
基于注意力机制和RECWE模型的中文词向量方法
2020-06-20 05:32:00高统超张云华
网络空间安全 2020年2期
高统超,张云华
(浙江理工大学信息学院,浙江杭州 310018)
1 引言
信息安全与自然语言处理密切相关,近些年来,自然语言处理在信息安全上得到广泛应用。文本表示是自然语言处理中的一项基本任务[1],以字符为基本元素,将元素的类型转化成数学概念上可用于计算的数值形式,经常用于脚本攻击检测。随着深度学习的发展,词向量模型逐渐代替了传统的文本表示。目前,针对中文词向量模型研究方向主要有基于语义、基于形态和基于辅助知识三种。
但是,基于语义的方法存在噪音问题,上下文词语和汉字,在不同语境中表现的语义不同,一词多义的问题,需要使用特殊方式进行处理。基于形态的方法利用象形字的特点,提取特征信息,但是也会引入一定的噪音。基于辅助知识的方法处理流程比较复杂,对辅助知识的依赖性较强。针对以上存在的问题,Chen等人[2]在CWE(Character-enhanced Word Embedding)模型的基础上提出RECWE模型。模型分为词组预测模型和子信息预测模型。除了考虑单词组成蕴含丰富的语义信息之外,还考虑汉字自身结构的形态特点。此外,还考虑到汉字演变过程中产生巨大的变化,对偏旁部首进行额外的映射处理,模型在实验中取得了较好的效果。
因此,本文在R E C W E模型的基础上进行研究。在词组预测模型和子信息预测模中,通过累加求平均数的方式分别计算词组预测层和子信息预测层向量,但是无法体现两个模型各自组成部分不同的贡献度。为此,本文基于注意力机制,采用SAN(Self-Attention)模型和基本注意力机制[3]分别对两个预测模型进行改进,实验结果表明改进后的RECWE模型具有较好的效果,在信息安全上具有重要的研究价值。
2 相关工作
2.1 基于语言模型的词向量
词向量的概念最早来自分布式表示(Distributed Representation)[4]。语言模型生成词向量是通过训练神经网络语言模型[5](Neural Network Language Model,NNLM)。基本思想是对出现在上下文环境里的词进行预测,本质上是一种对共现统计特征的学习。2013年Google团队推出开源的Word2vec工具[5,6]。Word2vec工具是一款将词表征为实数值向量,简单高效,主要包含两个模型:跳字模型(Continuous Skip-gram Model,Skip-gram)和连续词袋模型(Continuous Bag-of-Words Model,CBOW)。Word2vec工具生成的词向量可以较好地表达不同词语之间的相似程度和类比关系。
本文以CBOW模型和Skip-gram模型为例,介绍采用语言模型生成词向量。模型结构图如图1所示。

图1 CBOW和Skip-gram模型结构图
在CBOW模型中,通过上下文词语对目标词的预测,得到词向量。模型包含三层结构,假设目标词为 ,上下文词向量用表示,为上下文词窗口大小,则每一层操作为:
(3)输入层,将输出层内容构造为一颗Huffman树,叶子节点为数据集中出现过的词,以该词在数据集中的频数为权值。
模型提供了两种近似训练法:负采样(Neg at i ve sa m pl i ng)和层次Softmax(Hierarchical Softmax),可计算出目标词出现的概率。Skip-gram模型思想与CBOW模型相反,通过从目标词对上下文词的预测中学习到词向量表达,用一个词来预测它在文本序列周围的词,其计算过程与CBOW模型类似。
2.2 中文词向量模型
目前,中文词向量模型主要在C B O W和Skip-gram两个模型思想的基础上进行广泛研究。中英文语言结构本身存在较大的差异,许多学者基于汉字结构及字词组合等不同特点进行研究,主要分为三种研究方向。
第一,基于语义的方法。该方法是显式地对中文字符层级语义多样性进行建模,可以有效地处理一字多义的问题,更能通过字词语义相似性的先验,非平均地对待构成词的不同字符。Chen等人[7]根据中文汉字的特点,利用汉字自身也能够表达较好的语义信息,提出了CWE模型。为了消除汉字歧义性问题,利用汉字在单词中位置并结合k-means算法思想提出了三种方案。
第二,基于形态的方法。该方法深入挖掘汉字的形态构成特征,将中文词语拆分成字符、偏旁部首、子字符、笔画等细分的特征,与原词语一并进入词嵌入模型,为模型提供更多的语义信息。Yin等人[8]认为中西方语言存在差异,汉字内部丰富的语义信息更能表达词语的意义,在此基础上提出MGE (Multi-Granularity Embedding)模型。模型充分利用词语和汉字的基础部件,增强词的向量表示,并在相似度和类比任务上验证了模型的有效性。Cao等人[9]在Skip-gram模型基础上,利用汉字一笔一画的结构信息和联系进行研究,提出了cw2vec模型,保证不损失词向量语义信息。
第三,基于辅助知识的方法。该方法是利用汉字的外部特征与字词建立联系为模型提供语义辅助。Xu等人[10]认为CWE模型中单词与汉字贡献度不同,把中文翻译成英文,使用方法计算单词与字之间的相似度以表示贡献的不同程度。Wu等人[11]根据象形文字的历史演变进程,提出基于字形的Glyce模型。利用不同历史时期的汉字字形(如甲骨文、金文、篆书、隶书等)和汉字书法(如行书、草书等)增加字符图像的象形信息,更广泛的捕捉汉字的语义特征。而且添加图像分类的损失函数,利用多任务学习方法增强模型的泛化能力。
2.3 注意力机制
注意力机制(Attention Mechanism)[12]的主要目标是将当前任务目标相关的关键信息从各种信息中挑选出来,本质上来看注意力机制和人类的选择性视觉注意力机制相似。注意力机制早先用于NLP领域中的机器翻译,如图2所示,在Encoder-Decoder模型[13]中运用注意力机制。


图2 注意力机制模块图解


其中, 是一个函数,利用Decoder网络最新的隐藏层状态,和编码器端第1个单词的隐藏层输出作为输入,计算得到。
3 基于注意力机制和RECWE模型的中文词向量
3.1 基于RECWE模型的中文词向量
在以往的词向量模型的研究中,研究者们基于CBOW模型或Skip-gram模型,通过单个通道的结构进行研究。RECWE模型改变了以往的做法,提出了新的方法抽取形态和语义特征,采用与CBOW模型结构相似的并行双通道网络模型,将目标词语的上下文词语和目标词语中的汉字与上下文词语中的汉字及各汉字结构信息一起使用来预测目标单词。同时使用简化的转换和部首转义机制来提取中文语料库中的内在信息,结合丰富的汉字内部结构的形态语义信息。
R E C W E模型结构含有两个子模块。如图3所示左边是词组预测模型(Word Prediction Module),通过利用目标词语的上下文词语进行预测,其中和表示上下文单词,表示目标词,表示词组预测层向量;右边是子信息预测模型(Sub-information Prediction Module),其中分别表示词组预测模块中目标词和上下文词的汉字、部首和汉字组件,模型对部首进行了转换处理,能够充分挖掘汉字的语义信息[14]。表示子信息预测层向量。为了消除音译词语和一词多义的影响,直接使用代替。目标优化函数为:
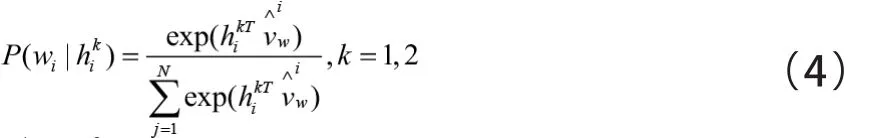
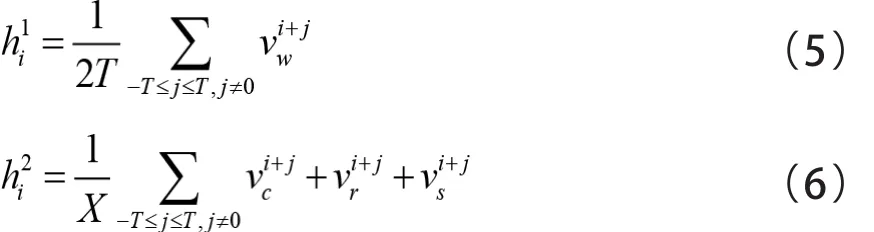
3.2 RECWE模型存在不足
在RECWE模型,词组预测模型通过语义的方法获取关于目标词语的语义信息,子信息预测模型通过形态方法提供更多的语义信息。虽然模型在实验中取得了较好的效果,但是还存在一些问题。
(1)在词组预测模型中,通过对目标词组语的上下文词语向量进行累加求和,没有体现词语对目标词语的重要性,例如“笔记本价格涨幅很大”,当“价格”作为目标词语时,上下文词语中“涨幅”更能体现目标词语的重要性。在此基础上,引入自注意力机制,用于计算上下文词语的权重。
(2)在子信息预测模块,通过对每一条评论语句中的汉字向量、部首向量和组件向量先进行求和再求平均,作为子信息向量。这种方法忽略了各自向量之间对子信息向量不同的贡献。为此,采用基本注意力机制,为三者各自向量划分不同权重,完善模型。最后通过对比实验,验证方法的有效性。
3.3 基于注意力机制和RECWE模型的中文词向量
在原始注意力机制结构的基础上,本文使用Vaswani等人[15]提出的SAN模型,它与传统注意力机制不同之处在于不需要借助额外的语义向量进行计算。该模型处理某一个位置的单词时,会自动处理其他位置的单词是否能够更好地表达目标词语的语义信息,为了充分考虑句子之间不同词语之间的语义及语法联系。在机器翻译任务中,架构分成编码器-解码器结构,假设编码器中长度为 的单个序列输入向量为编码器将输入向量映射为隐藏向量。利用隐藏向量表示整个序列,会导致输入序列语义表示不充分,产生语义信息的损失。因此,计算隐藏向量时,考虑所有时间步长下的隐藏状态,利用下列公式计算上下文向量。
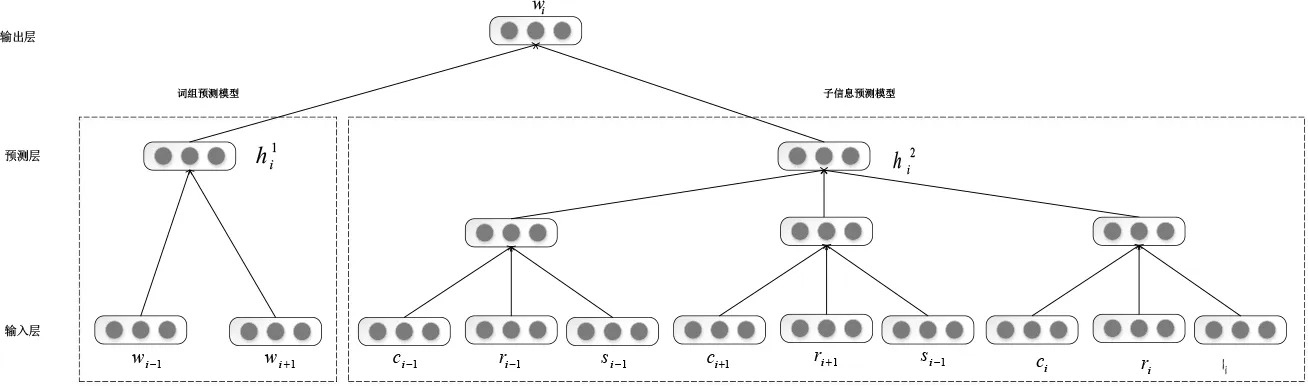
图3 RECWE模型结构
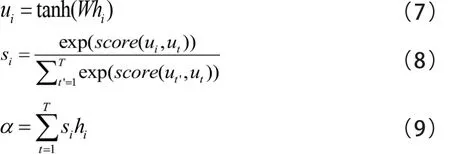
词组预测模型利用单词作为输入变量的最小单位,在计算预测层上下文向量时,采用了公式(5)中累加求和的方式,忽略了不同上下文词语对目标词语的影响力。为此,在自注意力机制思想的基础上,计算公式为:

为了能够自适应学习评论语句中上下文的语义,针对自注意力机制中的权重向量进行了修改,采取了Self-Attention Unit模型中的方法进行计算,引入尺度变换函数,用sigmoid函数计算注意力权重向量。该函数曲线光滑连续,可以根据语境能够较好的区分上下文词语与目标词语的语义关系。修改后的词组预测模型如图4所示。
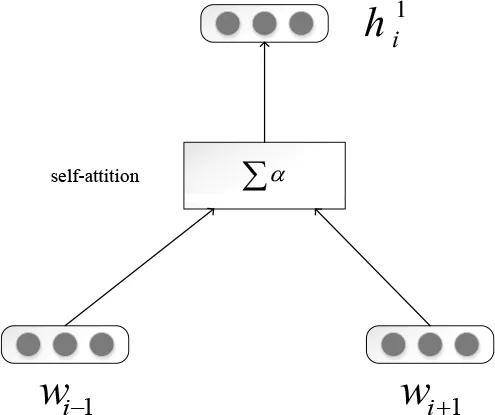
图4 词组预测模型
子信息预测模型利用将对应单词的汉字、部首和字组件之间的语义信息进行累加求和,计算公式如上式所示。模型中每个字都由三部分构成,但是三部分对字的贡献度是不同的。在此基础上,引入基本注意力机制完善模型,为三者增加不同权重。改进后的模型如图5所示。

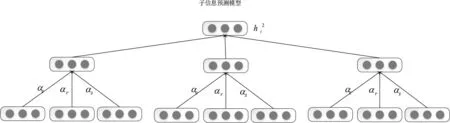
图5 子信息预测模型
式(15)中,通过对三者求平均值作为最终子信息预测层向量。
4 实验分析
4.1 实验数据及实验设置
本文利用爬虫技术获取新闻文本作为实验的数据集。数据集中包含很多的英文,中文标点,乱码等一些非中文字符以及图形表示等问题。为了保证数据集的完整性和平衡性,从中筛选了部分数据。利用脚本从汉典获取数据集的部首和组件数据,语料预处理流程图如图6所示。
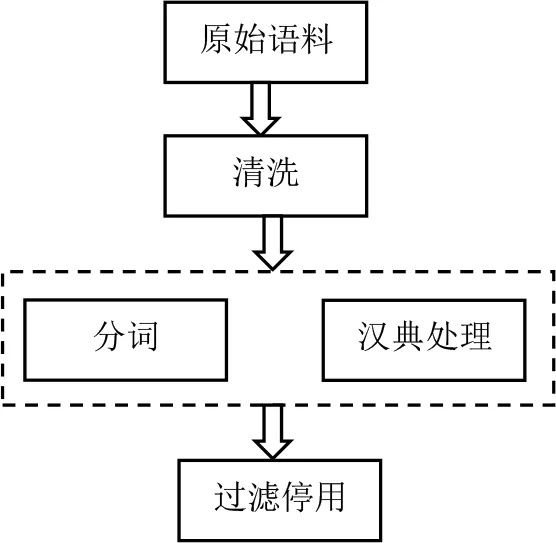
图6 评论文本预处理流程图
清洗的目的是去除数据中有噪音的内容和非文本部分,包括提取原始文本中的标题、摘要和正文等信息[17]。本文主要使用正则表达式进行替换和删除进行清洗。中文分词中使用哈工大社会计算与信息检索研究中心研制的语言技术平台(LTP)的pyltp分词工具[18],其支持使用分词外部词典和使用个性化分词模型,在分词测评任务上,准确率和分词速度取得了较好的成绩。停用词是指文本中出现频率很高,但是实际意义并不大的词语,主要包括语气助词、副词、介词、连词等。本文使用Mallet工具包[19]中所提供的缺省停用词列表,在不影响情感分类准确率的情况下,过滤停用词。实验环境如表1所示。
4.2 模型参数调优及评价标准
实验数据处理完成后,本文所有模型参数进行统一设置,词向量维度选择为200,词窗口大小5,初始化的学习率为0.25,语料中最小词频为5,模型迭代次数为100,高词频下采样阈值为10-4。

表1 实验环境设置
本文使用词语的相似度和类比两项任务进行评价。在相似度任务中,利用余弦值表达单词地相似性,采用Spearman相关系数[6]评价相似度任务的实验效果。在类比任务中,目标是输入一组具有特定联系的词语组,期望推理出含有特定单词的另一组词语。例如“首都城市1-国家1=首都城市2-国家2”,为此,转成数据公式进行表示为,因此需要找出一个与的标准化内积的值为最大值的词
向量,利用余弦相似度计算,计算公式如公式(16)。
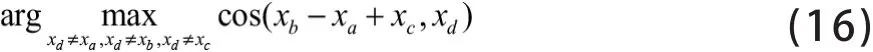
4.3 实验结果分析
在相似度的任务中,为了评估模型改进的效果,选择部分模型作为基础模型进行实验对比。选择wordsim-240和wordsim-296两种数据集作为评测文件。实验结果如表2所示。
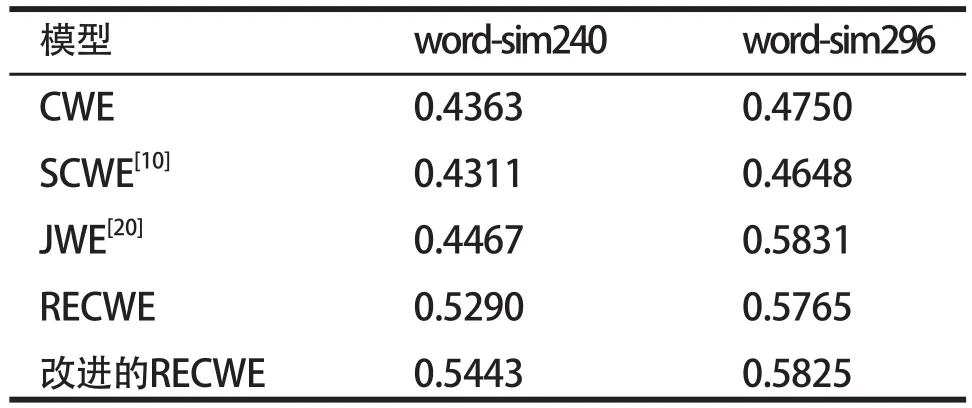
表2 相似度任务实验结果
为了更直观地展示各个模型效果,将上述结果绘制成柱状图,如图7所示。
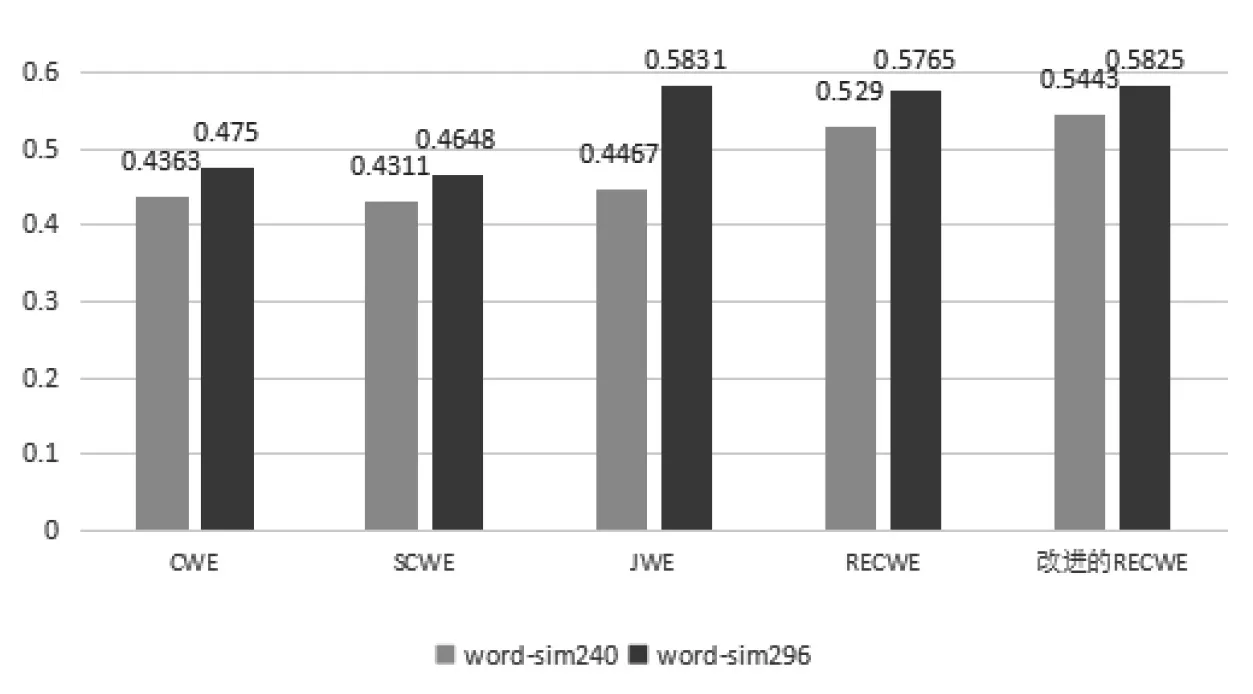
图7 六种模型相似度任务的实验结果对比图
从图7中可以发现,改进的RECWE模型整体上较其他模型在性能上有一定的提升效果,在两个数据集中模型提高了2.89%和1.04%。利用自注意力机制在词组预测模型中,可以发现效果也比其他模型好,说明上下文词语包含丰富的语义信息,自注意力机制可以较好的为上下文词语分配权重。但是在实验过程发现,单个子信息预测模型训练效果较差,原因在于利用汉字及其部首信息会提供一定的语义,辅助词组模型作为更好的判断,但是存在一定的语义含糊或者无法提供语义帮助的情况,比如“东西”是一个名词词语,用于泛指各种具体或抽象的人、事、物。在现代语言交流也包含爱憎情感色彩成分。而其汉字组成“东”“西”分别是方位描述字,无语提供精确的语义信息。此时,需要词组模型根据上下文词语寻找更加匹配的语义信息。
在类比任务中,使用Chen等手动构建的用于中文词向量类比任务的数据集,数据集的统计情况如表3所示。采用准确率作为评估指标,实验结果如表4所示。

表3 数据集的统计情况
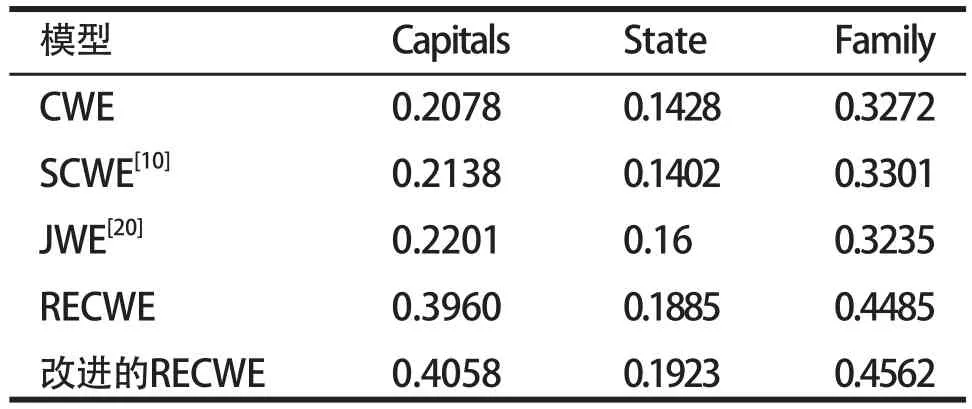
表4 类比任务实验结果
为了更直观地展示各个模型效果,将上述结果绘制成柱状图,如图8所示。
从图8中可以看出,改进后RECWE模型整体上取得了较好的效果,在三个不同主题的数据中,类比任务分别提高了2.47%、2.02%和1.72%,总体平均成绩提高2.07%。说明不同词语中的汉字及汉字部首提供的语义强弱不同,对词语的贡献也是不同的,通过利用注意力机制,可以较好的分配权重,以突出不同成分的重要性。不同类别数据,取得效果是不同的,主要原因是根据训练集有关,存在部门词语的汉字和部首无法提供较好的语义信息,影响类比任务的效果。同时,随着汉字的不断演化,仅仅依靠偏旁部首提供的语义是有限的。

图8 五种模型类比任务的实验结果对比图
5 结束语
词向量是自然语言处理中一项重要任务,在信息安全中广泛应用,比如WebShell检测和XSS注入检测等。将WebShell文件和XSS攻击样本作为普通文本序列,利用词向量模型进行特征提取,通过分类训练识别访问行为和攻击行为。本文在RECWE模型的基础上,通过引用注意力机制的相关知识,分别对词组预测模型和子信息预测模型进行了改进,通过实验验证改进后的有效性。对于信息安全具有重要的实际意义。但是,相比较英文来说,效果还存在一定差距,还需要进一步研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
开放教育研究(2020年2期)2020-03-31 01:54:14
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
高中生学习·高三版(2014年3期)2014-04-29 06:09:37
外语学刊(2011年1期)2011-01-22 03:38:33
