
融合双向GRU与注意力机制的医疗实体关系识别
2020-06-18 03:42张志昌张瑞芳张敏钰
计算机工程 2020年6期
张志昌,周 侗,张瑞芳,张敏钰
(西北师范大学 计算机科学与工程学院,兰州 730070)
0 概述
电子病历(Electronic Medical Records,EMR)是医务人员使用电子医疗系统产生的文字、符号、图表、图形、数据和影像等数字化信息,并将其进行存储的医疗记录[1]。随着EMR的大量使用,人们对其认识也逐渐完善,它不仅包括患者的一些临床信息,如检查结果、临床诊断以及不良反应等,还包括丰富的医疗实体[2]。如何在非结构化的病历文本中抽取有价值的医疗信息,建立可用于临床决策支持的医疗知识库,成为自然语言处理(Natural Language Processing,NLP)领域的研究热点。实体关系抽取是NLP信息抽取技术中的基本任务,也是构建知识库和知识图谱的关键方法[3]。从EMR文本中挖掘医疗实体以及实体间的语义关系,对于推动EMR在医疗健康服务中的应用具有重要意义。实体关系抽取最早被消息理解会议(Message Understanding Conference,MUC)[4]评测会议引入,直至2010年,I2B2/VA在NLP挑战临床记录中提出关于英文EMR的医疗实体关系抽取[5],使得EMR中的医疗实体关系抽取成为了研究热点。但在中文EMR方面,公开的评测以及研究成果相对较少,已有的关系抽取方法依赖于机器学习算法,且需要构建大量的手工特征。近年来,在不依赖手工特征条件下,神经网络方法在关系抽取任务中取得了较好的性能,但是常见的关系抽取是以句子作为单独的处理单元,没有考虑到EMR语料库中部分语料的实体关系标签标注错误,影响分类效果。
本文提出一种双向门控循环单元(Gated Recurrent Unit,GRU)和双重注意力机制结合的深度学习方法。该方法构建一个双向GRU和双重注意力机制结合的实体关系抽取模型,利用双向GRU学习字的上下文信息,获取更细粒度的特征。通过字级注意力机制提高对关系分类起决定作用的字权重,利用句子级注意力机制学习更多语句的特征,降低噪声句子的权重,以有效解决标签标注错误问题,提高分类器效果。
1 相关研究
目前,大多数关于实体关系抽取的方法是在开放域上进行的,如新闻报道、博客以及维基百科等[6]。在开放域上进行关系抽取研究的最大难点在于语料内容没有固定的结构,早期的实体关系抽取研究是基于有监督学习的方法,如基于特征工程、核函数以及条件随机场[7]的方法。文献[8]在MUC-7评测会议中,对原始数据进行统计并提取特征来进行实体关系抽取,实验过程中取得了较高的F1值。文献[9]利用支持向量机的方法进行关系抽取,这类方法依赖于人工构建手工特征,需要标注大量的训练语料,耗时耗力,且泛化能力差。针对此局限性,文献[10]提出远程监督的思想,通过将文本与大规模知识图谱进行实体对齐,有效解决关系抽取的标注数据规模问题。文献[11]首先使用循环神经网络来解决关系抽取问题,利用句法结构得到句子的向量表示并用于关系分类,但没有考虑到实体在句子中的位置和语义信息。文献[12]利用卷积神经网络进行关系抽取,采用词向量和词位置向量作为输入,通过卷积、池化得到句子表示,使得在关系抽取过程中考虑到句子中的实体信息。文献[13]提出一种基于最短依存路径表示文本的深度学习方法,能够准确地抽取实体关系。
医疗领域的关系抽取与开放域的关系抽取有所不同,EMR是一种半结构化的文本数据,包含大量的专业术语、缩略词等。2010年,I2B2/VA评测引入了英文EMR的信息抽取任务[5],定义了三大类医疗实体关系:1)医疗问题和治疗的关系;2)医疗问题和检查的关系;3)医疗问题和医疗问题的关系。文献[14]使用支持向量机作为分类器,并引入外部字典和丰富的特征提升关系识别精度。文献[15]通过基于规则的方法从中草药相关文章中抽取关系,并用于构建关系数据库。文献[16]从病历中计算疾病和症状的共现程度来抽取两者的关系。文献[17]采用两阶段方法,将长短期记忆(Long Short Term Memory,LSTM)网络和支持向量机相结合,抽取药物之间的影响关系。
2 方法描述
给定一个句子集合S={x1,x2,…,xn},其中xi为句子集合S中的第i个句子。实验模型主要分为句子编码和句子级注意力机制两部分。
2.1 句子编码
句子编码模型如图1所示,将任意给定的一个句子xi={c1,c2,…,cn}通过双向GRU编码处理,字级注意力机制计算产生每个字的权值,并把双向GRU的输出向量表示成一个句子向量。
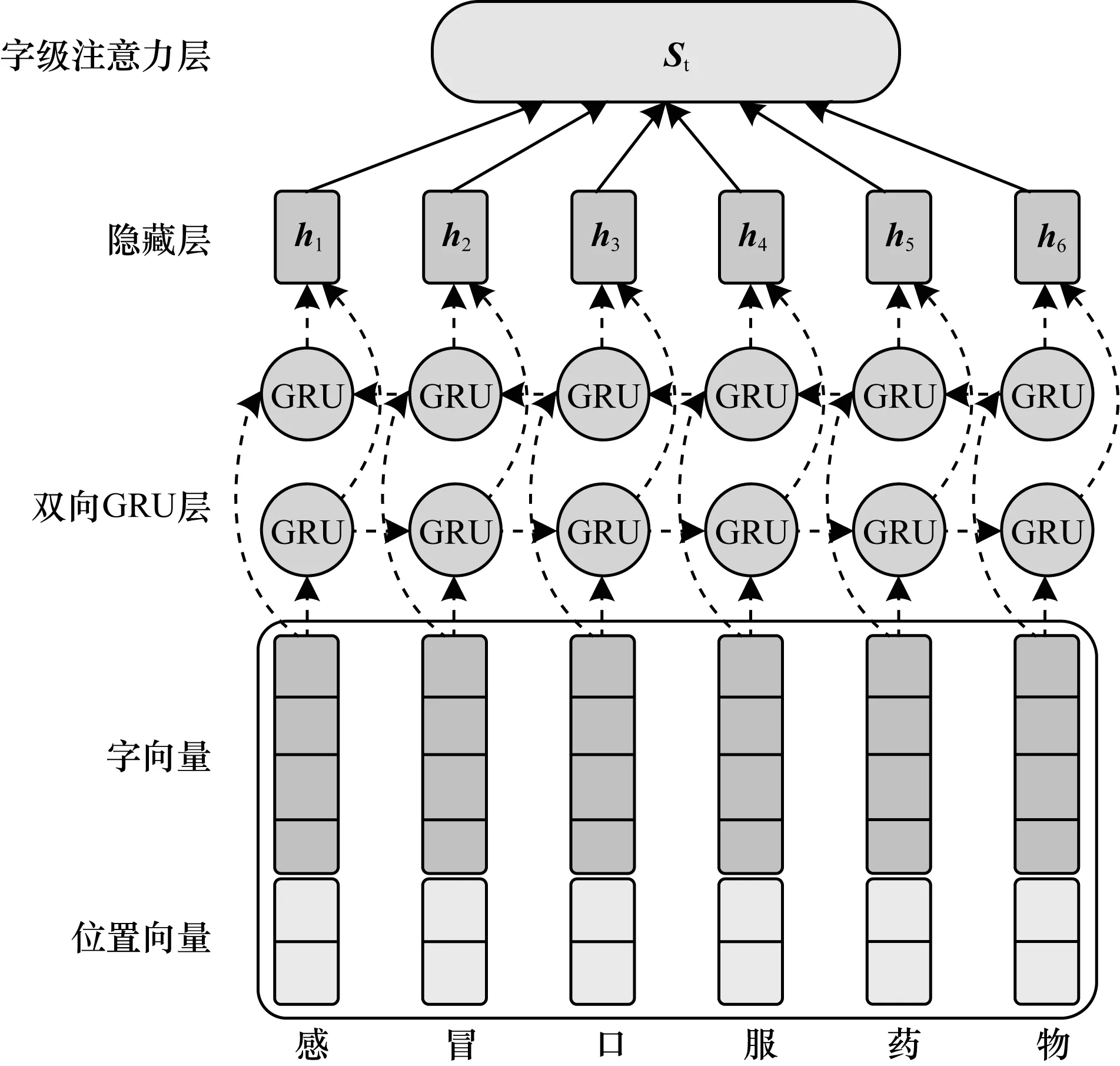
图1 句子编码模型
2.1.1 向量表示
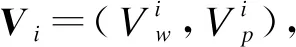
1)字向量表示:字嵌入是将句子中的字映射成一个低维稠密的向量,从而更好地刻画字的属性。给定一个含有n个字的句子xi={c1,c2,…,cn},实验用word2vec工具训练生成字向量,每个字均被映射为向量表示,向量维度为dw。
2)位置向量表示:在关系抽取任务中,位置嵌入用相对位置的低维向量表示,最早被文献[12]引入实体关系抽取任务中。在图2所示标注的句子中,当前字“引”与医疗实体“感冒”“发烧”之间的相对位置分别为2和-2,每个相对位置分别对应一个位置向量,维度为dp。

图2 当前字与医疗实体的相对位置
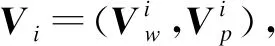
2.1.2 双向GRU层
GRU是循环神经网络的分支,也是LSTM的变体,GRU在保持LSTM效果的同时使其结构简单,且计算简便,由于其在序列处理上的出色表现而被广泛应用于自然语言处理任务中。GRU结构如图3所示。
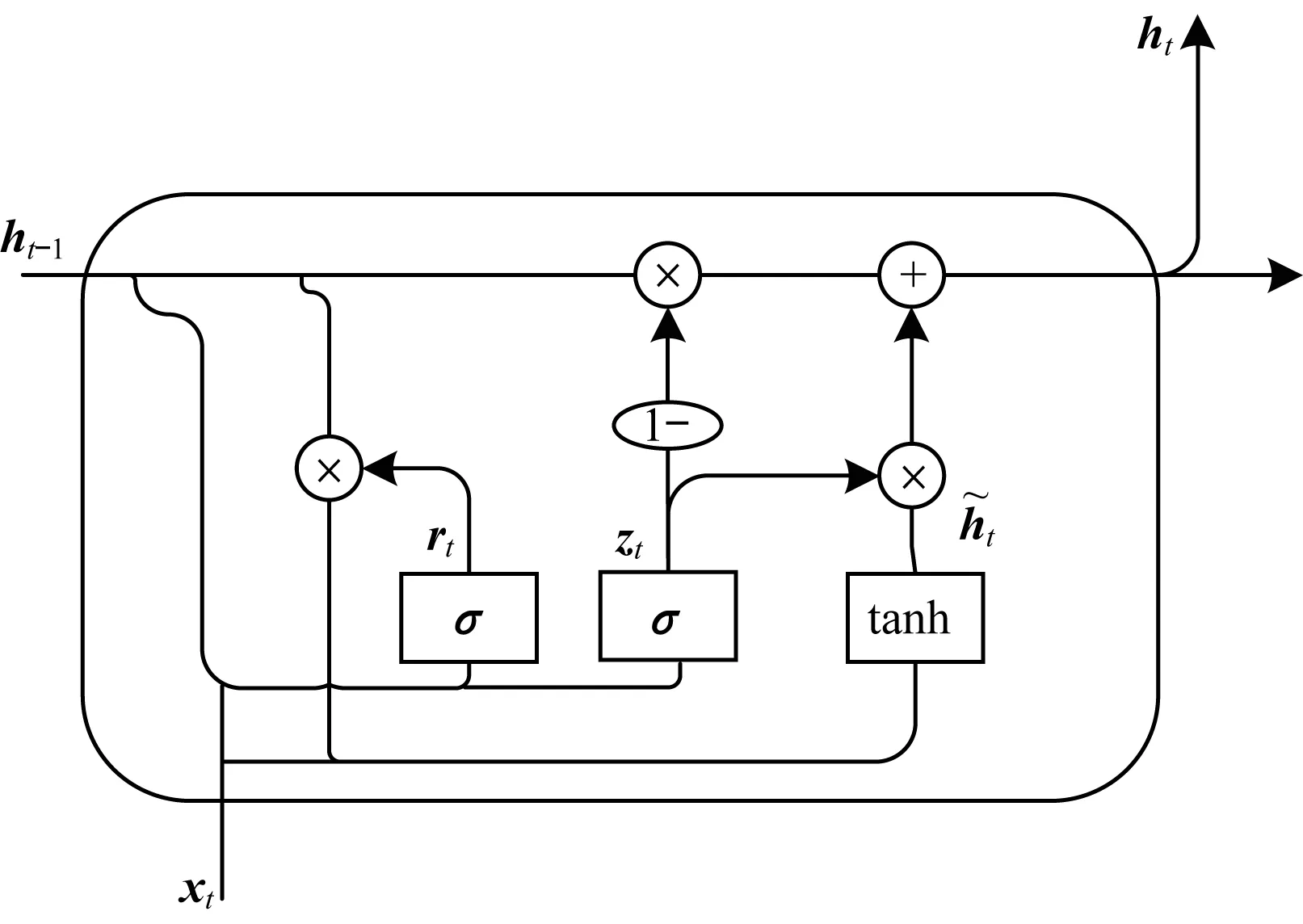
图3 GRU结构
zt=σ(Wzxt+Uzht-1+bz)
(1)
rt=σ(Wrxt+Urht-1+br)
(2)
(3)
(4)
(5)
其中,zt和rt分别为GRU的更新门和重置门,更新门是控制上一时刻的状态信息传递到当前时刻的程度,重置门是控制上一时刻的状态信息被遗忘的程度。Wz,Wr,Wh和Uz,Ur,Uh分别为神经元当前时刻的输入权重和循环输入的权重,bz,br,bh为偏置向量。首先,实验通过上一时刻的隐藏状态信息ht-1和当前时刻的节点输入xt来获取2个门控的状态。得到门控信号之后,利用重置门来获取遗忘后的状态ht-1⊗rt,⊗表示哈达马积对应元素相乘;然后,将其与当前时刻的输入xt相加并通过非线性函数tanh激活;最后,用更新门对当前节点的输入选择记忆。
GRU采用“门”结构来克服短时记忆的影响,不仅可以调节流经序列的信息流,还可以改善RNN 存在的“梯度消失”问题。为了能够有效利用上下文信息,实验采用双向GRU结构,双向GRU对每个句子分别采用前向和反向计算得到2个不同的隐藏层状态,然后将2个向量相加得到最终的编码表示。
2.1.3 字级注意力机制
注意力机制模仿了生物观察行为的内部过程,是一种通过增加部分区域的注意力来获取关注目标更多细节信息的机制。注意力机制可以快速提取数据的重要特征,减少对外部信息的依赖,捕获语言中的长距离依赖性,被广泛应用于自然语言处理任务中。本文通过引入字级注意力机制来判断每个字对关系分类的重要程度,并有效提高模型精确率。
通过双向GRU得到每个字的输出向量ht,输入到全连接层并获得其隐藏表示ut,通过Softmax函数计算归一化权重向量αt,最后得到句子向量表示。字级注意力机制权重计算如下:
ut=tanh(htWt+bt)
(6)
(7)
(8)
其中,Wt表示当前时刻神经元的输入权重,T表示序列长度,uw表示随机初始化的上下文向量,通过反向传播更新上下文向量。St表示编码后的句子向量。
2.2 句子级注意力机制
目前,很多用来构建知识库的方法均需要标注好的训练语料,人工标注的语料因为标注人员不同而导致语料噪声。在实验标注的语料库中,相同的实体对和实体类型在不同的语料中被标注为不同的关系标签,影响模型效果。常见的关系抽取方法是以句子作为单独的处理单元,若仅使用字级注意力机制时,则只考虑到当前的句子信息,而对于含有同一实体对的其他句子,还需要通过句子级注意力机制学习实体共现句的上下文特征,为每个句子学习注意力权重,来提升分类器效果。正确标注的句子将获得较高的权重,而错误标注的句子会得到较低的权重,隐式摒弃一些噪声语料,如图4所示。
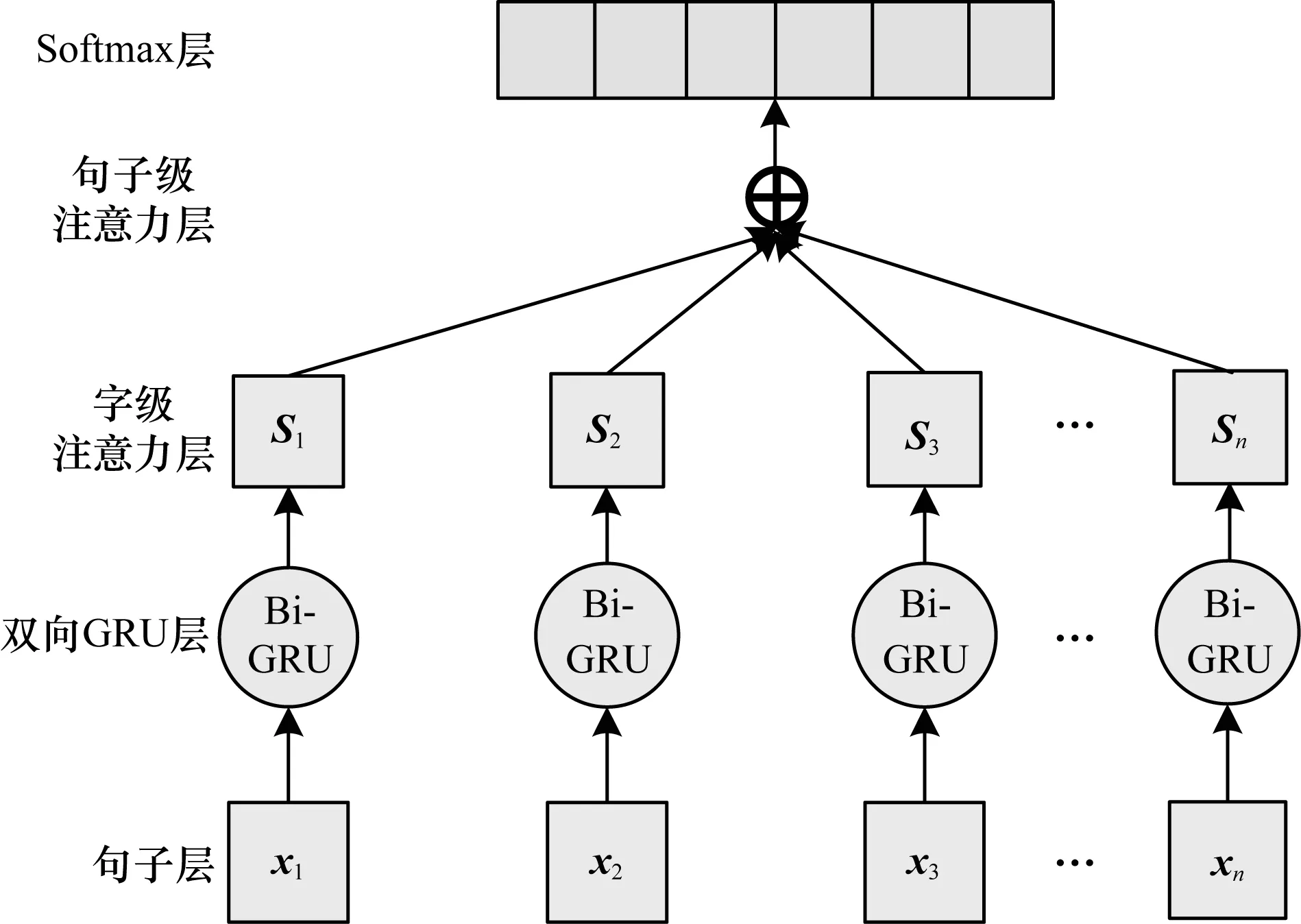
图4 句子级注意力机制模型
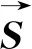
(9)
通过计算句子特征向量与目标实体关系的相似度来得到句子的注意力权值。句子特征向量与目标实体关系向量的相似度越高,则正确表达实体关系的可能性越大,注意力权重也越高。句子特征向量目标实体关系的相似度计算如下:
(10)
ei=xiAr
(11)
其中,ei表示句子特征向量xi与预测关系向量r的匹配分数,A表示加权对角矩阵。最后,通过Softmax层对实体关系向量进行输出。
3 实验结果与分析
3.1 数据集
中文EMR中包含大量的医学知识和临床信息,由于标注人员医学领域知识的限制以及病历中包含患者的隐私,使得EMR在语料构建上存在一定的困难。本文依据I2B2/VA Challenge医学关系标注规范,且在专业人员的指导下,制定自己的中文EMR标注规范。在EMR的文本片段中,医学实体语义关系主要存在于治疗、疾病、检查和症状等实体之间,如表1所示,包含5个粗粒度类别和15个细粒度类别,表2所示为标注语料示例。
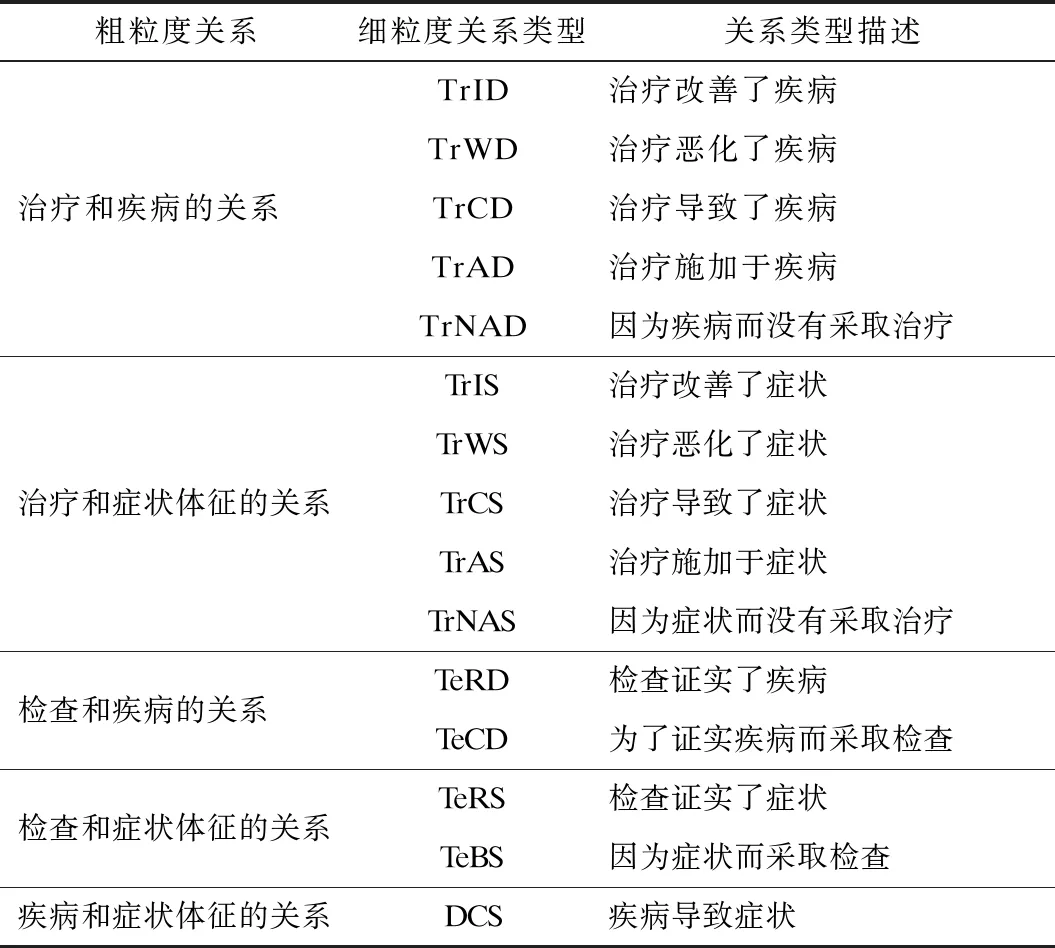
表1 医疗实体关系类型及其描述

表2 中文电子病历医疗实体关系
本文以甘肃省某二级甲等医院提供的不同临床科室的EMR为分析对象。首先,对已校对的EMR文本进行简单的去隐私处理,然后,从不同临床科室随机挑选一定量的EMR文本进行人工标注。本文总共使用1 200份EMR文本对实体关系抽取进行研究,其中800份EMR作为训练集,200份EMR作为开发集,200份EMR作为测试集。
3.2 评价指标
本文利用精确率P、召回率R和F1值对中文EMR实体关系分类效果进行评价,具体计算公式如下:
(12)
(13)
(14)
其中,TP表示对当前类别识别正确的数目,FP表示对当前类别识别错误的数目,FN表示应该识别为当前类别但是没有被识别的数目,TP+FN表示该类别下所有正实例的总数目,TP+FP表示识别出来属于当前类别的总数。分别计算各个类别的精确率P和召回率R,然后以F1值作为各个类别整体的评价指标。
3.3 实验设置
选择目前的主流模型LSTM作为基线实验,分别和SVM模型、CNN模型、BiLSTM-Attention模型和BiGRU-Dual Attention模型进行对比。
1)SVM模型:该模型在SemEval-2010评测任务中表现最好。文献[18]利用各种手工制定的特征,用SVM作为分类器,实验取得了较好的F1值。
2)CNN模型:该模型被文献[19]使用,采用CNN编码句子向量,将编码后的结果最大池化,利用Softmax函数输出结果。
3)BiLSTM-Attention模型:该模型由文献[20]提出。利用双向LSTM抽取上下文信息,结合注意力机制对词赋予不同的权重,判断每个词对关系分类的重要程度,提高对分类有贡献的词权重,有效提高模型效率。
4)BiGRU-Dual Attention模型:该模型由本文提出,使用双向GRU和双重注意力机制结合来抽取实体关系,通过随机搜索调整在开发集上的超参数,超参数如表3所示。
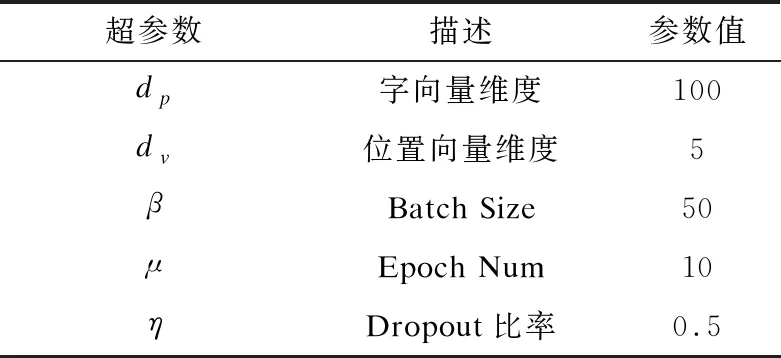
表3 BiGRU-Dual Attention模型超参数
模型实验中字向量维度为100,位置向量的维度为5,Batch Size大小为50,Epoch Num设置为10,使用Adam优化器进行训练,学习率为0.000 5,其中L2正则化值为1,Dropout比率为0.5。在本文中,将Dropout比率与L2正则化结合起来以防止过度拟合。
3.4 实验结果
本文提出基于双向GRU和双重注意力机制结合的实体关系抽取模型,将擅长学习长期依赖信息的双向GRU加入到句子编码阶段中,然后用字级注意力机制提高对关系分类有决定作用的字权重,最后用句子级注意力机制获取更多语句的特征,增大正确标注的句子权重,同时减小错误标注的句子权重。在训练过程中,使用相同的数据、批次大小及迭代次数,分别对SVM模型、CNN模型、LSTM模型、BiLSTM-Attention模型和本文模型进行训练,记录训练过程中最高的精确率P、召回率R和F1值,具体数据如表4所示。
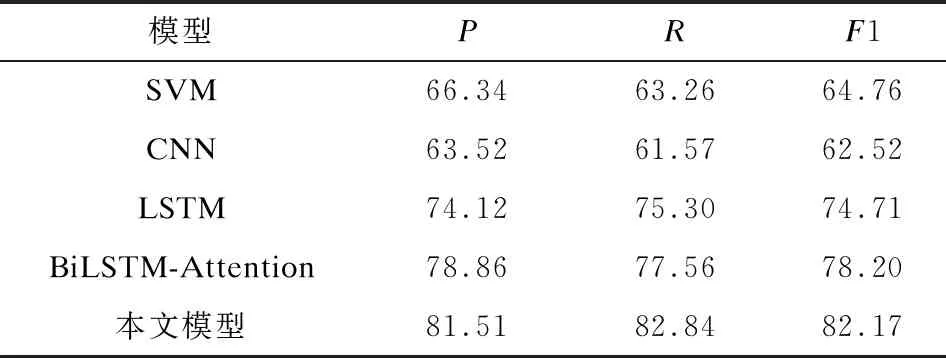
表4 不同模型进行中文电子病历实体关系识别时的 性能比较
3.5 实验分析
根据上述表4中的数据,可以看到本文提出的基于双向GRU结合双重注意力机制的实体关系抽取方法相比其他方法效果较好,F1值达到了82.17%。表4中的学习方法可以分为传统机器学习方法和深度学习方法,从实验结果可以看出,深度学习方法普遍优于传统机器学习方法,这是由于传统机器学习方法依赖于大量的手工特征,而EMR中文本语料较长,且结构性差,传统机器学习方法无法从病历文本中获得包含的语义和长距离信息。本文提出的BiGRU-Dual Attention模型相较于传统的机器学习算法有明显地提高,同时相较于目前主流的BiLSTM-Attention模型,F1值提高了3.97%。在表4中,可以看出精确率P和召回率R均得到了大幅提高,这说明本文提出的方法改善了错误标签的问题,同时在对细粒度特征分析中,结果发现F1值也提升了很多。双向GRU和注意力机制的影响分析如下:
1)双向GRU的影响分析。本文模型在句子编码阶段加入双向GRU结构,能够很好地学习字的上下文信息,并提供丰富的特征。由表4可以看出,LSTM的关系抽取模型比普通卷积的效果更好,然而GRU作为LSTM的变体,它可以像LSTM 一样,既具备记忆序列特征的能力,又善于学习长距离依赖信息。EMR文本语料较长,存在许多长依赖语句,卷积神经网络仅靠滑动窗口来获得局部信息,不能学习到长依赖特征。双向GRU结构却可以学习到丰富的上下文特征,且效果更佳。
2)注意力机制的影响分析。本文模型中通过加入注意力机制,来判断每个字对关系分类的重要程度,提高分类效果,并且引入句子级别的注意力机制,增大正确标注的句子权重,同时减小错误标注的句子权重。本文实验设计对比了LSTM模型、BiLSTM-Attention模型以及BiGRU-Dual Attention模型的实体关系抽取效果。其中,BiLSTM-Attention模型只使用字级注意力机制,BiGRU-Dual Attention模型使用了字级注意力机制和句子级注意力机制。从表4的实验结果可以看出,加入注意力机制的方法均高于未加注意力机制的方法,其中BiLSTM-Attention模型的F1值比LSTM模型的高3.49%,说明加入字级注意力机制有助于实体关系抽取准确率的提升。此外,由表4中数据可以看出,BiLSTM-Attention方法的F1值比本文方法要低许多,这可能是因为本文使用的句子级注意力机制学习更多的语句特征,降低错误标注语句的权值,减少噪声句子影响。
3.6 方法验证
实验将本文方法与Mintz、 MultiR、 MIML 3种传统的远程监督方法相比较,具体数据如图5所示。
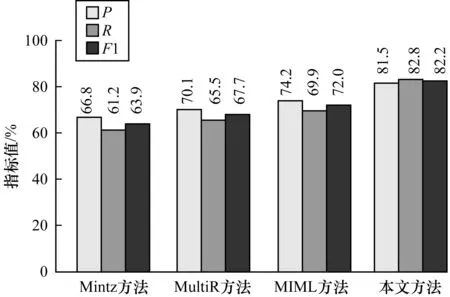
图5 本文方法与传统远程监督方法的结果对比
由图5可知,本文方法的精确率P、召回率R、F1值均高于其他3种传统的远程监督方法,这是因为本文提出的方法不需要人工构建特征,能够准确学习到句子的语义信息,直接从原始字中自动学习特征,减少错误传播。另外,本文方法除了从更多的语句中学习特征,还加入字级注意力机制和句子级注意力机制,有效缓解标签错误问题。
4 结束语
针对已有实体关系抽取方法存在的标签标注错误问题,本文提出双向GRU和双重注意力机制结合的实体关系抽取方法。利用双向GRU学习字的上下文信息,获取更细粒度的特征信息,通过字级注意力机制提高对关系分类起决定作用的字权重,同时加入句子级注意力机制学习更多的语句信息,有效解决标签错误问题。通过在人工标注的数据集上进行实验对比,证明了本文方法能有效提升实体关系抽取效果。下一步将对实体识别和实体关系进行联合抽取。
猜你喜欢
出版人(2022年11期)2022-11-15
小雪花·成长指南(2022年1期)2022-04-09
通信技术(2021年12期)2022-01-25
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
通信电源技术(2016年5期)2016-03-22
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
