
基于有监督学习的店铺类虚假评论检测
2020-06-19 08:45王琢汪浩胡润龙高飒
软件导刊 2020年4期
王琢 汪浩 胡润龙 高飒


摘要:网络在线评论对于商家和顾客具有重要价值,因而日益受到虚假评论行为的冲击。作为两个重要的在线评论领域,产品类评论(如亚马逊、淘宝)和店铺类评论(如点评网、Yelp)在语言特性、评论行为等方面存在显著差异。虽然研究者们已提出大量针对产品类虚假评论的检测方法,但对于店铺类虚假评论的研究仍然较少。针对Yelp.com网站上旅店、饭店有标注的点评数据,提取并分析各种评论欺诈特征,利用多种有监督学习方法进行虚假评论检测。实验结果表明,检测精度最高可达74%,AUC值可达75%。虽然店铺类虚假评论具有极强的隐蔽性,但通过权衡检测精度和召回率,可利用有监督学习方法对店铺类虚假评论进行有效检测。
关键词:网络在线评论;虚假评论;店铺类评论;有监督学习
DOI: 10. 11907/rjdk.191695
开放科学(资源服务)标识码(OSID):
中图分类号:TP306
文献标识码:A
文章编号:1672-7800(2020)004-0071-04
Store Fake Review Detection Based on Supervised Learning
WANG Zhuo.WANG Hao . HU Run-long, GAO Pei
(School of Information Scierzce and Engineering , rShenyang Ligong Univer.sity,SHenyang110159 . Ch ina )Abstract: Due to the iruportance for both the merchants and customers. online reviews are increasingly under the attack of' f'ake re-views. As the two main review domains , product reviews (e.g. Amazon,Taobao) and store reviews (e.g. Dianping.com, Yelp.com) sig-nificantly dif'ferentiate f'rom each other in linguistics and behaviors. While product fake review detection attracts much research inter-ests. store fake review detection has got less attention. In this paper, we focus on store fake review detection problem by exploiting thelabeled datasets containing hotel and restaurant reviews from Yelp.com. Specifically , we extract and analyse a number of review spamfeatures. with which we use supervised machine learning approaches to detect fake reviews. Experiruents suggest that the ruaximum pre-cision and AUC can reach 74% and 75% , respectively. Although the f'ake reviews f'rom Yelp.com are very deceptive, supervised learn-ing methods are effective in detecting fake store reviews by trading of'f detection precision and recall.Key Words : online review;fake review ; store review;supervised learning
O 引言
随着Web2.0技术的发展,电子商务也发展迅速。网络评论在网络购物中发挥着重要作用,顾客已习惯于在购物前首先查看相关评论,因此好评或差评都将在很大程度上影响顾客的购买选择。网络评论不仅受到消费者重视,商家也极为重视,因此会千方百计提高白身产品或服务的好评度。然而,有些不法商家或个人受利益驱使,故意书写虚假评论,以美化白身或贬低竞争对手[1]。据统计,产品评分每增加1分,商家可以增加约5.4%的收益[2]。
Jindal等[3]首先提出虚假评论检测问题,并针对亚马逊(Amazon.com)评论提取大量评论特征,然后使用朴素贝叶斯、逻辑回归等机器学习算法对评论进行“虚假/真实”分类。其研究发现,虚假评论检测的困难性在于难以获取大量标注数据集用于分类器学习,而只能利用一些重复或接近重复的评论文本作为虚假评论,并选取非重复评论作为真实评论,训练多种分类器。但随着网络评论重要性的不断提高,评论作弊行为也越来越隐蔽,单纯依赖评论文本已无法识别虚假评论。因此,国内外学者义提出基于评论文本3-7]、评论人之间关系[8-10]以及评论行为[11-14]的虚假评论检测方法。
然而,网络评论具有强烈的领域相关性,不同的评论领域(如图书评论、饭店评论等)不仅评论文本有很大区别(如使用的词汇、主题、文体、情感、习惯等),甚至评论行为(如打分、评论频率)也有很大不同。因此,针对不同领域的虚假评论,必须使用不同检测方法,才能有效提高检测性能。本文将网络评论分为针对产品的评论(product re-views)、针对店铺的评论(store reviews)与服务类评论(ser-vice reviews)。除在评论文本和评论行为方面的差别外,产品评论和店铺评论还有一个重要区别是店铺数量一般远远少于产品数量,造成针对店铺的评论数量大、评论顾客多。目前针对店铺类虚假评论检测的方法[8]较少,大部分检测方法未对二者进行区分,缺乏针对性。因此,如何针对店铺类虚假评论特点设计有效的檢测方法是一个重要研究课题。
本文首先利用有標注的Yelp数据集抽取店铺类评论的作弊特征,然后利用决策树、朴素贝叶斯、K近邻、集成学习等机器学习算法,对店铺类虚假评论进行检测,揭示店铺类虚假评论特征,比较不同机器学习算法的分类性能,为进一步深入理解J占铺类虚假评论的特征模式、设计更为有效的检测手段打下基础。
1 Yelp评论数据集介绍
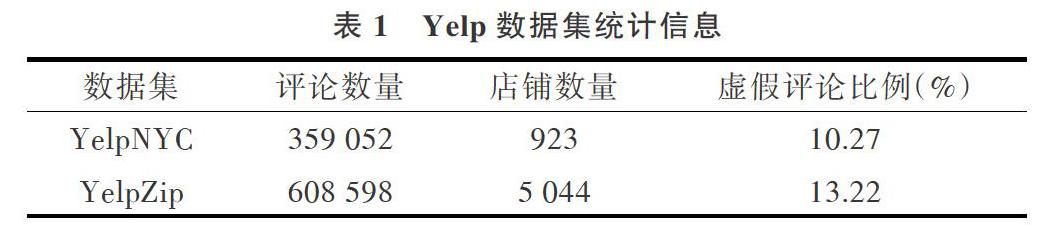
Yelp( www.yelp.com)是美国一个大型网络评论社区,成立于2004年,主要目的是为人们提供当地商业活动的点评服务,内容涉及饭店、购物、家政、夜生活、美容等。由于商业竞争的加剧,Yelp受到大量虚假评论的困扰,因此该网站设置了虚假评论过滤器,利用多种算法发现可疑虚假评论。Mukherjee等[11]首先利用Yelp的虚假评论过滤器构造一个虚假评论标注数据集(YelpChi),之后Ravana等[15]义构造了YelpNYC与YelpZip标注数据集。其中YelpChi是美国芝加哥地区的饭店、旅店评论,YelpNYC为美国纽约市饭店和旅店评论,YelpZip是美国多个州邮编连续区域的饭店、旅店评论。由于虚假评论标注的困难性,这些标注数据集被认为是接近准确的(nearground-truth)。3个数据集都包含了旅店、饭店评论,本文利用YelpNYC和YelpZip对店铺类评论的虚假性进行检测,具体统计信息见表l。
2店铺类评论特征提取
为实现对虚假评论与真实评论的准确分类,从评论数据中提取有效评论作弊特征是其中的关键。通过对Yelp标注数据集进行探索性数据分析,本文设计了一系列文本特征和行为特征,以提高分类的准确性和召回率。令评论v= ,其中v.r表示评论v的作者,v.p表示评论v所评论的店铺或服务,v.为评论v的打分,v.t表示评论v的评论时间(日期)。文献[11]指出词频特征(unlgram或higram)对于Yelp虚假评论区分度较低,故本研究不采用词频特征。
2.1文本特征
(1 )WorciCou nt:评论文本包含的单词个数。虚假评论者一般没有购买产品就书写评论,加上书写评论会耗费大量时间与精力,所以其评论数量通常比真实消费者包含的单词个数要少。
(2)TextSentiment:虚假评论者为了故意夸大或贬低产品,其评论文本的情感极性通常比较明显[6]。本文利用情感极性计算包TextBloh计算评论文本的情感极性,取值范围为[-1,1]。为使特征具有单调性,本文取其绝对值作为该评论的情感极性特征。
2.2行为特征
( l)RatingDev:为了提升自身信誉或贬低竞争对手声誉,虚假评论打分值一般与真实评论的打分具有显著偏差[11.16]。该特征计算公式为:
即评论v的特征是该评论打分与同一产品其它评论打分的均值之差。
(2) ExtremeRate:评论作者所写评论中极端打分所占比例。真实用户一般根据对J占铺的满意度进行打分,分数不尽相同。但虚假评论者往往书写极力提升或贬低的评论。该特征可表示为:
(3) UserReviews:评论作者累计书写的评论数。评论欺诈者往往只参加一次欺诈活动,其评论数量一般较少。将此评论人特征作为为该评论特征。
(4)TimeSpan:评论作者活跃时间。一般作弊评论者账户活跃度差,而真实用户会不时地书写评论。本特征的计算可表示为:
其中VT、V.分别表示v.r的最后一次评论日期和第一次评论日期。
(5)Rank:为了使评论影响极大化,虚假评论往往抢先发布,其排列位置靠前。本特征取该评论在同一店铺内的排列次序。
(6)KernelDen:在群体评论欺诈中,存在多个欺诈者同时对一个店铺进行爆发型评论,导致短期内评论密度过大的现象。核密度估计可以较好地体现评论密集度[17-18]。为了综合考虑不同店铺的评论总量,本文将该评论的核密度估计值乘以该店铺评论时间跨度作为本特征值。令x1.x2...xn为店铺v.p所有评论的评论日期序列,共有n条评论,则日期x对应核密度可表示为:
其中h为邻域宽度,一般取1,K(-)为核函数,可以取高斯核,则有: 于是有:
(7)TBurst:类似于KerneIDen特征,对一个占铺而言,如果一条评论在相近时间内存在多条评论,则该评论有较大嫌疑。本特征取一条评论的周围k条评论与该评论的平均时间差。本研究中取k=4。
2.3特征标准化
由于不同特征的取值范围及其分布有显著差异,不同特征之间难以相互比较,故采用文献[15]提出的方法,按特征值进行排序,以其排列序号占总体评论数的比值作为其特征标准化值,从而使所有特征取值范围均归一化到[O,1]。进一步地,对于取值越小、越可疑的特征F,令F=1-F,从而使特征更趋近于1。
2.4特征有效性分析
通过比较每个特征中真实评论和虚假评论的累计分布函数( Cumulative Distribution Function,CDF)曲线,可以观测到该特征对于分类的区分能力[19。YelpNYC数据集的9个特征对应的CDF比较曲线如图1所示,可见各特征均有一定区分度,其中TimeSpan、UserReviews、ExtremeR -ate、WordCount、TextSentiment区分度明显。RatingDev特征在该数据集中与文献[11]、[16]中的亚马逊数据集不一致,即本数据集中的作弊者打分偏差并不高于真实用户,说明产品评论( Amazon)与店铺评论数据存在不同行为特征。YelpZip与此类似,这里不再赘述。
3 基于有监督学习的虚假评论检测
3.1检测算法
由于不同机器学习算法采用不同的优化策略模型,根据“没有免费午餐定理( No free lunch theorem)”,不同算法适合不同数据集。本文选取sklearn机器学习包中的决策树( DecisionTree)、朴素贝叶斯(GaussianNB)、K近邻(KNeighbors)以及集成学习算法随机森林(RandomFor-est)。LightGBM[20]是最近提出的基于梯度提升决策树的集成学习算法,被证实具有很高的学习效率与很好的分类性能,故本文引入LightGBM算法。
3.2检测结果比较
对整个数据集采用交叉校验法( Cross Validation),随机抽取数据集中80%的数据作为训练集,其余20%作为测试集。机器学习结果见表2、表3,其中每项指标的最优值用黑体显示,可见YelpZip数据集检测性能整体优于YelpNYC。如果侧重检测精度,则LightGBM和Random-Forest占优;如果考虑召回率,则GaussianNB占优。
由于评论数据中虚假评论占少数,属于严重不均衡数据,所以高AUC值往往是第一目标。对于不平衡数据集,下采样(Under-sampling)可以提高分类器性能[5]。将整个数据集的20%作为测试集,从其余80%样本中取出全部虚假评论作为正例,然后从真实评论中随机取出数量相等的评论作为负例,构造训练集训练分类器。其中,每次对测试集和训练集分别采样5次,取其平均值。YelpNYC和YelpZip实验结果见表4、表5。
可见采用下采样时,使用任何机器学习算法均可得到较高的召回率与较低精度,整体AUC值大幅提升。主要由于训练集中虚假/真实评论比值为1:1,而测试数据集中真实评论数量明显偏大,所以分类器倾向于将真实评论分类为虚假评论。总体来看,集成学习算法LGB和Random -Forest的性能较好。显然,通过平衡下采样训练集中正例、负例的比率,可以权衡检测精度和召回率。
4 结语
虽然学者们已提出多种针对产品类虚假评论的检测方法,但对店铺类虚假评论检测的研究仍然较少。本文利用Yelp数据集中的虚假评论标注数据,提取虚假评论的文本特征和行为特征,分别利用交叉校验和下采样法,采用多种机器学习算法对J占铺评论数据进行有监督分类。实验结果表明,Yelp店铺类评论欺诈具有极强的隐蔽性,虚假评论和真实评论特征分布区分度不明显。有监督方法在店铺虚假评论检测中具有一定效果,但需要在召回率和精度之间作出权衡,并提出利用下采样法在虚假评论检测中平衡检测精度和召回率。本研究提出的有监督方法在实际应用中取得了较好效果,也可为下一步设计基于无监督学习的檢测方法提供参考。
参考文献:
[1]陈燕方,娄策群.在线商品虚假评论形成路径研究[J]。现代情报,2015.35(1):49-53.
[2] LLCA M. Reviews, reputation, and revenue: the case of Yelp.Com[EB/OLl. https: //ssrn.com/abstract=1928601.
[3]IhrDAL N,LIL B Opinion spam and analysis[C].International Con-ference nn Weh Search&Data Mining, 2008.
[4]OTT M, CHOI Y,CARDIE C. et al. Finding deceptive opinion spambv aiUT stretch of the imagination[C]. In proc. of ACL:Human Lan-guage Technologies, 2011: 309-319.
[5]llil,QIN B, REN W,et al. Document representation and featurecomhination for deceptive spam review detection[J]. Neurncomput-ing, 2017,254(6):33-41.
[6]任亚峰,尹兰.姬东鸿基于语言结构和情感极性的虚假评论识别[J].计算机科学与探索,2014.8(3):313-320.
[7]张建鑫 .基于聚类与句子加权的欺骗性评论检测[J]软件导刊 , 2019 ,18(2) : 34-37.
[8]WAhrC G, XIE S. LIU B. et al. Review graph based online store re-view spammer detec.tion[C] . Proceedings of ICDM , 201 I : 1 242-1247.
[9]WAhrG Z, HOU T. SONG D. et al. Detecting re,'iew spammer groupsvia hipartite graph projection [Jl. Computer Journal, 2016. 59(6) :861-874.
[10]WANG Z. CU S.ZHAO X. et al. Graph-hased review spammer groupdetection[J]. Knowledge and Information Systems, 2018. 55(3) :571-597.
[ll]MUKHERJEE A. VENKATARAMAN V. LIU B, et al. What yelpfake review filter might he doing:l[C]. Bosmn: Proceedings of IC-WSM , 2013.
[12]LIM E P. NCUYEhr y A. JINDAL N, et al. Detecting product review spammers using rating behaviors [C]. Proceedings of the 19th ACMConference on Information and Knowledge Management. 2010.
[13]孙升芸 .田萱,何军 .基 -T-评 ik行为的商 pOa垃圾评论的识别研究[J].计算机工程与设计 , 2012. 33(11) : 4314-43 19.
[14]LIH. FEI G, SHAO W, et al. Bimodal distrihution and co-hurstingin review spam detection rcl. Internatir,nal Conference on WorldWide Web . 2017.
[15]RAYAhrA S, AKOGLU L. Collectire opinion spam detection: bridg-ing review networks and metadata [c]. Sydney : Proceedings of KDD ,2015.
[16]MUKHERJEE A. KLrMAR A, LIU B, et al. Spotting opinion spam-mers using hehavioral footprint [C].Chicago : Prnceedings of KDD ,2013.
[17]FEI C. MUKHERJEE A, LIU B, et al. Exploiting hurstiness in re-views for reriew spammer detection [C]. 17th AAAI Conference onWehlogs and Social Media. 2013.
[18]wANG Z, cu s. XU X.CSLDA: LDA-hased group spamming de-tection in product reviews [J]. Applied Intelligence, 2018. 48 (9) :3094-3107.
[19]MUKHERJEE A. BINC L. GLAhrCE N. Spotting fake reviewergroups in consumer reviews [c].International Conference on V-orldWide Web . 2012.
[20]KEG, MENG Q, FIhrLEY T, et al. LightCBM: a highly efficientgradient boosting decision tree[C]. Long Beach: Proceedings ofNIPS.2017.
收稿日期:2019-05-13
作者簡介:王琢(1969-),男,硕士,CCF会员,沈阳理工大学信息科学与工程学院副教授,研究方向为机器学习;汪浩(1994-),男,沈阳
理工大学信息科学与工程学院硕士研究生,研究方向为机器学习。
