
基于风险轨迹与复杂网络的缺陷定位方法
2020-06-18 03:41:50王曙燕孙家泽
计算机工程 2020年6期
王曙燕,韩 雪,孙家泽
(西安邮电大学 计算机学院,西安 710121)
0 概述
随着软件复杂性的增加,软件缺陷几乎不可避免。程序调试在软件开发与维护过程中是一项成本昂贵且复杂耗时的工作[1]。研究表明,软件发展维护过程中50% ~80%的成本用于软件测试和调试[2]。因此,如何有效快速定位软件缺陷是保证软件高质量和可靠性的关键性工作。
当程序输出偏离预期输出时,通常说明程序中存在缺陷。传统的软件缺陷定位方法大多是在源码中设置断点,在失败的输入上重新执行程序,并检查程序状态以了解失败的原因,但该方法依赖于程序员的主观判断,效率不高。为实现软件缺陷定位自动化,许多用于调试的自动缺陷定位技术被提出。文献[3]提出将程序切片技术用于软件调试中,常被用来减少错误的搜索范围,但存在时间和空间复杂度过高的问题。文献[4]提出基于覆盖信息的错误定位技术,通过对成功和失败测试用例执行过程中的覆盖信息进行分析,计算语句可疑度,例如Tarantula[5]、Jaccard[6]和Ochiai[7]等方法,但这些方法会受到偶然性成功测试用例的影响[8],使定位效率降低。文献[9]提出程序谱的概念,程序谱记录了程序运行过程的某方面信息,可用于跟踪程序行为。文献[10]通过对程序频谱间差异和回归缺陷的相关性进行研究,实验结果表明有缺陷的程序在运行过程中表现出行为异常的概率较大。文献[11]根据程序光谱间的相似性进行缺陷定位,但如果错误语句不在可疑集合中,则定位效率会明显降低。文献[12]收集时间频谱信息用于辅助缺陷定位,通过对比成功和失败测试用例执行的时间谱并找出差异,然而差异处存在缺陷的概率较大。文献[13]通过构建程序频谱及其执行结果之间的关系模型,提出基于条件概率的缺陷定位方法,总体定位效果显著。但上述技术均是关注软件局部特征而非全局特征,适用范围相对较小。
为寻找通用的软件缺陷定位方法,文献[14]将复杂网络理论引入软件缺陷定位领域,提出基于中心度量的软件缺陷定位方法,通过度中心性和结构洞两个度量值计算程序语句的怀疑度。文献[15]根据错误语句在通过测试执行和测试执行失败过程中的距离对程序各语句进行怀疑度计算,提出基于复杂网络理论的软件缺陷定位方法,该方法可同时对程序中的单个错误和多个错误进行定位。
相对而言,基于语句粒度的缺陷定位分析研究较多,而基于函数这一粒度进行分析的缺陷定位研究较少。从实际情况看,程序中出现的多数缺陷是由函数内部的语句间逻辑错误引起,因此以函数为研究对象定位软件缺陷更符合生产环境[16]。面向对象程序,文献[17]指出如果某个方法仅出现在程序通过或失败程序中,此方法可行性不高。文献[18]通过挖掘控制流异常对缺陷进行定位,该方法可有效定位缺陷函数。文献[19]将缺陷报告和源代码方法体用向量表示,计算其余弦距离并排序,提出的MethodLocator技术可有效定位缺陷函数。针对以函数为分析粒度进行缺陷定位效率不高的问题,本文提出基于风险轨迹与复杂网络的缺陷定位方法(Defect Location Based on Risk Trace and Complex Network,DRC),以期在满足对大规模软件缺陷定位需求的同时,提高软件缺陷定位效率。
1 程序风险轨迹获取
在程序执行时动态输入多个测试用例,获取运行过程中的函数调用序列,根据测试用例在不同缺陷版本程序的执行结果,为待测程序选择目标序列和可疑序列,提取风险轨迹并检测可疑函数候选集。
1.1 函数调用序列获取
函数调用序列(Function Call Sequence,FCS)指程序在特定输入下函数之间调用关系的全信息。本文主要分析函数调用序列的3个部分:函数间的调用关系,函数间调用次数及函数调用的时间顺序。
定义1(函数调用关系) FC=a→b[calls="count"],其中,a与b均为函数名,a称为主调函数,b称为被调函数,a→b表示函数a调用函数b,calls="count"表示a函数调用b函数count次。
动态获取函数调用序列,如图1所示。利用C程序代码追踪工具Pvtrace[20],通过定制特殊的分析函数,可获取函数运行过程中的地址信息。然后将分析函数与待测程序一起编译,就可获取一个调用路径可追踪的新程序。将设计好的多个测试用例动态输入调用路径可追踪的程序中,多次运行程序,得到函数运行时所对应的地址序列文件,利用可将指令地址转换为函数名的工具Addr2line,把地址信息转换为对应的函数名称,Pvtrace可以通过分析函数执行序列得到函数间的调用序列dot文件。

图1 函数调用序列获取流程
1.2 风险轨迹提取
若程序P在测试用例ti上执行对应预期输出结果为oi,实际输出结果为pi,根据测试用例在程序上执行是否通过可以定义目标序列和可疑序列。
定义2(目标序列) 如果pi=oi,则说明程序在测试用例ti上执行通过,所对应的函数调用序列称为目标序列Scorrect。
定义3(可疑序列) 如果pi≠oi,则说明程序在测试用例ti上执行不通过,所对应的函数调用序列称为可疑序列Sdoubt。
定义4(风险轨迹) 通过对比目标序列和可疑序列,提取可疑序列与目标序列不一致序列的集合称为风险轨迹Trisk。
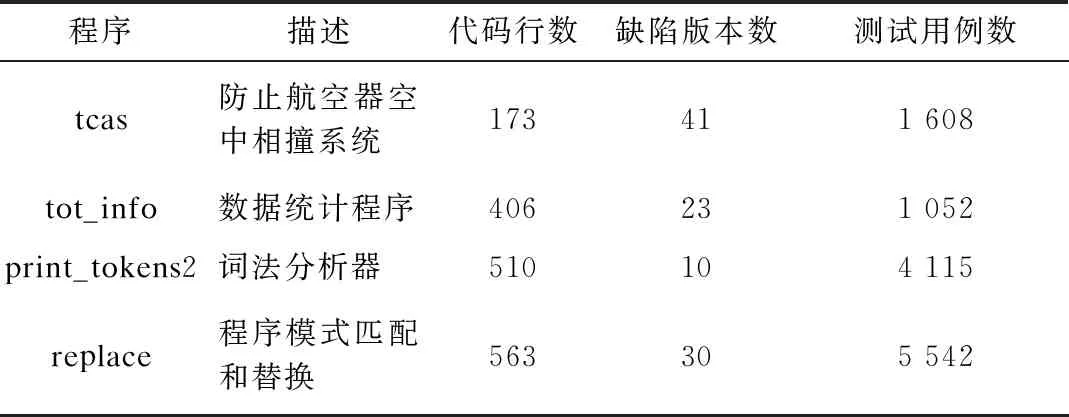
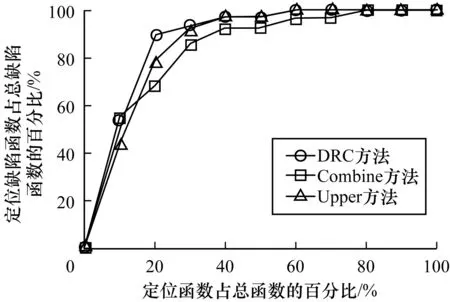
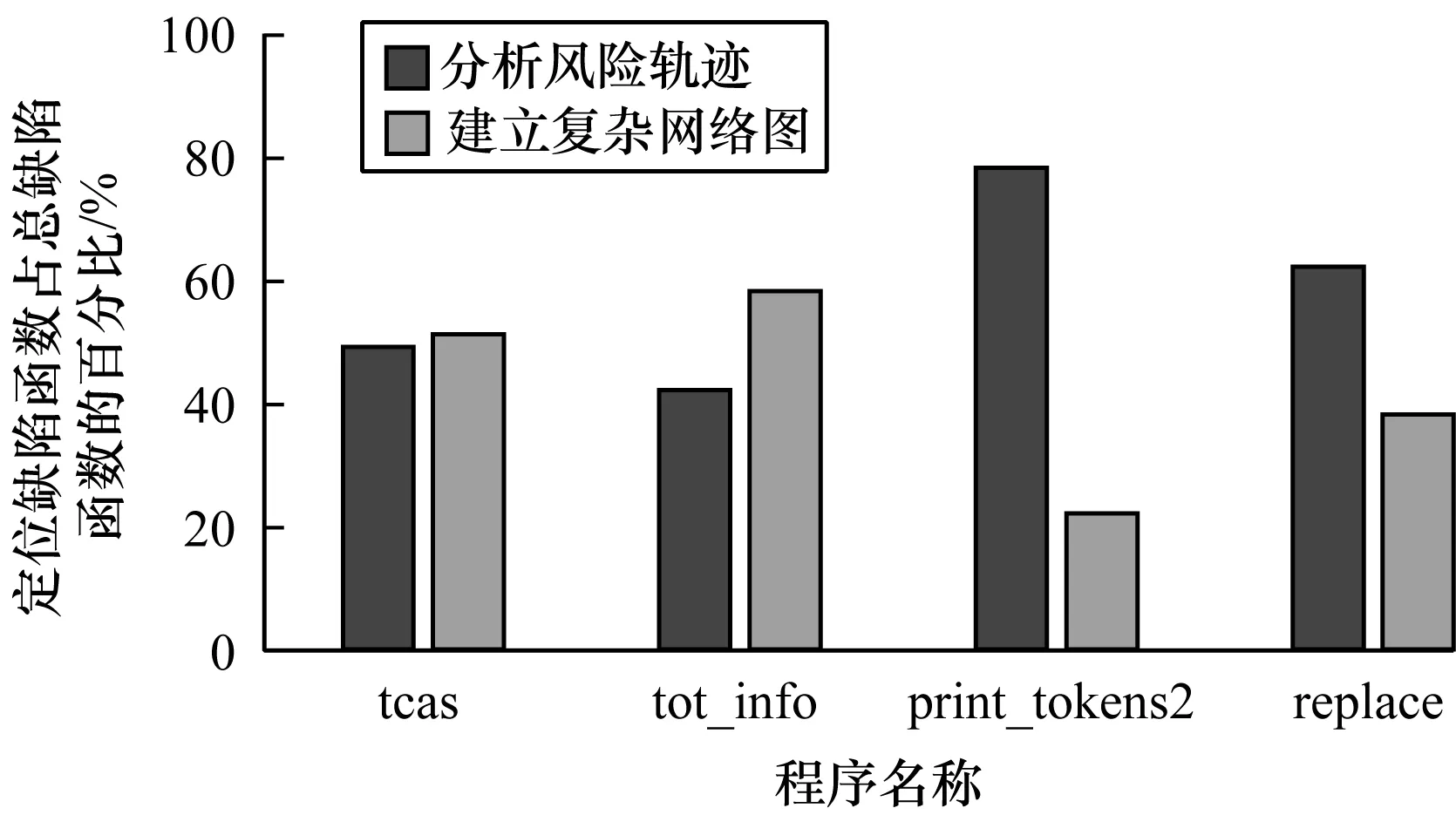
对于特定的输入,程序函数调用序列是固定的。存在缺陷的程序在执行测试用例时可能会导致函数调用序列发生异常,将目标序列和可疑序列进行对比找出程序风险轨迹,分析并提取可疑函数集,依次检测并定位缺陷函数。通过运行正确的程序可获取目标序列,也可能在大多情况下无法获得一个正确的软件版本,但却可以得到含有不同缺陷版本的软件。在回归测试中,对比多个含缺陷版本的程序,同一个测试用例可能在一个版本中执行失败,在另一个版本中执行成功,在程序执行成功中的函数调用序列就是目标序列[21]。假设程序P在回归测试中的版本是P1,P2,…,Pn。如果测试用例t在P1中运行失败,在Pi(1 本文主要分析函数间的调用关系、函数间调用次数及函数调用的时间顺序3种函数调用信息。当可疑序列与目标序列调用关系或调用次数不一致时,异常位置的主调函数很可能存在缺陷。当可疑序列与目标序列调用时间顺序不一致时,说明异常位置的上一调用序列有很大嫌疑,以致异常处函数调用时间顺序异常。如果可疑序列与目标序列同时出现函数间的调用关系、调用次数及调用时间顺序不一致时,则认为调用关系和调用次数异常对程序缺陷影响更大,可忽略调用时间顺序异常,因为调用时间顺序不一致可由多种因素造成,提取可疑函数候选集时,只考虑调用关系和调用次数异常。 在获取待测程序目标序列和可疑序列后,利用Linux文本比对命令diff找出程序风险轨迹,diff命令会在可疑序列与目标序列不一致处打上标记,共有3种情况:1)不一致处标记为“|”,表示可疑序列与目标序列对应行调用信息(调用关系或次数)有所不同,提取不一致位置的主调函数作为可疑函数;2)不一致处标记为“<”或“>”,表示可疑序列与目标序列调用时间顺序(调用序列个数)不同,提取发生异常处上一位置的主调函数和被调函数作为可疑函数;3)无标记,说明目标序列和可疑序列完全相同,不提取可疑函数。 将提取的可疑函数fsuspect按其在调用序列的执行次序排列,作为可疑函数候选集Tsuspect={fsuspect1,fsuspect2,…,fsuspectn|n≥1},然后依次检测,定位缺陷函数。 由于复杂网络在解决复杂问题方面的鲁棒性和自适应性,因此在过去的几十年中受到来自不同领域研究工作者的极大兴趣与广泛关注。最重要的是,复杂网络具有很强的数学背景,使得复杂网络成为理解系统复杂性的重要工具。复杂网络的研究成果为探索大规模软件系统提供有力支撑,利用网络的观点看待软件系统得到了众多研究者的认同。复杂网络为缺陷定位提供了新思路[22],在不深究程序内部细节的情况下,从整体和全局的角度探究与软件缺陷相关的信息量。本文将函数作为分析对象研究缺陷定位,随着粒度变大,网络结构越来越简单,从而能忽略一些局部的细节问题,获得更通用的研究结果。 在函数动态调用关系图中位于叶节点的函数不会调用其他函数,导致函数调用序列发生异常的可能性很小,基于风险轨迹的分析忽略此类缺陷。在检测完毕分析风险轨迹提取的可疑函数集后未发现缺陷函数或目标序列与可疑序列并无异常时,将待测程序的函数调用序列中函数名作为节点,函数间调用关系作为边为程序建复杂网络图,求其节点出度值(Out Degree,OD)。OD值代表该节点调用其他节点的个数(即该函数调用其他函数的个数),在函数动态调用关系图中处于叶节点的函数出度值为0。出度值计算方式如下: 其中,对于节点Ni,复杂网络记录了该节点指出的邻接节点Nj,j为节点Ni所指出的所有邻接节点序号,n为复杂网络中的节点总数,OD(i)为节点Ni的出度值,oij为节点Ni是否指向节点Nj,如果节点Ni指向节点Nj,则oij= 1,否则oij= 0。 将OD值从小到大排列,若出现多个OD值相同的节点,则按其在输入数据文件中的执行次序排列,在排序后的缺陷函数候选列表中去除分析风险轨迹时已检测过的函数,生成缺陷函数候选集Tfault,在Tfault中依次检测并定位缺陷函数。 DRC方法实现流程如图2所示,其主要模块为:1)获取风险轨迹模块,在执行程序时动态输入测试用例集,获取运行过程中的函数调用序列,为待测程序找出目标序列和可疑序列,对比找出风险轨迹;2)分析风险轨迹模块,主要对风险轨迹的异常信息进行分析,提取可疑函数集;3)定位缺陷函数模块,检测可疑函数集并直接定位缺陷函数,或者针对风险轨迹模块定位不足的问题,融合复杂网络相关度量进行二次定位,最终定位缺陷函数。 图2 DRC方法流程 DRC方法实现步骤具体如下: 步骤1获取函数调用序列。将待测程序Pf和其他任一含缺陷版本的程序P′f分别与分析函数一起编译,获取两个调用路径可追踪的新程序,将设计好的测试用例集动态输入路径可追踪的程序中,记录测试结果通过或失败。 步骤2获取目标序列和可疑序列。在测试用例集中找出测试用例t,使得t在Pf上运行不通过,在P′f上运行通过。将t在Pf执行过程中的函数调用序列称为可疑序列,在P′f执行过程中的函数调用序列称为目标序列。 步骤3分析风险轨迹。利用Linux文本比对命令diff找出程序风险轨迹,根据diff命令在不一致处的标记类型提取可疑函数集,并依次检测定位缺陷函数。如果可疑序列和目标序列一致,则转到步骤4。 步骤4定位缺陷函数。如果步骤3执行完未定位到缺陷函数,将待测程序的函数调用序列作为输入数据文件,以函数名作为节点、函数间调用关系作为边为程序建立复杂网络图,求其节点OD值并排序,去除上一步已检测过的函数生成缺陷函数候选集,最终定位缺陷函数。 下文以西门子数据集的replace(字符串匹配替换程序)测试集中6个缺陷版本程序(v1和v2、v7和v8、v20和v21)为例,具体说明DRC方法的实现过程。 将以上版本程序分别与分析函数进行编译,获取对应调用路径可追踪的程序,将测试集提供的测试用例动态传入路径可追踪的程序并记录测试结果(通过或失败),可获得多组函数调用序列。为方便统计本文实验在相邻缺陷版本程序中找到待测程序目标序列,例如,若要检测v1版本中的缺陷函数,则要在v2版本找到目标序列。目标序列和可疑序列所对应的测试用例不唯一,只需找出一个测试用例即可。在v1和v2、v7和v8、v20和v21中,在测试用例集中找到符合条件的第一个测试用例分别为t205、t29和t290。 若要检测v1的缺陷函数,首先将测试用例t205传入v1和相邻版本v2中,分别获取可疑序列和目标序列,然后用diff进行分析比对,找出风险轨迹。如图3所示,[label="xcalls"]表示函数间调用x次。分析风险轨迹,根据异常标记,忽略序列调用时间顺序异常,提取可疑函数集Tsuspect={dodash,subline,amatch,patsize},按可疑函数候选集中次序依次检测,检测第1次就定位出缺陷函数,即定位成功。 图3 diff标记的v1和v2调用序列结果 若要检测v7的缺陷函数,首先将测试用例t29传入v7和相邻版本v8中,分别获取可疑序列和目标序列。然后用diff进行分析比对,找出风险轨迹。如图4所示,分析风险轨迹,根据异常标记,忽略main函数异常,提取可疑函数集Tsuspect={makepat,int_set_2,dodash,addstr},按可疑函数候选集的次序依次检测,检测第2次就定位出缺陷函数,即定位成功。 图4 diff标记的v7和v8调用序列结果 若要检测v20的缺陷函数,则首先将测试用例t290传入v20和相邻版本v21中,分别获取可疑序列和目标序列。然后用diff进行分析比对,发现目标序列与可疑序列完全一样,此时,将处理后的可疑序列文件作为数据输入文件,在Cytoscape平台上建立复杂网络图,求其函数节点OD值。表1是程序中各函数节点的出度值及缺陷函数检测次序(其中“—”表示main函数无需检测),按检测优先级次序检测,检测第2次就定位到缺陷函数。 表1 函数节点出度值及检测优先级 为验证本文方法的有效性,选用西门子套件的4个子测试集作为评测程序,基本信息如表2所示。 表2 评测程序信息 实验程序均采用shell脚本和Python语言编写,计算机配置为Intel(R) Core(TM) i7-8550U CPU@1.80 GHz,内存为8 GB,使用的GCC版本为5.4.0。测试执行结果与程序集提供无缺陷程序的输出进行比较,若一致则通过,否则为失败。 为验证本文方法的有效性,选择同样基于函数粒度级别的缺陷定位方法Combine和Upper与本文DRC方法进行比较。表3是在replace数据集上这3种方法的定位结果,replace数据集有30个缺陷版本的程序,由于其中1个缺陷在宏定义上,因此忽略此缺陷版本。 表3 Combine、Upper与DRC方法缺陷定位结果比较 由表3可以看出,本文方法不执行所有测试用例,平均需执行700个测试用例。由表4可知,定位到的缺陷函数平均检测数少于Combine和Upper方法,且稳定性好,定位效果优于Combine与Upper方法。 表4 Combine、Upper与DRC方法缺陷定位性能比较 由图5可以看出,相较于Combine和Upper方法,本文DRC方法定位效率明显提高,仅需检测20%的函数即可定位出90%的缺陷函数,而Combine、Upper方法检测同样数量的函数可定位出的缺陷函数分别是69%和79%,与这两种方法相比,缺陷定位代价分别降低了22.2%和12.5%。图6展示了本文DRC方法在4个不同量级程序上的缺陷定位效果,结果表明,程序规模越大,该方法对缺陷的定位越有效,定位效果随程序规模的扩大而提高,更适用于大规模程序。图7为本文DRC方法在4种不同量级的程序上,通过分析风险轨迹和建立复杂网络图定位到的缺陷函数比例。其中,分析风险轨迹平均可以定位58%的缺陷,建立复杂网络图平均可以定位42%的缺陷。由此表明,程序缺陷在大多情况下会导致函数调用序列发生异常。 图5 Combine、Upper和DRC方法的缺陷定位效率比较 图6 DRC方法在不同量级程序下的缺陷定位效率 图7 DRC方法的缺陷相关度 目前,基于函数粒度的缺陷定位方法大多是先统计程序中函数调用过程中的全信息,再结合概率论或数据挖掘的方法定位缺陷。这些方法消耗时间资源与所需测试用例数量均较多,并且将获取的信息应用于概率论或数据挖掘中的方法较为复杂,在大型软件中效率不高且可操作性不强。本文以函数为分析粒度进行研究,通过分析程序风险轨迹,提出对不同类型的异常序列进行可疑函数抽取的策略,并针对基于风险轨迹定位会忽略叶函数节点的缺陷,结合复杂网络相关度量,定位此类缺陷。根据软件风险轨迹异常信息给出不同异常类型的优先级,通过对西门子测试集多个程序进行测试,并与同样以函数为分析粒度的Combine和Upper缺陷定位方法进行对比,实验结果表明,本文方法在节省时间资源消耗的情况下,提高了缺陷定位效率,且在大型软件上可操作性更强。由于本文实验程序中仅含单个错误,因此后续将在含多个错误的程序上验证DRC方法的有效性,并且复杂网络中的其他度量(如紧密度中心性、介数中心性等)在软件缺陷定位领域的应用也将是下一步研究的重点。1.3 风险轨迹分析
2 DRC方法
2.1 复杂网络图构建
2.2 DRC方法实现流程

3 实例分析



4 实验结果与分析
4.1 实验设置
4.2 实验结果


5 结束语
猜你喜欢
电脑知识与技术(2021年33期)2021-12-17 00:50:31
铁道通信信号(2020年6期)2020-09-21 09:23:22
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
传感器与微系统(2018年7期)2018-08-29 00:44:18
湘潭大学自然科学学报(2018年2期)2018-05-28 09:04:38
电脑知识与技术(2017年32期)2017-12-15 10:22:23
中国新通信(2017年1期)2017-03-08 03:12:21
信息安全研究(2016年4期)2016-12-01 06:07:05
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29
