
一种基于质心的多标签文本分类模型研究*
2020-06-22 12:29李校林
计算机工程与科学 2020年6期
李校林,王 成
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065; 3.重庆信科设计有限公司,重庆 400021)
1 引言
随着网络的快速发展,网页新闻机构或社交网络随时都会产生大量的电子文本[1 - 3]。在这种情况下,文本分类TC(Text Classification)成为发现和分类文档的关键技术[4,5]。
TC是一种将未标记的文本文档自动分配到预定义类别的方法。近年来由于文本检测、垃圾邮件过滤、作者识别、生物信息和文档识别等数据处理需求的增长,TC越来越受到关注并被广泛应用于各个领域[6 - 10]。多标签分类是1个实例可以同时分为多个类别[11]的一种方法。例如1篇关于基督教会对“达芬奇密码”电影发行的报纸文章可同时标记为“宗教”和“艺术”2种类别。
在过去几年中,学者们已经提出了大量算法来学习多标签数据。多标签学习算法可分为2类[12]:(1)问题转换算法;(2)自适应算法。第1类算法将多标签学习问题转化为其他成熟学习场景。代表方法有二元相关性BR(Binary Relevance)[13]、标准校准标签排名CLR(Calibrated Label Ranking)[14]和随机k-标签集(Random k-labelsets)[15]。第2类算法通过调整常用学习技术直接处理多标签数据来解决多标签学习问题。代表性算法包括多标签k-最近邻算法ML-KNN(Multi-Label K-Nearest Neighbor)[16]、多标签决策树ML-DT(Multi-Label Decision Tree)[17]和排名支持向量机Rank-SVM(Ranking Support Vector Machine)[18]。
2类算法都有各自的优缺点。问题转换算法具有低计算复杂度的优点。然而,当数据非常大并且导致较低的分类准确度时,它将受到类不平衡的影响。自适应算法可以通过考虑每个标签有效地解决类不平衡问题,但计算复杂度非常高。为了解决这些问题,本文提出了一种基于质心的多标签文本分类模型ML-GM(Multi-Label Gravitation Model)。
该模型的提出是基于质心分类器并参考GM(Gravitation Model)[19]。由于在该模型中质心覆盖的区域将在所有方向上均等地扩展或收缩,可以直接缓解类不平衡问题。而基于质心的分类器CBC(Centroid Based Classifier)[19]的计算复杂度在训练阶段是线性的,因此它比其他TC方法更有效,这一优势对于在线文本分类任务很重要[20 - 23]。 实验结果表明,ML-GM在平均精确度、AUC、1-错误率和汉明损失方面优于现有的多标签分类算法。
2 相关工作
2.1 相关问题
尽管文本分类方法已被研究了很多年,但是很少有作者在CBC中研究过这个任务[24]。基于CBC分类高效的特点,本文提出了一种多标签文本分类模型,称为多标签引力模型(ML-GM)。其主要思想是通过判断未定义实例和质心的相对引力是否属于在训练阶段学习的引力区间内来执行多标签分类。基于质心的多标签分类过程如图1所示。
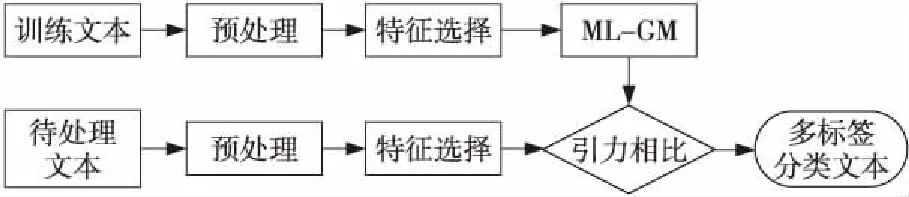
Figure 1 Flow chart of ML-GM classification图1 ML-GM分类流程图
2.2 质心分类器
文档由基于质心的文本分类中的向量空间模型VSM(Vector Space Model)[25]表示。比如文本dj=(ω1j,…,ωkj),k是术语(特征)集的大小,ωij代表文档dj中第i个术语ti的权重,不同术语在一个文本中具有不同的重要性。术语加权是通过为术语指定适当的权重来提高TC的有效性的重要步骤。在术语加权方法中,术语频率和反文档频率TFIDF(Term Frequency and Inverse Document Frequency)是最著名和最常用的方法,如式(1)所示[19]:
(1)
其中,tf(ti,dj)是术语ti在文档dj中出现的频率,|D|是训练文档的总数,|D(ti)|表示包含术语ti的文档数。术语权重的规范化执行方式如下所示:
(2)
2个文档之间的相似性可以用余弦公式来测量:
(3)
其中,“·”表示向量的点积,‖d‖2表示d的L2范数。
质心向量cj是通过对Cj类中所有文档向量进行求和并进行归一化。质心向量可以用式(4)来表示:
(4)
文档向量和质心向量之间的相似性可以用余弦公式进行测量:
(5)
最后,未定义文档将被分配到最相似的类别:
(6)
3 ML-GM方法
3.1 GM
GM[19]是受牛顿的万有引力定律启发而提出的。在GM中,类CA和类CB可以看作对象A和对象B,未定义文档d可以看作对象S。rA和rB分别代表S到A和B之间的距离。对类CA和类CB具有相同吸引力的分类超平面定义如式(7)所示:
(7)

MA*Sim(d,cA)=MB*Sim(d,cB)
(8)
在测试阶段,未定义文档和Cj类质心之间的力可以通过式(9)描述:
F(d,cj)=Mj*Sim(d,cj)
(9)
其中,Mj为Cj类的质量因子。
然后,分类器将未定义的文档分配给其质心向量与文档最相似的类别。
质量因子M可以在训练阶段通过式(10)和式(11)来学习得到:
Mi:=Mi+ζ
(10)
Mj:=Mj-ζ
(11)
其中,ζ是一个常数,用来控制迭代强度。
算法1随机学习质量(M)法

输出:类的质量因子。
1:forj=1,j≤Pdo
2:Mj←1;
3:endfor
4:Rnew←1;
5:Repeat~Iter++;
6:error←0;
7:Rold←Rnew;
8:forn=1,n≤Ndo

11:Mj←Mj+ζ;
13:error++;
14:endif
15:endfor
16:Rnew←error/N;
17:Untilε>(Rold-Rnew)/RoldorIter>Max
18:returnMj~(1≤j≤P);
3.2 多标签引力模型
本文对GM进行改进提出了基于质心的多标签引力模型(ML-GM),在ML-GM中,Cj类质心和此类中文本之间的相似性可以用引力来表示,可以在此类中得出一个引力区间FjINT=[Fjmin,Fjmax]。Fjmin和Fjmax是Cj类质心与类中文本的最大和最小引力。在测试阶段,计算未标记文档与每个类质心之间的相似性。
未定义文档与每个类质心之间的吸引力可以用F(d,cj)来表示,如式(12)所示:
F(d,cj)=Mj*Sim(d,cj)
(12)
其中,Mj表示Cj类的质量因子,可以由式(10)和式(11)计算得出。Sim(d,cj)是衡量文档d和类质心之间相似性的指标,其代表1/r2。当F(d,cj)∈FjINT时,则未定义文档d被分配到Cj类中,实现多标签文本分类。
图1所示为ML-GM分类流程图。整个分类过程可分为2个步骤:训练阶段和测试阶段。第1步训练本文分类模型,第2步测试文本分类模型。
第1步:训练阶段。
培训文件:从语料库准备的培训文件。
预处理:初始化并过滤语料库中的单词。例如,使用停用词列表处理文档中具有高频但具有含义的词,并在整个文本中处理低频率的罕见词。
特征处理:使用TFIDF方法对文档进行矢量处理。
训练模型:基于算法2创建ML-GM模型,该模型可以对多标签文本进行分类。
第2步:测试阶段。
测试文档:在语料库中准备的测试文档。
预处理:文本的处理方式与训练阶段的预处理步骤相同。
特征处理:使用TFIDF方法对文本进行矢量处理。
相似性估计:在此步骤中,将文档向量与每个类中的引力区间进行比较以进行分类。
算法2总结了ML-GM训练阶段的代码。在该模型训练阶段中,q和p分别表示训练数据集中的类别数和类中的实例数。如算法2所示,基于多标签训练示例,第1~3行使用式(4)计算每个实例的质心。第4~8行通过式(9)计算每个类质心与该类文档中的相似性引力值。最后,将每个类别中的引力值相互比较并返回1个引力区间。
算法2ML-GM的训练阶段
输入:q个类别和p个样本的数据。
输出:引力区间。
1:forj=1,…,q
2: 用式(4)计算质心cj;
3:endfor
4:forj=1,…,q
5:fori=1,…,p
6: 用式(9)计算得出F(d,cj);
7:endfor
8:endfor
9:ReturnFjINT=[Fjmin,Fjmax]
为了更好地解释本文所提出的模型,给出分类模型示例图,如图2所示,并详细地阐述如何进行多标签分类。
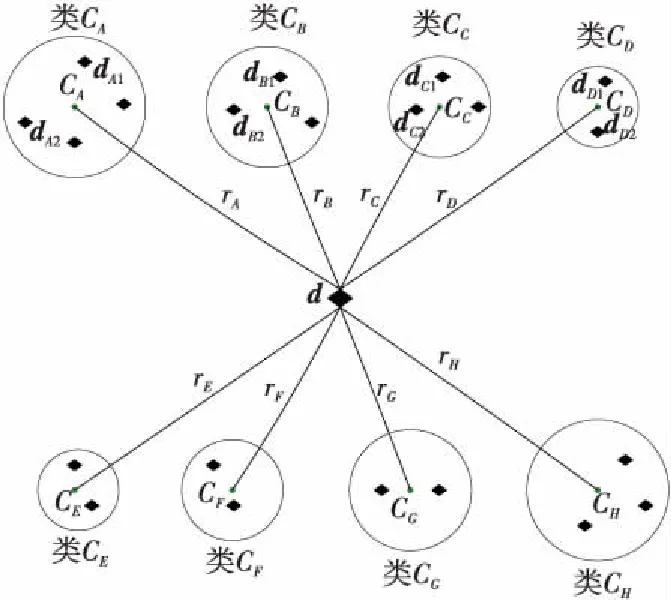
Figure 2 Diagram of classfication图2 分类模型图
示例:在训练阶段,通过式(4)计算每个类别的质心(例如cA,cB,cD,cE)。接下来,计算预处理文本(例如dA1,dA2;dS1,dS2;dD1,dD2;dE1,dE2)和类质心之间的相似性,用引力来表示(例如dA1和cA之间的相似性为引力值FA1)。最后,在每个类中得出1个文本与类质心的相似性引力区间FjINT=[Fimin,Fimax]。其中,Fjmin和Fimax是Cj类中文本向量与类质心之间的最小和最大相似性引力值。在测试阶段,预处理的未定义文档d和质心之间的相似性引力值F(d,cj)将由式(12)计算得出。最后,将此引力值与Cj类中的相似性引力区间进行比较,从而进行文本分类。当F(d,cj)=FjINT时,未定义文档d被分配到Cj类中,实现多标签文本分类。
4 实验
本节进行了一些实验来检验本文提出的多标签分类模型的性能。应用任务主要是网页分类。采用ML-KNN[16]、BR[6]和CLR[14]与ML-GM进行比较。
4.1 评估指标和实验数据
本文使用平均精确度(Average Accuracy)、汉明损失(Hamming Loss)、1-错误率(One-error)和AUC[13]来评估多标签分类模型的性能。平均精确度评估特定标签上方列出的标签的平均分数。汉明损失评估错误分类的实例-标签对的分数。1-错误率评估顶级标签不在相关标签集中的示例的分数。AUC被称为ROC曲线下的区域,并且与每个实例的标签排名性能相关。平均精确度和AUC的值越大,而汉明损失和1-错误率的值越小,性能越好。在这个实验中,使用雅虎的网络数据集来确认本文提出的模型的有效性。
表1所示为数据集的基本信息。数据集由11个顶级类别(例如“Business”和“Science”)组成。根据类别的不同随机选取了不同数量的样本作为训练文本。
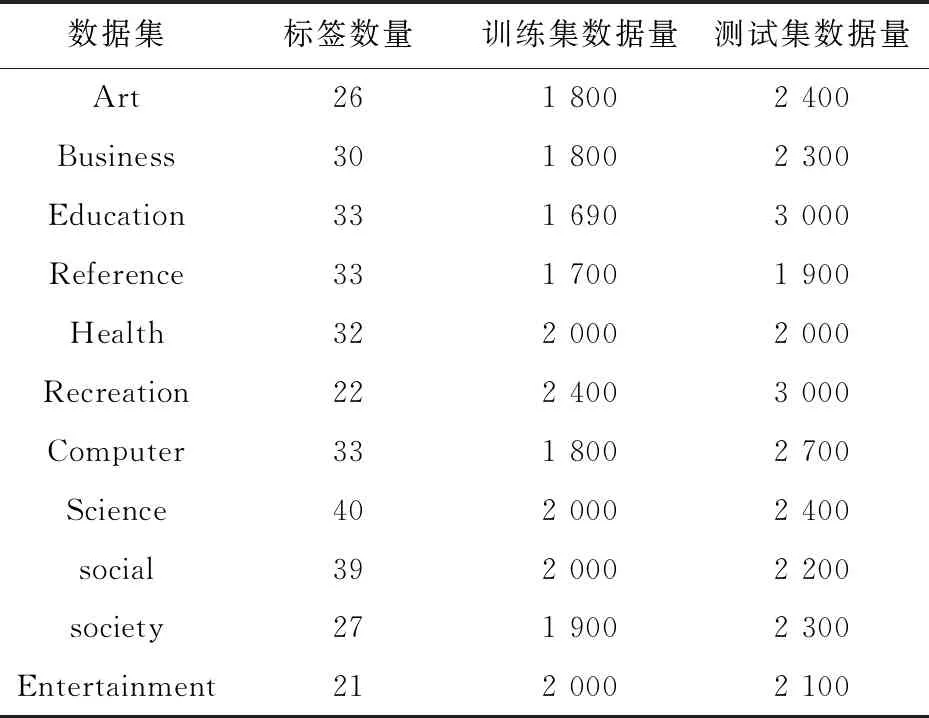
Table 1 Description of datasets表1 数据集基本信息
图3和图4用柱形图的形式展示了表1中的数据信息。从图3中可以看出,这些标签的数量没有差异,标签最少的类别是“Entertainment”。从图4中可以看出,大约40%的实验数据被用作构建分类模型的训练集,60%被用作测试集来测试分类方法的性能。
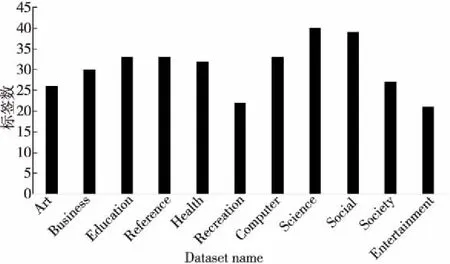
Figure 3 Label numbers of each dataset图3 每个数据集的标签数

Figure 4 Instance numbers of each dataset图4 每个数据集中的实例数
4.2 实验结果和分析
表2~表5分别给出了在Yahoo数据集上的平均精确度、AUC、汉明损失和1-错误率的实验结果,其中最好的结果用黑体标出。

Table 2 Average accuracy comparison of different classifiers表2 平均精确度比较
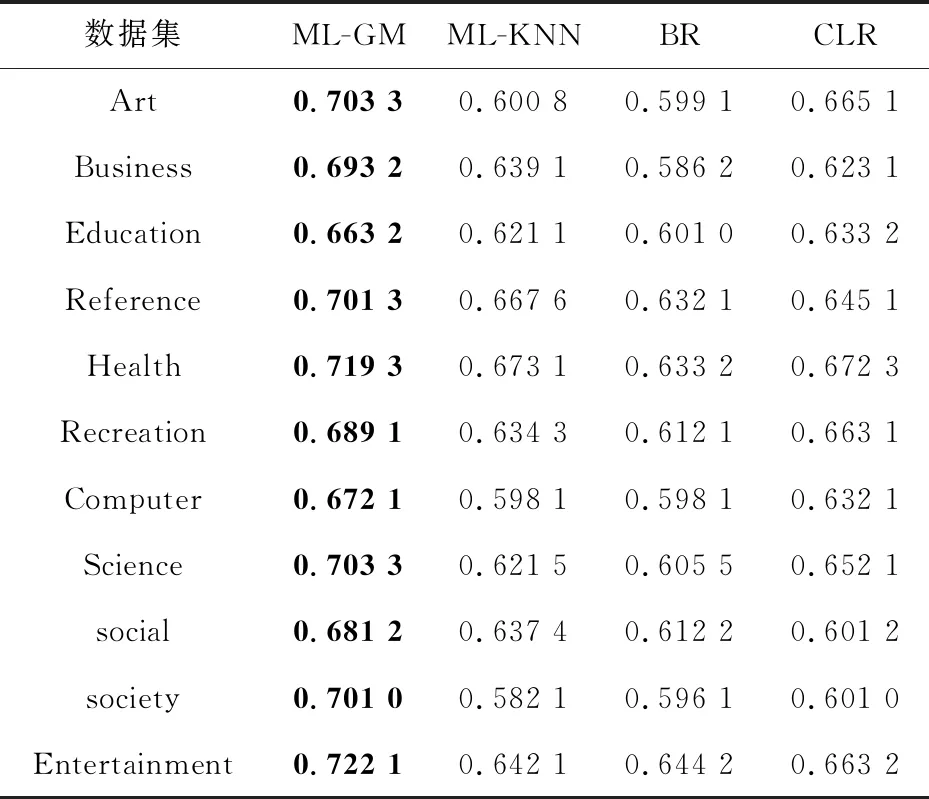
Table 3 AUC comparison of different classifiers 表3 AUC比较
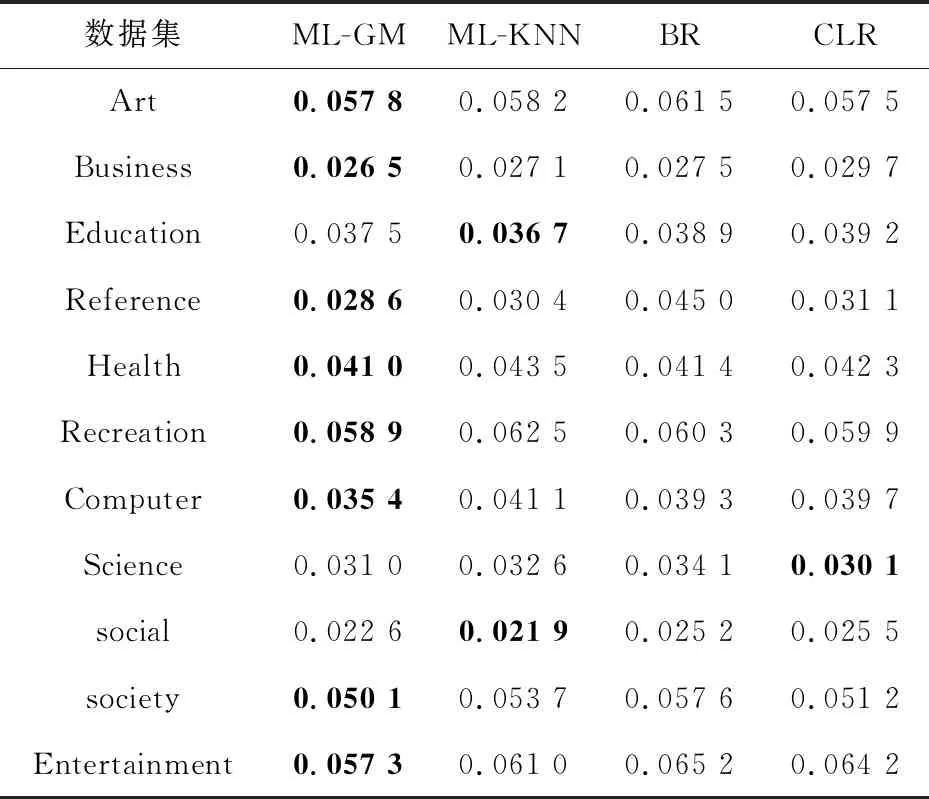
Table 4 Hamming loss comparison of different classifiers 表4 汉明损失比较
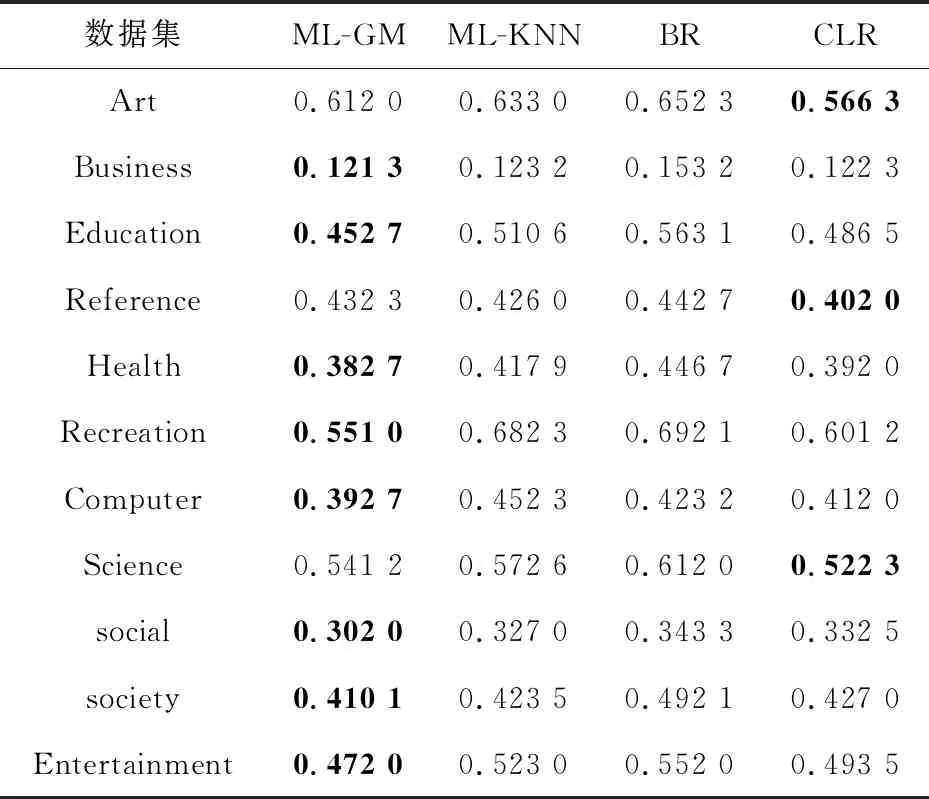
Table 5 One-error comparison of different classifiers 表5 1-错误率比较
与ML-KNN相比较:在所有11个数据集上ML-GM平均精确度、AUC、1-错误率优于ML-KNN的。对于汉明损失,ML-GM在9个数据集上是最好的,在数据集Education和Social上稍微低于ML-KNN的。与BR相比较:ML-GM在所有数据集上的评估数据都优于BR的。与CLR相比较,在9个数据集上,ML-GM平均精确度表现最优,而CLR在数据集Education和Society上表现最优。对于AUC,ML-GM在所有数据集上都表现最优。对于汉明损失,ML-GM在10个数据集上表现最优,而CLR仅在数据集Science上表现最优,但是ML-GM与CLR在此数据集上相差很小,大约为0.000 9。对于1-错误率,ML-GM在8个数据集上表现最优,而在数据集Art,Reference,Science上ML-GM要稍微差于CLR。但总的来说,所提模型的性能大致优于其他多标签分类模型。
另外,我们还比较了计算时间,如图5所示为计算时间随数据样本数量增加的变化情况,初始样本数量固定在n=500。
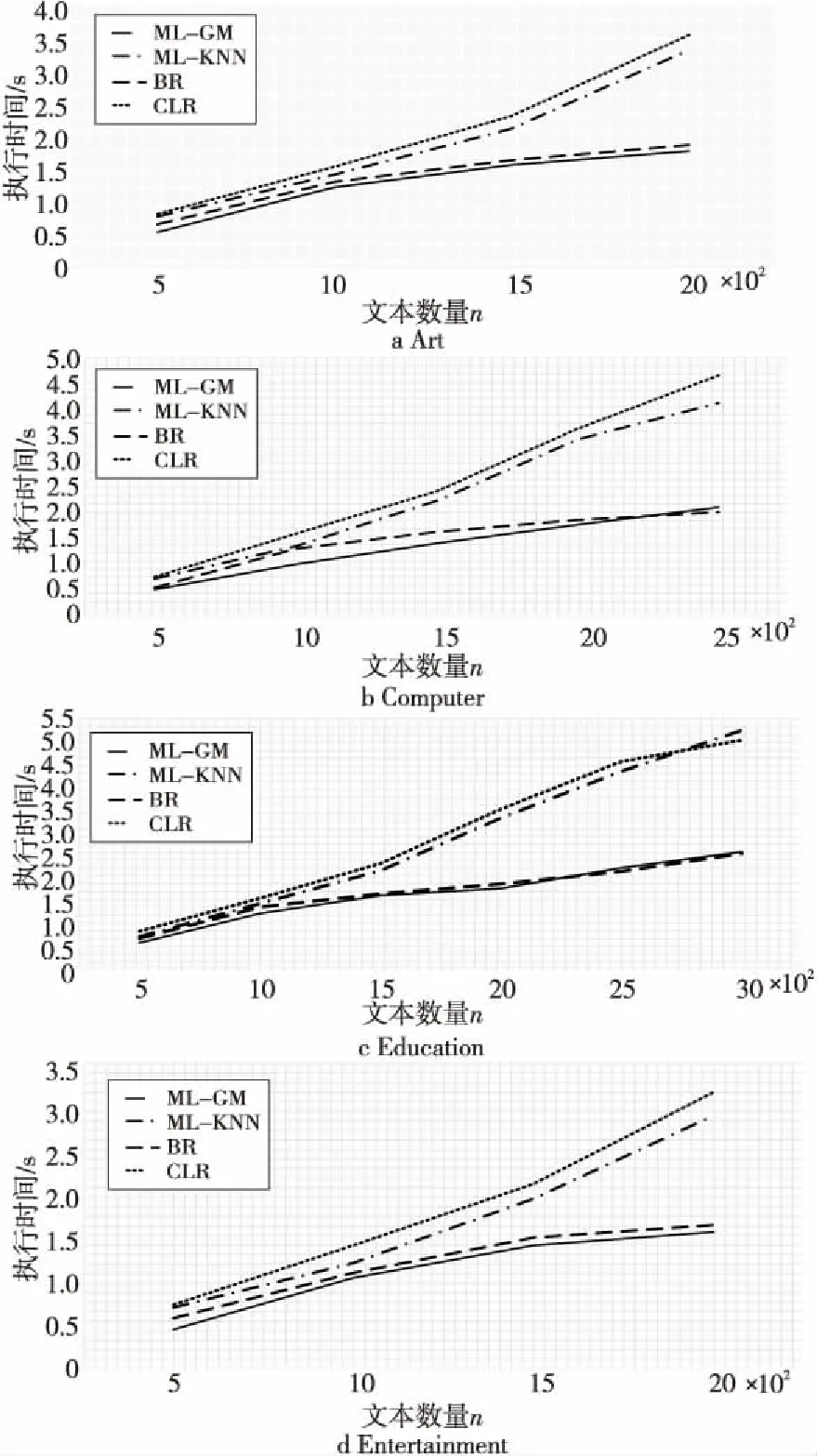
Figure 5 Computation time comparison of each model on different datasets图5 各模型在不同数据集上的计算时间比较
总的来说,ML-GM和BR的计算速度比CLR和BR快得多。从图5a中可以看出,当样本数为500时,所有模型的计算时间非常接近。然而,ML-KNN和CLR的计算时间大于ML-KNN和BR的。BR和ML-GM之间的计算时间差异不是太大,时间增长曲线非常相似。图5c中,当样本数超过2 500时,ML-KNN计算时间迅速增加。研究发现,本文提出的多标签分类模型在计算效率方面优于ML-KNN和CLR的,类似于BR的。
5 结束语
本文提出了一种新的多标签文本分类模型ML-GM。利用质心分类器的线性技术复杂性来提高计算效率,并利用引力模型的均匀分布来解决类不平衡导致的分类精确度低的问题。从实验中可以得出结论,本文提出的模型与其他分类模型比较,可以提高文本分类的准确度,减少分类错误。
但是,在ML-GM分类模型分类过程中,未考虑某一测试文本不属于任何一个类时怎么处理。今后,我们将针对该问题进行研究。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
当代陕西(2020年15期)2021-01-07
河北画报(2020年8期)2020-10-27
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19
浙江大学学报(工学版)(2016年2期)2016-06-05
应用科技(2015年5期)2015-12-09
第二课堂(课外活动版)(2015年4期)2015-10-21
航天器工程(2014年5期)2014-03-11
