
基于高光谱图像技术结合深度学习算法的萝卜种子品种鉴别
2020-06-27 05:58杭盈盈李亚婷孙妙君
农业工程 2020年5期
杭盈盈,李亚婷,孙妙君
(江苏大学电气信息工程学院,江苏 镇江212013)
0 引言
萝卜是一种重要的根菜类蔬菜作物,在我国栽培历史悠久,分布广泛且在中国民间一直有“小人参”的美称[1]。萝卜可增强肌体免疫力,对防癌、抗癌有重要意义。但我国萝卜产业也存在着品种良莠不齐、栽培技术落后和生产模式分散等问题,种子品种不一样,其价格也不一样[2]。一些不良商家为了牟取暴利用廉价种子冒充高价种子贩卖给农民,导致农民利益受到损失。
传统的种子品种检测方法如形态鉴定、显微鉴定、微形态鉴定及微性状鉴定,其操作简单,但是由于种子的鉴定特征在各个科属中存在的变异很难达到鉴别种子的目的[3]。而高光谱图像技术作为一种能够快速无损检测的技术,它兼具机器视觉和光谱分析技术的优点且已经被广泛地应用到种子的成分测定和品种鉴别等领域[4-5]。
但是由于高光谱技术得到的光谱数据信息量大、冗余性强,所以需要使用特征提取算法对光谱数据进行降维。成忠等[6]通过连续投影算法实现小麦近红外光谱特征波长的选择。传统的特征波长选择方法虽然获得了更理想的效果,但是其模型有时存在一些干扰信息[7-8]。
近年来,深度学习发展前景广阔,堆叠自动编码器(SAE)通过对高维数据进行特征学习已被应用在各个方面[9-11]。孙俊等[12]通过将低秩矩阵与堆叠自动编码器结合实现对茶叶品种的鉴别。深度学习可以提取数据深度特征并提高模型鲁棒性,且目前结合深度学习与高光谱技术鉴别萝卜种子品种的文献较少。
为了探究应用可见近红外高光谱技术结合深度学习算法对萝卜种子品种鉴别的可行性,该文以6种萝卜种子为研究对象,利用3种降维算法(SPA,VISSA,SAE)结合Softmax与SVM分类模型分别建立萝卜种子品种鉴别模型,从而得到鉴别萝卜种子品种的无损检测方法。
1 材料与方法
1.1试验样本
本试验所选取的6种萝卜种子样本是镇江种子站提供的满膛红、胭脂红、杨花白、扬州园白、短叶十三和南京红。选取无外部缺陷的种子作为试验样本。从每种种子中选取适量样本分别放入广口试剂瓶,并做好标签且密封保存。采用将每类种子选取5.4 g聚拢摆放在一个半径1.8 cm、高0.8 cm的瓶盖中的堆叠摆放方式进行光谱采集[13]。
1.2高光谱图像采集与数据提取
本试验所采用的高光谱成像系统,主要包括1台装有光谱成像软件的电脑、分光模组(V10E,SPECIM,Finland)、成像相机(Zyla4.4,andor,UTKL)、光纤卤素灯(3900E型,Illumination Technologies,USA)、电位移动平台(MSI300,ISUZU OPTICS,TaiWan)和暗箱(DC1300,ISUZU OPTICS,TaiWan)。光谱仪为可见-近红外光谱仪,光谱范围400~1 000 nm,光谱分辨率2.8 nm,图像分辨率2 048×2 048像素。采用半径1.8 cm、高0.8 cm的塑料圆形器皿放置萝卜种子样品。在试验中将相机的曝光时间设置为20 ms,同时电控位移平台的移动速度设置为2.47 mms且进行黑白板校正。将种子样品放在移动平台上进行数据采集。
高光谱图像数据的采集使用HSI软件平台,在每个样本中选取20×20像素的矩形感兴趣区域(region of interest,ROI)并计算各个像素点的反射率,将其平均值作为该样本的反射率,每类种子选取60个样本,共获得360个样本。
1.3算法介绍
1.3.1堆叠自动编码器(SAE)
自动编码器(auto encoder)是在1986年由RUMELHART DE等[14]首次提出并将其用于高维复杂数据处理,之后更是促进了神经网络的发展。AE模型结构可以看作1个由输入层、隐含层和输出层3层结构组成的深度学习模型,自动编码器常被用于降维或特征学习[15]。
堆叠自动编码器(SAE)是将多个AE通过级联方式堆叠构成的多层AE。SAE采用的是逐层非监督预训练,其将上一层的隐含层作为下一层的输入,同时在预训练之后会执行细化调节,通过上一步预训练得到的权重来初始化网络,以获得最优参数,并将最后一个隐含层输出作为光谱数据的深度特征[16]。
1.3.2连续投影算法(SPA)
连续投影算法是一种使矢量空间共线性最小化的前向变量选择算法,能够提取波段中的特征波长,且消除原始光谱矩阵中冗余的信息,可用于光谱特征波长的筛选。连续投影算法的实现可分为两个阶段:第1阶段完成p个波长分组各M个波长,选M的最大可能取值为M=min(n,p);第2阶段借助多元定量校正模型完成m个(1≤m≤M)最优波长的选定[6]。
1.3.3变量迭代空间收缩方法(VISSA)
变量迭代空间收缩算法是一种基于模型集群分析的算法,其主要思想是在每次迭代的过程中逐步优化变量空间,最终实现对最优变量组合的选择。其每次迭代过程满足变量空间逐渐收缩和优化准则。用VISSA选出的变量建模,其主要优势是考虑变量组合的影响和变量空间的软性收缩[8]。
1.3.4Softmax模型
Softmax函数是Logistic函数在多分类问题上的推广,将分类问题转化为概率问题从而实现对多个类别的分类任务。Softmax作为一种有监督的神经网络常与深度学习的方法结合进而用于分类识别问题中[17]。Softmax的训练过程是首先通过对Softmax分类器进行训练,然后检查损失曲线收敛是否满足要求;最后利用训练好的分类器进行分类[18]。
1.3.5SVM模型
SVM算法是一种经典分类算法,是按监督学习方式对数据分类的分类器。SVM能够无限逼近复杂系统,且在样本数量比较少的情况下可以获得最优的泛化能力。其主要思想是将输入数据空间映射到高维空间,寻找一个最优分离曲面,使得数据的间隔尽可能大从而得到一个全局最优解,完成分类任务[19]。
2 结果与讨论
2.1光谱数据分析
本试验共获得478个波段在400.68~1 001.6 nm的光谱信息,为提高分类效果,去除部分噪声明显的波段后共获取了411个波段在480.46~1 001.6 nm的光谱信息作为原始光谱数据,如图1所示。根据每个品种在每个波段内的反射率平均值得到每种萝卜种子样本的平均光谱曲线,如图2所示。由于萝卜种子属于十字花科油脂类种子,不同品种的萝卜种子样品内部的有效成分(如抗真菌蛋白Rs-AFP1、Rs-AFP2和氨基酸等)的含量与比例存在差异,这些成分大多存在含氢基团(C—H、O—H和N—H等),能在某些特定波长下产生倍频和合频吸收,其表现为对光的吸收强度不同,即表现为不同的反射率[20]。由图2可知,萝卜种子的光谱特征差异明显,重叠部分较少,在波长为930 nm时,满膛红的反射率最高,短叶十三的反射率最低,其光谱特征为萝卜种子的品种鉴别提供了依据。
2.2光谱数据预处理
本次预处理算法在The UnscramblerX10.4中运行。
对光谱数据进行预处理可有效抑制和消除光谱数据中的噪声,提高所建立模型的性能。采用Savitzky Golay(SG)平滑对光谱数据处理,使用SG平滑可以在一定程度上消除高频随机误差,提高信噪比。同时将经过SG平滑处理后的数据通过多元散射校正(Multiple Scattering Correction,MSC)进行处理,MSC算法通过对每个波长点的光谱数据进行散射校正,能够有效地消除散射影响,增强与目标成分含量相关的光谱信息[21]。光谱预处理后曲线如图3所示。
2.3数据降维
通过改变SAE的隐含层个数及每层神经元个数来探究不同模型架构对最终特征学习结果产生的影响。通过将SAE最后一个隐含层输出的数据输入到Softmax分类器中,并通过训练集和预测集的准确率来确定该隐含层的最优神经元个数。本试验的SAE学习率为0.2,且激活函数为sigmoid函数。SAE的优化参数如表1所示。通过对比可以发现,改变SAE的隐含层个数及每层神经元个数对学习结果有一定的影响。当隐含层层数增加时,其最优模型的准确率反而在逐渐下降,其训练难度与时间也增加。因此选择了简单的两个隐含层的SAE,模型架构为[411-212-125],共获得125个深度特征,其训练集和预测集准确率分别为99.72%和96.22%。
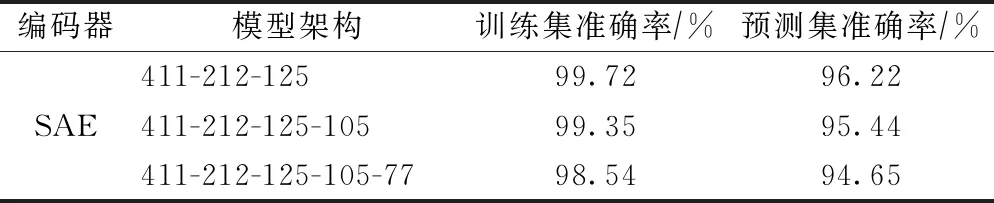
表1 堆叠自动编码器的优化参数
SPA模型的最优样本集是通过计算不同样本子集的多元线性回归模型的均方根误差RMSE值来选取的,当RMSE值最低时代表的子集就是最优样本子集。图4所示是不同子集模型的RMSE值,其中“□”代表最优样本子集的样本数,从图4可知,当变量数<25时,RMSE值整体呈下降趋势,当变量数≥25时,变化趋势趋缓。因此,本文利用SPA共选取25个特征变量。图5所示是具体变量的选取,“□”代表选取的变量,其中横轴初始变量代表480.46 nm的波长,终止变量为1 001.6 nm的波长,纵轴代表反射率。
VISSA模型是通过不断降低交互验证均方根误差(RMSECV)来获取最佳特征变量组合,RMSECV值越低,则模型所选择的变量组合越好[22]。本模型的Plscv偏最小二乘法的交叉验证程序采用的是10折,潜在变量数设为10,交叉验证为五折交叉验证,二进制矩阵采样的数量设为1 000,变量初始权重设为0.5。VISSA模型的运行结果如图6所示,RMSECV值随着迭代次数的增加在不断地下降,经过45次迭代后,RMSECV值达到最小值0.721 0,且最终保留112个变量。
2.4分类结果
本试验建模算法均在Windows 10系统下,利用Matlab R2016b软件完成的。通过结合Softmax分类器对全光谱数据采用五折交叉验证的方法进行验证,其训练集和预测集的比例为4∶1。原始光谱的训练集和预测集的准确率分别为90.1%和85.0%。
将降维模型获得的低维光谱数据通过五折交叉验证处理,分别采用Softmax分类器和SVM两种分类算法进行建模,各模型分类的预测集准确率和训练集的准确率如表2所示。
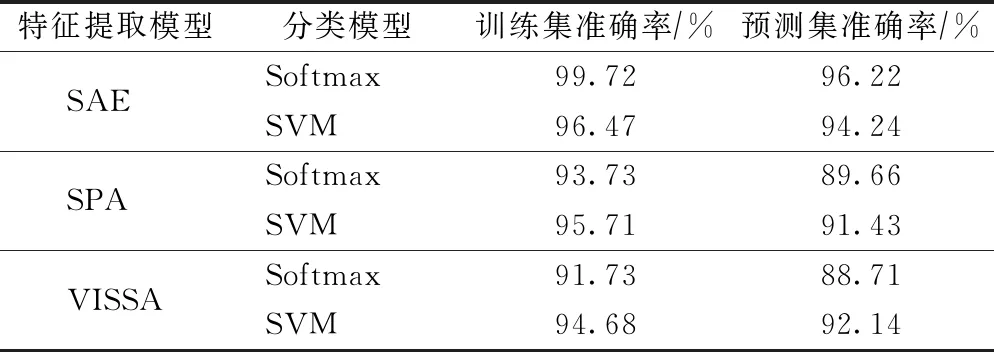
表2 分类结果
对构建的3种降维模型进行分析,可以发现本文模型均改善了种子的分类效果。构建的SAE模型的训练集和预测集的准确率相较于其他传统的特征提取模型的准确率高一些,且SAE与Softmax分类算法结合的预测集准确率高达96.22%。根据本次试验结果可以发现,SAE模型对于萝卜种子的深度特征学习效果更好。而对Softmax和SVM两种分类模型进行分析,可以发现两类模型中分类效果较好的是Softmax模型。而分类的预测集准确率也由最初的85%提高到96.22%。
3 结论
(1)通过光谱采集仪器获取萝卜种子样品的可见近红外光谱数据。对进行预处理后的近红外光谱数据分别采用SAE、SPA和VISSA进行数据降维,其维度分别为125、25和112。其中SAE提取的深度特征在Softmax和SVM分类模型中的分类预测效果都优于SPA和VISSA算法。因此本研究选取SAE,将光谱数据降到了125维。
(2)对选取的特征波长变量分别通过五折交叉验证的方法进行Softmax和SVM分类建模。比较分类预测结果可知,SAE-Softmax模型的分类结果最优,其训练集和预测集准确率分别达99.72%和96.22%。
综上所述,结合可见近红外高光谱技术与SAE-Softmax模型对于萝卜种子品种的鉴别是可行的。同时,本研究也为快速检测种子品种的装置提供了理论基础,具有一定的学术与实用价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
小天使·一年级语数英综合(2019年3期)2019-04-19
学生天地·小学低年级版(2018年9期)2018-12-03
食品工业科技(2014年23期)2014-03-11
幼儿时代·故事妈妈(2004年11期)2004-04-14
