
基于大数据的招聘信息爬虫技术研究与实现
2020-06-24 03:06张婷姚仿秋
中国新通信 2020年2期
关键词:网络爬虫
张婷 姚仿秋
摘要:網络招聘中信息量巨大,数据冗余较多,导致很多求职者在浏览招聘信息时往往不知道如何选择。网络爬虫,一种基于python语言的专有性搜索工具,能够将网络上的信息下载保存到本地,还能将网页爬取到的大量信息用于数据分析和大数据研究。
本文实现了Scrapy爬虫对招聘网站的数据爬取,通过搭建Flask框架对采集的数据进行可视化分析。其分析结果可以帮助求职者在浏览招聘信息时更好地评估工资水平,有效地判断招聘信息是否合理,进而有效提高求职者在寻求招聘岗位时的效率。
关键词:网络爬虫;Scrapy框架;网络招聘信息
随着互联网的高速发展和大数据时代的来临,网络招聘已经成为企业之间人才竞争的主要手段。相对于传统的线下招聘而言,网络招聘成本低、覆盖面广、易于发布信息、招聘信息种类众多[1],通过网络平台求职者还可以更快地与招聘者进行沟通联系,节约了彼此之间的时间成本。同时由于“互联网+”经济的蓬勃发展,使得网络招聘成为我国招聘市场的主流趋势[2]。招聘信息本身存在不同时段的时效性,不同政策的工资变化不同,冗余度大,成效低,让求职者很难匹配到自己心仪的工作。
本文使用网络爬虫技术爬取三个招聘网站的招聘信息,将爬取下来的招聘数据进行智能可视化分析,发掘数据中隐藏的价值,摸索网站招聘规律。通过得出结论,可以更有效地帮助求职者找到适合自己的工作。
一、网络爬虫技术概述
随着大数据时代的来临,互联网上的数据容量爆炸性地增长,高性能的网络搜索引擎以及定向的信息获取的需求,使得网络爬虫技术逐渐成为人们研究的对象。网络爬虫就是通过模拟浏览器发出网络请求,获取网站服务器返回的响应,并按照一定需求爬取数据的脚本程序。网络爬虫可以分为两类:通用爬虫和聚焦爬虫。
1.1 通用爬虫概述
通过用户初始规定的一个待爬取URL地址列表,爬虫从中按顺序爬取URL地址,通过DNS解析获得到主机网页的ip地址,然后交给下载器去下载网页,将采集成功的网页保存到本地磁盘中,并且将已爬取的URL地址做出标志防止二次爬取,保存到磁盘中的网页又存在许多链接信息,再从中抓取URL地址放入待爬取列表中去进行分析。如果发现有未下的url就放在待抓取url队列的列尾,从而等待调度下载。如此循环下载,待抓取队列为空时,爬虫就完成了对网页的下载。
1.2 聚焦爬虫概述
通用网络爬虫所采集的网页数据和正常用户在浏览器中访问的数据是一样的,而在大多数情况在,这些网页数据中有90%是对用户来说是不需要的。聚焦爬虫则可以根据用户的需求而去爬取特定的一些内容,是一种面向主题、面向需求的爬虫。本次论文所使用的爬虫就是聚焦爬虫。
二、搭建Scrapy框架
2.1 Scrapy框架
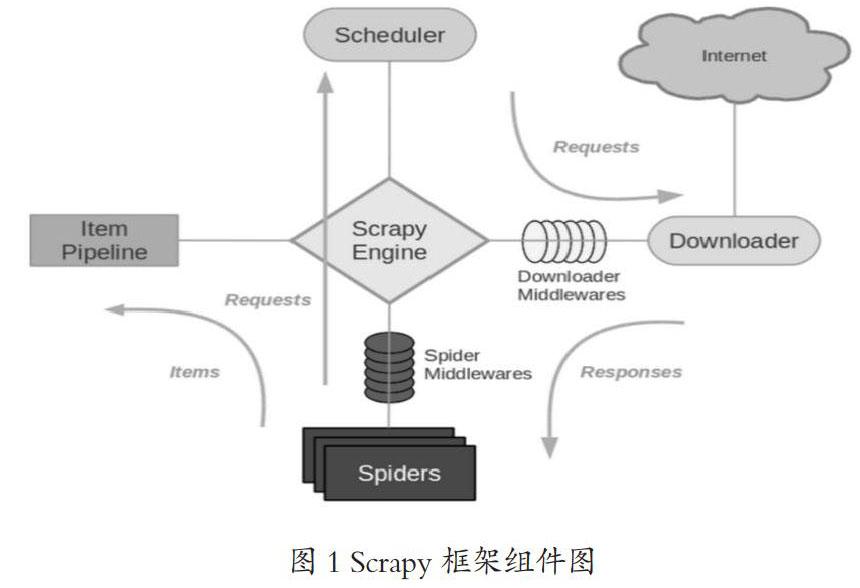
Scrapy框架是Python语言开发的,基于Twisted异步网络框架的开源爬虫框架。用户可以根据需求在Scrapy框架各个模块中编写好要爬虫的规则、存储的结构,就能快速、灵活地爬取web网站的数据。其主要的框架组件有以下几个:
(1)Scrapy Engine(引擎)组件:负责各个组件之间的连接、信号传递
和数据通信,是整个框架组件的核心。
(2)Spiders(爬虫)组件:用来定制爬取web网页的规则,发出Request
请求到Schedule(调度器),同时也接收Downloader(下载器)发送过来的Response响应,并从中提取到item字段所需要的数据由引擎发送到Item管道,如果有需要根据的url链接,就继续提交给调度器。
(3)Schedule(调度器):接收到爬虫组件发送过来的Request请求,将请求进行入队列处理,进而交给Downloader下载。
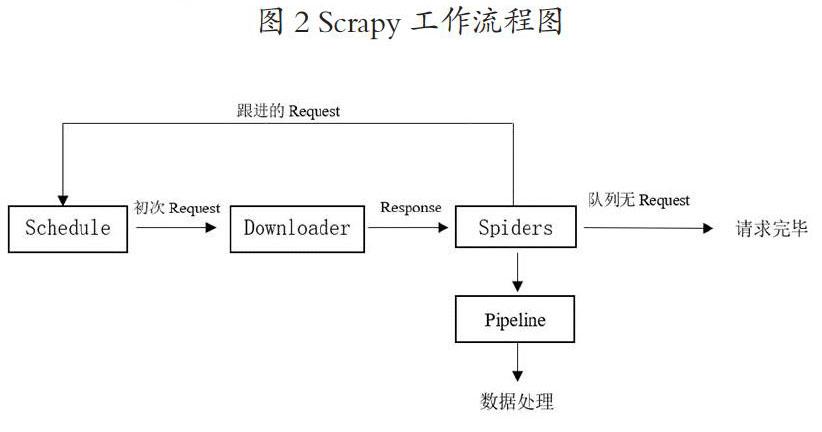
Scrapy架构图如下所示,其中绿线表示数据流向。
图2为Scrapy框架的工作流程图。
三、 基于网络爬虫的数据采集实验
本研究的实验基于Python软件进行,对北京计算机岗位招聘信息进行爬虫实验,其中爬虫程序运行过程如图3。
运行完毕之后,打开navicat可视化工具查看下载的招聘数据内容,如图4。
三个爬虫项目最大的区别在于各自网站数据传输的URL,这是各不相同的,通过抓包分析能获取到网站数据传输的Json地址,将其包装到爬虫模块中去发送请求。前程无忧和拉钩网爬虫项目的反爬虫设置、数据库连接、数据清洗都与智联招聘网爬虫项目一致。执行各自的爬虫名即可完成对网站数据的抓取。
四、结论
本文实现了使用Python的Scrapy爬虫框架对三个招聘网站的招聘信息采集,本文从求职者的角度去进行数据分析,利用Flask框架简单,灵活的特点,完成后台服务器的搭建和使用SQLAlchemy模块对采集的数据进行操作,实现可对不同岗位进行搜索分析的网页。求职者可以通过图形的分析结果进而判断招聘信息是否合理,有利于更好地选择工作。
参考文献:
[1]杜玉帆,杜莹莹.“互联网+”时代下网络招聘行业发展探析[J].中国市场,2018(11):180-181.
[2]耿玉德,张元元.招聘网站求职满意度影响因素分析——以高校大学学生为例[J].工业经济论坛,2018,05(05):82-89.
[3]杜玉帆,杜莹莹.如何应对网络招聘中的虚假信息[J].中国市场,2018,(11):180-181.
[4] 北京大学天网搜索引擎[EB/OL].http:∥pku.edu.cn,2019-05-03
[5]赵禹婷.我国网络招聘市场的现状及提升对策研究[J].现代交际,2019(05):243-244.
[6]毕宁宁. 移动互联网环境下企业招聘渠道研究[D].东北师范大学,2018.
[7]郭越. 虚假网络招聘中的法律问题研究[D].山西大学,2018.
[8]郑毅. 某公司招聘管理系统设计与实现[D].电子科技大学,2018.
[9]赵丹. 网络招聘信息的分析与挖掘[D].贵州财经大学,2017.
[10]彩广畏. 从网络招聘信息看我国人才需求状况[D].湖南师范大学,2017.
作者简介:
张婷,(1982.08.29-),女,岳阳职业技术学院,414000,汉族,湖南省岳阳市,硕士,讲师,大数据。
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24
电脑知识与技术(2017年1期)2017-03-24
计算机时代(2017年2期)2017-03-06
中国新技术新产品(2017年4期)2017-03-04
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技经济市场(2016年2期)2016-06-16
电脑知识与技术(2016年7期)2016-05-19
