
Elman神经网络在优化空气预报模式结果中的应用①
2020-06-20 07:32:30于海飞1杜毅明金继鑫曹吉龙赵思彤
计算机系统应用 2020年6期
张 镝,于海飞1,,刘 闽,杜毅明,金继鑫,曹吉龙,赵思彤
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(辽宁省沈阳生态环境监测中心,沈阳 110000)
4(中国医科大学附属第四医院,沈阳 110032)
5(沈阳市第二十二中学,沈阳 110000)
改革开放以来,我国大力发展工业、制造业,经济发展的同时,带来的环境问题也不容忽视.近年来,空气质量状况越发得到人们的密切关注,2017年我国空气污染状况以华北地区为中心呈放射状分布,空气质量直接影响到人类的日常生活[1].绿水青山就是金山银山,地处东北老工业基地的沈阳市也面临着同样严峻的空气质量问题.空气质量的精准预测能够为空气质量的治理提供科技支撑,各项污染物浓度数据是计算空气质量指数进而衡量空气质量的重要依据.
空气质量数值模式是一种通过大气物理化学方式来模拟污染物之间的相互反应、传输和转化过程,进而预测空气质量的方法.空气质量模式CMAQ 和CAMx是依据大气物理化学方法来模拟污染物的扩散和反应过程进而来预测空气质量的方法.从最初的采用简单线性机制的第一代空气质量模式,发展到考虑了物质之间的互相作用和相互转化的第三代空气质量模式,预测精度不断提高.但是由于空气质量模式受污染源清单数据,气象数据,光解文件等输入文件的影响,输入文件的质量会影响预测结果误差大小.因此本文提出了一种集成CMAQ 和CAMx 两种单一空气质量模式结果的方法,在单一数值模式的基础上降低误差,提高预测准确率.司志娟等[2]将灰色GM(1,1)模型与人工神经网络模型组合,对天津市2009 到2010 的PM10、SO2、NO2进行预测,预测相对误差在5%以下.张恒德等[3]利用BP 神经网络集成了CUACE、BREMPS和WRF-Chem 等3 个环境模式预报产品,2015 到2016年在北京和石家庄地区污染物浓度和实测值的均方根误差比各单一模式降低了15%以上.梅贵琴[4]利用Elman神经网络根据以往臭氧浓度数据预测未来臭氧浓度值,绝大多数的数据可以达到小于0.2 的相对误差.神经网络具有预测未来非线性数据的能力,应用于各个地区空气质量预测方面取得了良好的效果.考虑到过往短时间段内空气质量会对未来空气质量产生影响,而Elman神经网络能够增加对过往数据的敏感性.因此本文提出将Elman 神经网络用于集成CMAQ 和CAMx 两种数值模式的预测结果,在单一数值模式基础上提高空气质量预测结果的准确度.
1 Elman 神经网络
Elman 神经网络是一种反馈型神经网络,由输入层,隐含层,承接层,输出层四层组成,承接层是从隐含层获得反馈信息,然后再输入到隐含层,以此来记忆隐含层神经元的上一时刻的输出,这样的网络结构可以增强对过往数据的敏感度[5-8].Elman 神经网络结构如图1所示.其中,输入向量是r维的x向量,x=[x1,x2,···,xr];隐含层输出向量是n维的u向量,u=[u1,u2,···,un];输出向量是m维的y向量,y=[y1,y2,···,ym];承接层输出向量是n维的xc向量,xc=[xc1,xc2,···,xcn].w(i,k),w(k,j),w(s,k)分别是输入层到隐含层,隐含层到输出层,承接层到隐含层的权重矩阵[9].f(·),g(·)分别是隐含层和输出层的激活函数,h(·)是承接层激活函数,Xc是承接层输出,t是时间步长,输出层输出为:

隐含层输出为:

承接层输出为:

Elman 神经网络模型的算法学习流程,首先要初始化各层节点的权值,然后输入训练数据,计算各层的输入输出值.其中将隐含层上一轮的输出,输入到承接层,数据经过承接层处理后在本轮和输入层数据一同输入到隐含层.最后根据输出层的结果和误差函数计算误差,若误差的大小满足要求或训练次数达到最大,则停止训练,否则更新权值,进入下一轮训练.

图1 Elman 神经网络结构示意图
误差函数为:
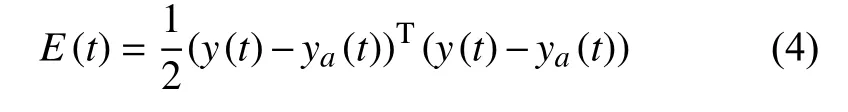
式(4)中,ya(t)是标准实际输出数据,y(t)模型输出数据.
根据误差逆向传播算法,得到:
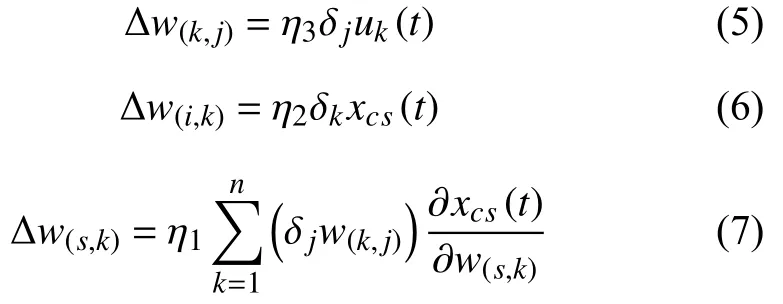
其中,
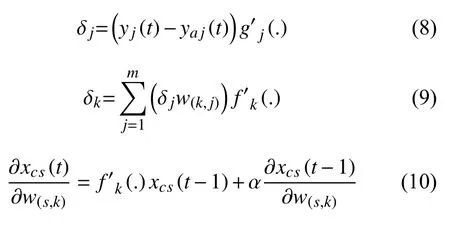
η1,η2,η3分别是w(i,k),w(k,j),w(s,k)的 学习率,δj是输出层神经元的梯度项,δk是隐含层神经元的梯度项[10].xcs是承接层第s维输出,uk是隐含层第k维输出.yj(t)是第j个结点第t轮的输出值,yaj(t)是第t轮 第j个结点的标准输出值.g′j(.)是输出层的导数,f′k(.)是隐含层的导数,0 ≤α <1.
学习算法伪代码如算法1 所示.

算法1.学习算法.训练集D={(xt,yt)}1.初始化Elman 神经网络中所有连接权重和阈值.(xt,yt)∈D2.for all do 3.根据式(1)~式(3)计算每一层的输出值;4.根据式(8)计算输出层神经元梯度项;5.根据式(9)计算隐含层神经元梯度项;6.根据式(5)~式(7)更新权值;7.if(达到停止条件)8.break;9.end if 10.end for
2 实验分析
本文数据集来源为空气质量数值模式CMAQ 和CAMx 输出的辽宁省沈阳市6 项常规污染物(包括PM2.5、PM10、SO2、CO、NO2、O3)的浓度结果,以及在中国空气质量在线监测分析平台所下载的6 项常规污染物的实测数据.本文中的数据集的大小为2019年1月到2019年6月共181 天,起报时刻为20 时,预报时长为未来4 天的6 项常规污染物24 小时平均浓度数据,其中选取30 条数据用作测试数据来评价模型的效果,剩余数据用于训练模型.
2.1 数据预处理
空气质量模式受气象数据,地理数据,以及污染源清单数据等输入文件的影响,会出现数据缺测情况,首先要去除缺测值,减少缺测数据对模型训练的影响.
为了减少不同量纲对后续数据分析和模型训练造成影响,需要先采用Min-Max 线性归一化方法对数据进行归一化处理,将原数据映射到(0,1)之间,公式如式(11)所示:
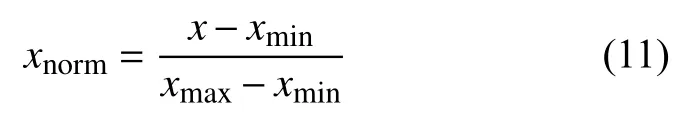
其中,xnorm表示归一化后的数据,x表示原数据,xmin表示的是数据集中的最小值,xmax表示的是数据集中的最大值.
2.2 实验过程
实验过程如图2所示,首先运行空气质量模式CMAQ 和CAMx,对得到的空气质量模式预测结果去除缺测数据处理,然后将空气质量模式预测结果和实测数据进行归一化处理,处理后的数据作为Elman 神经网络的输入,初始化各层结点的权值,进行训练.
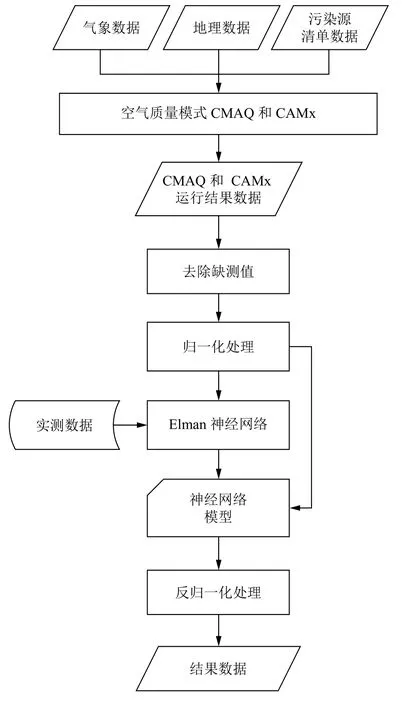
图2 实验流程图
由于本算法需要结合CMAQ 和CAMx 两个模型优化预测值,所以把输入层节点数设置为2,输出层节点数设置为1,经过敏感性实验得到隐含层节点数设置为10 时效果最佳;输出层激活函数设置为输入和输出相等的Purelin 函数;隐含层激活函数设置为Sigmoid函数,其公式如下所示:

当训练误差达到最小(0.01)或达到最大训练轮数(10 000)停止训练.将测试数据输入到训练好的模型中,得到模型输出结果,对模型输出结果进行反归一化处理,得到Elman 神经网络模型优化的CMAQ 和CAMx预测结果.
2.3 评价指标
本文使用均方根误差(RMSE),平均绝对误差(MAD),和平均绝对百分比误差(MAPE),来定量分析模型结果的精度[11-14].3 个评价指标公式如下:
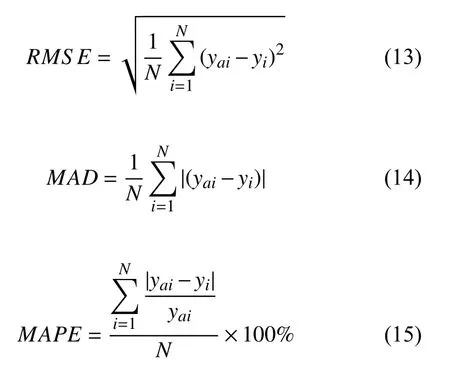
其中,yi是预测值,yai是实测值.均方根误差(RMSE)是预测值与实测值误差的平方和与实验次数N比值的平方根,它能反应出预测值和实测值的偏差大小以及预测结果的稳定程度.平均绝对误差(MAD)是预测值和实测值的绝对误差和与实验次数N的比值.平均绝对百分比误差(MAPE)能反应模型的优劣程度,是相对误差的和与试验次数的比值.
2.4 结果分析
图3是对比实验结果图,横坐标表示时间序列,纵坐标表示污染物浓度,从图3中可以看到,CMAQ 和CAMx 两个单一数值模式的SO2和PM2.5预测结果偏高,NO2预测峰值时结果偏高,PM10和CO 预测趋势和实测值大致相同,个别地方相差较大;而经过Elman神经网络优化的预测结果与单一模式相比较更为接近实际值.
空气质量模式CMAQ,CAMx 和基于Elman 神经网络集成后结果的评价指标对比情况,如表1所示.综合表1和图3我们可以看到,就沈阳市的预报结果而言,两种单一模式对于6 项污染物的预测结果都有不同程度的误差.而集成后的6 项污染物预测结果的预测误差有所下降,综合对比3 个评价指标可以看到PM2.5和SO2的MAD和RMSE都有下降,MAPE有大幅度下降,其中PM2.5的MAPE下降了50%-88%,SO2的MAPE下降了110%-209%;而PM10,CO,NO2和O3的MAD和RMSE有小幅度下降或持平,MAPE都有所下降.总体来说,基于Elman 神经网络优化两种单一空气质量模式的结果相比于单一空气质量模式的预测精度和稳定性有所提高.

图3 实验结果图
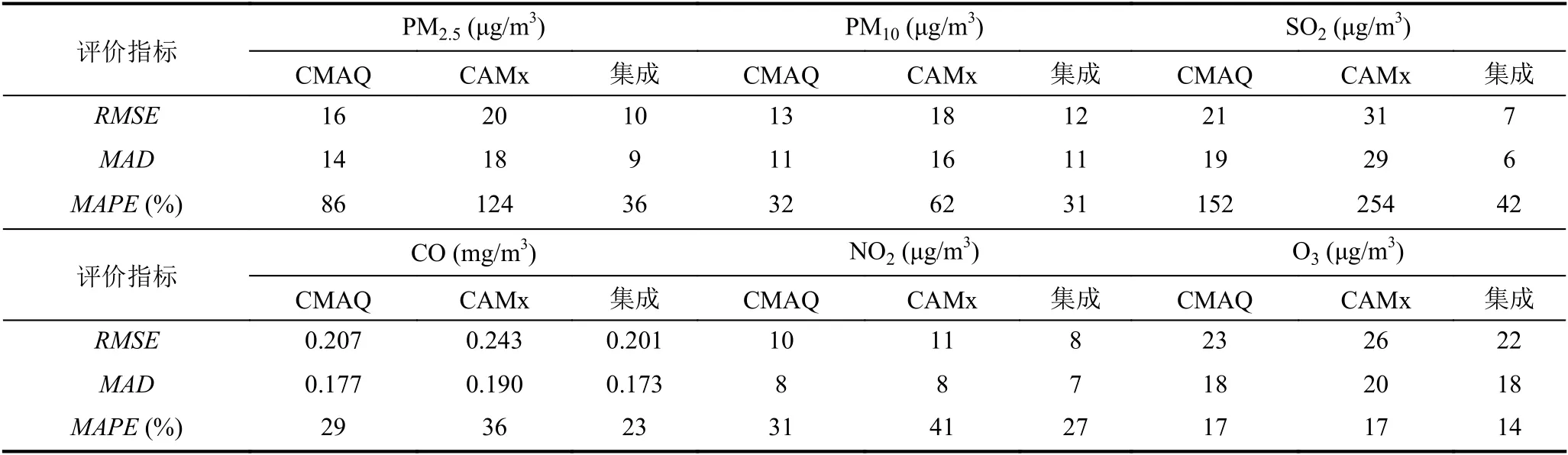
表1 实验结果对比
3 结论
本文针对空气质量预测提出了在CMAQ 和CAMx两个空气质量数值模型基础上,通过Elman 神经网络集成两个数值模式结果的方法.实验结果表明,本文提出的方法结合了两种模型的优势,提高了预测精度和稳定性,降低了单一空气质量数值模式的预测误差,从而能够为后续空气质量预报以及空气质量控制提供数值依据.
猜你喜欢
今日农业(2021年11期)2021-11-27 10:47:17
环境科学研究(2021年6期)2021-06-23 02:39:54
环境科学研究(2021年4期)2021-04-25 02:42:02
少儿科学周刊·儿童版(2021年23期)2021-03-24 01:00:31
电子制作(2019年19期)2019-11-23 08:42:00
环境保护与循环经济(2017年3期)2017-03-03 20:08:30
汽车与安全(2016年5期)2016-12-01 05:22:14
汽车与安全(2016年5期)2016-12-01 05:22:13
中国环境监察(2016年11期)2016-10-24 05:25:12
重型机械(2016年1期)2016-03-01 03:42:04
