
基于深度学习的目标人物情绪预测①
2020-06-20 07:32:18刘勇,王振
计算机系统应用 2020年6期
刘 勇,王 振
(青岛科技大学 信息科学与技术学院,青岛 266100)
恐惧、焦虑、内疚、压抑、愤怒、沮丧······每个人的身体里,都有一张关于情绪的地图.研究指出,70%以上的人会不同程度的遭受到情绪对身体器官的“攻击”,如“癌症”的产生与长时间的怨恨情绪有关[1],经常受到批评的人容易患关节炎[2]等.据统计,目前与情绪有关的病已达到200 多种,在所有患病人群中,70%以上都和情绪有关.因此,我们可以通过跟踪目标人物的情绪变化,及时的将结果反馈给相关专家进行分析,在分析值到达某临界状态时,进行预警处理.故通过分析情绪波动状况来及时发现、处理情绪变化的影响,可以更好的辅助疾病预防工作.
目前,越来越多的人喜欢通过微信、QQ 等实时在线工具进行沟通交流.为更好的发现和关注目标人物的情绪波动状况,我们结合深度学习相关技术,研究了基于深度学习对目标人物情绪预测.
针对情感预测方面的研究已受到国内外学者的广泛关注.从Hearst 等[3]开始表示情感倾向分析预测在文本处理中的重要意义.此后Brown 等[4]发现情绪指标与投资者的关系.在最近几年,Pagolu 等[5]使用Word2Vec对情绪进行了预测分析,将情感预测的准确率提升到一个新层次.李潇潇等[6]依据DHS 模型对情感的影响及走势建立了模型.朱小微[7]通过使用TS-BP 模型,实现了对中文影评情感倾向的研究.
以往关于情感倾向预测研究中大部分使用统计和机器学习的方法,而统计方法会带来准确率低等问题.使用机器学习的方式可以带来准确率的提高,但其分类效果仅停留在二分类方面.深度学习的出现解决了这两种方法的局限性,在提高准确率的同时,保证分类结果不再局限于两类
本文提出了一种基于深度学习的目标人物的情绪预测模型.首先调用BERT 预训练集,训练好情感识别模型,然后调用情绪定量算法,判定一个人的情感常态,最后将模型与定量算法结合对目标人物的情感进行预测.
1 情绪预测概述
在情绪预测算法中,最重要的是情绪定量相关的算法.只有将情绪进行量化处理,才能进行数值的预测与分析.因此,在情绪预测前必然要迈过的一道门槛儿就是情绪定量问题.在目前情绪定量的算法中,人们更多的是通过特征词对情绪进行定量.Hu 等[8]利用规则提取出高词频的名词和名词性短语作为高频属性,但该方法的问题是属性词过于分散,且没有进行归类筛选,从而导致实验的准确度较低.周清清等[9]利用高频名词构建候选属性词,通过深度学习来构建候选属性词向量,根据属性词向量完成候选属性词聚类,得到目标候选属性词集.这种方法可以更全面发现评论对象细粒度属性,但在噪音过滤方面仍需加强,并且对于冷门属性的效果较差.此外,也有好多的实验更偏向于心理学和理学方面,而没有站在计算机角度去分析研究.在未来的发展中,只有不同学科领域进行交叉融合,才能更好的应用于现实生活.因此,本文提出了一种基于数据集的定量方法,通过研究目标人物的日常整体对话,来对其整体情绪进行定量.
目前,在情绪预测方面有很多的学者都以网络文本来做相关研究,但最终更多的是应用在经济领域上.Oliveeira 等[10]使用从微博中提取的情感和注意力指标(采用大型Twitter 数据集)以及调查指数来预测股市的行为.Si 等[11]提出一种基于Twitter 情感主题的技术来预测股票市场.Ding 等[12]发现Facebook 的“like”数量会影响票房表现.张帅等[13]通过识别分析投资者的情绪来预测研究市场的成交量.
本文提出情绪定量和拟合算法,结合情绪定量化与算法进行预测.首先通过训练改进对话识别模型,执行参数传递来启动情感预测算法.通过情绪预测的定量算法确定用户的情绪程度系数,用BERT 神经网络进行情绪分类.将得到的分类情绪与程度系数相结合,得到一天的整体情绪,放到情绪拟合算法中,预测目标人物第二天的情绪.具体架构如图1所示.其中,数据集有两大作用,一是通过定量算法的调用确定情绪程度系数,二是为神经网络的训练提供训练集.
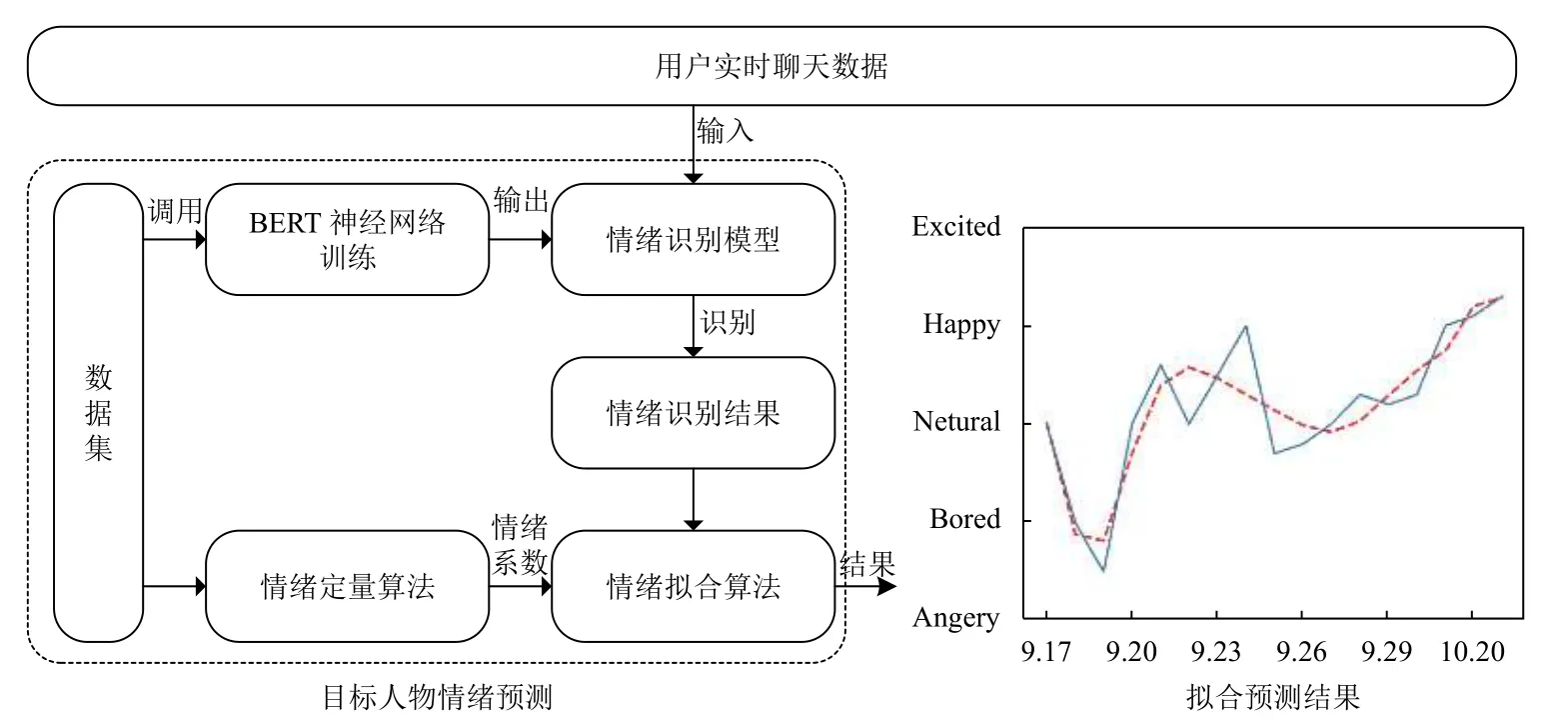
图1 情绪预测算法架构
2 情绪定量和拟合算法
在情感定量和拟合算法中,数据集是其基础的数据.因此算法中为了使识别到的情绪更加准确,添加了多种标签.分别为气愤,厌烦,中立,开心,兴奋5 种情绪标签,并分别使用1,2,3,4,5 来进行代替.同时,我们也对数据集加上了具体的时间特征,来为最终结果的定量分析与时间引用提供帮助.
2.1 情绪定量算法
目标人物在某个具体时间的情绪很好判断,但是其一天内的情绪却无法判断,因此在本节提出一种情绪定量算法来判断一天内的主流情绪.
由于每个人的情绪状况也不是均衡分布的,比如有的人生性易怒,有的人天生和善.情绪定量算法应用了归一化算法Z-score 标准化(0-1 标准化方法).将每个人的脾气进行分类,根据数据集给每种情绪来确定其情绪程度系数进行定量.具体公式如下:

其中,x表示5 种情绪中一种情绪的标签待定数值,μ表示所有数据集平均值,σ表示所有数据集的标准差也称为标准偏差.
σ标准差公式如下:

其中,N为数据集的数量大小,xi是 数据集中第i个数据的情绪待定值.
除去8 小时晚上休息的时间,我们按照一天的16 个小时对识别结果进行处理.根据数据集的标注,将其中1 代表生气,2 代表厌烦,3 代表中立,4 代表开心,5 代表兴奋,通过如下公式进行处理,对一天内所代表的情绪进行总结:
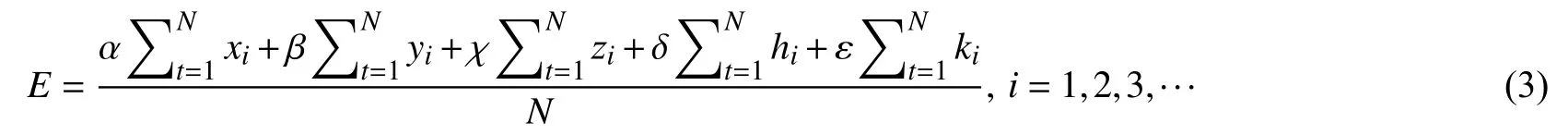
其中,E代表一天内的主流情绪,α,β,χ,δ,ε分别代表生气,厌烦,中立,开心的情绪程度系数[14],是由式(1)所求出的 |X*|,N代表的是识别到的一天内情绪个数,最终得到的E值就代表了该目标人物某一天的主流情绪.
2.2 情绪拟合算法
为解决根据已知数值来预测未来数值的难题,我们将数学领域中的最小二乘法公式与情绪识别领域相结合,提出了一种新的情绪拟合算法.在识别出情绪,完成定量后,下一步需要对未来的情绪进行预测,情绪拟合算法使用最小二乘法的思想来对已知结果进行拟合曲线,来预测未来可能产生的情绪.
最小二乘法(又称最小平方法)是一种数学优化技术.该技术通过最小化误差的平方和来寻找数据的最佳函数匹配.利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小.下面我们以一元的公式为例,最小二乘法公式推导如下:
给定如下成对的数据{(x1,y1),(x2,y2),···,(xm,ym)},设待拟合的公式为:
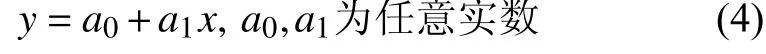
误差结果为:

当拟合直线的误差最小时,直线参数a0,a1满足:
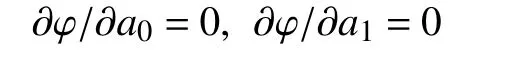
即:

整理上式结果可得:
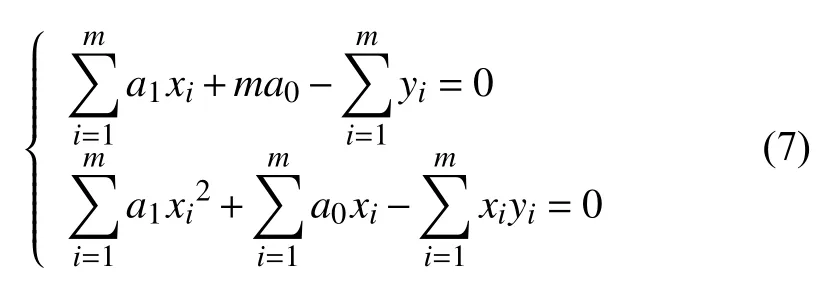
求解方程组可得:
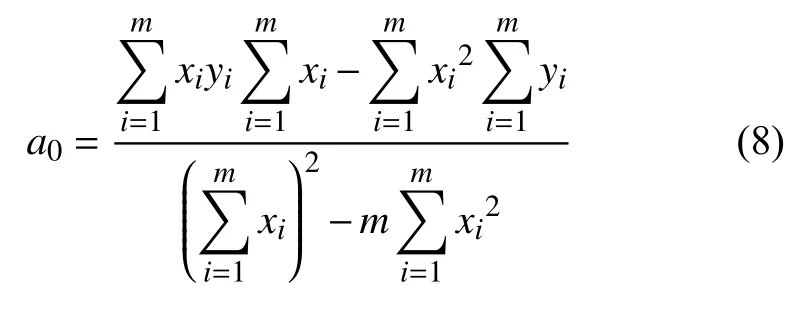
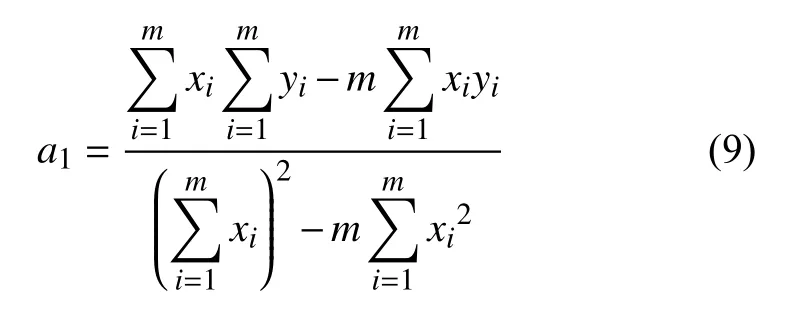
最终将得到的a0,a1带入式(1)中,得到0 最终求解,然后再使用y=a0+a1x公式,结合后面BERT 做好的情绪分类与定量算法相结合所得到的数值,去预测目标人物情绪的变化.
3 目标情绪识别
目标情绪识别是将目标人物的情绪识别出来,并且进行定量分析和对目标人物的情绪进行汇总,再进行预测.
如图2所示,首先对数据集进行预处理,然后对数据集中的语句进行分词处理,处理完毕将其放到BERT[15]的预训练模型中转换成向量后,再将其放入到BERT神经网络中对其进行训练,之后利用训练好的模型对目标人物的简单对话进行识别,对识别的情绪进行汇总预测与分析,得到最终结果.
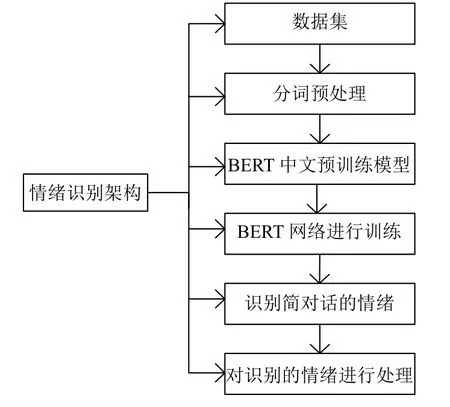
图2 系统总体架构
BERT 作为Transformer 结构的网络一经推出,便刷新了很多NLP 任务的最好性能,其结构如图3所示.在SQuADv1.1 上将BERT 与其他先进的NLP 系统进行了对比,获得了93.2%的F1 分数(一种准确度的衡量指标),超过了之前最高水准分数91.6%合人类分数91.2%.并且BERT 具有广泛的通用性,可以很简单的移植到情感分类方面.
BERT 作为Transform 特征抽取器,与传统的循环神经网络相比,可以获取更长的上下文信息.同时,传统的LSTM 模型只学习到了单向的信息,而BERT 改进了常见的语言双向模型,转而使用上下文融合语言模型.其不同于Word2Vec 需要对输入模型的所有词序列进行预测,BERT 语言模型不再是简单地将从左到右和从右到左的句子编码简单拼接起来,而是随机遮挡部分字符,训练中损失函数只计算被遮挡的token[16],避免了上下文中对当前词类的影响,在真正意义上实现双向.

图3 BERT 预训练语言模型
预训练是BERT 的重要部分,但预训练需要巨大的运算资源.按照论文里描述的参数,其Base 的设定在消费级的显卡Titan x 或Titan 1080ti (12 GB RAM)上,甚至需要近几个月的时间进行预训练,同时还会面临显存不足的问题.
谷歌公布的预训练集为两部分,分别为Base 版本和Large 版本,Base 版本大小在400 MB 左右,Large版本大小在1.2 GB 左右.谷歌针对大部分的语言都公布了BERT 的预训练模型,满足了各国研究者的需求.因此可以更方便地在自己的数据集上进行微调.
4 实验及其结果
4.1 数据集
本文使用的数据集为subtitle 电视剧对话数据集,经过整理筛选出17 500 句日常的简单对话,对其进行校准标注.其含有包含 5 种情感,其中喜悦、兴奋、愤怒、生气各有3300 条,平常的感情状态有4300 条.数据结构如图4所示.对话数据集包含3 部分:时间,内容和情绪标签.我们可以根据时间去推算情绪随着时间的变化,根据内容和情感标签,去训练神经网络,以及情感系数的确定.
4.2 数据集处理
在进行训练时,BERT 开始前会给每个输入文本开头和结尾分别加上[CLS]和[SEP].在中文BERT 模型中,中文分词是基于字而非词的分词.BERT 会为标识真实字符/补全字符标识符,其中真实文本的每个字对应1,补全符号对应0,[CLS]和[SEP]也为1.转换完成后的特征值就可以作为输入,用于模型的训练和测试.
完成读取数据、特征转换之后,将特征送入模型进行训练,训练算法为BERT 专用的Adam 算法,其中的训练集、测试集、验证集比例为3:1:1.

图4 对话数据集
在保存训练集时回保存为TFRecord 类型的文件减小,程序运行时零散的数据集对其的影响.我们进行训练调用,与验证时同样直接调用TFRecord 文件.
4.3 实验环境及参数设置
实验中涉及神经网络参数的设置,具体设置如表1所示.使用谷歌开放的中文预训练模型参与训练,Base版本Chinese_L-12_H-768_A-12,使用的训练机器为双显卡1080ti,显存为12 GB.使用的编程语言为Python,使用到的主要库为Tensorflow1.9.0.

表1 模型参数设置
4.4 实验结果与分析
为了验证本文提出的基于深度学习在情感预测上面的有效性,分别使用过BERT 和正在广泛应用Bi-LSTM,LSTM 进行对比.实验中没有使用SVM 等机器学习方法是由于机器学习方法仅能做到两分类状况,无法做到多分类.
图5为不同深度模型中运行结果的对比图,在第一行中分别使LSTM,Bi-LSTM,BERT 对同一天的数据对其预测的结果图,其中横轴为时间纵轴为情绪,其中每一个点为经过训练模型识别得到结果.从图中可以看出,主要为早上8 点到晚上24 点之间的情绪变化.第二行为同一数据对半个月内的情绪变化,其中虚线为对情绪变化的拟合.可以看出LSTM 对下一步的情感预测将是往平淡方向发展,而Bi-LSTM 和BERT 的趋势将是往兴奋方面发展.
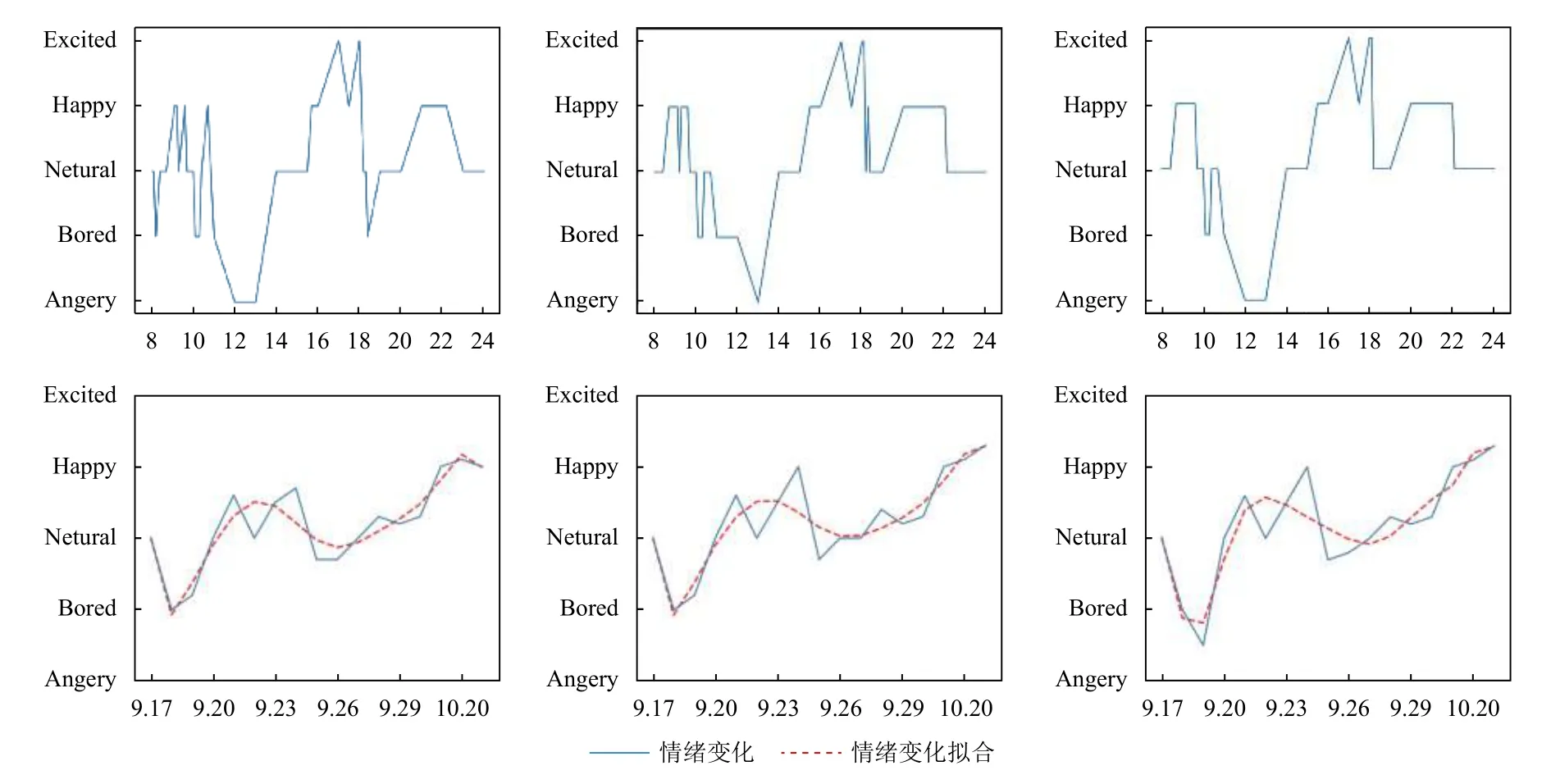
图5 运行结果对比
得益于BERT 在特征提取方面的优势和双向性的结合他的F1 值高于LSTM 和BI-LSTM,足以展现其在深度学习当中的优势.
在用BERT 进行训练时,其验证集的准确率可以达到90%,其中验证集的误差是0.3.其中结合情感定量算法所得到的情感系数从生气到兴奋之间的系数分别为0.89、1.27、0.89、1.74、0.89.从系数可以看出,其偏向于乐观的性格.虚线表示为经过情绪量化算法后得到的结果,蓝色曲线的变化为目标人物从9.17 到10.3 这段时间内的情绪变化,虚线为拟合算法拟合出来的预测曲线最高次幂为10 次,其结果如表2所示.

表2 实验结果
再将x值相当于日期输入到公式中即可预测其目标人物的未来情绪状况.
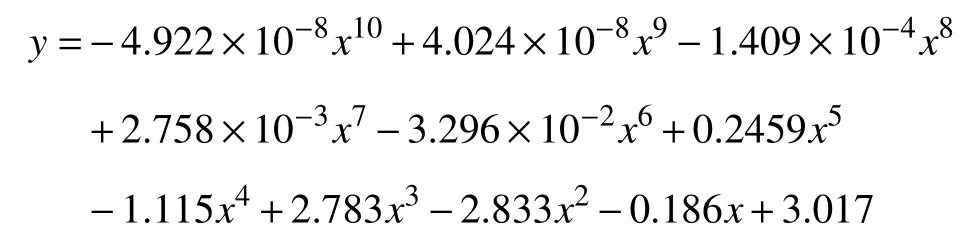
实验结果如图6所示,随着预测需要预测时间的增加,其准确率也在不断地变化,从第2 天的90%准确率逐步降低,当预测到第10 天时,准确率下降速率最快,但是随着时间的推移预测的准确率也在不断的降低,最终的结果在20%上下浮动.
5 总结与展望
本文主要使用基于深度学习的方法进行情感预测,使用BERT 来训练情感识别模型,然后通过情绪定量算法,判定一个人的情感常态.最后将模型与定量算法相结合有效预测目标人物的情感走向变化.
本文提出的情感预测模型有广阔的发展应用前景.在医学领域,可以通过对目标人物的情绪变化信息进行收集,为目标人物的疾病进行预警.在市场经济领域,也可以利用情感预测模型大体判断出目标投资人的意愿走向.
为进一步提高精确度,可以增加数据集内容.在后续工作中,可以从细化,完善数据集中的标记规则进行着手,同时扩展语料的规模.单纯使用实体权重相同的损失函数进行训练效果并不是太理想,可以对各类设置加权损失函数,进一步提升情绪的识别效率.
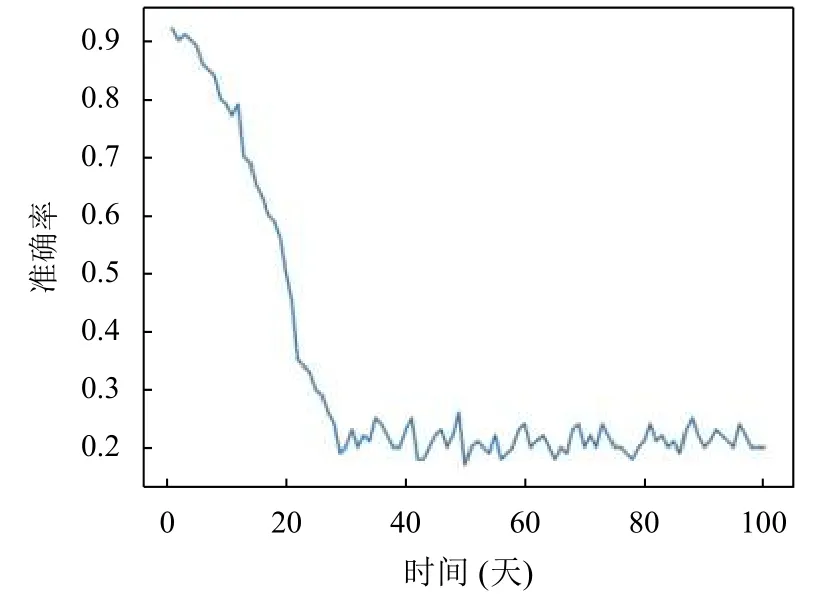
图6 准确率与时间推移的关系
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
世界科学技术-中医药现代化(2020年2期)2020-07-25 02:06:06
中成药(2018年12期)2018-12-29 12:25:44
风流一代·青春(2018年2期)2018-02-26 15:27:06
风流一代·青春(2017年6期)2018-02-14 19:28:55
风流一代·青春(2017年5期)2018-02-14 09:32:37
中成药(2017年6期)2017-06-13 07:30:35
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
