
关系词非充盈态复句的特征融合CNN关系识别方法①
2020-06-20 07:32杨进才汪燕燕胡金柱
计算机系统应用 2020年6期
杨进才,汪燕燕,曹 元,胡金柱
(华中师范大学 计算机学院,武汉 430079)
语义分析是自然语言处理(Natural Language Processing,NLP)领域中的一项基础任务,是自然语言理解的基础.在统计机器翻译[1]、信息抽取[2]、自动问答[3]和计算机辅助评估[4]等下游任务中,通过语义分析获取句子级别上的丰富的语义信息,推动自然语言处理领域的发展.
汉语文章中有2/3 的句子是复句,因而复句在现代汉语中占十分重要的地位.复句通常由两个及两个以上意义密切相关的分句组成.关系词(也称关系标记)是用来连接各个分句构成复句的语法成分,但在汉语复句中,分句中的关系词可以部分省略或全部省略[5].
关系词非充盈态复句是指关系词在分句中没完全显式出现的复句.复句的关系类别是指两个分句之间语义关系类别,一个含有多个分句的复句可以划分为多个含两个分句式的复句.因此,本文选取含有两个分句的二句式复句作为研究对象.
二句式复句定义为一个二元组 〈c1,c2〉,其中c1,c2 为分句.
非充盈态复句满足:(r(c1)=Φ∧r(c2)≠Φ)∨(r(c1)≠Φ∧r(c2)=Φ)
复句的类别与关系词搭配有很强的关系,一个关系词与不同的关系词搭配,构成不同的类别.例句1 中,关系词“既”与“也”搭配,复句关系类别为并列关系.例句2 中,关系词“如果”与“也”搭配,类别为因果关系.对于一个每个分句的关系词显式出现的充盈态复句,根据关系词搭配的可以判断出对应的类别.对于例3,例4 和例5,仅分句2 中出现关系词‘也’,对这样的关系词非充盈态复句,无法根据关系词的搭配直接判断复句的类别.
例1:这种电话既是用于紧急情况下的报警,也用于遇到一般困难时的求助.
例2:如果技术掌握得当,阔叶树移栽也有成功的实例.
例3:当我的独创产品成为世界一流时,我也自然而然跻身于世界强人之列.
例4:他听课,也不打声招呼.
例5:条件不同,面临的任务也不同.
1 相关工作
对于复句关系类别识别的方法分为两类,第一类是借助关系词识别和关系词搭配的研究分析复句的语义关系.Huang HH 等基于半监督学习方法探索关系标记的概率分布,发现成对的关系词连用对分析篇章的语义关系起到的强提示[6].胡金柱、舒江波等将词性和关系标记搭配理论相结合,提出正向选择算法用于关系词识别[7].胡金柱、陈江曼等分析了关系词连用情况,提出一种连用关系词识别算法[8].胡金柱、胡泉等对在关系词识别过程中的规则解析算法进行了研究,提出了包含匹配算法[9].
第二类是结合句法树的词法、句法特征,采用机器学习的方法识别复句关系类别.李艳翠、孙静等基于已标注的清华汉语树库,采用最大熵、决策树和贝叶斯方法判断准关系词是否为关系词以及复句关系类别的识别[10].周文翠和袁春风[11]选取主语、谓语等相关特征,使用支持向量机模型识别并列复句.杨进才、陈忠忠等结合汉语复句的句法理论和分句间的语义信息,提出了基于语义相关度的非充盈态的二句式复句关系类别识别[12].Huang HH 等利用决策树算法提取词性、句子长度、关系标志特征,来识别汉语句子间的因果、并列关系[13].
上述方法需要依赖良好的语言学知识,通过人工总结规则以及发掘特征,不利于发现隐藏的特征,影响识别系统的自动化.
本文以复句整体为处理对象,在神经网络模型中输入关系词特征,以自动地从复句分句中发现与关系词相关的蕴含的语义关系特征.
2 方法
2.1 复句分类体系
汉语复句关系分类体系很多,著名汉语语言学家邢福义先生的复句关系“三分系统”[5]是目前广泛使用的主流的分类体系.三分系统将复句分成因果、并列、转折3 大类,其中每一大类又分成多个小类(如表1所示).
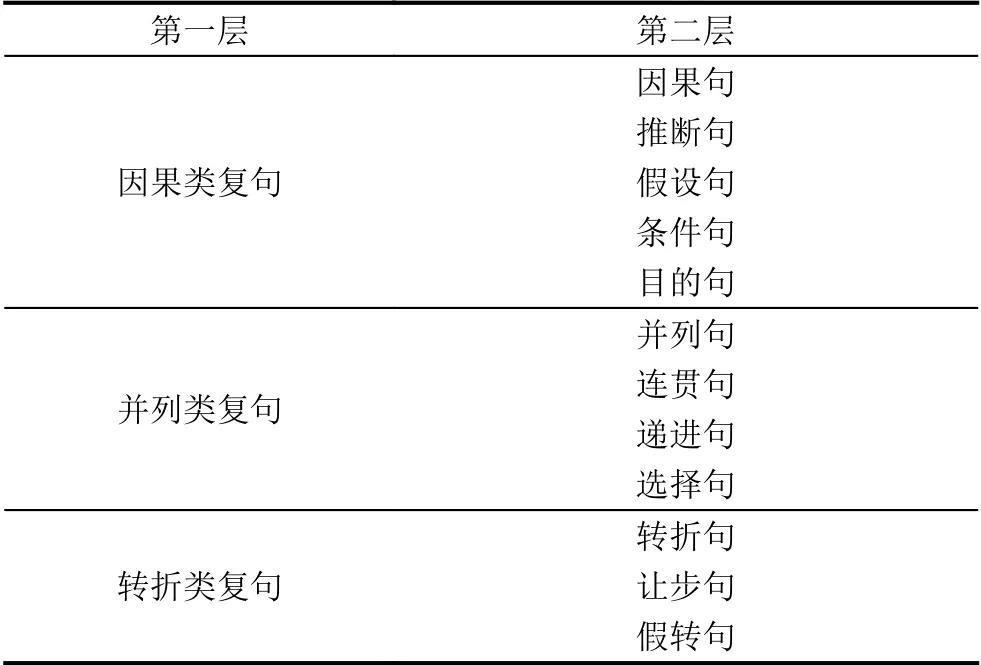
表1 复句三分系统
R<c1,c2>为复句关系类别.R(<c1,c2>)∈{因果,并列,转折},因果={因果|推断|假设|条件|目的},并列={并列|连贯|递进|选择},转折={转折|让步|假设}.本文采用复句三分系统作为类别标识标准.
2.2 模型结构
使用的Shallow CNN 模型结构如图1所示.首先,利用查询词表,提取词对应的词向量,将整个复句转换成句子向量并将其作为卷积层的输入[14];同时,将关系词特征输入到我们的模型中.经过卷积和maxpooling操作,不同窗口大小的滤波器获取不同的特征映射,最后这些特征连接起来,作为全连接层和Softmax 层的输入,输出各个类别概率分布.
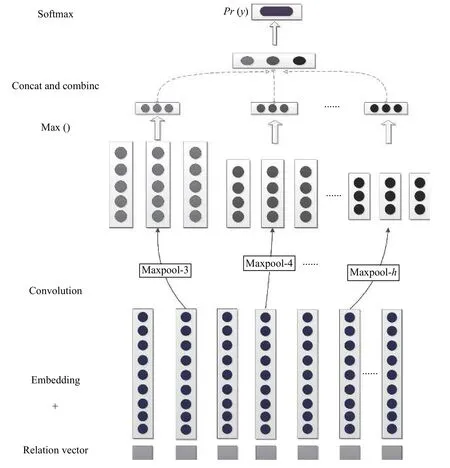
图1 SCNN 的结构图
2.3 词向量的获取
一个关系词在不同的语境下,对应的复句关系类别可能不同,关系词与类别是一对多的关系.经过对大规模地语料统计,我们考察了关系词在关系类别、词性、搭配情况以及在搭配中处于前呼还是后应等属性,统计了499 个准关系词的上述特征属性,构建关系词库.
图2展示的是部分关系词与复句关系类别的对应.根据关系表采用onehot 离散化每一个词,得到每一个词对应的关系向量,Rri∈Rl中(其中l是关系类别数),若用Xi∈Rk表示每个词在预训练词向量中对应的向量,则每个词对应的特征向量记为Yi:
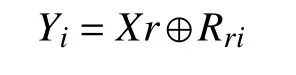

图2 关系词——关系类别对应
一个长度为n的句子表示为:

其中,⊕是连接操作,用Yi:i+j代表特征Yi,Yi+1,···,Yi+j之间的拼接操作.
2.4 卷积核最大池化操作
卷积操作是滤波器w∈Rnk,一个大小为h个单词的窗口的滤波器产生新特征.例如,一个特征ci是由大小为Yi:i+h-1的窗口生成的.句子级的特征向量利用滤波器矩阵[W1,W2,···,Wn-h+1]进行卷积操作生成,这些句子级的向量被转化为特征映射:

这里的下标[i+h-1]表示卷积窗口的始末下标.此外,在embedding 层和滤波器矩阵之间应用卷积操作,即利用不同窗口大小的卷积核作用于整个句子,以获取不同的特征映射表示,得到复句的不同特征表示.接下来,在上一步得到的特征映射中使用max-pooling 操作[15],即=max(),这样就得到了特征映射中最重要的特征
2.5 拼接操作
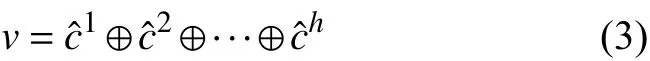
然后将得到的特征通过全连接层Softmax,输出最终的概率分布.
2.6 模型训练
在训练过程中,我们有两种类型的词向量:一种是直接通过训练数据训练词向量,另一种是结合关系词特征得到的词向量.
CNN 网络训练是基于梯度的Adadelta 优化器[16]和反向传播算法[17].同时,我们结合了early stopping[18]和dropout[19]来防止过拟合.
交叉熵函数用来证明可以加速反向传播算法,提供良好的网络性能和相对较短的停滞期,尤其对分类任务[20].为了构建目标函数,应该考虑交叉熵损失函数和L2 正则化项.我们使用ReLU 作为模型的激活函数,可以产生与Sigmoid 函数接近的结果,而ReLU 不存在指数计算,求导计算量小,且收敛得更快,同时缓解了过拟合的情况.模型参数调节列表如表2所示.
3 实验与分析
3.1 数据集
汉语复句语料库(the Corpus of Chinese Compound Sentence,CCCS),可访问http://218.199.196.96:8080/jiansuo/TestFuju.jsp 获取.语料库是包含658 447 条的汉语有标复句专用语料库.来源于《人民日报》、《长江日报》.我们从中选取了24 706 条二句式非充盈态有标复句,构成语料库简记为NCCST.NCCST 语料库中,各关系类别的数据分布如表3所示,3 种关系类别的数据分布是不平衡的,这会影响模型的训练效果,易造成过拟合,模型难收敛.本文采用过采样技术[15]处理不平衡样本数据.
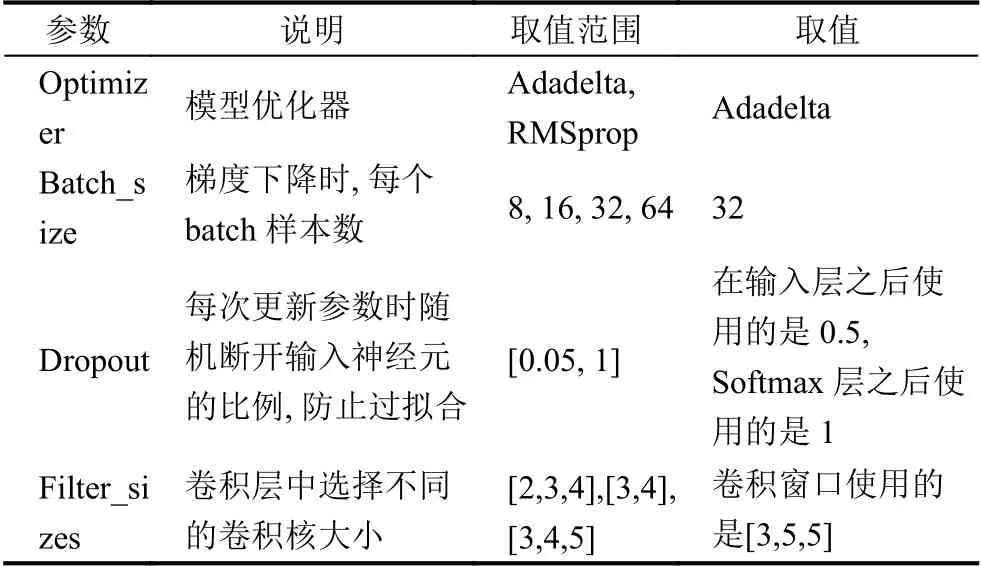
表2 模型参数调节列表

表3 数据统计分布表
3.2 实验对比与分析
决策树算法(C5.0)[13]:作为传统机器学习模型的代表,在各种分类问题上取得不错的效果.本次对比的对象中,Huang HH 等使用了词性、句子长度和关系连接词等特征,用C5.0 模型训练.
Semantic_relevance 模型[12]:该模型是基于汉语复句语义相关度计算,主要考虑了词语共现、关系词搭配距离、词间距等因素.根据计算结果判别复句语义关系类别.
我们进行了3 个实验,第1 个是预训练词向量作为CNN 模型的输入;第2 个实验在CNN 中引入外部知识,加入了关系词特征,得到融合模型FCNN;第3 个是对比实验,与文献[13]中,Huang HH 等用决策树算法进行的汉语句子的关系分类进行对比.此外,我们也进行了是否使用停用词表(停用词表不包括所有的关系词)的对比实验,实验结果表明其对结果影响很小,几乎可以忽略不计.
表4的结果显示,Shallow CNN 比文献[12]和文献[13]中的方法在正确率分别高出5.16%和1.96%,说明神经网络利用词向量能够捕获基本的词法、语义相似度一些信息.Shallow CNN 通过卷积运算自动学习词法方面的特征,将低级特征组合成高级特征,得到整个复句的语义表示;同时使用max 池化操作捕获复句关系词特征,对复句的关系类别识别起到显著的作用.

表4 识别正确率的对比结果
4 讨论
为了保证实验结果的公平,所有模型使用的是同一数据集.表5分别展示了C5.0、shallow CNN 和FCNN模型在Precision、Recall 和Macro-F1 不同的表现结果.
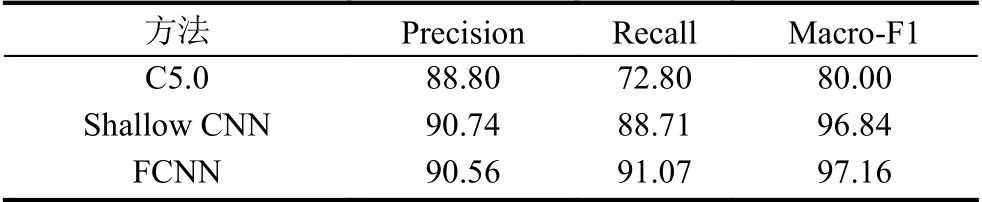
表5 不同评价指标的实验结果比较(%)
结果表明,相比较于C5.0,Shallow CNN 和FCNN在Macro-F1 上高出16.84%以上,这表明我们的方法在复句关系分类方面要好于C5.0 算法.C5.0 算法是决策树算法的一种,该算法需要人工构建特征,分析分句之间的语言学特征比如词性、关系连接词等,从而构建对应的特征矩阵.因此,特征的选取对C5.0 算法起到关键的作用,而特征的好坏依赖于语言学知识和规则的总结.本文提出的Shallow CNN 模型直接利用CNN 做特征提取,得到句子的特征表示.值得一提的是,FCNN 在Shallow CNN 的基础上加了关系词特征,它在召回率和Macro-F1 上比Shallow CNN 好,分别提高了2.36%和0.32%,这表明关系词提供了一些有利于复句关系类别分类的信息.FCNN 模型融合关系词与关系类别之间映射关系这一特征,首先CNN 利用embedding层获取复句的语义特征表示,然后融合对关系类别识别起到关键作用的关系词特征,进一步强化神经网络自动学习该特征,从而更加高效地识别关系类别.
我们对标识结果进行统计分析,发现FCNN 模型不仅对于一个关系词对应单种关系类别的识别效果好,并且对于像“也”这样的关系词,它对应多个关系类别(如图2所示),FCNN 也要比Shallow CNN 的识别效果要好.对于文中的例句,FCNN 能够识别出例3 是并列关系,例4 是转折关系,例5 是因果关系.模型中融合了关系词特征,从侧面说明了关系词特征对复句类别的识别起到了提示作用.
我们进一步分析使用预训练词向量初始化的影响.如图3所示,相比较于使用(-1,1)的均匀分布初始化词向量,而使用训练语料初始化词向量的Micro-F1 值大约提高了24%.
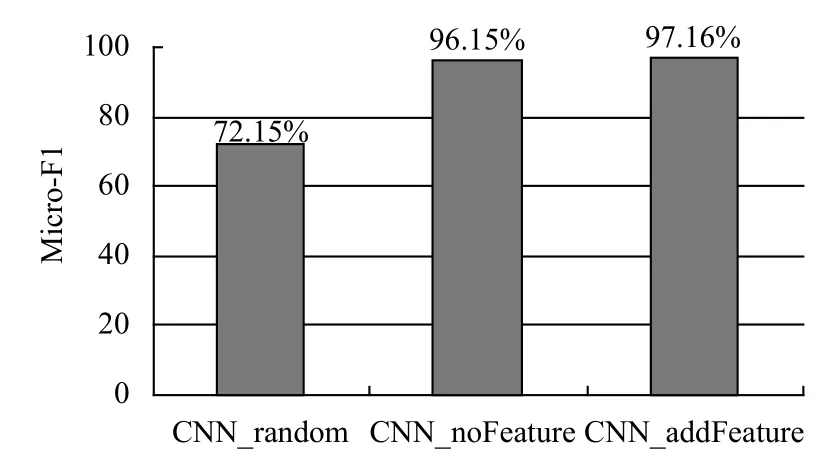
图3 词向量不同对模型的影响
依据上述分析,一方面,基于特征的方法会很大程度地依赖特征提取的质量,并且耗时耗力;另一方面,特征提取又需借助于NLP 解析工具,这也会带来解析工具已经存在的传播误差,影响系统性能.因此,Shallow CNN 和融合特征的FCNN,减少对先验的语言学知识和大量的手动提取的特征的依赖,总体上要优于传统的机器学习的方法.
5 总结
本文中,我们利用卷积神经网络模型学习了两个分句之间有效的关系表示,进一步训练Shallow CNN分类器,更好地处理复句的两个分句的语义关系,并且该模型对复句的关系分类是简单高效的.当加入关系词特征时,系统的效果得了提升,我们模型已远远优于仅依赖手动提取特征的模型.自动学习特征能得到很好的结果,可用于替代利用语言学知识和现有的NLP 工具设计的特征.
在接下来的工作中,我们将重点探索无标复句的关系类别识别.并在依存句法树上构建神经网络模型,融合更丰富的语法与结构特征[21].
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都理工大学学报·社会科学版(2022年1期)2022-05-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
少儿画王(3-6岁)(2020年4期)2020-09-13
时代人物(2019年14期)2019-11-21
新生代(2019年3期)2019-10-19
东方教育(2018年20期)2018-08-22
微型计算机(2009年4期)2009-12-23
