
基于HDP的主题词向量构造
——以柬语为例*
2020-06-22 12:29徐广义莫源源
计算机工程与科学 2020年6期
李 超,严 馨,谢 俊,徐广义,周 枫,莫源源
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650504; 3.云南南天电子信息产业股份有限公司,云南 昆明 650400;4.云南民族大学东南亚南亚语言文化学院,云南 昆明 650500; 5.上海师范大学语言研究所,上海 200234)
1 引言
词向量又称为词编码,是一种使用自然语言处理方法从大量的文本中学习、提取词特征信息的一种表示方法,它将文本中的多种上下文关系使用数学中的向量进行表示。自然语言处理中,词是表义的基本单元,词向量是非常基础和重要的,广泛地应用于命名实体识别、句法情感分析等方面。东南亚小语种之一的柬埔寨语,又称高棉语,其发展过程中受到多种语言的影响,其构词方式多样,例如四音歌词[1],特殊的构词,结构紧密,语义有较强的概括性,1个词具有多个义项,有的义项与该词本身意义相差甚远。由于自然语言处理研究大部分集中于英语,且不能有效地应用于柬语等小语种,在面对语料匮乏,人工标注花费巨大等问题时,我们希望资源较少的柬语也能学习出更高效的词向量,作为柬语信息处理乃至柬汉双语信息处理技术的基础资源,为接下来的研究作铺垫,所以我们以柬语为例提出基于层次狄利克雷过程HDP(Hierarchical Dirichlet Process)的主题词向量构建方法。
目前构建的单一词向量,无法更有效地解决一词多义和一义多词等问题。基于神经网络的词向量学习方法的最重要思想是通过给定的上下文对目标词汇出现的概率进行预测。Mikolov等[2]通过一个循环神经网络的模型来实现词向量的训练,其特点是简化了原有模型中复杂参数的训练过程,并且更为全面地利用到语料中的上下文信息。在文献[2]的词向量模型的基础上改进而来的模型word2vec[3],是由Google公司提出的一个能够将语料中的单词转化为词向量的工具,该训练模型中将原有神经网络中最复杂的隐藏层删除掉了,这样能够大大降低模型训练时的计算复杂度。该模型主要是由根据上下文来预测目标词的CBOW(Continuous Bag Of Words)模型和根据目标词对上下文进行预测的Skip-Gram模型组成。上述训练词向量的模型训练出的词向量均是1个单词对应着1个词向量,无法合理地分辨多义词,且无法很好地解决词向量的歧义等问题。Liu等[4]提出了TWE(Topic Word Embeddings)模型,其基本思想是通过LDA(Latent Dirichlet Allocation)主题模型获取单词主题,形成单词-主题对,然后将主题视为伪单词,通过Skip-Gram模型分别学习主题向量和词向量,最后进行级联得到主题词向量。该主题词向量将词的主题信息融入到词向量信息中,解决了单一词向量存在的一词多义和一义多词的问题,但是该模型中使用的LDA主题模型的主题数目需要人工设定。人工主题数目的设定与个人经验息息相关,因而人工经验对于主题模型的训练结果影响较大。而后在此基础上,吴旭康等[5]针对TWE模型中将单词向量和主题向量进行简单连接的方式会存在向量表达性上不够突出的问题,提出了单词主题混合WTM(Word-Topic Mixture)模型。李思宇[6]提出使用BTM(Biterm Topic Mode)主题模型来代替LDA主题模型的方法,解决了LDA主题模型在短文本的主题建模上效果不佳的问题。
上述前期调研表明,目前对词向量构建的研究,已有一些可借鉴的成果。目前存在单一词向量无法对多义词有效分辨;一词对应多个词向量,过于繁复;LDA主题模型人工设定主题数对模型训练结果影响较大等问题。为有效地进一步研究我们面对的柬语等小语种资料匮乏,不同语境下词的歧义,一词多义等特殊情况,本文提出了基于HDP主题模型的主题词向量构造方法,能够较好地解决上述存在的一词多义和一义多词等问题,且主题数目通过训练的语料学习得到,领域适应性也有扩大。该方法在单一词向量基础上融入了主题信息,首先通过HDP主题模型得到单词主题标签;然后将其视为伪单词与单词一起输入Skip-Gram模型,同时训练出主题向量和词向量;最后将文本主题信息的主题向量与单词训练后得到的词向量进行级联,获得文本中每个词的主题词向量。
2 HDP主题模型
2.1 HDP主题模型的原理
通常认为文档中的单词是由许多潜在的“主题”产生的,其中1个主题通常被建模为一些基本词汇中单词的多项式概率分布。我们希望扩展模型,在多个文档中共享潜在的主题,Teh等[7]定义了层次狄利克雷过程HDP,HDP本身是一组随机概率测度的分布。为了确保文档之间可以共享主题,HDP文档之间共享从连续基分布H得出的离散分布G0,G0是一个离散的随机度量,是每个文档主题分布的先验。
HDP主题模型的基础是狄利克雷过程,其原理如图1所示,在该原理图中,圆形代表分布,小矩形框代表参数,阴影部分代表观测到的变量,大矩形框代表其中过程可重复,进行实验的语料集是1个含有M篇文档的文档集,假定在其中的每篇文档的主题信息是相互共享的,那么此时各个文档的主题都是以基分布H为基础的。更正式地说,HDP为每个文档d定义了一组随机概率度量Gj,以及一个全局随机概率度量G0。G0是从基本分布H构造的狄利克雷过程中得出的。在这种结构中,全局度量G0从基本分布H中选择所有可能的主题,然后每个Gj从G0得出文档d所需的主题。因此,HDP主题模型的过程为:
(1)从H和聚集度参数γ构成的狄利克雷过程抽样产生一个G0,即整个文档集的基分布满足狄利克雷过程,具体表示如式(1)所示:
G0~DP(γ,H)
(1)
(2)以G0作为基分布和聚集度参数α0对每一篇文档构造狄利克雷过程,此时每篇文档都满足一个狄利克雷过程,具体表示如式(2)所示:
Gj|G0~DP(α0,G0)
(2)
(3)最后依据Gj这一层次狄利克雷过程作为先验分布,构造狄利克雷过程混合模型,具体表示如式(3)和式(4)所示:
θji|Gj~Gj
(3)
xji|θji~F(θji)
(4)
其中,F(θji)表示在给定参数θji的前提下,观测变量xji的分布,这里采取多项式分布,与基分布H构成共轭分布。参数θji条件独立服从分布Gj,观测的变量xji条件独立服从分布Fji(θji)。
此模型本质上是实现了LDA的非参数版本,该LDA在语料库的所有文档中共享无限数量的主题。

Figure 1 Schematic diagram of HDP model图1 HDP主题模型的原理图
2.2 HDP主题模型的构造过程

θji|θj1,θj2,…,θj,i-1,α0,
(5)
Ψjt|Ψ11,Ψ12,…,Ψ21,…,Ψj,t-1,γ,
(6)
从上述构造过程可以看出,CRF的过程就是按照一定的概率规则为顾客分配菜和餐桌,首先为每个顾客分配餐桌,已有餐桌被选中的概率与其就座的顾客数成正比,而新餐桌也允许以一定的概率被选中,在完成餐桌指派后,为每张餐桌分配菜肴,已有菜肴被选中的概率与其供应的餐桌数成正比,而新菜肴也允许以一定的概率被选中。对应到文档的聚类问题上,即为文档中单词对应主题的过程,一旦完成CRF构造,即可采用模型参数后验分布推断方法求解HDP主题模型,进而获取整个文档集的主题分布。

Figure 2 CRF construction process图2 CRF构造过程
2.3 基于吉布斯采样的参数估计
CRF的构造分为3个步骤,首先将每个文档中的单词划分到每一张餐桌,然后为每张餐桌划分配菜(也就是主题),最后从此种层次化的划分中为单词分配潜在主题。通过上述基于CRF构造的Gibbs采样算法迭代地为每个单词分配潜在的主题标签,我们将对文档j中每个单词标记的tji进行采样,然后对文档j中每个kjt进行采样。
(1)对t进行采样。
首先根据式(6)可得xjt的条件概率为:
p(xji|t-ji,tji=tnew,k)=
(7)

则可得到tji的条件概率为:
(8)
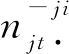
如果采样的tji是tnew,此时通过式(8)可以得到kjtnew的采样概率:
(9)
(2)对k进行采样。
在完成所有的餐桌分配之后,便可以对餐桌进行菜品的分配。kjt采样类似于tji,因此kjt的后验概率正比于选择菜品k的桌子数目与xjt的条件概率之积:
(10)
其中,k表示已有顾客点的菜。
3 主题词向量模型
3.1 Skip-Gram模型
基于层次Softmax的Skip-Gram模型根据输入的单词对上下文进行预测,每个单词对应唯一1个向量,输入单词词向量用作预测上下文的特征。该模型的最终优化目标是:
(11)
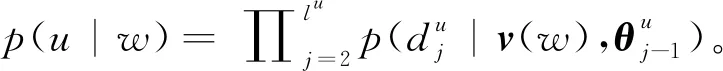
(12)
(13)

如引言部分所述,本文希望结合词向量模型Skip-Gram和主题模型HDP增强向量的表示能力。
3.2 改进主题词向量模型
在Skip-Gram的词向量模型中,每个词都是用唯一的向量进行表示。为了能够将文本中不同语境下拥有不同含义的单词在进行向量表达时区分开来,并且克服LDA主题模型需要人工设定主题的缺点,本文采用了HDP主题模型来对向量的语义信息进行补充,也就是说通过结合主题模型HDP和词向量模型Skip-Gram来增强向量的表示能力,于是本文提出了基于HDP主题模型和Skip-Gram模型的改进主题词向量模型。
主题词向量的构造依赖于每个单词的主题信息。首先通过HDP模型获取单词主题并将其视为伪单词;然后分别将单词和主题作为Skip-Gram模型的初始输入分别学习词嵌入与主题嵌入;最后将训练得到的单词的词向量和主题向量进行级联,得到单词的主题词向量,并通过词相似度任务和文本分类任务对得到的主题词向量进行实验,以评估得到的主题词向量性能的好坏。主题词向量模型如图3所示,该主题词向量模型的目标函数是最大化式(14)所示的对数函数:
logP(wi+j|zi)
(14)
其中,wi表示目标单词,zi表示目标单词的主题(被视为伪单词),为每一个词分配一个潜在主题zi∈TS。因为我们使用的是基于层次Softmax的Skip-Gram模型,通过随机行走的方式为每一个单词赋予一个概率。使用随机梯度算法时,通过归一化向量以保证最终目标函数能够较快收敛。

Figure 3 Improved topic word embeddings model图3 改进的主题词向量模型
从图3可知,本文中的主题词向量模型与Skip-Gram模型相类似,包含有3层结构,训练完成后输出w和z,分别是单词所对应的词向量和主题向量。输出层则可根据级联之后的主题词向量对其目标单词上下文进行预测。
改进的主题词向量模型的基本思想是将HDP主题模型训练出来的每个主题看做是一个伪单词,出现在分配给该主题的单词的所有位置,那么训练出来的主题向量便代表了该主题下所有单词的集合语义。
在该主题词向量模型中,通过级联w和z(即wz=w⊕z)来获得词的主题词向量。其中,⊕是级联操作符号,为了简化整个模型的计算过程,在本文中设置的主题向量的维度和词向量的维度相同。因此,级联之后的主题词向量wz的向量维度是w或者z的2倍。
但是,由于训练得到的主题向量和词向量数值相差较大,其中主题向量较大,词向量较小,因而需要对主题向量和词向量分别进行归一化,如式(15)和式(16)所示。
(15)
(16)
其中,A∈Rm×n和B∈Rm×n为主题向量和词向量矩阵(为了简便计算,模型要求单词向量和主题向量拥有相同的维度),其中m是词表中单词个数,n是词向量维数;i=1,2,3,…,m;j=1,2,3,…,n;A′∈Rm×n和B′∈Rm×n为归一化后的主题向量和词向量矩阵。然后将归一化后的单词词向量和主题向量进行级联获得主题词向量。
上述获得的主题词向量可以应用于上下文单词相似度的计算。这里的相似度计算并不是直接对得到的主题词向量进行相似度计算,而是需要基于单词的上下文,即通过当前单词的主题词向量来获得其上下文单词的主题词向量。具体来说,对于文本中的每个单词w和其上下文c,首先根据HDP主题模型可以推断出若将上下文c看成1个文档,则可以得到P(z|w,c),即此时P(z|w,c)∝P(w|z)P(z|c)。在此之后便可以进一步得到词w的上下文词c向量,即:
wc=∑z∈TSP(z|w,c)oz
(17)
其中,oz为主题词向量,通过连接归一化后的词向量和主题向量获得。通过式(17)可知,本文将模型中得到的所有的主题的概率作为权重,进行加权求和,得到最终的上下文词向量。
Figure 4 Reptile crawling Khmer corpus图4 爬取的柬埔寨语料
由式(17)得到上下文词向量的目的是用于衡量两个词之间的相似性,于是,给定2组具有上下文的单词(wi,ci)和(wj,cj),其上下文单词相似度的计算采用AVGSimC公式,如式(18)所示:
∑z∈TS∑z′∈TS′P(z|wi,ci)P(z′|wj,cj)S(oz,oz′)
(18)

(19)
4 实验结果与分析
本节将主题词向量分别从上下文单词相似度、文本分类2个任务进行实验,对比评估多种相关模型的性能。
4.1 数据集
本文实验所需要的语料包括2类:第1类是能够提供训练主题词向量的训练语料;第2类是为检测文中改进的主题词向量模型的性能而进行相关测试的测试语料。本文中的实验训练数据全部来自于柬埔寨语的各大官方网站[9],如图4所示,首先将爬取的柬埔寨篇章语料通过预处理切分为小文档;然后对柬埔寨语进行分词,采用实验室已搭建好的分词工具得到的语料规模为5 000篇文档,1 108 423个单词。针对2种不同的实验任务采用了不同的测试集。
4.2 实验设置
在本文提出的主题词向量模型中,由于使用的是自适应主题数目的HDP主题模型,所以该模型中需要设定的参数只有主题向量和词向量的维度,为了简化计算,本文中设置主题向量和词向量的维度均为100。本文使用Skip-Gram模型,并将模型窗口的大小设置为5。使用HDP主题模型训练词的主题标签时需要设置该模型的超参数α,γ,以及迭代次数,本文中这些参数分别设置为α=1,γ=0.1,迭代次数为100。整个实验环境为Intel i7的处理器,64 GB内存。
4.3 单词相似度和文本分类实验
(1)单词相似度实验。
这里的单词相似度需要考虑单词的上下文,但是传统的诸如WordSim353等的测试集是孤立的单个单词,并不适于本文实验,于是,本文采用的是具有上下文的单词数据集SCWS(具体语料如图5所示),此数据集包括2 003对单词和包含这些单词的句子,应用于本文的柬埔寨语时需要将其翻译为柬埔寨语。然后再由10个柬埔寨语学习者对测试集中每2个单词的相似度进行打分,打分的原则是个人根据理解给每一对单词打出1个0~10的分数。本文取10个打分值的平均数作为参考分数值。而且考虑到模型计算得到的相似度与人为打分值差异较大,本文采用斯皮尔曼相关系数评价最终模型打分与人为打分的接近程度。具体的计算公式如式(20)所示:
(20)
其中,r表示等级个数,即测试集中包含的词语对的数量;g表示2组单词之间的等级差数;gi表示第i组单词的等级差。

Figure 5 SCWS data set图5 数据集SCWS
在该实验任务中进行的对比实验是将本文所得到的主题词向量模型和Skip-Gram模型、LDA主题模型、HDP主题模型、LDA-Skip-Gram的主题词向量模型在上下文单词相似度任务上进行结果对比。
(2)文本分类实验。
文本分类实验采用的数据集是基于柬埔寨语官方网站爬取的,其中80%的语料作为实验训练集,20%的语料用于实验测试集。然后对这些语料进行整理并进行预处理。文本的预处理是对原始语料进行分词和去停用词,使用的分词工具是Khmer Unicode Line Breake。为了能够提取文档的特征,本文引入文档向量:
(21)

在该实验任务中,将本文得到的主题词向量模型和LDA主题模型、Skip-Gram模型、HDP主题模型以及LDA-Skip-Gram主题词向量模型进行对比。其中,LDA主题模型和HDP主题模型均是使用其模型中的主题分布来代表文档;Skip-Gram模型则是将文本中所有单词的词向量按数目求平均来代表文档的向量;LDA-Skip-Gram主题词向量模型则是使用类似于本文提出的主题词向量模型中的方法进行文本分类。
为了能够直接评价各种模型针对文本分类任务的效果,文本使用精确度P、召回率R和F值评价方法对文本分类实验结果进行估计。
(22)
(23)
(24)
4.4 实验结果及分析
本文的单词相似度实验是在柬埔寨语版本下的单词具有上下文关系的SCWS测试集上进行的。
实验结果如表1所示,最终通过斯皮尔曼相关系数来对模型的相关性能进行判定,即在本文实验中斯皮尔曼相关系数ρ越大,代表该模型对单词相似度计算的结果越好。
在本文实验中,将本文提出的基于HDP主题模型和Skip-Gram词向量模型构成的主题词向量模型分别与其它主题模型和词向量模型在单词相似度上进行对比,从实验结果可以看出,在相似度检测实验中,主题词向量模型的结果优于其他模型的。

Table 1 Spielman coefficient of word similarity on SCWS data set表1 SCWS数据集上单词相似度斯皮尔曼相关系数
将本文提出的主题词向量模型分别与LDA主题模型、HDP主题模型、Skip-Gram词向量模型以及基于LDA主题模型和Skip-Gram词向量模型的主题词向量模型从精确度P、召回率R、F值指标方面进行了对比。结果如表2所示。

Table 2 Experimental results of text classification表2 文本分类实验结果
通过上述实验结果可知,在柬埔寨语测试语料的环境下,本文所提出的基于HDP主题模型和Skip-Gram词向量模型在本文分类任务中精确度达到了74.5%,相较于传统的单一词向量模型Skip-Gram模型在分类精确度上有了一定的提高,同时相较于同类型的基于LDA主题模型和Skip-Gram词向量模型的主题词向量模型也有了一定的提高。由此可以说明,本文所提出的主题词向量模型在针对柬埔寨语的文本分类任务中有着十分重要的作用。相比传统模型和其他模型,本文模型的优势在于,HDP主题词向量方法相对简洁,且对不同上下文语境语义相似情况也有所优化;对于LDA-Skip-Gram模型,本文模型可以避免LDA主题数目需要人工设定的问题,能够得到基于上下文的词向量,生成的词向量具有特定的主题,简化了计算,提升了整体的运行速度。
5 结束语
本文提出一种基于HDP的柬语主题词向量构造方法,在单一词向量基础上融入了主题信息,首先通过HDP模型得到单词主题标签;然后将其视为伪单词与单词一起输入Skip-Gram模型,同时训练出主题向量和词向量;最后将文本主题信息的主题向量与单词训练后得到的词向量进行级联,获得文本中每个词的主题词向量。实验结果表明,本文提出的主题词向量模型在单词相似度以及文本分类方面都有明显的优势。将主题整合到了基本的词向量表示中,并允许得到的主题词向量能够在不同的语境下对单词的不同含义进行建模。与单一的词向量模型相比,这种方法不仅学习到了文本层面中单词的主题信息,而且学习到了词层面的信息;能够较好地解决单一词向量存在的一词多义和一义多词等问题,且主题数目不需要手工设定。下一步我们将改进级联方法,获得更为完善的主题词向量模型的构建方法。
猜你喜欢
客联(2022年3期)2022-05-31
通信技术(2021年12期)2022-01-25
中国新闻周刊(2021年26期)2021-07-27
中国医学计算机成像杂志(2020年6期)2020-03-14
信息安全研究(2016年4期)2016-12-01
中国骨与关节杂志(2016年12期)2016-01-23
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
民族古籍研究(2014年0期)2014-10-27
