
融合施工场景及空间关系的图像描述生成模型
2020-06-18 03:42徐守坤吉晨晨倪楚涵
计算机工程 2020年6期
徐守坤,吉晨晨,倪楚涵,李 宁
(常州大学 信息科学与工程学院 数理学院,江苏 常州 213164)
0 概述
图像描述生成是图像理解领域的研究热点,而对图像场景空间关系的准确描述在图像理解中至关重要。化工厂、建筑工地等施工场景环境多变,存在多种不安全因素,其中人和危险物的空间关系是一个重要方面,例如人站在脚手架上或塔吊机的机臂下方时就存在安全隐患。对图像施工场景中空间关系的准确描述可为施工管理提供理论指导和技术支持,也有助于提高施工现场安全管理水平,防范和降低安全隐患,保证现场的安全性。因此,研究施工场景中空间关系的图像描述具有重要意义。目前,关于建筑施工的研究主要侧重于对不安全行为的潜因分析和施工现场的安全行为检测,关于建筑施工场景图像描述的研究较少。
本文提出一种基于施工场景的图像描述生成模型。针对施工场景需要检测施工人员的安全状态、人员与危险物的空间位置关系,以及最终生成描述语句的特殊性,进行目标检测与关系检测,基于模板和规则相结合的方法构建针对施工场景的图像描述模型,重点研究对象之间的空间关系,并融合目标检测、空间关系语义建模、基于规则和模板的文本生成技术对多个场景进行实验验证。
1 相关工作
传统目标检测方法大部分基于低层图像特征,如图像对比度[1-2]、颜色[3-4]和纹理[5-7]等。近年来,基于深度学习的目标检测方法,特别是基于卷积神经网络(CNNs)的目标检测方法,较传统目标检测方法取得更优异的效果。文献[8]提出两种深度神经网络融合局部估计的像素和全局建议搜索区域可实现突出目标检测。文献[9]使用多个通用的CNN多尺度特征预测各像素的显著程度。虽然上述方法具有较好的效果,但是没有很好地处理底层细节,而且采用的模型包含了多个完全连接层,这些连接层计算量较大,且易丢失输入图像空间信息。为解决该问题,文献[10]提出深层次显著性网络来学习全局结构,通过整合上下文信息逐步细化显著性映射细节。文献[11]开发出深度递归的全卷积神经网络,将粗预测作为显著先验知识,并逐步细化生成的预测。
在关系检测方面,文献[12-13]通过网络学习上面、下面、里面和周围4种空间关系以改善图像分割精度。文献[14-15]提出一种检测相邻物体间物理支撑关系的方法。文献[16-17]通过研究对象间语义关系(例如动作或交互),将每种可能的语义关系组合作为一个可视短语类进行关系检测,该方法采用手工标注且只能检测到少量常见的视觉关系。近年来,基于深度学习的视觉关系检测体系结构引起研究人员的关注[18-20]。文献[18]加入参与对象信息或字幕的语言线索进行关系检测。文献[19]将关系作为连接场景图中两个对象节点的有向边,通过迭代构造场景图推导出对象间关系。文献[20]采用边界框方法标注出主体对象和相关对象,并通过网络学习边界框内的视觉特征。
在图像字幕生成方面,基于模板的方法是使用预先定义模板生成语句,并用模板中的插槽填充图像实体[21-23]。采用该方法将可视化内容表示为一个三元组,其生成的描述语句虽然语法正确但是语言僵化不灵活。基于合成的方法是将检索到的文本片段或者实体拼接成一个图像描述语句[24-26]。该方法通过复杂的预定义规则来检索文本片段或实体以生成完整的图像标题[27]。与基于模板的方法相比,基于合成的方法生成的图像描述更具有表现力,但是其参数个数具有不确定性,因而测试时计算量较大。基于语言模型的方法是将图像和语言结合到一个多模态嵌入空间中,使用基于神经网络的语言模型生成图像标题[28-30]。文献[28]使用循环神经网络(Recurrent Neural Network,RNN)对不同长度的标题进行解码。文献[29]采用LSTM解码器对上下文的图像描述进行解码。文献[31]提出一种多模态对数双线性神经语言模型,该模型通过图像特征的偏置来解码图像标题。文献[32]将CNN编码的图像和分析标准正则学习到的语义嵌入作为LSTM解码器的输入。文献[33]将注意力机制与LSTM解码器结合,在字幕生成过程中注重图像的各部分。
2 图像描述模型设计
建筑施工场景环境具有多变性。施工现场通常存在多种不安全因素,包括施工人员未按规定佩戴安全帽导致被坠落物体击伤,以及脚手架、塔吊等因局部结构工程失稳造成机械设备倾覆、结构坍塌或人员伤亡等,因而本文主要研究以下场景:1)安全防护场景,如施工人员佩戴安全帽的状态;2)高空作业场景,如施工人员在脚手架上;3)地面作业场景,如施工人员在塔吊下方。在安全防护场景中检测施工人员是否佩戴安全帽,在高空作业场景和地面作业场景中检测人与脚手架、塔吊的空间位置关系,并最终生成空间关系图像描述语句。
本文生成空间关系图像描述的模型包括3个阶段,如图1所示。第1阶段是采用YOLOv3网络进行目标检测;第2阶段是采用关系检测模型结合对象坐标框信息进行关系检测,从待测图像中检测所有对象之间的空间关系;第3阶段是基于规则和模板的方法生成关于空间关系的图像描述。
2.1 目标检测
本文使用YOLOv3网络进行目标检测,这是因为该网络融合分辨率不同的特征图,具有较高检测精度和效率。对于分离式模型,目标检测网络性能越好,关系检测结果越优。YOLOv3网络包含Darknet-53特征提取层和3层输出层,其中Darknet-53特征提取层由DBL层和res_unit构成,YOLO输出层由尺度为13×13×255、26×26×255、52×52×255的3种特征图谱构成,如图2所示。该网络结构可提高对不同尺寸物体和遮挡物体的检测精度。YOLOv3网络以跃层连接的方式进行,收敛效果优异,且采用多尺度训练策略增强了该网络的鲁棒性。
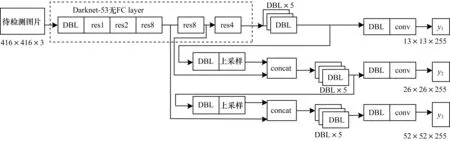
图2 YOLOv3网络结构
图2中DBL层为YOLOv3网络的基本组件,由卷积层、BN层和Leaky relu激活函数组成,BN层、Leaky relu激活函数和卷积层不可分离(最后一层卷积除外)。Resn(n为数字,表示res_block中含有n个res_unit)为YOLOv3网络的大组件,通常有res1、res2、…、res8等。张量拼接(Concat)是将darknet中间层和后面某一层的上采样进行拼接。拼接操作和残差层的add操作不同,拼接操作会扩充张量维度,而add操作只直接相加不会改变张量维度。
YOLOv3网络采用多尺度输出并大量使用残差的跃层连接,是一个全卷积网络。这种残差结构使得YOLOv3网络在结构很深的情况下仍能正常收敛,从而实现模型的正常训练。在通常情况下,网络结构越深,其提取的特征越好,且分类和检测效果越佳。残差网络中的1×1卷积使用了网络的思想,通过减少参数数量一定程度上减少了计算量。
YOLOv3网络检测的每个对象均有一个边界框代表其空间信息和对象分类概率,表示为:
Po={Pi}i=1,2,…,N+1
(1)
其中,Pi为待测物体属于类别i的概率,N为对象类别总数,N+1是作为背景的对象个数。每个被检测对象的位置记为(X,Y,W,H),其中,(X,Y)为图像平面上边框左上角点的归一化坐标,(W,H)为边界框的标准化宽度和高度。
YOLOv3网络目标检测过程具体如下:
1)输入自制目标检测数据集(以下称为自制数据集)并将其预处理为YOLO格式数据集。
2)送入YOLOv3网络训练模型,网络将图片分成S×S个网格,每个单元格用来检测中心点在单元格内的目标,并通过非极大值抑制筛选出最终目标检测框。
3)测试图像,若检测目标得分大于阈值则标注出图像中对象及输出对象得分,否则将显示无法检测出图像中的对象。
自制数据集标注了对象和场景类别,在此数据集上训练模型参数,可使得模型能捕捉图像中的物体信息,同时包含许多场景先验信息用于捕捉图像中的场景信息。在一般情况下,将对象及其特定空间关系抽象为一种场景,该场景包括3个方面:1)场景中行为主体表现出不同的行为特征,如施工人员是否佩戴安全帽;2)场景基本不变或者变化很小,如施工楼层等;3)在同一空间中,对象之间的不同位置关系形成不同场景,如脚手架和塔吊等。自制数据集通过收集施工现场图片,按照上述场景的定义进行标注以支持安全防护、高空作业、地面作业等场景分析。
2.2 关系检测
视觉关系的一般表达式为<主语,谓语,宾语>,组件谓语为一个动作(如戴着),或者为相对位置(如左边、右边)。关系检测的任务是检测和定位图像中出现的所有对象,并预测任意两个对象之间所有可能的空间关系。关系检测过程如下:
1)输入自制关系检测数据集和由目标检测模型训练得到的权重文件,对数据集进行预处理。
2)送入关系检测模型进行训练,采用转换嵌入(TransE)算法学习主语到宾语之间的转换嵌入,通过特征提取层提取对象的类别信息、位置和视觉特征,预测对象之间的关系。
3)测试图像,若检测到对象对关系的得分大于阈值则标注出图像中成对的对象及输出对象间关系的三元组,否则无法检测出图像中对象之间的关系。
2.2.1 空间关系上下左右的定义
定义对象oi的几何中心,其中(xi1,yi1)和(xi2,yi2)分别是对象oi左上角和右下角的坐标:
center(oi)=[centerx(oi),centery(oi)]=
(2)
定义lx(oi) 和lx(oj)分别为对象oi和oj边界框在x方向上的长度,如果
|centerx(oi)-centerx(oj)|<ε(lx(oi)+lx(oj))
(3)
则定义在x方向上两个对象位于同一位置,否则,如果:
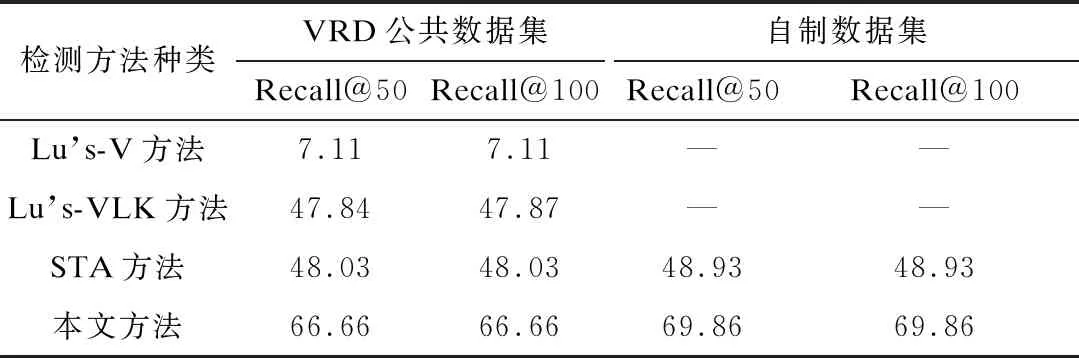
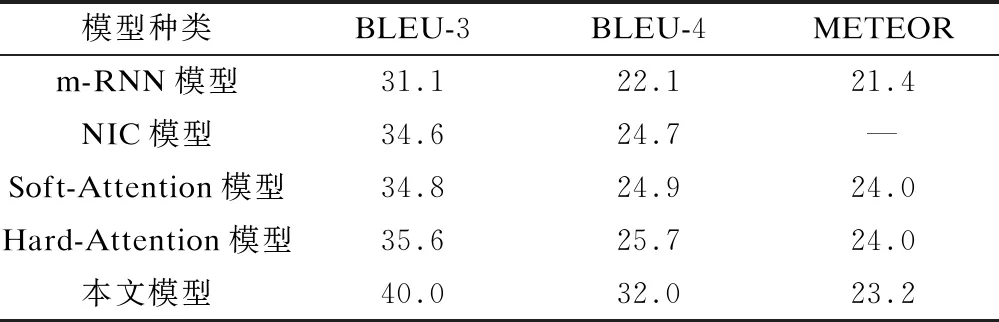
center(oi) (4) 则认为对象oi在oj的左边,否则认为对象oi在oj的右边。 定义ly(oi) 和ly(oj)分别为对象oi和oj边界框在y方向上的长度,如果: |centery(oi)-centery(oj)|<ε(ly(oi)+ly(oj)) (5) 则定义在y方向上两个对象位于同一位置,否则,如果: center(oi) (6) 则认为对象oi在oj的上边,否则认为对象oi在oj的下边。 2.2.2 关系检测模型 本文使用TransE算法作为关系检测模型的基础,并加入特征提取层,其中TransE算法通过在低维空间中映射对象和谓语特征对可视化关系建模,特征提取层以全卷积方式实现目标关系知识的迁移。该模型融合了语言先验知识并提高了关系检测准确率,其建立在传统对象检测模型基础上,可以与YOLOv3网络很好地衔接,从而预测出对象之间的空间关系。空间关系采用广泛使用的 图3 关系检测网络结构 网络结构的相关定义为: 定义1(转换嵌入) 通过在低维空间里将目标和谓语进行建模生成视觉关系,低维空间里的关系三元组被认为是一种向量转换,如“人+上方≈危险源”。通过减少变量可避免学习大量主语、谓语、宾语的表示关系,即使主语或者宾语有较大变换,只需学习空间关系里的“上方”转换向量。 定义2(关系中的知识转换) 网络中对象和谓语之间的知识转移结合。通过一种特征提取层提取转换嵌入中对象的三种类型特征:分类(类概率)、位置(边界框坐标和比例)和视觉特征。 定义3(类别信息) 一个目标检测网络中的(N+1)维向量,用来表示目标的类概率。类别信息在各种视觉任务中被广泛用作语义属性。 定义4(位置) 一个表示边界框参数的四维向量。前两个参数表示比例不变的平移,后两个参数表示相对于主体或者目标其在对数空间的高或宽的变换。以主体为例: (7) 其中,(x,y,w,h)和(x′,y′,w′,h′)分别是主体和目标的坐标。位置特征用于检测空间关系和动词。 定义5(视觉特征) 一个从空间卷积特征转换而来的d维向量。物体的视觉特征通过使用线性插值从卷积特征映射提取出来,因而对象和关系之间的信息、位置、视觉特征可以单一的前向或后向传递。 2.2.3 坐标信息确认 关系检测模型可检测出图像中对象与对象、对象与场景之间的空间关系,对于同一类对象间的关系无法区分,例如关系检测模型检测的关系包含“人在人的左边”“人戴着安全帽”“人在人的右边”,但是无法区分图中戴着安全帽的人在左边还是右边,因而还需利用坐标信息进一步区分对象间的关系。 南通集装箱多式联运尚处于起步阶段,绝大多数企业不具备策划、组织、协调多式联运的能力和经验,整体服务水平处于较低层次。各企业间没有统一的信息协调平台,各企业系统各自独立运行,还处于一种分割的各自为战的状态,这也不利用构建完善的、通畅的集装箱联运体系,无法实现无缝链接,联运效率难以提升。 关系检测模型中存在对象坐标框信息,利用该信息可区分同类对象之间的空间关系,即对象1位于对象2的某个位置。关系检测模型输出关系短语由主语、谓语和宾语组成,本文将关系检测模型检测到的多个关系短语通过以下方式来确认对象间的关系:关系检测模型预测出第一个关系短语,定义一个存放对象边界信息的列表并建立索引,将主语的坐标框信息存放于列表中,获取该坐标框信息的索引并添加到主语后,将宾语的坐标框信息与列表中存储的坐标框信息进行对比,如果无相同的坐标框信息就重新存放于列表中,获取该坐标信息的索引并添加到宾语后。其他关系短语的主语与宾语对象按照上述方式进一步区分,每次向列表中存放对象坐标框信息时,都必须与列表中的边界框坐标信息进行对比,确保存放在列表中的坐标框信息不重复,以保证每个对象有唯一的下标。经实验验证,该方法具有较好的实验效果,可以区分戴着安全帽的人在左边还是右边。 2.3.1 空间关系描述的规则 根据关系检测模型的检测结果,制定空间关系描述规则:从上下关系考虑,根据人是否在危险源的上方或者下方来确定施工场景中是否存在安全隐患;从左右关系考虑,由于单人情况下无需判断左右关系,所以只制定了两人和多人情况下的规则,根据各对象之间的左右关系以及目标对象是否佩戴安全帽来确定左边、右边的人是否佩戴安全帽。空间关系描述规则的具体内容如表1所示。 表1 空间关系描述规则 2.3.2 空间关系描述的生成 在采用模板生成空间关系描述过程中,可采用模板生成技术根据需求设计出可能出现的语言情况,并制定相应情况的模板,模板中有常量也有变量。空间关系描述的表达具有一定规律,可根据人们描述空间关系的固有规律来制定描述的固定模板为:“<变量1>位置的人<变量2>安全帽。”该固定模板以检测到的信息作为字符串嵌入模板中替换变量。 一幅图像生成一个包含空间关系语句(字幕)的过程如图4所示。关系检测模型检测的关系短语、根据图像字幕数据集生成的语句模板与制定的规则三者结合生成图像字幕。 图4 图像字幕生成过程框架 空间关系描述是将图像中对象之间存在的空间关系以自然语言的形式进行描述,其中空间关系既包括人戴安全帽的隐性空间关系,也包括人处于参考对象某个位置的显性空间关系。通常只有将隐性和显性的空间关系相结合,才能贴切、详细地描述一幅图像。下面以关系检测模型得到的空间关系示例图(见图5)为例来说明如何进行有空间关系的图像描述。 图5 空间关系示例图 空间关系描述的语句通常为固定句式,例如“<变量1>位置的人<变量2>安全帽”等,所以空间关系描述可由模板生成技术生成。由图5可以看出,检测的空间关系包含了“人1戴安全帽2”“人3戴安全帽4”“人1在人3的左边”“人3在人1的右边”4种关系,再采用基于规则的方法匹配满足4种关系条件的结果,将<变量1>替换成“左边”、<变量2>替换成“戴”,最终采用基于规则和模板的方法生成空间关系的自然语言描述为:“左边的人戴安全帽并且右边的人戴安全帽”。 实验采用GeForce GTX 1080 Ti软件、CUDNN6.0软件、CUDA8.0软件和Ubuntu16.04软件作为图形处理器(Graphics Processing Unit,GPU),内存为12 GB。本文基于tensorfow框架进行实验操作,该框架支持GPU运算。 目前在国内外尚未发现公开的施工现场工人作业图像标准数据集,实验所用的3 050张图片通过从公共数据集筛选、从“视觉中国”网站收集和自行拍照等方式获得,其中包含了具有不同施工背景和不同质量施工场景的图片。根据目标检测实验需求,将上述图片标注为VOC2007数据集格式,用labelimg进行标注,保存后生成与所标注图片文件名相同的xml文件,如图6所示,分别对每一类图片进行人工标注。 图6 图片标注示例图 3.2.2 关系检测数据集 视觉关系检测(Visual Relationship Detection,VRD)数据集[17]:使用VRD数据集进行关系检测模型的训练,模型在参数调整完成后进行再迁移,替换为自制数据集进行训练。VRD数据集共有5 000张图像,包含100个对象类别和70个关系。具体而言,VRD数据集包含37 993个关系三元组注释,每个对象类别包含6 672个唯一三元组注释和24.25个关系。实验从VRD数据集取4 000张图像作为训练样本、1 000张图像用于测试。其中,1 877个关系只存在于零样本评估的测试集中。 自制数据集:将目标检测数据集中收集的图片按照VRD数据集的格式制作用于关系检测实验,标注“人在危险物的上方或下方”“人和人的左右关系”“人是否佩戴安全帽”以及各个对象的坐标信息,最终生成json格式文件。 3.2.3 图像字幕生成数据集 用于研究图像字幕生成的公共数据集有COCO数据集、Flickr30k数据集等,但上述公共数据集中均没有基于施工场景的图像字幕数据集,因而本文实验使用的图像字幕生成数据集是由目标检测实验中收集的3 050张图片按照COCO数据集格式制作得到。通过自编程实现图片统一命名和统一格式处理,具体流程为:编写一个脚本程序自动获取图片文件名、高度、宽度信息,并将其写进json文件,为每张图片人工标注五句话。标注流程为:对每句caption进行中文描述→翻译成英文→检查时态(现在时或现在进行时)→检查语法→复制到captions_train2018.json文件对应的字幕中→检查整句话→完成全部图片标注后将captions_train2018.json文件内容复制到https://www.bejson.com/网址中检查是否为规范的json文件。 3.3.1 数据集预处理 自制数据集为VOC2007格式,目标检测实验使用YOLOV3网络,因而需先将VOC格式的标注转换为YOLO格式的txt标注,并对YOLOv3网络配置文件的参数进行修改,具体包括:修改filters参数(该参数为输出特征图的数量;其值取决于类别、坐标和masks的数量);修改anchors参数(该参数值由kmeans聚类算法得到,分别为27、17、52、128、53、34、85、56、88、189、134、223、152、120、205、257、374、588)。 3.3.2 网络训练与测试 目标检测实验分为网络训练和网络测试2个阶段。 1)网络训练阶段:先初始化网络训练参数:batch参数(一批样本数量)设置为64;动量参数设置为0.9,使用小批量随机梯度下降进行优化;权重衰减参数设置为0.005,设置该值是为防止过拟合;学习率由原来算法中的0.005变为0.001。YOLOv3网络采用多尺度进行网络训练,增强了网络对不同尺寸图像的鲁棒性,图片尺寸为320×320~608×608,采样间隔为32。实验中网络结构部分参数如表2所示。 表2 YOLOv3网络结构部分参数 2)网络测试阶段:输入一张待检测图片到YOLOv3网络,输出一张检测到目标对象的图片。 3.3.3 评估指标 目标检测有多种评价指标,例如目标检测精度、检测效率和定位准确性等,每种评价指标的性能侧重点不同。本文实验侧重于考察目标检测精度,因此采用多个类别平均精度的平均值(mean Average Precision,mAP)作为描述目标检测精度的评估指标。mAP取值范围为[0,1],mAP值越大表示目标检测精度越高。精确度的计算公式如下: (8) 其中,TP(True Positive)为被模型预测为正值的正样本;FP(False Positive)为被模型预测为负值的正样本。 3.3.4 结果与分析 由图7可以看出,当YOLOv3网络开始训练时,损失值高达6 000;随着YOLOv3网络训练迭代次数的增加,损失值逐渐降低;当YOLOv3网络训练迭代次数达到5 000次时,损失值趋于恒定约为0.1。从损失值的收敛情况看,YOLOv3网络的训练结果较理想。 图7 YOLOv3网络训练过程中损失值随迭代次数 的变化曲线 目标检测实验的部分检测结果如图8所示。可见通过目标检测实验检测出人、安全帽和脚手架等对象,这表明YOLOv3网络可实现对目标对象较准确地定位。 图8 目标检测实验的部分检测结果 3.4.1 数据集预处理 训练用图使用一个“主谓宾”三元组来标记,其中每个不同的主体或者目标用边界框进行注释。 3.4.2 网络训练与测试 关系检测实验分为网络训练和网络测试2个阶段。 1)网络训练阶段:图像尺寸设置为600像素(最大不能超过1 000像素),一个图像和128个随机选择的三元组作为每个批次的输入。首先在VRD数据集上训练模型,模型训练完毕后再用自制数据集进行训练。采用Adam优化器计算各参数的自适应学习率。初始学习率均设置为0.000 01,batch参数设置为50,每测试50个样本更新一次参数。在每次学习过程中,将学习后的权重衰减按照固定比例降低,权重衰减参数设置为0.005。关系检测网络结构的部分参数如表3所示。 表3 关系检测网络结构部分参数 2)网络测试:输入一张未标注的图片到关系检测模型,输出一个检测到不同目标的集合,并且输出每一对目标之间关系的预测评分。 3.4.3 评估指标 实验使用召回率(Recall@N)评估关系检测模型对空间关系检测的有效性[34],Rec@N用来计算每个图像前N个预测中所包含正确关系实例的比例,计算公式如下: (9) 其中,FN(False Negative)表示被模型预测为负值的正样本。 3.4.4 结果与分析 关系检测实验的部分检测结果如图9所示。可见通过关系检测实验检测出单人场景中人与物之间的关系、多人场景中人与人间的关系,这表明关系检测模型可较准确地检测对象之间的空间关系。 图9 关系检测实验的部分检测结果 利用坐标信息区分同类对象的关系检测实验部分检测结果如图10所示。可见通过实验检测出人1在人3的左边,这表明加入坐标信息后关系检测模型可区分出同类对象间的空间关系。 图10 利用坐标信息的关系检测实验部分检测结果 除了本文采用的关系检测方法(以下称为本文方法)外,常用的关系检测方法还有Lu’s系列方法和STA方法。Lu’s系列方法采用单独预测对象和关系谓语,结合语言先验知识进行关系预测。STA方法采用训练前重组策略,降低关系对于对象的依赖性再进行关系预测。本文方法以TransE算法和特征提取层为基础结合坐标信息检测对象间的关系。分别采用Lu’s-V方法[18]、Lu’s-VLK方法、STA方法[35]和本文方法在VRD公共数据集和自制数据集上进行实验,结果如表4所示。可见采用Lu’s-V方法和Lu’s-VLK方法得到的召回率较低;采用STA方法得到的召回率略有提升;采用本文方法得到的评估指标分数较高,在VRD公共数据集和自制数据集上采用本文方法得到的召回率比采用STA方法得到的分别提高18.63%和20.03%,这表明本文方法更适用于检测对象之间的空间关系。 表4 不同关系检测方法在不同数据集 上得到的召回率 3.5.1 数据集预处理 将图像字幕数据集分割为单词,按单词出现的频率进行筛选后建立词汇字典,词汇字典里包含单词、词频、单词编号,出现频率低于4次的单词不被收入词汇字典。 3.5.2 图像字幕生成的过程 关系检测模型检测的空间关系为“人1戴着安全帽2”“人1在人3的左边”“人3在人1的右边”,根据定义的规则,可得到关系检测结果为“左边的人戴着安全帽”。句子模板为The 3.5.3 评估指标 本文采用双语评估替补(Bilingual Evaluation Understudy,BLEU)方法和METEOR方法对生成的语句进行整体评估[36-37]。BLEU方法将候选翻译结果的N-gram算法与参考结果的N-gram算法匹配的个数进行对比。这些匹配与位置无关,匹配个数越多说明候选翻译越好。BLEU方法是一种改进的精度度量方法,缺点为语句简短,其计算值为不同长度N-gram算法的加权几何平均值。METEOR方法通过将翻译假设与参考译文对齐并计算语句相似度评分来评估翻译假设。对于一个假设引用对,可能的对齐空间通过详尽地确定语句之间所有可能的匹配而构建。如果单词的表面形式相同,则表明单词匹配;如果词干相同,则表明词干匹配;如果短语在适当的释义表中被列出,则表明短语匹配。 3.5.4 结果分析 将本文模型与m-RNN、NIC、Soft-Attention、Hard-Attention等主流模型在自制数据集上的精度进行对比,结果如表5所示。可见与m-RNN模型和NIC模型相比,本文模型在BLEU-3、BLEU-4、METEOR等评价指标上分数较高(评估指标值越高,说明模型性能越好),其中本文模型的BLEU-4值比NIC模型提高7.3%。这是因为NIC模型是较早提出的端到端模型,采用CNN网络和LSTM网络生成图像描述,因而本文模型的性能整体优于NIC模型的。与Soft-Attention模型和Hard-Attention模型相比,本文模型的METEOR值略低,但是反映句子连贯性和准确率的BLEU-4值较高,其中本文模型的BLEU-4值比Soft-Attention模型提高7.1%,比Hard-Attention模型提高6.3%。这是因为Soft-Attention模型虽然在NIC模型的基础上增加了注意力机制,但是没有考虑描述图像中对象之间的空间关系,所以本文模型的性能比Soft-Attention模型更优。 表5 本文模型与其他模型在自制数据集上的 评价指标情况 由表6可以看出,与NIC模型相比,本文模型生成的语句具有更好的空间关系语义表达,能更准确地描述施工场景中包含的空间位置关系。在建筑施工场景中,当两个人都戴了安全帽时,本文模型描述为“左边的人戴着安全帽并且右边的人戴着安全帽”;当两个人中只有一个人戴了安全帽时,本文模型明确描述出是左边的还是右边的人戴着安全帽。 表6 本文模型与NIC模型生成的图像描述对比 本文提出一种融合施工场景及空间关系的图像描述生成模型。通过使用YOLOv3网络目标检测模型训练得到权重文件,将其与数据集输入到关系检测模型,基于规则和模板的方法生成图像描述。实验结果表明,本文模型较m-RNN、NIC、Soft-Attention、Hard-Attention模型在图像描述生成任务上取得更好的效果,能很好地解决施工现场中人的安全性推断和描述问题。但是本文模型生成的描述语句句式较单一,内容上缺乏细节描述,下一步将对此进行研究以生成更生动的图像描述语句。
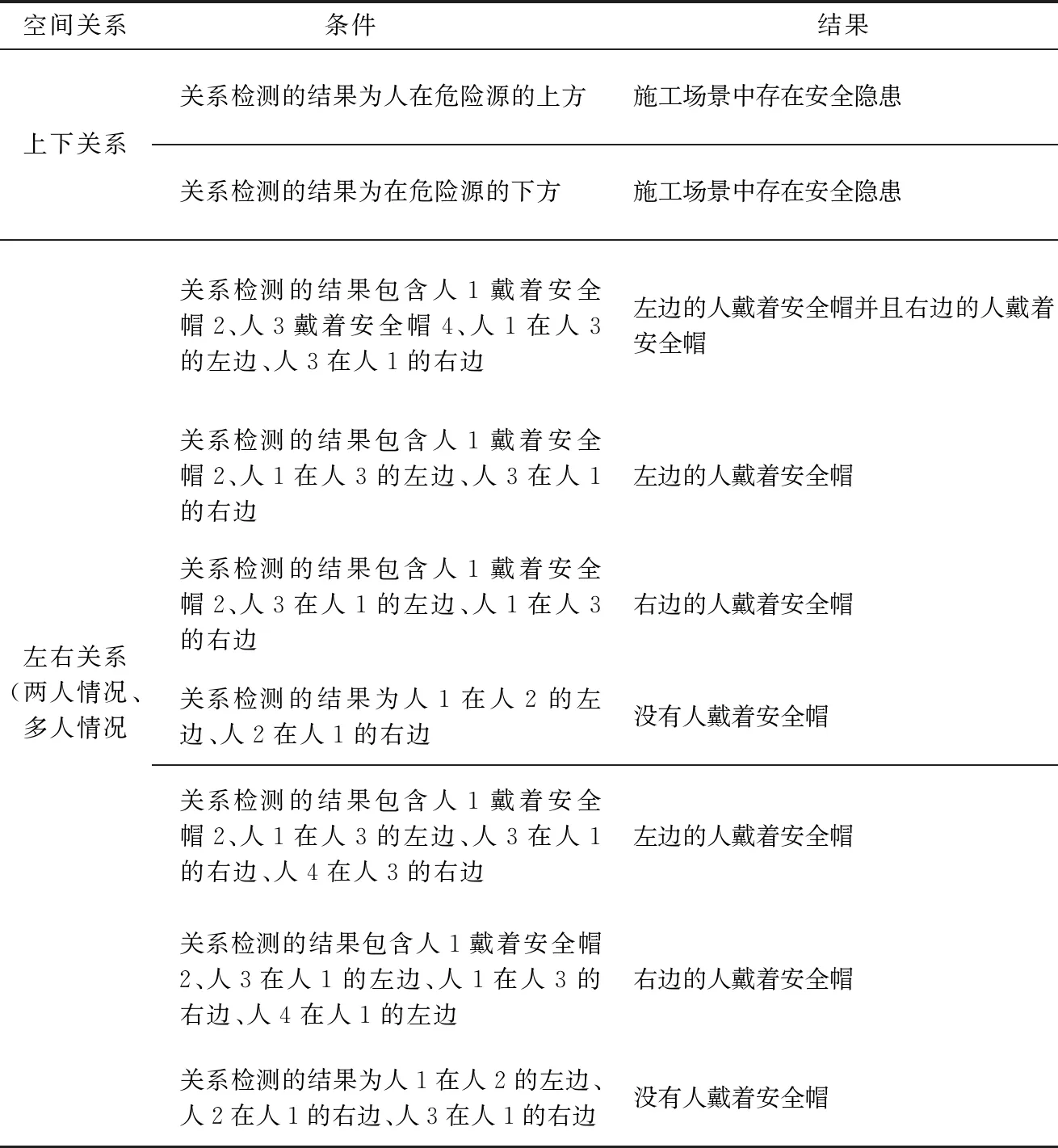
2.3 基于规则和模板的空间关系描述方法
2.4 空间关系的图像描述


3 实验与结果分析
3.1 实验环境
3.2 数据集

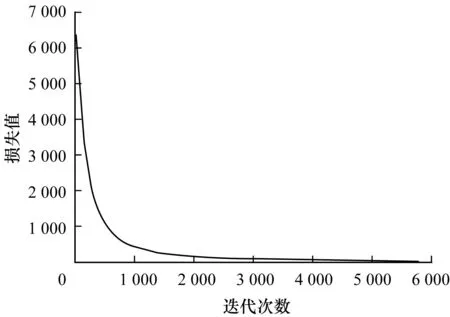
3.3 目标检测实验


3.4 关系检测实验



3.5 空间关系图像描述实验

4 结束语
猜你喜欢
机电安全(2022年4期)2022-08-27湖南税务高等专科学校学报(2021年4期)2021-08-30中学生数理化(高中版.高考理化)(2020年11期)2020-12-14中学生数理化·中考版(2020年10期)2020-11-27作文小学中年级(2020年6期)2020-07-24课外生活·趣知识(2019年4期)2019-09-10意林(2018年3期)2018-03-02今古传奇·故事版(2017年5期)2017-04-08北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27自然资源遥感(2014年3期)2014-02-27
