
基于深度可分离卷积的YOLOv3行人检测算法
2020-06-16 10:40王丹峰陈超波马天力李长红苗春雨
计算机应用与软件 2020年6期
王丹峰 陈超波 马天力 李长红 苗春雨
1(西安工业大学电子信息工程学院 陕西 西安 710021)
2(西北机电工程研究所 陕西 咸阳 712099)
0 引 言
随着无人驾驶汽车和智能监控等应用领域的发展,行人检测技术[1]也进入人们视野。行人检测技术是指判断输入视频或图像数据中是否存在行人,并对行人所在位置进行标定。由于经典的行人检测算法依赖手工设计特定的特征算子提取行人特征,导致该类算法泛化能力差无法适应行人的姿态变化,并且计算难度大,限制了该算法在实际领域的应用。近几年来,神经网络在行人检测[2]领域取得突破性成果,是特征学习最有效的方法之一。
基于神经网络的两大类检测算法分别为基于区域选择的方法和基于逻辑回归的方法。基于区域选择的方法主要思路是通过区域预选方法获取目标可能存在区域,再利用卷积神经网络提取特征,最后对目标位置和类别进行预测,主要方法有R-CNN[3]、SPP-Net[4]、Fast R-CNN[5]和Faster R-CNN[6]等。R-CNN利用选择性搜索方法[7](Selective Search)获取目标预选区域,再将各区域统一尺寸并送入CNN网络[8]提取其特征,最后使用多个支持向量机[9]分类器对提取特征进行分类并且通过逻辑回归获取目标位置,相比传统算法性能有了较大改善,但是其存在大量的冗余计算,训练复杂度高,并且由于预选区域尺寸需要调整,导致部分特征信息丢失。SPP-Net在R-CNN的基础上增添了SSP层,能够使任意尺寸的预选区域变成统一大小的特征向量,消除了预选区域形变过程导致的特征信息损失,但是其特征提取和SVM分类网络的单独训练,增加了网络训练复杂度。Ross Girshick提出了Fast R-CNN算法,该算法结合SPP-Net思想改进R-CNN,将输入数据只进行一次特征提取,通过映射关系获取预选区域的特征信息,并且同时训练整个网络以更新网络结构参数。虽然Fast R-CNN消除了SPP-Net中训练复杂的问题,但是Selective Search导致算法速率较慢,预选区域质量较差。Faster R-CNN使用基于CNN的区域建议网络(Region Proposal Networks,RPN)代替Selective Search获取预选区域,CNN提取的深度特征信息保证了预选区域的质量,同时RPN的使用提高了检测速率。
基于逻辑回归的检测方法主要思路是去除区域建议环节,利用设置默认的锚框获取预选区域,并直接对锚框中物体的位置和类别进行预测,代表性方法有YOLO[10]、SSD[11]、YOLOv2[12]和YOLOv3[13]。YOLO是基于回归思想的网络模型,实现了模型的端到端的训练并且速率较快,但是其对训练集中不存在的目标尺度鲁棒性差使得检测精确率降低。SSD采用特征融合的思想将低层结构信息和高层语义信息融合,提高了目标检测精确率。YOLOv2与YOLO相比,采用anchor box[14]机制在保证分类精度不变的情况下,提高物体定位精度,同时增加Batch Normalization[15]层简化模型训练难度和使用多尺度训练策略提高模型的鲁棒性。YOLOv3结合残差结构[16]改进YOLOv2模型构成Darknet53分类网络,并使用3个尺度特征图进行预测目标类别和位置,达到了速率和准确率的平衡,但是模型参数量和计算量较大,并由于使用单一卷积核进行特征提取导致特征信息缺乏泛化性,导致训练难度大、速率慢、准确率低和漏检等问题。
本文在YOLOv3模型框架基础上,使用参数量和计算复杂度低的深度可分离卷积替代标准卷积操作,利用Inception结构增加网络宽度和复杂度,提出了基于深度可分离卷积的YOLOv3行人检测算法。最后在VOC2007数据集训练和测试,并通过不同算法效果比较对该算法进行评价。
1 相关工作
1.1 YOLOv3及其他改进方法
YOLOv3检测方法是目标检测领域最有效的算法之一,YOLOv3算法融合了GoogleNet网络横向特征拼接的思想,网络结构如图1所示。
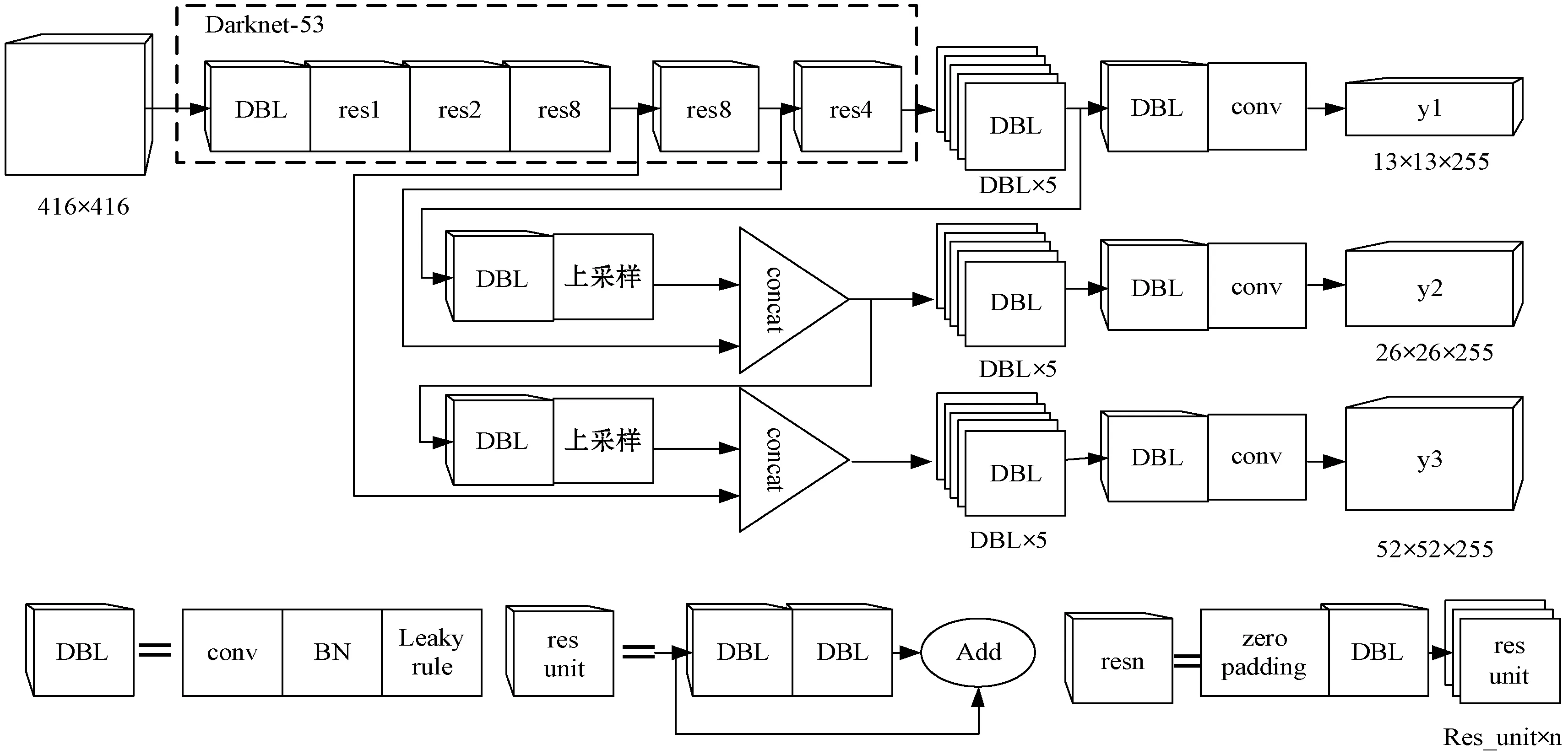
图1 YOLOv3网络结构图
YOLOv3网络结构可分为分类网络和检测网络两个部分。分类网络是使用残差网络构成一个含有53个卷积层的Darknet53网络,该网络能够提取更深层次的语义信息,对图像进行更精确的分类;检测网络是在Darknet53分类网络基础上实现目标检测的网络结构,其采用FPN(Feature Pyramid Networks for Object Detection)[17]方法对3个不同尺度的特征图进行检测,实现多尺度检测。
YOLOv3模型输入为416×416的图像数据,通过分类网络和检测网络的卷积操作将输入划分为S×S的网格,每个网格使用3个锚框对其中的目标进行预测,输出为S×S×3×(5+C)。其中包含检测框的中心坐标和宽高的4个值和置信度值,S是划分的网格数量,C是类别数量。最后使用非极大抑制[18]确定图中目标最终的坐标信息和类别的预测值。
基于密集连接的YOLOv3算法在原算法基础上进行改进,如图2所示。该算法将网络结构简化为Darknet49,用于单类物体检测;再利用4个不同尺度的特征图进行检测,在增加的104×104的特征图中使用更精确地锚框,提高算法对小目标的检测精度;最后结合密集连接的思想,将不同尺度特征图通过上采样方式互相融合,提高网络对各层级特征信息的利用。因此该检测算法更适用于特征像素较少的目标。

图2 密集连接的多尺度检测
1.2 深度可分离卷积
深度可分离卷积(Depth-wise Separable Convolution,DSC)[18]是将标准卷积结构进行拆分的产物。标准卷积结构(图3(a))是将输入数据的每个通道与一个特定卷积核实行卷积操作,并将各通道的卷积结果相加的过程。在深度可分离卷积结构中(图3(b)),输入数据的各通道进行深度卷积操作,再使用点卷积线性连接深度卷积的输出。该网络结构能够极大降低模型参数量以及计算量,从而在检测精度没有明显变化的情况下,提高检测速率。设输入数据为M×M×N,卷积核为K×K×P,并且步长为1时,标准卷积参数量为:
WSC=K×K×N×P
(1)
且对应的计算量为:
OSC=M×M×K×K×N×P
(2)
深度可分离卷积的参数量为:
WDSC=K×K×N+N×P
(3)
且对应的计算量为:
ODSC=M×M×K×K×N+M×M×N×P
(4)
因此,两种结构对应参数量和计算量的比分别为:
(5)
(6)

(a) 标准卷积
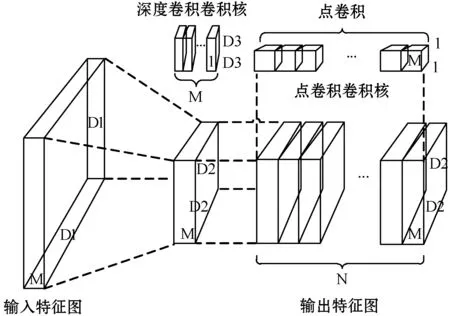
(b) 深度可分离卷积
1.3 Inception结构
Inception是对不同大小卷积核卷积结果进行拼接的一种结构,如图4所示。主要使用1×1卷积对输入实现降维,再利用3×3和5×5卷积核对特征图提取不同尺寸的特征信息。该模块在不增加计算量的条件下,增强网络结构复杂度,便于提取更为丰富的特征用于检测。而且该网络能够降低参数量,有利于防止过拟合问题。

图4 Inception结构
2 行人检测算法
2.1 基于深度可分离卷积的残差结构
YOLOv3中使用Darknet53作为分类网络,虽然Darknet53利用残差结构增加网络结构的复杂度以提取更高层的语义信息用于提升目标检测精度,同时,大量运用1×1卷积核降低输出维度以减少3×3卷积过程中的参数量,但是在实时行人检测中,标准卷积操作会产生大量参数,使得网络训练难度增加并且检测速率降低。
为了提高行人检测的速率和降低网络训练难度,本文使用一种参数量少并且计算复杂度低的深度可分离卷积对残差结构进行改进,用于提取输入数据特征。
本文提出的基于深度可分离卷积的残差结构如图5所示。第一个DBL模块运用1×1卷积核提高输入特征图维度,并将其作为输入进行步长为2的深度可分离卷积操作;然后利用1×1卷积层将上一层输出线性连接,同时使用线性激活函数降低对特征信息的损坏;接着执行步长为1深度可分离卷积和线性激活的1×1卷积层;最后将第一个线性激活和第二个线性激活的输出执行相加操作作为输出。

图5 基于深度可分离卷积残差结构
2.2 横向卷积扩展
尽管残差网络可以避免由于卷积层数增加导致的梯度爆炸问题,但是随着网络深度的提升会增添大量的训练参数,加剧端到端网络的反向传播难度,所以不能通过扩张网络深度增加网络复杂度。同时由于YOLOv3目标检测算法网络结构中只有单一的3×3卷积层对输入进行特征提取,导致网络只能够提取一种尺寸的信息从而降低检测算法的精度。因此,本文提出一种利用Inception结构改进YOLOv3的检测网络的方法,通过扩展检测算法网络的宽度和运用不同尺寸的卷积核来增加网络复杂度,以提高检测精度。
本文利用Inception结构对检测网络中的5个DBL模块进行了改进,如图6所示。第一、三、五层同样使用1×1DBL模块对输入进行降维操作;在第二、四层使用Inception结构提取输入数据的特征,在3×3和5×5卷积操作的分支中都存在1×1的降维卷积层,因此使得网络在不明显增加参数量和计算量的前提下,提高算法精确度。

图6 基于Inception结构的DBL模块
3 实 验
基于深度可分离卷积的YOLOv3行人检测算法的实验是使用Python语言在开源的Darknet深度学习框架下进行的,电脑搭载I7处理器、16 GB RAM和RTX2080显卡的配置以及Ubuntu操作系统。
3.1 数据集介绍
本文使用VOC2007数据集进行行人检测实验。由于VOC2007数据集中有20种类别的标签信息,因此通过数据清洗只保留person类别的标签信息,并将清洗后的数据分为训练集、验证集和测试集。表1为VOC2007数据集中person类别的数量。

表1 VOC2007数据集中行人数量
3.2 训练过程与结果
本文对基于深度可分离卷积的YOLOv3模型进行训练。在训练过程中,反向传播阶段使用Gradient Descent进行优化,batch-size设为8,动量值为0.9,权重衰减设为0.005,设置学习率初始值为0.000 1,并通过学习率检测机制调整学习率大小,epoch设为50,每3个epoch保存一次模型并且保存最后一次模型,最终选取loss最低的模型用于检测。
图7为模型训练过程中损失函数值的曲线图,可以看出,在前10次学习训练集时,由于权重初始化为随机值使得loss迅速下降;在后40次中对表达行人特征的权重进行微调,loss缓慢下降并最终趋于稳定,最小值为4.96。从收敛曲线来看,网络模型训练已达到预期效果。

图7 损失函数曲线图
3.3 实验结果
本实验将精确度(AP)和每秒处理帧数(FPS)作为所提模型的评价指标。精确度计算公式为:
(7)
式中:TP是真正标签;FP是假正标签。
用VOC2007测试集验证所提模型对行人的检测效果,部分测试集图像检测结果如图8所示。可以看出,本文算法能够对测试集中的行人精确地识别并且定位。

图8 基于深度可分离卷积的YOLOv3检测结果图
3.4 结果分析
本文将Faster R-CNN、SSD300、SSD512、YOLOv3和基于深度可分离卷积的YOLOv3算法在VOC2007数据集上实行训练与测试,并得到FPS、精确率、参数量和计算量等技术指标,如表2所示。可以看出,本文算法精确率达90.3%,并且由于计算复杂度的降低,实现了65.34帧/s的检测速率。

表2 不同方法技术指标对比
表2中Faster R-CNN算法获得了79.1%的精确率,比本文改进YOLOv3算法低11.2%;在检测速率方面该算法仅有13.56帧/s,与本文所提算法相差很大,并未达到实时检测的标准。
SSD300和SSD512是基于高斯金字塔结构的检测算法。SSD300算法的精确率为75.5%,检测速率为59.34帧/s。对于SSD512算法,由于该算法增大输入数据尺寸获得更多的目标描述信息,并且增加了网络计算复杂度,使得该算法相比SSD300算法精确率提高4.7%,速率降低为28.89帧/s,两者与本文改进YOLOv3算法相比均没有明显优势。
YOLOv3、密集连接改进算法和本文算法是基于回归思想的检测算法。在检测精度方面,由于本文算法在检测网络中应用Inception结构,提取了更加丰富的特征信息用于目标检测,因而精确率比原YOLOv3模型和密集连接分别高6.7%和2.2%;在检测速率方面,因本文算法使用深度可分离卷积代替YOLOv3中的标准卷积,使得参数量和计算量分别降低为95×106和24.22×109,以至检测速率比原YOLOv3模型和密集连接分别高16.64帧/s和12.03帧/s。从以上分析中可以看出,本文提出的基于深度可分离卷积的YOLOv3行人检测算法相比YOLOv3具有更好的精度和检测速率;相比于基于密集连接改进算法,在检测速率上具有明显优势。
图9显示了YOLOv3、基于密集连接的改进算法和基于深度可分离卷积的YOLOv3行人检测算法对相同图像数据的检测结果。可以发现,在发生遮挡情况下,本文算法可以更好地将遮挡部分的行人准确检测。另外,本文算法和基于密集连接的改进算法对特征像素较少的目标都有很好的检测效果。

(a) YOLOv3

(b) 基于密集连接的YOLOv3

(c) 基于深度可分离卷积的YOLOv3
4 结 语
本文提出了基于深度可分离卷积的YOLOv3行人实时检测算法,使用深度可分离卷积取代Darknet网络中的标准卷积,减少了参数量和计算量,从而提高了检测速率和降低了模型训练复杂度;同时,该算法将Inception结构融入检测网络,提高了网络结构复杂度和行人检测精度。在VOC2007数据集上实验得出,该算法的运行速率达到65.34帧/s,精确度为90.3%。下一步将对Darknet53网络中残差结构与Inception结构进行结合,提高行人检测准确度。
猜你喜欢
社会科学战线(2022年2期)2022-03-16
意林(2021年5期)2021-04-18
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中学化学(2016年10期)2017-01-07
中学化学(2015年8期)2015-12-29
祝您健康(1985年1期)1985-12-29
