
卷积神经网络SSD的道路目标检测
2020-06-20 03:35:58赵建国曹朝辉
机械设计与制造 2020年6期
赵建国,曹朝辉,梁 杰
(郑州大学机械工程学院,河南 郑州 450000)
1 引言
道路目标检测是一种在场景图像中找出道路目标的研究问题。随着辅助驾驶和无人驾驶的发展,道路目标的检测表现出很大的发展潜力,在驾驶中,车辆对周围目标物体感知能力,能够提高驾驶的安全性,它是现在道路交通研究的重要问题。
早期的目标检测的研究在于研究人员手工提取目标特征[1]进行组合,这种做法比较依赖研究人员的经验,模型缺乏泛化能力。近些年,随着深度学习的发展,基于卷积神经网络的深度学习在图像识别和检测等都取得了显著成就[2]。与传统的算法相比,避免了对图像目标的手工提取特征,能够提高模型的泛化能力。所以越来越多的研究员通过深度学习来解决道路目标检测问题。
从2012年某些科研人员ImageNet挑战赛的表现点燃了深度学习的热潮。随后就被应用到了目标检测上。文献[3]的提出,取得了很好的效果,但是空间和时间的耗费都很大。文献[4]进一步将提出Fast R-CNN,降低空间和时间的开销,之后Ross Girshick又集成 RegionProposalNetwork(RPN)网络提出了文献[5],文献[6]实现端对端,多任务学习,检测速度快,但是对小物体检测的精度一般,随后的SSD[7]的出现结合了Faster R-CNN固定框的思想和YOLO网格离散化的思想,增加了在多尺寸特征图上映射特征的能力,增强了对小目标的检测能力。
2 SSD模型的道路目标检测
主要解决车辆在行驶过程中通过行车记录仪记录的视频进行检测,主要检测的目标分为车辆、行人和骑行的人。采用深度学习来解决道路目标检测的问题,利用SSD网络建立模型,通过训练集对模型进行训练得到目标模型,然后利用目标模型对测试集进行预测,如图1所示。

图1 模型学习检测流程Fig.1 Model Learning Detection Process
2.1 SSD架构
模型检测方法是基于前馈卷积网络,分为两个部分:基础网络和多尺寸特征图检测,如图2所示。首先为了增加数据多样性,对原图像进行数据扩增,扩增方式[3]有原始图像、随机采样一个图像片段和采样特定的图像片段,然后调整图像的尺寸为(300×300),最后以0.5的概率对图像进行水平翻转。基础网络部分主要是对数据扩增后的尺寸为(300×300)的图像特征提取,在其后添加不同尺寸的特征图,对不同尺寸的特征图进行检测,得到对应的不同大小目标的检测效果。
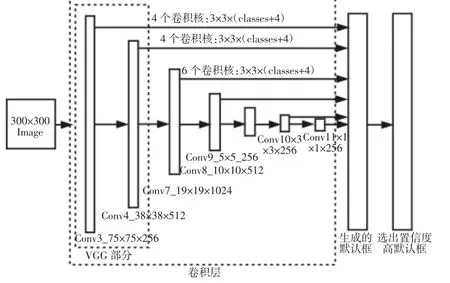
图2 SSD架构Fig.2 SSD Structure
2.1.1 基础网络
基础网络承载着对图像的特征提取的功能,基础网络对特征的提取能力影响着多尺寸特征图检测的优劣,常用的基础网络有VGG[8],GoogleNet[9]以及ResNet[10]等,也可以采用多网络融合的方法进行特征提取,采用VGG网络结构做特征提取,在其后添加不同尺寸的特征图,这些特征图的尺寸逐渐减小,以达到能检测不同尺寸的效果。
2.1.2 多尺寸特征图检测
通过基础网络提取图像目标特征,在基础网络之后添加多张特征图,这些特征图的尺寸不同,对这些特征图做一个卷积滤波器得到目标的坐标值和目标的类别,如图2所示。例如:某一具有p个通道尺寸大小为m×n的特征图,可以使用3×3×p的卷积核进行卷积操作,得到一个默认框对各个目标类别的置信度和此默认框的坐标偏移值。运用多个卷积核对m×n特征图进行多次卷积得到此特征图在不同默认框的各个类别的置信度和坐标偏移值。在这里默认框表示目标在原图所代表的区域大小。在这里由于数据特点是小目标比较多,增加了对VGG网络中的conv3层的特征图的提取,来增强小目标的检测能力。最后再运用非最大化抑制对默认框进行筛选得到最终的检测结果。
2.2 模型的训练
模型的训练包括模型的训练步骤和训练过程中所默认框的生成和匹配。
2.2.1 模型训练步骤
模型的训练分为2个阶段:预训练阶段和训练集训练阶段。预训练阶段首先用ImageNet数据集对VGG的卷积层进行预训练,固定SSD模型中属于VGG的卷积层,利用VOC2007数据集对剩余网络进行训练,最后对整个模型网络进行微调。在训练集训练阶段,首先利用预训练阶段所得到的参数进行初始化网络,然后固定网络卷积层,对检测分类的参数进行训练,然后在对整个网络进行微调,最后得到目标模型,模型训练过程,如图3所示。之后可以用训练好的目标模型对测试集进行测试,得到测试集的检测效果。

图3 SSD模型训练过程Fig.3 Training Process of SSD Model
2.2.2 默认框的生成
默认框是依靠特征图生成的,在卷积网络部分通过网络深度来减少特征图的尺寸大小,获取不同尺寸的特征图用来做不同尺寸下的目标检测,假设使用m张特征图做预测。每张特征图的默认框的比例计算如下:
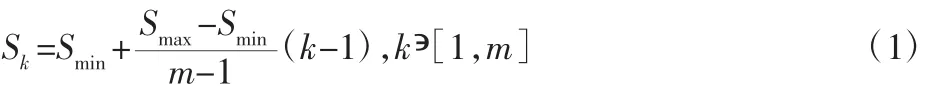
为了提高小目标的检测效果,令Smin=0.10,Smax=0.90,按照m的不同依次求出不同特征图比例。然后对默认框施加不同的宽高比,来增加默认边框的数量,表示为a增加的默认框宽度和高度计算方式,宽度为
2.2.3 默认框的匹配
此次实验的把目标划分为3类,再加上一个背景,所有预测置信度为4类。在训练时,首先我们把默认框和真实框进行匹配,计算IOU值,公式如下:

式中:S—框的面积。
把IOU大于0.5的默认框定为正样本,IOU小于0.5的作为负样本。一个真实框可以对应多个正样本,以达到增加数据多样性的效果。每一个默认框采用Softmax方法求与目标类别(这里为3个种类加上背景类为4类)的置信度。
2.2.4 目标函数
目标函数的计算分为两部分,第一部分是默认框的预测值与目标类别的置信度的损失函数,第二部分是默认框微调后的预测框与真实框的位置损失。为了提高Softmax分类效果,我们可以采用交叉熵代价函数为置信度的损失函数,定义如下:
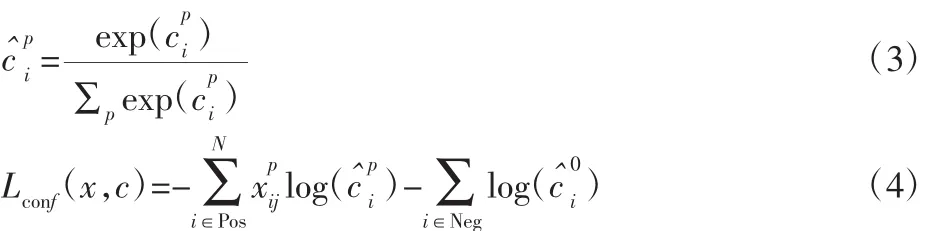
第二部分位置损失,为了使目标预测位置更加准确,使用默认框d微调后预测框l与真实框g之间的损失函数Smooth L1,公式如下:

式中:l—预测框;g—真实框;(cx,cy)—默认框的中心;w—默认
框的宽;h—默认框的高。
总体的目标函数为位置损失函数和置信度损失函数的加权和:

式中:α=0.5;N—默认框的个数。
3 实验
3.1 评价标准
实验结果的目标检测评价标准采用精确率P(precision)与召回率 R(recall),定义如下:

根据模型对测试集的预测结果做出P-R曲线,求出各个目标的平均准确率AP,即P-R曲线下的面积,然后求出mAP表示不同种类的平均准确率均值。
3.2 实验平台与数据
采用的是Tensorflow框架,采用Tesla K80的GPU加速计算,采集的数据集的统计信息,如表1所示。
3.3 实验结果及分析
通过实验,对测试集进行检测典型的检测结果,如图4所示。

表1 训练集和测试集的统计信息Tab.1 Statistical Information of Training Set and Test Set

图4 典型测试集检测结果Fig.4 Typical Test Set Test Results

图5 车辆的P-R图Fig.5 The P-R Diagram of Vehicles

图6 行人的P-R图Fig.6 From Left to Tight,the P-R Diagram of Pedestrians

图7 骑行的人的P-R图Fig.7 The P-R Diagram of Riding Persons

表2 SSD模型AP分析图Tab.2 SSD Model AP Analysis Diagram
对于目标完整,背景干扰少的目标识别率在0.9以上,而下雨天、光线弱、目标和背景相近的和目标比较小的识别率相对较低,如图4所示。模型检测conv3特征层和原图像的尺寸增加一倍的检测效果的P-R分析详见图,如图5、图6和图7所示。检测效果的AP分析表,如表2所示。由结果分析得知,车辆检测的效果较好,骑行的人检测效果一般,行人检测较差,分析发现,由于图像来自于行车记录仪录制视频图像,在公路上骑行的人和行人都是靠路边行走,距离记录仪的距离较远,而行人相对于骑行的人距离车辆更远,所以行人和骑行的人在图像上呈现的目标很小,目标越小越容易受到背景的干扰,目标的特征丢失越多,另外行车记录仪的目标设备,设备质量较差,大多数是关注于车辆周围的环境和目标,对远距离的物体拍摄质量比较差,在夜景中的拍摄效果更差,加大了识别的难度。增加原图像的尺寸,使尺寸增加一倍,目标检测的mAP值增加了0.033,SSD模型增加conv3的特征图的检测,目标检测的mAP值增加了0.049,增幅较大,说明在数据集中存在的小目标较多,虽然增加了针对于小目标的特征图检测,但是效果仍然不理想,分析模型得知,越靠近原图的特征图所经过的卷积层会越少,对图像特征的提取能力越弱,所以骑行的人和行人的检测效果比较差。
4 总结
利用了深度学习来解决道路目标的检测问题,采用了SSD模型算法,利用模型的基础网络提取图像特征,给网络添加不同尺寸的特征图做卷积滤波,得到图像中目标位置坐标和目标类别。避免了手工提取图像特征,提高了道路目标检测的泛化能力。通过实验得出,与原网络相比,这里的方案使模型目标检测的mAP值增加了0.082,模型对车辆检测效果较好,对行人和骑行的人检测效果一般。由于SSD模型的特点,检测速度快,但是对小目标的检测能力不强,虽然对小目标的检测效果有所提升,但是效果仍然不尽人意。在保证检测速度的前提下,提高对目标的检测能力仍然是下一步工作的重点。
猜你喜欢
智族GQ(2022年12期)2022-12-20 07:01:18
China’s foreign Trade(2021年6期)2021-12-26 06:22:58
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
汽车与新动力(2017年3期)2017-06-29 12:00:21
中华奇石(2015年5期)2015-07-09 18:31:07
