
基于自然近邻的自适应关联融合聚类算法
2020-06-18 03:41龚晓峰雒瑞森
计算机工程 2020年6期
李 萍,龚晓峰,雒瑞森
(四川大学 电气信息学院,成都 610065)
0 概述
聚类分析是数据挖掘领域的一个重要分支,其可在无任何先验知识的条件下,用于探索数据之间的内部结构和内在联系从而获取有价值的信息。聚类的过程是通过迭代将数据集划分为多个类簇,并且使类间联系尽可能小、类内联系尽可能大[1]。如今,聚类分析已广泛应用于人工智能、图像处理、模式识别等任务中。
聚类算法一般可分为基于划分的聚类、基于网格的聚类、基于密度的聚类等算法[2-3]。K均值聚类(K-means)算法[4-5]是基于划分聚类的经典算法,通过多次迭代找到最佳数据均值点作为聚类中心,因此异常点和噪声点对聚类中心的影响很大。基于此,文献[6-7]相继提出K-medoids聚类和K-modes聚类算法来寻找最佳聚类中心,改善异常点和噪声点对聚类中心的影响,但其都需要设定初始聚类个数。STING算法[8]是基于网格聚类的代表算法,将数据每个属性的可能值划分成多个相邻区间,从而创建网格单元集合进行聚类,但其也需提前设定聚类个数。基于密度的空间聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法[9]是基于密度聚类的经典算法,该算法能够识别异常点和噪声点,然而需要人工设定两个邻域信息参数(Eps和Minpts),并且对于数据集的密度比较敏感。为解决以上问题,文献[10]提出改进的DBSCAN算法对不同密度层次的数据进行分层聚类,但需要确定近邻数K。文献[11]提出一种新的密度峰值聚类(Density Peaks Clustering,DPC)算法,该算法只需要指定一个截断距离来计算数据集的局部密度,但是聚类中心的选取需要利用决策图进行判断,缺乏可靠性。近些年来,基于图论的谱聚类算法[12]广泛应用于聚类任务中。谱聚类主要通过求解图的最优划分得到最优结果,但是该算法的准确性依赖于其邻接矩阵,基于此,文献[13-14]相继提出改进的谱聚类算法,虽然通过改进邻接矩阵能有效改善聚类效果,但是需要指定聚类数并且无法识别出异常点和噪声点。
由于多数聚类算法需要指定聚类参数,导致聚类结果的准确性受到影响,而自然近邻[15-16]是一种无尺度的最近邻概念,其利用数据集自身的特性进行自然邻居的搜索,通过每个数据点的自然邻居个数来判断其周围的数据分布情况,因此无需人为指定聚类参数。本文利用自然近邻的特性筛选出密度较高的数据作为代表核点进行聚类,从而排除边界点和噪声点对聚类的影响,通过建立簇间的关联度矩阵来寻找具有关联度的簇,并根据簇间融合的有效性评估自适应合并关联度较高的簇,最终得到理想的聚类结果。
1 相关工作
1.1 自然近邻
自然近邻是一种新型的最近邻概念,其属于无尺度最近邻方法的范畴,自然邻居的搜索过程中不需要进行人工的参数设置,而是通过不断扩大自然邻居的搜索范围,使得数据集比较密集的地方自然邻居较多,数据集比较稀疏的地方自然邻居较少。对于一些离群点和噪声点而言,其自然邻居个数相对较少甚至几乎为0。假设存在数据集X,p∈X,q∈X且p≠q,则存在如下定义[17]:
定义1(逆K近邻) 若q在p的K近邻内,则称p属于q的逆K近邻,记为p∈RNNk(q)。
定义2(自然稳定状态) 在自然邻居的搜索过程中,若每个数据点都有逆近邻或者当所有逆邻个数为0的数据不变时,自然邻居搜索达到自然稳定状态。
定义3(自然特征值) 当自然邻居的搜索达到自然稳定状态时,自然邻居的搜索次数称为自然特征值,记作supk。
定义4(自然近邻) 当自然邻居的搜索达到自然稳定状态时,若∀p是q的supk逆近邻,则称p是q的自然邻居,同理,若q是p的supk逆近邻,则称q是p的自然邻居。
自然近邻搜索算法的具体步骤如下:
步骤1初始化搜索次数r=1,自然近邻数nb=∅,逆近邻数RNN=∅。
步骤2计算每个样本p的r近邻、nb(p)及RNN(p)。
步骤3r=r+1。
步骤4当∀q使得RNN(q)≠∅或所有RNN=∅的q值不再变化时,supk=r-1,输出supk、nb和RNN,否则跳转至步骤2。
1.2 自适应关联融合聚类算法
本文通过自然近邻思想寻找数据集中的相对稀疏点和密集点。为去除稀疏的边界点和噪声点信息,本文提出代表核点的概念,即代表核点周围的自然邻居数较多并且其周围分布的自然邻居也多数为代表核点。因此,由代表核点组成的代表核点集能反映数据的集中分布情况,从而体现原数据集的主要数据结构信息。以R15人工数据集为例,通过计算代表核点并去除干扰点,得到如图1所示的主要簇信息,最后将代表核点进行聚类得到初始聚类信息和聚类数。
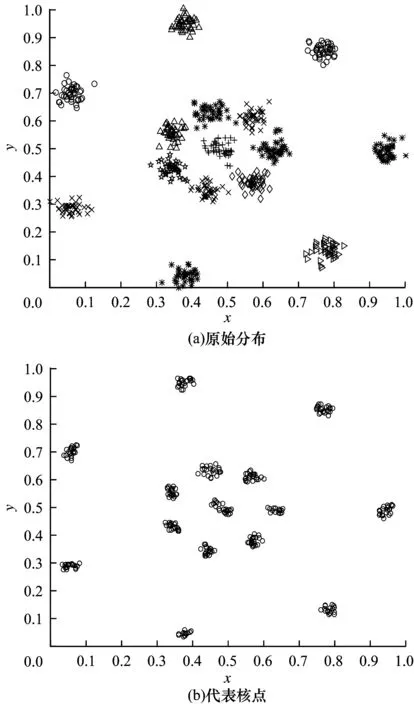
图1 R15人工数据集原始分布及其代表核点
定义5(代表核点) 当自然邻居的搜索达到自然稳定状态时,∀p满足其自然邻居个数nb(p)大于等于自然特征值supk,并且在p的supk范围内满足此条件的数据个数大于不满足该条件的数据个数,则称该点为代表核点。
代表核点的选取虽然能有效移除边界点和噪声点,从而使得边界点和噪声点不会影响数据的聚类,但是由于同簇数据间会存在一些相对稀疏的非边界点数据,该算法可能会将这些相对稀疏的非边界点移除,使得同簇的数据最终聚为两个不同的簇。因此,本文提出关联度矩阵(ccomatrix)的概念。关联度矩阵表示簇间的关联程度,簇间关联度越大,则关联程度越高,当簇间关联度为0时,即不存在关联关系,其数学表达式如下:
(1)
其中,cco_num为簇间数据点的关联个数矩阵,co_dist为簇间代表核点的最短距离,ds为簇间最短距离之和,ns为簇间关联个数之和。
为寻找最佳的关联簇进行融合,本文引入一种几何方法[18]计算簇间的融合信息。簇间的融合度量体现了簇间融合的有效性,本文通过聚类簇的数据特征轴和聚类簇间的距离来评估聚类结果对于簇间分离或融合的有效性。当聚类数据簇间的融合度量(GI)达到最优值时(GI达到最小),此时的聚类数为最佳聚类数。簇间的融合度量可表示为:
(2)
其中,λ表示聚类簇的协方差矩阵的特征根,d表示聚类数据维度,c表示聚类个数,k表示第k类簇,q表示第q类簇,mk表示第k类簇的中心点,mq表示第q类簇的中心点。
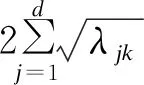
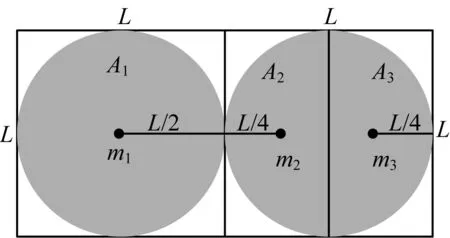
图2 样本分布示意图
本文算法步骤具体如下:
步骤1将数据进行归一化处理,利用自然近邻搜索算法计算自然特征值supk,逆近邻数RNN,自然近邻数nb。
步骤2通过定义5选择代表核点,将互为最大逆邻范围内的代表核点归为一类。
步骤3将最大逆邻范围内包含代表核点的未归类点归为离其最近的代表核点类。
步骤4对于最大逆邻范围内未包含代表核点的未归类点,若在其逆邻范围内包含具有类簇信息的数据点,则将该点归为该类簇,否则判断其为异常点。
步骤5通过式(1)计算簇间的关联度矩阵ccomatrix,选择关联度大于0的值从高到低排序作为数据融合阈值。
步骤6通过式(2)计算从高到低阈值下数据融合的最小GI值,选择最小GI值所对应的聚类数作为最佳聚类数,得到最终的聚类结果。
1.3 算法分析
本文算法主要分为初步聚类和聚类有效性评估两个部分:
第一部分主要是对数据集进行初步聚类,首先利用自然近邻筛选代表核点,再对代表核点集进行初步聚类,最后将一些边界点进行归类,其主要优点如下:
1)在代表核点的筛选过程中,由于自然近邻能寻找每个数据点的自然邻居,其自然邻居数越多,该数据点的位置就越集中,因此可以将自然邻居数少的边界点和噪声点排除,避免代表核点集聚类时将噪声点和具有边界相连的数据簇融合。
2)由于自然近邻算法的自然邻居寻找是通过数据点附近的数据分布特点进行搜索,因此对于不同密度簇的数据集而言,代表核点的筛选不会将整体密度较小的数据簇作为噪声点或边界点排除,只要密度较小的数据簇分布集中,也能筛选出该簇的主要簇信息。
3)对于代表核点的聚类,考虑数据点间的密度分布情况,本文通过对代表核点间的互逆近邻关系进行聚类从而达到一个理想效果,对于非代表核点的分类,主要分为两种情况,即其逆邻范围内存在代表核点和不存在代表核点,将存在代表核点的数据归为最近核点类,而不存在代表核点类的数据,若逆邻范围内无类簇信息,则可证明其远离信息簇,其可能为异常点或噪声点。
第二部分主要是对第一部分的初步聚类效果进行有效性评估。由于初步聚类过程中可能存在同簇间数据连接较稀疏,使得代表核点的筛选过程中将同簇分离,因此本文需要对聚类结果进行评估。该部分首先求出类簇间的关联度,其中关联度越小,类簇间融合的可能性越小,当簇间关联度为0时,说明该簇组无关联,无需考虑融合。为寻找最佳的关联簇进行融合,本文结合关联度信息与簇间融合度量的方法,将关联度以从高到低的类簇进行依次融合并计算其对应的GI值,当GI值达到最小时停止融合。此时的聚类结果可作为最佳聚类结果,可见本文算法在无需设定聚类数的情况下仍能寻找出合适的类簇个数。
2 实验设置与结果分析
2.1 实验参数设置
为验证本文聚类算法的有效性,将其与DBSCAN密度聚类、K-means聚类算法分别在D31、Aggregation、Five_Clusters人工数据集上进行对比验证,其中,K-means聚类算法的聚类个数K选取原始数据集的类簇个数,DBSCAN算法的参数Eps和Minpits选取接近于原始类簇聚类效果的最佳值。
2.2 结果分析
实验最终聚类结果如图3~图5所示,其中的实心圆点为噪声点或异常点。通过原始数据特征可以看出,3种类型的数据集都存在边界值相连的情况并且部分数据簇存在密度分布不均的问题。对于K-means聚类结果而言,由于K-means算法聚类中心选取不当,导致数据集中同簇数据分离成为异簇,异簇数据合并成为同簇。对于DBSCAN聚类结果而言,由于DBSCAN算法参数选取容易将边界相连的两类数据合并为同一簇,大部分边界点和密度较稀疏的点判断为噪声点。本文算法考虑到较稀疏的边界值和噪声点对数据聚类结果的影响,首先使用自然近邻搜索算法在保证密度层次较低的数据簇不被当作边界点或噪声点排除的情况下选取代表核点进行初步聚类,再将一些与类簇有关联的边界点进行归类,而无关联的数据点判定为异常点或孤立点,最后对已聚类的类簇间进行关联度计算排序,按照关联度大小依次计算融合后数据集的GI值,通过寻找最小的GI值使得数据集中本为同簇的类簇合并为一簇,从而找到合适的聚类数。因此,对比K-means算法和DBSCAN算法的聚类结果,本文算法在无需指定聚类个数的条件下,对边界互连和密度层次不同的类簇仍具有比较理想的聚类效果,并且能识别出偏离类簇较远的异常点或噪声点。
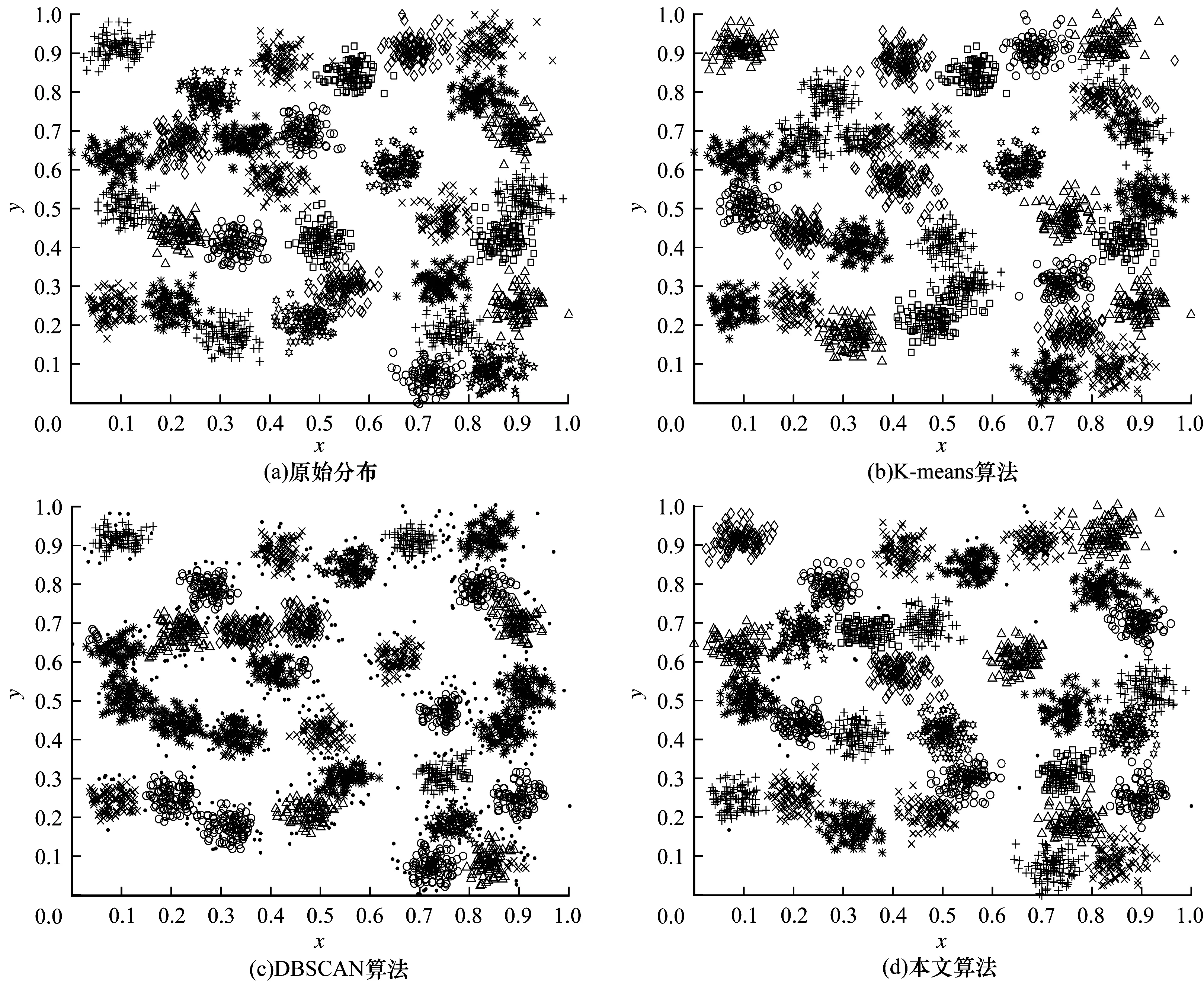
图3 D31人工数据集原始分布及聚类算法效果对比
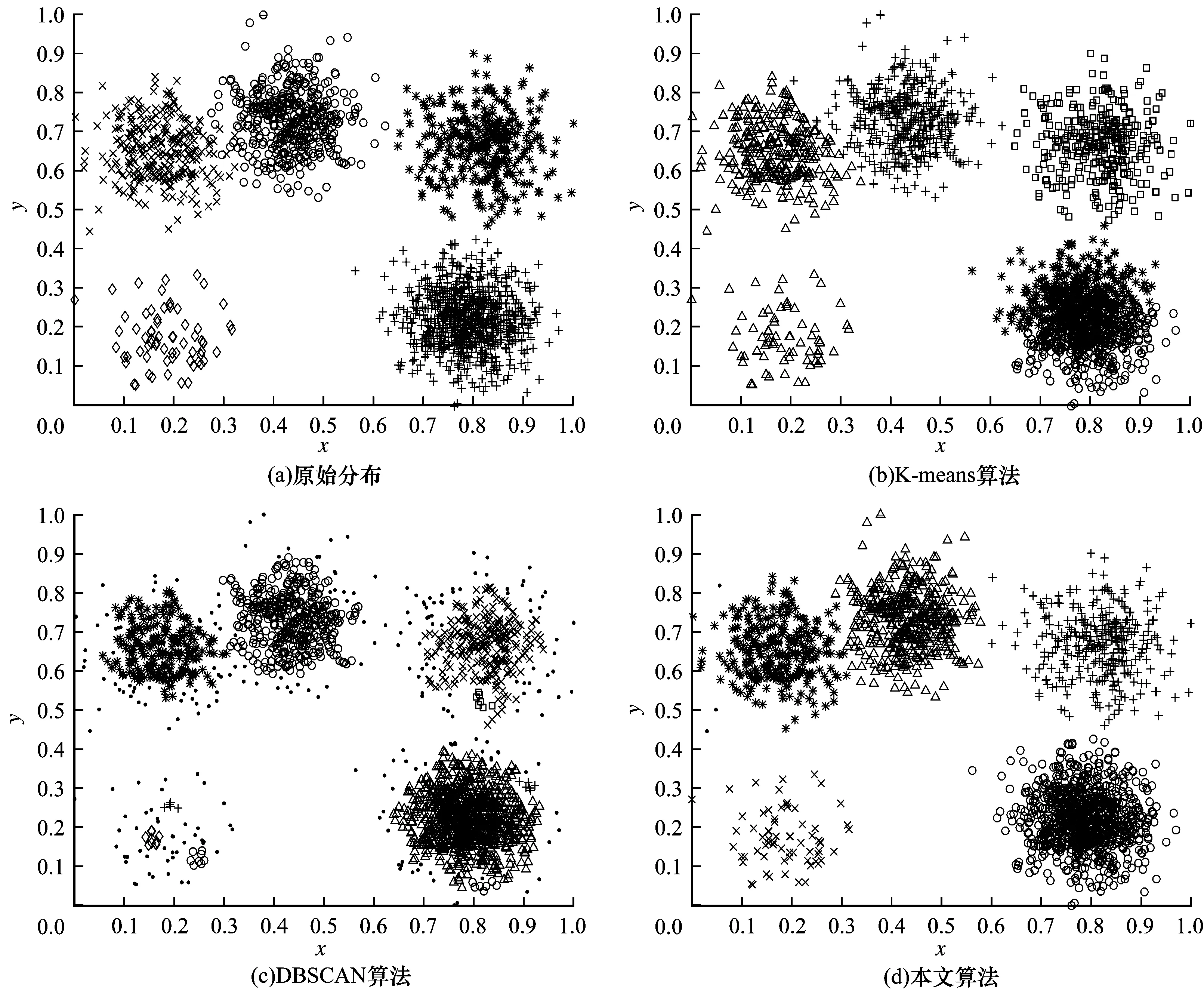
图5 Five_Clusters人工数据集原始分布及聚类算法效果对比
为验证算法的有效性,本文采用准确率[19]和轮廓系数[20]两组指标对这3种聚类算法的聚类结果进行评价。准确率是聚类结果的外部评价指标,其原理是将聚类得到的类标签与原数据的类标签进行对比,并计算出正确分类的样本个数占总样本的比值,准确率的比值越大,则表示聚类的质量越高,准确率的数学表达式如式(3)所示:
(3)
其中,xi表示第i个样本的正确类标号,yi表示聚类计算后得到的第i个样本的类标号,当xi=yi时,δ(xi,yi)=1,否则δ(xi,yi)=0。
轮廓系数是聚类结果的内部评价指标,其衡量了每个样本与其同簇样本间的紧密程度和异簇样本间的分离程度,取值范围为[-1,1],轮廓系数的数学表达式如式(4)所示:
(4)
其中:a(i)表示第i个样本与同簇样本间的平均欧式距离;b(i)表示第i个样本与所有异簇样本间的最小平均欧式距离;S(i)越接近于1,表示第i个样本聚类越具合理性,本文取所有样本的平均轮廓系数作为评价指标。
如表1和表2所示,本文实验分别记录了K-means算法、DBSCAN算法和本文算法在D31、Aggregation、Five_Clusters人工数据集下的聚类准确率和轮廓系数值。对于K-means算法,本文对每个数据集进行100次独立的K-means算法实验,实验的准确率和轮廓系数值取100次重复实验的平均结果。通过对比可知,本文算法的聚类准确率和轮廓系数值在不同数据集上均明显高于K-means算法和DBSCAN算法,验证了本文算法的可靠性。
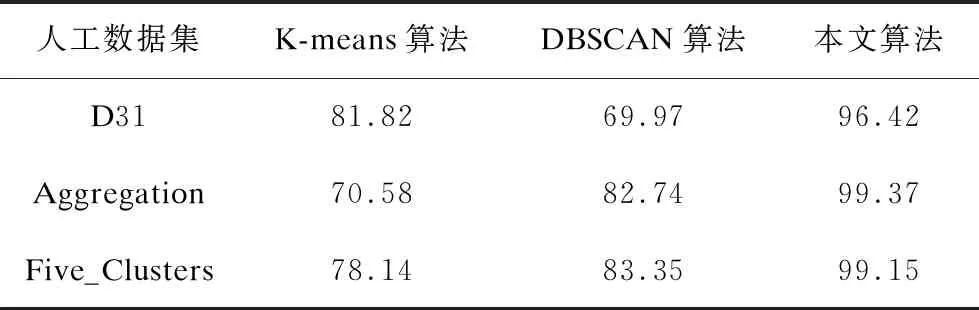
表1 聚类算法准确率比较
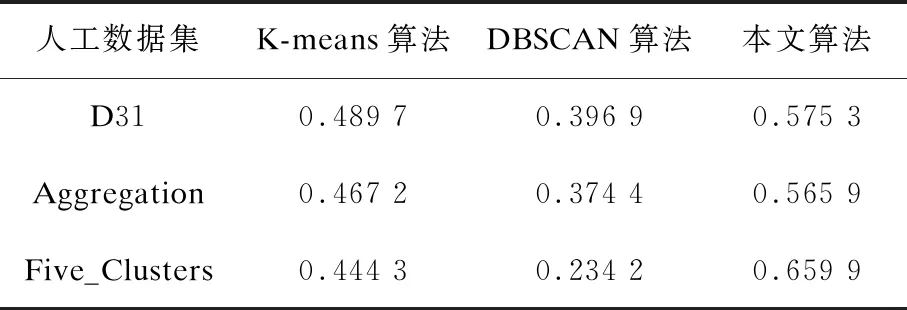
表2 聚类算法轮廓系数比较
3 结束语
本文提出基于自然近邻的自适应关联融合聚类算法,在自然近邻的基础上寻找代表簇结构的核点进行初步聚类,并通过簇间融合度量寻找关联度矩阵中的最优关联度类簇进行融合。实验结果表明,本文算法无需人工设定聚类参数,可以有效处理密度层次不同和簇间相互靠近的类簇,同时能排除异常点和噪声点的干扰。但由于本文算法在多维数据集中的聚类效果不明显,因此后续将对多维数据集的最佳聚类个数确定问题进行研究,进一步提升算法聚类准确率。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
小学生学习指导(低年级)(2018年9期)2018-09-26
考试周刊(2018年74期)2018-08-20
中成药(2018年1期)2018-02-02
郑州大学学报(工学版)(2017年2期)2017-05-18
计算机应用(2016年7期)2016-07-19
