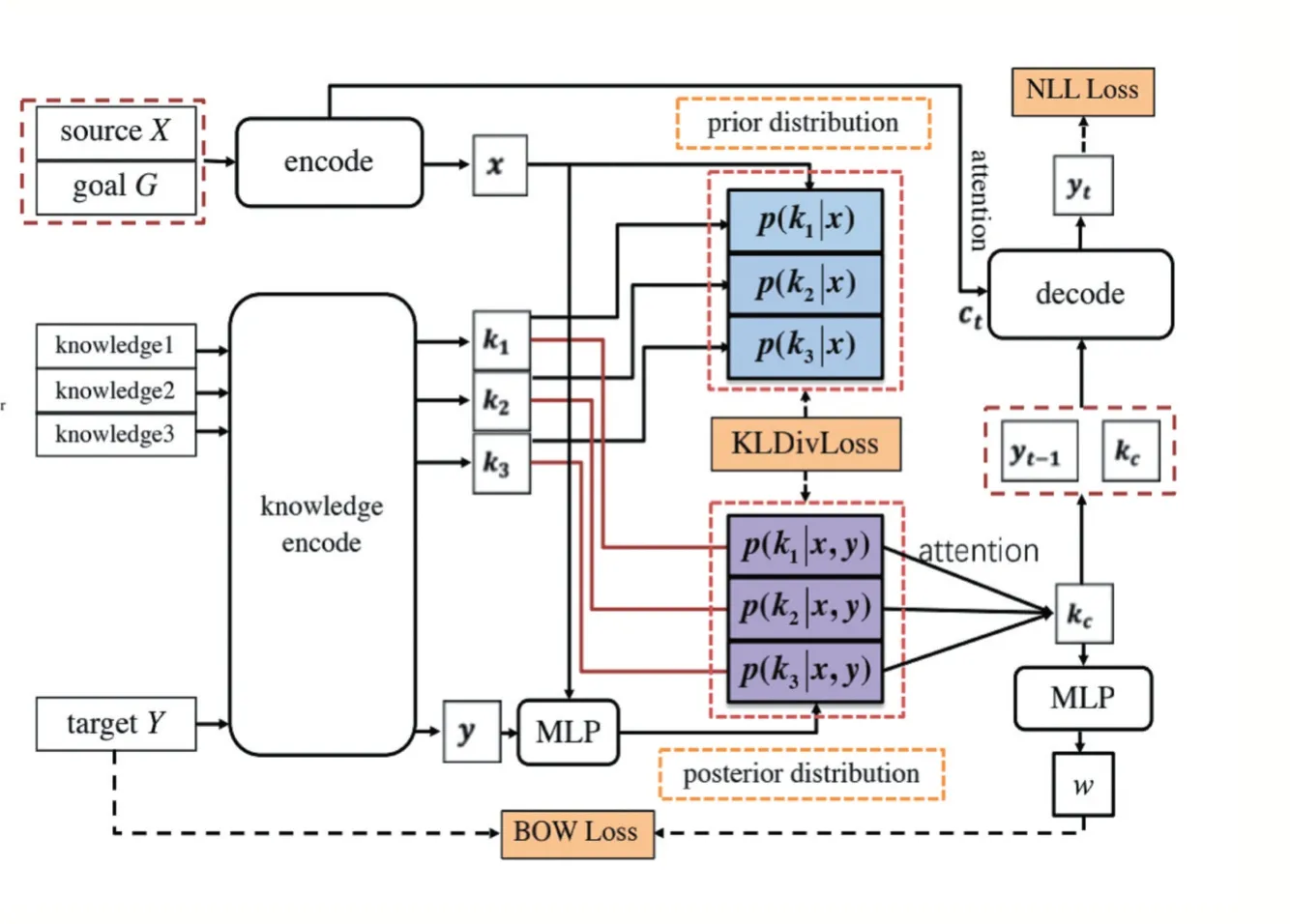
图1
所以,我们提出的模型改进也将从这两方面入手。
2.2 模型改进
通过对主动对话模型的分析,本文提出的改进主要聚焦于两个关键的部分:信息编码与知识选择。
(1)信息编码方面:
本文使用了全局的门控机制对编码后的信息进行过滤。门控机制被广泛的应用于NLP 的模型中,例如GRU 中的输入门和输出门。一般来讲门的作用是对编码之后的信息进行筛选和控制。针对主动对话的任务,引入全局的门控制机制的目的是更好地对上下文信息和背景知识进行编码。
门控具体的计算方式如下:
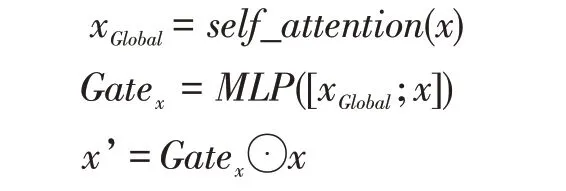
首先,我们使用GRU 编码句子,得到了句子的语义表示x。之后我们使用了自注意力机制[5]计算得到了句子的压缩编码xGlobal,它代表了句子的全局信息,我们希望通过这个全局信息来对句子进行进一步的信息过滤和控制。然后,我们通过全局的句子压缩编码和句子表示算出了每个时刻的门,而这个门的作用是对句子的表示来进行信息过滤。最后我们通过门和句子表示的按位乘法,得到了最终的句子表示。
(2)知识选择方面:
本文使用了双向注意力机制让对话上下文和背景知识的信息充分的进行融合。双向注意力机制是Seo等人[6]第一次在深度问答领域提出的一个结构,使用这个结构最终得到了一个问题感知的上下文表征。更进一步的讲,双向注意力机制提供了一个问题和文章交互编码的途径,得到了一种我中有你你中有我的交互的信息编码,一定程度上解决了深度问答中问题和文章的交互问题,这对于阅读理解模型的性能很关键。
在主动对话的任务中,我们使用这个结构去让对话上下文和背景知识进行交互。具体的计算方式如下:
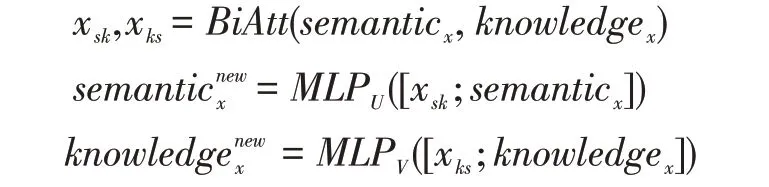
其中semanticx和knowledgex分别是对话上下文和背景知识的信息编码,BiAtt 代表的双向注意力机制。xsk和xks分别代表两个方向的注意力,一个是上下文关于背景知识的,另一个是背景知识关于上下文的。最后通过信息的拼接,我们得到了信息融合之后的编码表示和。 在基线模型中semanticx和knowledgex是用于解码的语义和知识信息,在我们提出改进后这两部分被替换为融合之后的信息也就是和。
3 实验结果与分析
3.1 评价方法
为了和基线模型保持一致,我们在这里沿用了BELU 作为评价指标。BLEU 是采用一种N-Gram 匹配规则的相似度计算算法,被用来评估句子与句子之间的相似度,得分越高我们认为两个句子之间越相似。具体的,我们使用BLEU-1 和BLEU-2 来评价,分别是BLEU 的1-Gram 版本和2-Gram 版本。
3.2 实验结果与分析
在不改变基线模型原本参数的条件下,本文对提出的两种方法做了消融实验,得到的结果如表1 所示。
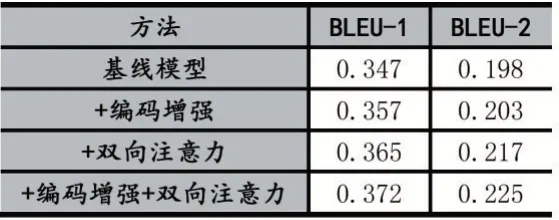
表1
实验结果验证了我们之前的分析,通过增强全局编码和信息融合这两种方法,均可以有效提升主动对话模型的表现。
4 结语
本文通过分析主动对话模型的特点,从信息编码和知识选择两个方面,提升了模型的性能。针对这两个方面,本文提出了两种结构:①全局信息增强的信息编码;②基于双向注意力机制的知识选择。最终,我们在主动对话的数据集中验证了我们提出的这两种结构,证明了它们的有效性。
在下一步的工作中,我们将尝试引入图神经网络去编码对话的背景知识。因为背景知识天然的是知识图谱的结构,而在文中我们却使用了GRU 来进行编码。尝试引入图神经网络这一为图而生的结构,或许可以带来更大的提升。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
汽车实用技术(2022年9期)2022-05-20
中国典型病例大全(2022年7期)2022-04-22
当代陕西(2022年4期)2022-04-19
小学生学习指导(中年级)(2021年12期)2021-12-30
科学与财富(2021年35期)2021-05-10
金桥(2018年4期)2018-09-26
人大建设(2018年7期)2018-09-19
