
试析基于云计算环境的web数据挖掘
2020-06-24 12:56田笑
锦绣·中旬刊 2020年3期
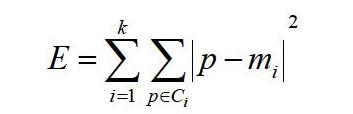
摘 要:本文针对基于云计算环境的web数据挖掘,结合理论实践,在简要阐述云计算特性的基础上,分析云计算环境下web数据挖掘的流程,并提出web数据挖掘的关键技术。希望对提升云计算环境下,web数据挖掘的准确性、速度等有一定的参考和帮助。
关键词:云计算;web;数据挖掘;数据预处理
引言
在云计算环境下,web数据挖掘的方法发生了较大概念。云计算为web数据挖掘提供动态化资源和高可用行的计算平台,为开发高性能的数据挖掘平台提供技术支持。但web数据量大,而且具有较大的噪音,对挖掘算法的要求比高。而基于云计算环境的web数据挖掘,可有效降低运营在数据挖掘技术上的投入,加快web数据挖掘速度,缩短产品研发周期。基于此,开展基于云计算环境的web数据挖掘的分析研究就显得尤为必要。
一、云计算的特性
(一)虚拟化
云计算是一种全新的技术,用户可以在任何位置、任何时间来获取各种终端的应用程序。并且请求的数据和资源全部来自于云环境,并非固定的实体,可为用户提供便捷的服务。
(二)通用性
云计算和其他技术相比,并不是针对特定的应用,可以在云支撑下,满足用户不同的需求,一个云同时服务于多个应用平台和系统。
(三)高可扩展性和超大规模性
云可以实现动态化扩展,并且此种扩展对用户来说几乎的透明的,并不会影响用户的使用情况。此外,云的动态化扩展是超大规模的,比如:微软、亚马逊等云计算,有上百万台 服务器。
二、云计算环境下web数据挖掘的流程
在云计算环境下,可实心web数据挖掘技术的全面优化,云计算高强的并行处理能力和海量存储能力,可有效解决web数据挖掘海量数据的问题。web数据挖掘的流程包括以下三个步骤:
第一步,web数据收集。web数据挖掘的主要对象是日志信息,也就是用户在应用web系统式留下的日志数据,这些日志数据并存子在web系统的数据库中。一旦数据库发生问题,存储在数据库的数据也会发生丢失或者破坏。因此,为保证数据的安全性,需要将数据库中的数据进行筛选、转换、统一处理,形成半结构化的XML文件,保存在分布式文件中。此种做法既能优化数据收集方法,也可以避免数据库中存储的数据因为设备发生损失[1]。在云计算环境下,web数据挖掘可有效保证数据的共享性,降低web数据应用门槛,保证数据库中各项有价值、有用的数据能够被充分利用。
第二步,数据预处理。通过数据预处理可为web数据挖掘提供良好条件。主要目的是对采集到的数据进行净化处理,以删除无用的数据。从日志数据中识别出多个用户,以确定哪些信息同一个用户留下的。再讲相同用户访问记录按照不同的访问时间区分开来。区分完成之后再进行格式化处理,转换成符合web数据挖掘算法要求的格式存储起来,以便后期挖掘使用。
第三步,数据分析。通过一系列web数据挖掘算法,对预处理后的数据进行分析,进而发现其中隐藏的有价值的数据。数据使用的目的不同,采用数据挖掘算法也不相同。比如:统计分析算法,通常应用在日志数据统计中。关联规则算法,多应用在挖掘用户之间或者页面之间的潜在关系上等。
三、云计算环境下web数据挖掘的关键技术
(一)云计算技术
分布式计算是云计算技术的关键,主要作用是解决海量数据挖掘的难度,提升数据挖掘的精度和效率。分布式计算涉及到两方面内容,其一是分布式存储,其二是并行计算。云技术环境既能提供数据的分布式存数,也可以满足并行计算的能力,为web数据挖掘提供良好的环境。在web数据挖掘中,分布式并行计算是高效完善数据计算和挖掘任务的基础,可对一些技术细节进行封装处理,包括:数据分布处理、任务并行处理、任务调度处理、负载平衡处理等。在用于在应用时,无需考虑这些内容,只要考虑web数据挖掘任务之间的逻辑关系即可。从而提升研发效率,降低系统维护成本。
(二)数据汇集调度
通过数据汇集调度,可有效解决不同数据之间的规约问题,而且支持不同格式的数据,无论是OLTP数据、OLAP数据,还是日志数据、爬虫数据,都需要提供数据同步的方式,如:数据库同步、socket消息同步、文件传输协议同步等。云计算环境中数据汇集调度多采用模板化设计技术,以满足新数据的模板和元数据配置的统一收集及规约,提升web数据挖掘的效率。
(三)挖掘算法并行化技术
web数据挖掘中的并行化是云计算平台的基础能力之一,在web数据挖掘中国并行化技术是否科学合理性,直接关系到web数据挖掘算法是否并行,并行策略是否有效等。常用的并行化算法是K-means算法,其核心思想是基于使聚类性能指标最小化[2]。具体应用流程为:线随机选择k个web数据挖掘对象,每个对象都可看做是一个簇的初始均值和中心;然后对剩余的对象,按照每个的均值距离,指派到最相似的簇中;最后通过平方误差准则,来计算每个簇的新均值,此环节可不断重复,直到准则函数完成收敛为止。具体表达公式如下:
此公式中,E表示数据集中所有对象的平方误差和;p表示空间中的点,也就是给定的对象;mi表示簇Ci的均值,在web数据挖掘中,先求出对象到其簇中心均值的平方,再求和,从而挖掘出数据库中的有价值的全部信息。
四、结束语
综上所述,本文结合理论实践,分析了基于云计算环境的web数据挖掘,分析结果表明,云计算环境下,对web数据挖掘提出了更高的要求,数据量越来越多,种类更加繁杂。加强对云计算技术、数据汇集调度、挖掘算法并行化技术的创新研究,有助于提升web数据挖掘的效率和精度,促进我国数据挖掘水平不断提升。
参考文献
[1]王建明.云计算环境下对Web数据挖掘技术的研究[J].现代信息科技,2019,3(05):108-109+112.
[2]張珍.云计算环境下的数据挖掘算法探究[J].网络安全技术与应用,2019,221(05):61-62.
作者简介:
田笑(1999-),女 汉族 河南省开封人 河南大学 软件学院 2017级本科生在读 ,研究方向:软件工程
猜你喜欢
西部交通科技(2021年9期)2021-01-11
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
哈尔滨理工大学学报(2016年2期)2016-09-12
计算机教育(2006年9期)2006-09-22
