
基于改进权值更新和选择性集成的AdaBoost算法
2020-06-19 08:45欧阳潇琴王秋华
软件导刊 2020年4期
关键词:入侵检测
欧阳潇琴 王秋华


摘 要:针对传统AdaBoost算法中样本权值更新缺陷造成的分类准确率降低,以及冗余弱分类器造成的分类速度慢、计算开销大等问题,提出一种基于改进权值更新和选择性集成的AdaBoost算法。首先,在弱分类器训练阶段,提出一种改进权值更新方式的AdaBoost算法,根据各个样本在前t次训练中的平均正确率更新样本权值,使所有样本的权值更新更均衡,在一定程度上抑制了噪声样本权值的无限扩大;其次,在弱分类器组合阶段,提出一种新的弱分类器相似度度量方式,并基于该度量方式和层次聚类算法进行选择性集成,剔除了冗余的弱分类器,提高了分类速度,减少了计算开销;最后使用KDDCUP99、waveform和image-segmentation三个数据集对所提方案进行性能仿真与验证,分类准确率分别达到99.51%、86.07%和94.45%。实验表明,将改进权值更新和选择性集成的AdaBoost算法应用于入侵检测系统,不仅提高了分类准确率和检测速度,而且降低了计算开销。
关键词:入侵检测;集成学习;AdaBoost;权值更新;选择性集成
DOI: 10. 11907/rjdk.191736
开放科学(资源服务)标识码(OSID):
中图分类号:TP312
文献标识码:A
文章编号:1672-7800( 2020)004-0257-06
0 引言
入侵检测可从网络系统若干关键点收集信息,并分析网络是否存在入侵行为及迹象[1,2]。入侵检测可看作一个数据分类过程,从收集的信息中识别出正常操作和入侵行为。当前,入侵检测分类算法主要有决策树[3]、神经网络[4]和支持向量机[5]等。上述分类器均为单个分类器,泛化能力不足,分类准确率不高。因此,集成学习方法[6]被引入。集成学习是一种通过构建多个弱分类器(单个分类器),再将其组合成一个强分类器的学习方法。集成学习方法充分利用单个弱分类器之间的互补性,有效提升了分类器的泛化能力。
集成学习方法分为Bagging[7]和Boosting[8]两大类。Bagging方法通过对训练样本进行有放回的随机抽样得到不同的样本集,从而构建一组具有差异的弱分类器,最后通过平均投票法确定待测样本类别。随机森林( RandomForest)[9]是改进版的Bagging集成方法。Random Forest使用决策树作为弱学习器,每个决策树随机选择样本的一部分特征,并从中选择一个最优特征作为决策树的左右子树,进一步增强了模型的泛化能力。B oosting方法先通过初始训练集训练出一个弱分类器,再根据该分类器的表现对训练样本分布进行调整,使得先前弱分类器分错的训练样本在后续受到更多关注;然后基于调整后的样本分布训练下一个弱分类器;最终将所有弱分类器进行加权组合,每个弱分类器的权重依赖于自身分类误差。在B oosting方法中,最著名的是AdaBoost算法[10](Adaptive Boosting:自适应提升),它是目前最具实用价值的集成学习算法,其本质是通过改变样本分布实现弱分类器训练。它根据每次训练集中每个样本的分类是否正确,以及上一次的总体分类准确率更新每个样本的权值。将修改过权值的训练集送给下层分类器进行训练,最后将每次训练得到的分类器组合成强分类器。虽然AdaBoost算法在一定程度上提高了分类器的泛化能力,其仍存在以下不足:
(1)该算法的权值更新机制容易造成不公平的权值分配,且容易导致噪声样本权值的无限增大。不少学者针对该缺点对算法进行了改进[11-14]。文献[11]提出一种分级结构的AdaBoost算法,通过增大权重变化量、寻找最优分类器等方法,提高分类准确率与分类速度;文献[12]提出一种基于噪声检测的AdaBoost改进算法,根据错分样本中噪声样本与普通错分样本的差异性确定噪声样本,并重新对其分类,从而提高了分类准确率;李文辉等[13]通过调整加权误差分布限制目标类样本权值的扩张,并且以概率值输出代替传统的离散值输出作为强分类器的输出结果;董超等[14]根据样本分类正确率提高其权值,同时抑制噪声样本权值的无限增大。
(2)弱分类器训练过程带有一定随机性,容易导致冗余弱分类器产生。此类弱分类器不仅不能提高分类准确率,还会增加计算开销,降低分类速度。周志华[15]提出的“Many could be better than all”理论证明,使用较少的弱分类器组合而成的强分类器也可以达到相同甚至更优的效果。基于该理论,选择性集成方法[16-17]被提出,该方法在集成学习的基础上增加了一个分类器选择阶段。在该阶段,通过某种策略剔除那些对集成分类器分类能力具有负面影响的弱分类器,将剩下的弱分类器组合成强分類器,从而进一步提高分类性能;谢元澄等[18]通过删除弱分类器中性能差的分类器进行选择性集成;王忠民等[19]通过计算弱分类器的双误差异性增量值并结合近邻传播聚类算法,将T个弱分类器分成K个簇,选取每簇的中心分类器组合成强分类器。
为解决AdaBoost算法存在的上述问题,本文提出一种基于改进权值更新和选择性集成的AdaBoost算法,该算法分别在弱分类器训练阶段和弱分类器组合阶段进行改进。
在弱分类器训练阶段,针对AdaBoost算法仅依靠前一次分类情况决定样本的权值变化太过片面,并且容易导致噪声样本权值无限扩大的缺点,提出一种改进权值更新方式的AdaBoost算法。改进更新方式根据各个样本在前t次训练中的加权平均正确率更新样本权值,所有样本都在前t次训练的基础上提升其权值。前t次的分类正确率越高,权值提升越小。最后再对提升后的权值归一化,在一定程度上抑制了噪声样本权值的无限扩大,令所有样本的权值更新更均衡。
在弱分类器组合阶段,针对弱分类器冗余导致的分类速度慢、计算开销大等问题,提出一种新的弱分类器相似度度量方式,并基于该相似度度量方式和层次聚类算法[20-21]进行选择性集成,将相似度超过阈值的弱分类器归入一类,取分类准确率最高的弱分类器组合成强分类器,从而剔除冗余的弱分类器,提高分类速度,减少计算开销。
基于KDDCUP99、wavetorm和image-segmentation三个数据集对所提方案进行性能仿真与验证,实验结果表明,改进权值更新方式的AdaBoost算法提高了分类准确率。选择性集成不仅剔除了冗余的弱分类器,并且能够保持相同甚至更高的分类准确率。
1 AdaBoost算法及分析
1.1 AdaBoost算法
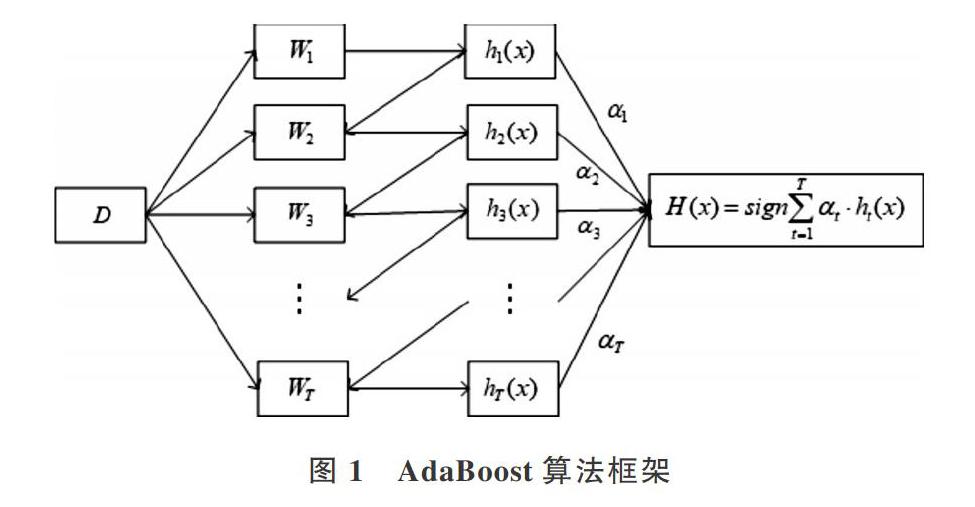
AdaBoost算法是一种将多个弱分类器组合成一个强分类器的迭代算法,通过T次迭代训练出T个弱分类器,算法框架如图1所示。
算法流程如下:①在第t次迭代时,根据此次样本权值分布Wt,从初始训练集D中随机抽取N个样本作为此次训练样本集Dt,并根据Dt训练得到第t个弱分类器h.;②使用h.预测D中的每个样本,得到ht的分类准确率。根据该准确率计算ht的权重ac,,准确率越高,权重越大;③根据步骤②的分类结果对Wt进行更新,提升错误分类样本的权值,降低正确分类样本的权值,使得错分样本在下一次迭代中被选中的概率更大;④将训练得到的弱分类器组合成一个强分类器H,弱分类器的加权投票结果作为强分类器的输出。
1.2 AdaBoost算法分析
AdaBoost算法通过训练多个弱分类器对待分类样本进行分类,并投票决定样本类别,利用弱分类器之间的互补性提高强分类器的分类精度。相比于单个分类器,在一定程度上提高了分类准确率,但其缺点也很明显。
(1)样本权值更新时对所有正确(或错误)分类的样本同等看待,并且仅凭第t次训练结果决定一个样本在下一次迭代中的权值太过片面。例如,在前t-1次训练中,样本xp被多次分错,而样本xq被多次分对,但在第t次训练中二者都分类错误。那么,令xp和xq的权值有同样变化是不公平的,而应令xp的权值比xq有更大提升,使其在第t+1次训练中更容易被选中。除此之外,一味降低分对样本的权值、提升分错样本的权值,容易导致噪声样本权值无限增大,从而使非噪声样本被选中的概率降低,最终分类准确率也可能随之降低。
(2)由于弱分类器训练阶段采用有概率的随机抽样方法选取训练样本,有可能使得两次训练抽取到的训练集十分相似,从而得到两个差异性很小的弱分类器。这些冗余的弱分类器不仅对分类性能没有帮助,反而会降低分类速度,增加计算开销。
2 AdaBoost算法改进
针对AdaBoost算法缺点,本文提出一种基于改进权值更新和选择性集成的AdaBoost算法,该算法分为弱分类器训练和弱分类器组合两个阶段。
该方法不需要预先设置K值,并且保证最后得到的K个类中任意两个类之间的相似度小于或等于δ,每个类内的任意两个弱分类器相似度大于δ。剔除冗余的弱分类器,保留相互之间差异性较大的弱分类器,既提高了分类速度,又保证了较高的准确率。
3 性能仿真与分析
3.1 实验数据集
本文使用3个数据集对所提算法进行性能仿真,分别是KDDCUP1999、wavetorm和image-segmentation,如表1所示。KDDCUP1999是一个入侵检测数据集,包含Nor-mal、DoS、Probe、U2L和R2L五个类别标签;wavetorm是一个声音波形数据集,包含3个类别标签:0、1和2;im -age-segmentation是一个图像识别数据集,包含7个类别标签:CRASS、CEMENT、WINDOW、PATH、SKY、FOLIAGE、BRICKFACE。
实验中将每个数据集的70%划分为训练集,30%划分为测试集,取10次实验结果的平均值作为最终结果。采用分类准确率衡量分类效果,其计算方式为分类正确的样本数与样本总数的比例。另外,分类效率的衡量标准为最终用来组合成强分类器的弱分类器数目,弱分类器越少,效率越高,反之越低。
3.2 分类准确率
首先对传统的AdaBoost算法权值更新方式进行改进。为了验证改进权值更新后的AdaBoost算法分类效果,在KDDCUP1999、wavef orm、image-segmentation三个数据集上进行实验,并与传统AdaBoost算法和文献[14]所提改进AdaBoost算法进行对比,对比结果如图2、图3和图4所示。
从图2、图3和图4可以看出,文献[14]所提算法虽然提高了部分类别的分类准确率,但对U2R类别的样本分类准确率明显偏低,而本文所提算法在各个样本类别的分类准确率都优于传统AdaBoost算法和文献[14]的算法。
3.3 不同弱分类器数目对分类准确率的影响
在集成学习方法中,弱分类器数目T与最终强分类器性能有直接关系。为了验证T对分类效果的影响,本文基于KDDCUP99、Image-Segmentation和Waveform三個数据集进行实验。对于每个数据集,分别令T=1、2、4、7、11、16、22、29、37、46、56、67,进行12组实验,结果如图5所示。
从图5可以看出,对于KDDCUP99数据集,当T<30时,分类准确率随T的增大而提高,T=29时,分类准确率最高,达到99.51%;而当T>30时,分类准确率不再随着T的增大而继续增加,而是稳定在99.4%左右;对于image-seg-mentation数据集,当T从1增大到16时,其分类准确率不断上升,从86.62%提高到94.62%。当T>16之后,准确率不再随着T的增大而提高,而是稳定在94.45%左右;对于wavetorm数据集,当T从1增大到37时,其分类准确率不断上升,从74.74%上升至86.07%,T>37之后,准确率稳定在86%左右。
上述结果表明,虽然集成学习方法都是通过训练多个弱分类器来提高强分类器的泛化能力,但不表示弱分类器越多效果越好。当弱分类器超过一定数目时,准确率将不再继续提升,甚至有可能下降,这也表示在弱分类器训练过程中极有可能产生冗余分类器,这些冗余弱分类器不仅不能令强分类器性能得到提升,反而会使强分类器性能下降,进而影响分类速度。因此,选择性集成是有必要的。
3.4 基于层次聚类的选择性集成效果分析
为验证本文提出的基于层次聚类的选择性集成方法,分别对3个数据集在T=10、20、30、40、50、60、70的情况下进行实验。
表2、表3和表4分别显示了KDDCUP99、Image-Seg-mentation和Waveform三个数据集在选择性集成前后的分类效果对比。从表中可以看出,由不同数目弱分类器组合成的强分类器,在经过选择性集成后都可以减少弱分类器数目,达到相同甚至更优的分类性能。例如,对于KDD-CUP99数据集,在T=10的条件下,选择性集成前分类准确率为99.25%,而δ=0.85和δ=0.9条件下的选择性集成分别将弱分类器数目减至7个和8个,分类准确率分别达到了99.26%和99.32%;對于Image-Segmentation数据集,在T=20的条件下,选择性集成前分类准确率为93.38%,而在δ =0.8、0.85和0.9的条件下,选择性集成可以将弱分类器数目减至12、14和16个,分类准确率分别达到93 .42%、93.90%和93.38%;对于Waveform数据集,在T=60的条件下,选择性集成前分类准确率为86.4%,而在δ= 0.9的条件下,选择性集成可以将弱分类器数目减至43个,达到86.6%的准确率。以上数据表明,本文提出的基于层次聚类的选择性集成方法可以在保证准确率的前提下,选取尽可能少的弱分类器组合成强分类器,从而提升分类效率。
此外,不同δ值得到的选择性集成结果也不同,δ越大得到的弱分类器越多。由于选择性集成既要剔除冗余的弱分类器,又要保留差异性较大的弱分类器,即在使用尽可能少的弱分类器同时要达到最为理想的分类性能,因此δ的选取尤为重要。若δ值过大,可能导致存在冗余的弱分类器没有被剔除;若δ过小,则会导致过多弱分类器被剔除,使得剩余的弱分类器之间互补性不足,达不到最优性能。如表3所示,在T=30的条件下,选择性集成前的分类准确率为94.19%;当δ=0.8时,选择性集成后得到的弱分类器数目为17,准确率为93.76%,小于94.19%;当δ=0.85时,选择性集成后得到的弱分类器数目为20,准确率为94.48%,大于94.19%;而当δ=0.9时,选择性集成后得到的弱分类器数目为23,准确率为94.33%,小于94.48%。因此,本实验中,δ =0.85时分类性能达到最优。
3.5 不同集成方法分类效果对比
本文同时基于上述3个数据集使用其它集成学习方法Bagging、AdaBoost和Random Forest进行分类实验,实验中所使用的弱分类器数目T=30,本文所提方案中令δ= 0.85,各方案分类结果如表5所示。通过表中数据对比可知,本文所提方法在分类准确率上略优于其它3种集成学习方法。但本文方案经过选择性集成后将弱分类器数目减少至23个,提高了强分类器的分类效率,减少了计算开销。因此,本文所提方案在准确率和效率上都优于Bag-glng、AdaBoost和Random Forest。
4 结语
为提高AdaBoost算法的分类准确率和效率,本文首先提出改进样本权值更新方式的AdaBoost算法,在一定程度上提高了分类准确率;其次,利用基于层次聚类和相似度的选择性集成方法对弱分类器进行筛选,得到一个弱分类器子集,并组合成强分类器。与其它集成学习方法相比,本文所提方法不仅提高了分类速度,而且保证了相同甚至更高的分类准确率。然而,与其它集成方法一样,弱分类器训练阶段的耗时问题仍然存在。另外,本文在参数选取方面,只能通过多次实验得出最佳参数。因此,提升弱分类器训练阶段效率、优化参数选取方式是今后的研究重点。
参考文献
[1]BUCZAK A L, GUVEN E. A survey of data mining and machine learn-ing methods for cyber security intrusion detection[J] . IEEE Communi-cations Survevs & Tutorials . 2017. 18( 2) : 1153-1176.
[2]OZA N C.Online ensemble learning[C].Seventeenth National Confer-ence on Artificial Intelligence and Twelfth Conference on InnovativeApplications of Artificial Intelligence, July 30- August 3,2000,Austin, Texas, Usa. DBLP, 2000: 1109.
[3]JIANG F,SUI Y,CAO C.An incremental decision tree algorithmhased on rough sets and its application in intrusion detection[J].Arti-ficial Intelligence Review, 2013, 40(4):517-530.
[4]SIMON H. Neural network:a comprehensive foundation [M]. NeuralNetworks:A Comprehensive Foundation. Prentice Hall PTR, 1994:71-80.
[5]YANG Q, FU H, ZHU T.An optimization method for parameters ofsvm in network intrusion detection system [C]. International Confer-ence on Distributed Computing in Sensor Systems. IEEE, 2016:136-142.
[6]WANG Y. SHEN Y, ZHANC G.Research on intrusion detection mod-el using ensemble learning methods[C] In IEEE International Con-ference on Soft,vare Engineering and Service Science, 2017: 422-425.
[7]BREIMAN L Bagging predictors [J]. Machine Learning, 1996, 24( 2):123-140.
[8]SCHAPIRE R, FREUND Y.Boosting: foundations and algorithms[J].Kvbernetes, 2012, 42(1):164 -166.
[9]BIAU G,SCORNET E.A random forest guided tour[Jl. Test, 2016,25(2):1-31.
[10] 曹瑩,苗启广,刘家辰,等.AdaBoost算法研究进展与展望[J].自动化学报,2013,39(6):745-758.
[11] 杨晓元,胡志鹏,魏立线.分级结构Adaboost算法在无线传感器网络入侵检测中的应用研究[J].传感技术学报,2012. 25(8):1159-1165.
[12]张子祥,陈优广.基于样本噪声检测的AdaBoost算法改进[J].计算机系统应用,2017( 12):186-190.
[13] 李文辉,倪洪印,一种改进的Adaboost训练算法[J].吉林大学学报(理学版),2011(3):498-504.
[14]董超,周刚,刘玉娇,等.基于改进的Adaboost算法在网络入侵检测中的应用[J].四川大学学报(自然科学版),2015, 52(6):568-574.
[15]ZHOU Z H, WU J,TANG W. Ensembling neural net,vorks: manvcould be better than all[C].Artificial Intelligence, 2002.
[16] 张春霞,张讲社.选择性集成学习算法综述[J]计算机学报,2011. 34(8):1399-1410.
[17]CHEN T.A selective ensemble classification method on microarravdata[J].Journal of Chemical& Pharmaceutical Research, 2014(9):851-859.
[18]谢元澄,杨静宇.删除最差基学习器来层次修剪Bagging集成[J].计算机研究与发展,2009,46(2):261-267.
[19] 王忠民,张爽,贺炎.基于差异性聚类的选择性集成人体行为识别模型[J].计算机科学,2018. 45(1):307-312.
[20]ZHAO Y. KARYPIS G,FAYYAD U.Hierarchical clustering algo-rithms for document datasets[J].Data Mining& Knowledge Discov-ery, 2005, 10(2): 141-168.
[21]惠飞,彭娜,景首才,等.基于凝聚层次的驾驶行为聚类与异常检测方法[J].计算机工程,2018 .44(12):196-201.
(责任编辑:杜能钢)
基金项目:浙江省自然科学基金项目( IY19F020039);之江实验室重大科研项目(2019DHOZXOI)
作者简介:欧阳潇琴(1993-),女,杭州电子科技大学通信工程学院硕士研究生,研究方向为传感器网络安全、计算机网络安全;王秋华(1978-),女,博士,杭州电子科技大学网络空间安全学院副教授,研究方向为传感器网络安全、计算机网络安全、安全密钥管理。
