
不确定环境下融合语义的无人机编队协同控制研究
2020-06-16 10:40戚茜
计算机应用与软件 2020年6期
戚 茜
(西北工业大学航海学院 陕西 西安 710072)
0 引 言
无人机编队作业可以完成单个无人机难以胜任的复杂任务,在地质勘测、应急救援、情报侦察、航海情景探测、文艺表演等领域应用广泛[1]。无人机编队在高空环境下受到气象状况、地理空间信息及通信系统状态等不确定性因素影响,随着编队规模以及编队重构复杂性的增长,无人机编队飞行轨迹和成员位置较难被描述和预测。求解不确定环境下智能体编队协同控制问题的传统方法一般从整体角度出发[2],对系统中所有成员进行统一建模,建立编队控制系统,通过协调并行的方式求解整体控制决策问题,进而将已求解的结果分配给个体成员,这种方法可以较好地解决系统的稳定性,但随着无人机数量的增加容易形成空间连续最优求解问题[3]。解决这类问题的方法大都采用基于多Agent的控制模型[4],通过竞争与合作的方法解决编队成员之间的协同行为,从而规划无人机系统的一致性和整体性,但这种方法会使信息共享机制在不确定因素影响下受到阻碍,使系统成员的差异性更加突出。
针对信息输入的不确定性和动态变化性,学者们提出了许多方法。文献[5]在基于贝叶斯框架的基础上提出基于狼群优化的无人机协同优化控制系统,融合贝叶斯概网络和值函数推理不确定信息的输入,实现最佳轨迹规划功能。文献[6]采用蚁群算法研究无人机编队在最小时间内搜索丢失目标问题,在不确定环境下重构编队的轨迹形成和关键点可达。文献[7]模拟蝗虫响应内外部动力的自主力和弹性行为研究无人机编队的任务分配问题,通过成员间运行状态和任务参数动态调整平均完成时间及持续稳定性能。文献[8]在考虑外界环境因素情形下,建立无人机纵向动力学模型和非定常气动力模型,并对编队速度、平尾偏角、矢量舵偏角及俯仰等进行特征分析,实现编队构建和重构控制的方法。文献[9]针对无人机编队飞行过程中的突风及客观因素的影响,设计了一种基于莱维飞行鸽群优化的仿雁群无人机编队控制器,以增加作战半径。以上方法较好地解决了不确定信息处理在编队控制的问题,但回避了对不确定抽象信息实体的语义建模,缺乏无人机计算更容易理解的语义知识,在一定程度上影响无人机系统对外部信息的有效识别。
综合考虑以上问题,从信息处理的角度出发提出了一种融合语义的无人机编队协同控制方法。该方法构建了一个具有不确定态势检测、不确定行为识别和语义策略本体模型的编队协同控制框架;在此框架的基础上,利用本体和贝叶斯网络推理实现态势检测,提出基于个体激活期望值的强化学习方法,将学习到的知识迁移到相似新任务中,更新语义本体模型;采用netlogo仿真平台验证本文方法的有效性。
1 协同控制模型
1.1 协同控制框架
针对无人机编队在不确定环境下行为控制的背景约束和信息感知过程中不确定数据的流向特点,将协同控制框架分为不确定态势检测模块、不确定行为识别模块和语义策略本体模型。
不确定态势检测模块可以计算各类事件发生的概率,结合语义策略本体模型触发基于贝叶斯网络推理的态势检测,其功能主要包括环境感知模块、任务执行检测模块和系统状态检测模块。环境感知模块用于检测影响当前无人机编队行为控制的周边环境信息;任务执行模块用于检测无人机编队任务规划执行情况;系统状态模块用于检测无人机系统的引擎控制、位置控制、姿态控制等状态。
不确定行为识别模块用于分析不确定检测模型所检测到的信息,通过基于个体激活期望值的强化学习方法,将该状态下学习到的知识迁移到相似新任务中,并更新不确定任务本体模型。
语义策略本体模型是一种基于OWL[10]的知识库,用于存储具有语义功能的地图、环境、任务和状态,其功能包括规则推理、行为任务更新、实时维护等。如图1所示,它是整个协同控制系统的底层框架。

图1 无人机编队协同控制框架
无人机编队通过传感器获得的外部不确定信息进行感知,生成不确定行为发生的概率和对行为控制的影响,并与策略规划知识共同作为语义本体模型信息,为无人机行为识别模块提供统一的规范化数据支持;感知行为、系统状态和任务策略共同触发协同控制条件;可视化界面用于操作人员与无人机之间的实时交互,更好地判断无人机协同控制的系统状态和参数信息;本体作为知识形式化表示的工具,能够为背景知识提供有效的概念和实例描述,实现融合语义的协同控制服务。
1.2 语义策略本体模型实现
语义策略本体的建模过程为:通过获取传感器的原始信息,生成无人机编队环境感知本体、任务执行本体和系统状态本体,构建相关概念、属性、实例。模型如图2所示。

图2 语义策略本体模型
语义策略本体模型中,行为状态本体描述无人机系统状态,包括引擎状态、位置状态、姿态调整、速度调整等,通过实例关系获取动力学模型中的平尾偏角、矢量舵偏角及俯仰角、中心角等参数;环境本体是由传感器及可视化地理信息系统结合所获取的数据,主要针对地理环境的概念、实例和关系,包括气象环境、地图概念,其实例包含了从点、线、面到复杂地图的环境现象的数据;任务策略本体针对当前用户指令智能判断飞行策略,包括GPS导航、地图搜索、飞行障碍物、飞行关键点、飞行目标点等实例。
2 基于本体推理的态势检测方法
2.1 本体推理机制
通过Apache Jena API[11]获取所有语义策略本体中的相关概念和实例,将基于OWL的语义策略本体模型转化为贝叶斯网络图结构,利用贝叶斯推理将检测到的信息进行综合分析,生成可识别的数据交换格式,其代码片段如下:
< MotorControl rdf : ID=“MotorControl _1”/>
< propulsion rdf: ID=“propulsion_1”>
< filtering rdf: ID=“filtering_1”>
其中:MotorControl_1表示单个无人机引擎状态的实例,propulsion_1表示当前状态推进力正常系数,0.855为正常系数概率;AttitudeControl_1表示姿态可达的实例,filtering表示卡尔曼滤波观测数据,0.519为当前系统的噪声影响因素;PositionControl表示当前系统的位置,Collocation表示共位参数,0.365表示位置共位的参数量值;Situation_1表示当前时刻的态势信息,0.736表示三种控制对感知的影响程度。
对于上述数据格式片段,设无人机A1的状态推进系数propulsion_1借助自定义规则connect_fact连接与其关联的无人机A2,生成一个扩展事实库con_link。
String rule=“Construct{?p:relatesTo:Cryptography}
Where ”+“{{: propulsion_1?p: propulsion_2}union{: propulsion_2?p: propulsion_1}}” %将具有相连关系的事件逐项存储
Repository repo=new SailRepository(new CustomGraphQueryInferencer(new MemoryStore(),QueryLanguage.SPARQL,rule, “”))
其中:con_link描述了将OWL文件转化单个无人机在一个状态参数下的关系,通过Jena推理引擎遍历所有结点,对于简单的事件则采用规则性推理,Jena推理引擎可以较好保证语义策略本体的完备性和有效性。而针对多无人机协同控制中的差异性和复杂性问题,则采用带有条件概率分布的贝叶斯网络的推理方法。
2.2 基于贝叶斯网络的推理方法
贝叶斯网络系统的主要功能是对语义策略本体的概念和实例进行解析,通过构建规则生成节点、边和条件概率表,其步骤为:
第一步采用拉普拉斯平滑方法对检测到的当前事件数据进行预处理,通过Jena API从任务策略本体中选择与预处理后的当前事件相匹配的概念节点x。
第二步根据获取的信息更新扩展该节点为x=(x1,x2,…,xn)并生成父节点C,
第三步通过OWL的实例关系生成因果关系边,并形成条件概率分布文件(Conditional Probability Distribution, CPD),如表1所示。

表1 条件概率分布表
由表1可知,Filtering存在f0、f1和 f2三种取值情况,即系统噪声的卡尔曼滤波观测值在完备、适合和不适合三种情况下影响多个无人机姿态可达、一般适应、不可达三种结果;Collocation存在c0、c1和 c2三种取值情况,即共位参数在基于0.500的中间值影响多个无人机节点的位置,并使得无人机有影响较高、一般和较低三种结果。同理,Propulsion代表无人机推进力影响因素的结果。采用贝叶斯网络对不确定的感知信息进行检测,网络中的结点代表感知的不确定信息对当前任务和状态的影响程度,对于当前不确定信息的集合,采用贝叶斯网络的方法可以检测出当前事件的概率,并更新语义策略本体模型。
3 基于个体激活期望的强化学习
为识别行为检测模块所检测到的不确定性数据,使编队不断地向成员发送队形变换及周边信息,更新当前行为状态,提出基于个体激活期望值的强化学习方法。基本思路是将当前无人机编队系统作为学习网络Ginti,语义策略本体模型作为指导网络S,单个无人机成员作为Ginti中的一个结点,通过结点和边对系统的期望值生成关于Ginti的最大化期望网络Gmax,并强制学习指导网络S在每个状态下的行为,最后将学习到的知识迁移到相似的新任务中,实时更新具有概率扩展的指导网络S。
3.1 个体激活期望值计算
设任意一台无人机的期望位置的阈值向量为δv,每台无人机为学习网络Ginti中的一个结点,根据结点间的激活期望估算和贝叶斯网络中的联合分布概率的权重计算最大化期望程度。
定义1(边激活期望值计算):设v为无人机学习网络Ginti中任意处于未激活的单个无人机结点。IN(v)为v的处于激活状态的入邻居结点集合。设u是v的任意处于未激活的入结点。则结点u通过边e(u,v)对v的期望值计算记为GH(u,v):
(1)

定义2(结点激活期望值计算):设OUT(v)为结点v的出边邻居集合,v的l步期望贡献值为GHl(v)(l≥2),计算为:
(2)
3.2 强化学习方法
当网络中结点和边激活,得到了最大期望程度的网络Gmax={G1,G2,…,GN}后,可以通过输出Q值波尔兹曼分布将指导网络S={S1,S2,…,SN},即本体网络转换成为一个策略网络。
(3)
式中:τ表示影响因子,ASi表示指导网络Si的动作空间,对于最大期望网络Gmax中的每一个状态,根据学习网络策略和指导网络策略之间的交叉熵定义一个策略回归目标函数。
(4)
式中:πAMN(a|Gmax;θ)表示用于指导当前学习网络Gmax的行为,指导网络的输出策略为一个稳定的监督训练信号,不断指导当前网络的行为向指导网络的行为靠拢。
3.3 算法实现
输入:网络Ginti(V,E),关联初始化集合长度k
输出:更新后的语义策略本体S和Gmax
1.由随机期望阈值向量δ确定网路实例g(v,e(u,v))∈G,Gmax←φ
2.for eachg∈Gdo
3.以g作为任意一个初始化待被期望激活的集合,对于g中每一个结点v∈V,从贝叶斯概率分布表中获取其入边权重wu,v。
4.end for
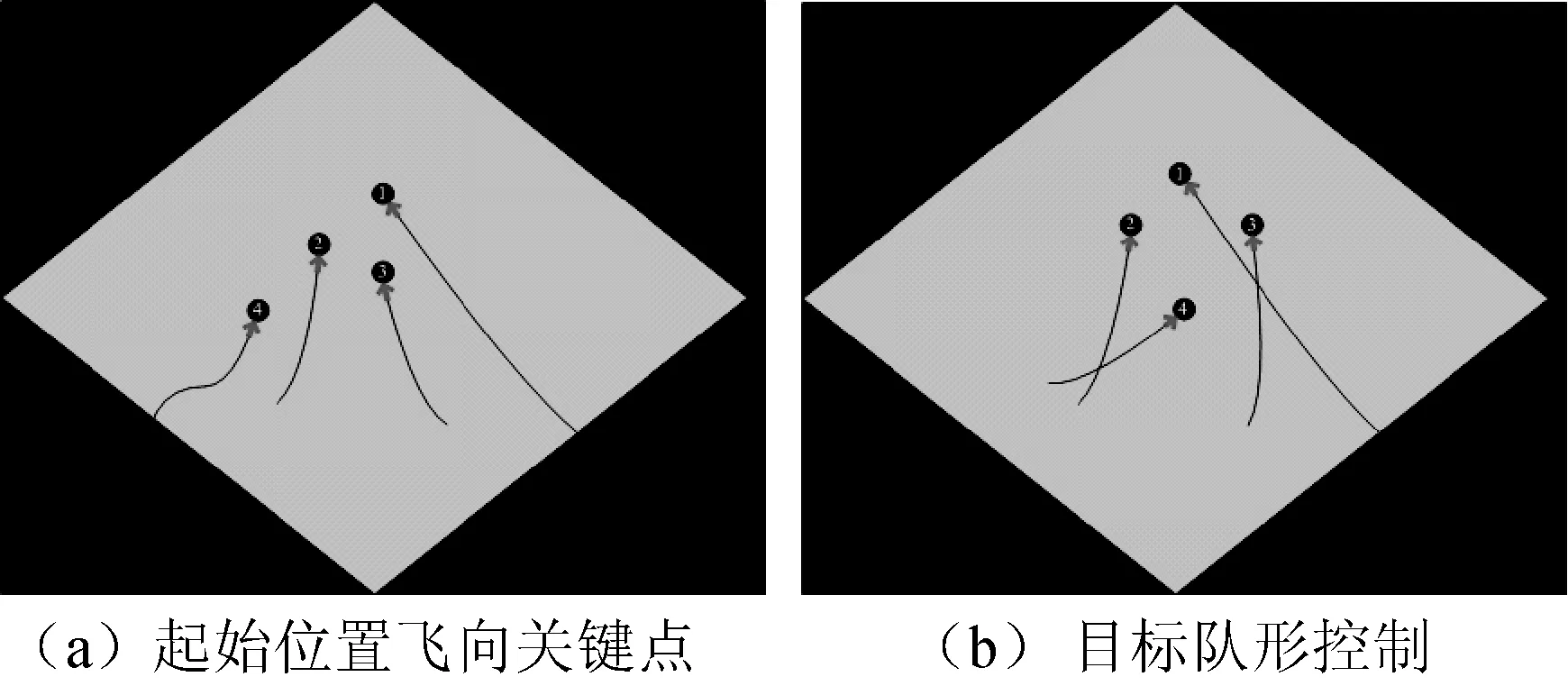
5.while(|gi| 6.通过式(1)计算边激活期望值GH(u,v) 7.通过式(2)计算结点激活期望值GHl(v) 8.end for 9.forv∈Vdo 11.end for 12.v←argmaxv∈V/SiEGH(v) 获取最大期望结点 13.Gmax←Gmax∪{v}求解最大期望网络Gmax 14. end while 15.通过式(3)将指导网络S转换成策略网络 16.求解策略回归目标函数式(4) 17.更新当前的任务策略本体模型S 18.returnS,Gmax 以上算法首先随机选择未被期望激活的结点v1,当步长l=2时,根据式(1)和式(2)可得GH2(v1)=0.347,GH2(v2)=1.252,GH2(v3)=0.548,GH2(v4)=0.378,GH2(v5)=0.195,此时选取激活期望值最大的结点v2作为激活期望结点,由于v2对v3和v4具有影响,当v2激活后,其指向v3和v4的有向边激活期望值发生了改变。因此重新计算这些边和未激活结点的期望值,并取期望值最大的结点作为激活结点,形成一个最大期望网络Gmax。最后,通过式(3)和式(4),求解策略回归目标函数,更新当前的任务本体S。 仿真实验在netlogo平台上验证所提出方法的有效性,应用4台无人机在高度为200米,背景在不确定海洋环境下,增加风雨状态进行仿真,仿真时间为60秒,每隔采样周期为5秒。 实验数据来源于某船舶自动识别系统(Automatic identification System , AIS),由岸基设备和船载设备数据构成,包括风雨场景的各项已有真实数据。与真实场景相比其区别在于该实验可以对场景进行随机布置,减少实验平衡状态的仿真时间。实验中,由于网络中存在数据不平衡等问题,应对超出预测范围的特征干扰,即策略本体库中没有出现的实例,直接采用随机方式会严重影响控制效果。为此,采用拉普拉斯平滑方法对检测到的当前事件数据进行预处理。另外,为提高仿真实验的实用性和合理性,消除数据检测随机误差的影响,实验重复10次后取平均值作为最终结果。 4台无人机初始位置随机设置,每台无人机接收到飞行信息后,根据设定的目标关键点进行期望位置飞行。图3(a)中4台无人机从任意位置开始,由语义策略本体引导成员向目标关键点飞行,通过传感器获取不确定信息进行感知,生成行为发生的概率为行为识别提供统一格式的数据。图3(b)中的箭头即为个体成员激活期望值所生成的期望方向,并最终形成一个菱形编队,实现关键目标点可达的效果。 图3 编队控制过程 由图4(a)可知,通过融合语义的编队协同控制方法,4台无人机相对距离误差逐渐减小。在25秒之前,无人机1保持飞行速度大于无人机2、3、4的状态;直到25秒后,4台无人机系统趋于稳定,同时以相同的姿态和位置渐进飞行。图4(b)进一步描述了编队成员之间变化情况,任意两台无人机成员之间的距离能够快速收敛并趋于稳定值,且形成菱形编队稳定距离值。这是由于当编队系统在生成OWL语义策略本体后实时转化为贝叶斯网络分析判断编队运行状态,并对整个系统的协作状态进行触发纠正。在实际工程应用中,当1台无人机飞行状态因外界或内部因素偏离时,通过结点和边激活期望值的计算激活当前成员,强制学习当前指导网络的期望目标,并实时更新语义策略本体的实例库。 (a) 各机与目标关键点距离 (b) 各机之间的距离 如图5所示,无人机编队可以有效规避障碍威胁,并且飞行轨迹弯曲较小、过渡平滑,成员之间操作灵活,等障碍物解除后,又迅速恢复到原有编队形态。这是因为感知的不确定信息经过贝叶斯网络的推理及个体期望贡献强化学习算法应用,更新了具有概率扩展的语义策略本体,可以在较短的时间内检测不确定数据,实现障碍物规避并保持编队飞行控制的稳定性。表2给出了不确定环境下编队协同控制输出结果。 图5 无人机编队障碍物规避控制 表2 不确定环境下无人机编队协同控制输出结果 表2显示系统的关键目标点是否可达事件在第60秒开始发生,v3、v1结点的无人机发生关键点不可达的概率为0.46,经过本文方法计算GH值形成一个最大期望网络并更新本体模型。同时,从工程实用性角度来说,本文算法每隔5秒获取一次输出结果,对于相似的任务可以由任务策略本体直接触发,从而减少计算量,保证数据的合理性和科学性。 采用代价函数(Cost Function)[13]进一步说明无人机编队协同控制性能,它是通过进化曲线测量无人机编队协同控制性能的重要指标。将本文方法与鸽群算法[14-15]、multi-agent算法[3]进行比较,结果如图6所示。由图6可以发现本文方法收敛速度较快,在第6代时达到了收敛,得到最优的目标解。这是由于在个体激活期望值计算时,学习网络策略和指导网络策略之间的交叉嫡定义了策略回归目标函数,输出了一个稳定的监督训练信号,各个体之间可以在工程实际应用中趋于稳定一致的状态;而鸽群算法在第30代才达到收敛稳定,没有本文方法效果好;multi-angent算法系统性地解决了局部最优的问题,但随着迭代次数的增加陷入了不稳定状态。 图6 基于代价函数的编队控制进化曲线 本文针对无人机编队感知行为、系统状态和任务规划等不确定性问题,从信息处理的角度出发提出了一种具有不确定环境检测、不确定行为识别和语义策略本体模型的无人机编队协同控制框架,实现了基于本体推理的态势检测方法和基于个体激活期望值的强化学习方法。该方法不仅可以使任意两台无人机相对距离收敛稳定,还可以判断关键点可达和障碍物规避,对于复杂海洋环境下的目标搜索、抢险救援有着重要意义。下一步将考虑更多无人机数量进行仿真,进一步优化无人机网络的学习算法,结合云计算和大数据平台优化编队控制性能,以提高协同控制的效率。
4 仿真结果与分析
4.1 关键点可达控制分析


4.2 障碍物规避控制


4.3 比较分析

5 结 语
猜你喜欢
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
中国航海(2019年2期)2019-07-24
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
数学学习与研究(2017年10期)2017-06-22
课程教育研究·学法教法研究(2016年19期)2016-09-07
中学课程辅导·教师教育(中)(2016年6期)2016-07-02
作文新天地(初中版)(2009年4期)2009-05-26
