
基于Scrapy的电商数据分析系统设计与实现
2020-06-13 07:43:26李依潼王骥任肖丽
电子技术与软件工程 2020年2期
文/李依潼 王骥 任肖丽
(广东海洋大学电子与信息工程学院 广东省湛江市 524088)
1 引言
电子商务的兴起促进了商业模式变革,物联网、云计算的出现推动信息爆发式增长,这是电商时代,亦是大数据时代,如何利用海量信息产生更多效益,成为商业竞争的核心[1][2]。获取有效数据是大数据研究的重点,网络爬虫技术是获取互联网海量数据的关键手段之一。
网络爬虫是对不同网页进行下载和分析,经过存储、相关度计算、排序,再将关键词展现到用户面前[1]。本文以爬取京东购物网站网页数据为例,设计一个基于Scrapy框架的数据分析系统。在Python 3.7编程语言的Scrapy框架下搭建Web爬虫,爬取京东网站搜索结果前两页商品信息、总体评价和每件商品前20页评论,然后采用MongoDB实现持久化数据存储,再利用Python生态的Numpy、Pandas数据处理工具包对数据进行清洗、转换、分组、计算,最终基于Matplotlib实现分析结果可视化。通过反馈回的商品信息与解析结果,为商家制定个性化的营销策略提供依据。
2 关键技术
2.1 Web爬虫
爬虫也称网络信息爬取技术,通过网页链接地址URL向服务器发送请求获取网页信息内容。Web 爬虫
是一个自动访问的互联网程序,用来检索Web页面、提取必要信息、存入本地数据库[3]。
网络爬虫基本工作流程如下[4]:
(1)选取精心挑选的种子URL;
(2)将种子URL放入待抓取URL队列;
(3)从待抓取URL队列取出待抓取URL,DNS解析后得到目标主机Ip;
(4)下载URL对应的网页并存储进已下载的网页库中。同时,将这些URL放进已抓取URL队列;
(5)分析已抓取URL队列中的URL,获取必要的数据存入数据库;
(6)分析其他URL,将URL放入待抓取URL队列,进入下一个循环。
2.2 Scrapy
Scrapy框架是使用Python开发的一种快速、开源的爬虫程序,可在运行在Windows、Linux等多种主流操作平台,采用基于Twisted的下载器,提供了丰富的中间接口及较强的目录约束,编写代码清晰、可扩展性好、可移植性强、可维护性高,用户只需在Scrapy 框架基础上定制开发模块即可实现高效的爬虫应用[5][6]。Scrapy框架由调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)、实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)五大组件构成。爬虫执行流程如下[7][8]:
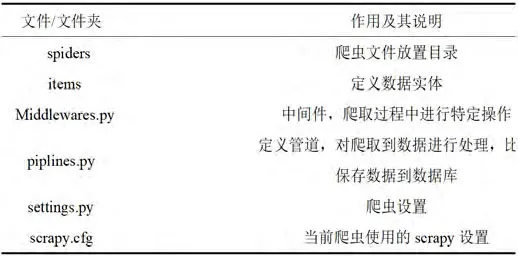
表1:工程目录下文件和文件夹作用
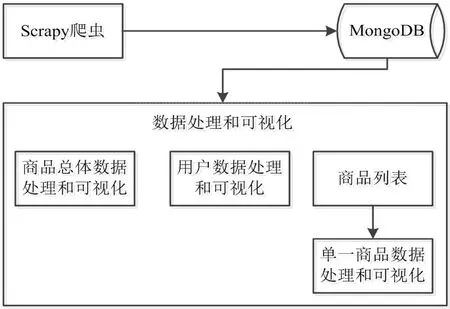
图1:系统整体架构
(1)Spiders将待爬取网页URL经Scrapy Engine交给Scheduler;
(2)Scheduler处理后经Scrapy Engine和Downloader Middleware交给Downloader;
(3)Downloader向Internet发送请求,接收Response,将Response经Scrapy Engine和Scrapy Middelwares交给Spiders;
(4)Spiders处理提取Response后经Scrapy Engine交给Pipeline保存;
(5)提取URL重复上述步骤,直到无URL请求或达到停止条件。
2.3 数据处理及可视化
数据清洗和处理采用Numpy和Pandas两个库,NumPy是Python科学计算的基础包,作为算法和库之间传递数据的容器,它提供了快速数组处理能力;Pandas能够进行复杂精细索引,它提供了大量处理结构化数据的函数,更加便捷地完成重塑、切块、聚合、选取数据子集等操作[9][10]。
数据可视化使用Matplotlib图形库,它是用Python 语言编写的二维图形库,充分利用了Python简洁优美和面向对象的特点,便于绘出直方图、功率谱、条形图、散点图等,Matplotlib提供的相关API,使得图表可以嵌入Tkinter画布中。Matplotlib绘制的图形使用Python标准Tk GUI工具包接口分析数据,再利用Tkinter库编写程序的GUI,即可实现数据的可视化呈现。
2.4 数据库
爬虫获取的数据不包含复杂关系,且数据模型经常变动,因此相较于传统的关系型数据库,本文选取非关联数据库MongoDB。MongoDB是由C++编写的基于分布式文件存储的数据库,支持数据结构松散,查询语言功能强大,可以存储复杂的数据类型。同时,MongoDB使用集合的概念存储数据,不会过多检测约束关系及数据合法性,存取效率高,对于Web中IO密集型的数据源优势巨大。
3 系统设计
3.1 系统总体架构
系统主要包括数据来源的爬虫模块及数据处理与可视化模块。首先启动Scrapy爬虫对目标网站进行爬取,Piplines接收数据并存储在MongoDB数据库中。启动数据处理和可视化GUI程序,启动后弹出窗口包含三个页面,分别是商品总体数据、用户数据和商品列表页。商品总体数据展示品牌占比、不同价位的评论分布情况、同类型商品描述词频;用户数据展示用户身份、用户下单设备等;列表页展示爬取到的商品分析数据,双击会弹出好评、中评、差评占比,不同时间段的评论分布,用户情感词云,评论词频。系统总体架构如图1所示。
3.2 爬虫模块
3.2.1 项目初始化
选取京东网站作为爬取目标,用scrapy startproject
JD_Spider生成爬虫项目,项目根目录为JD_Spider。在根目录下创建表1所示的文件或文件夹。
3.2.2 数据实体模型
Scrapy需建立实体模型来描述爬取数据[11]。设计的实体模型包括商品信息模型、店铺信息模型及评论信息模型。其中商品信息模型描述商品名称、品牌、价格; 店铺信息模型描述店铺名、店铺ID; 评论信息模型描述评论内容、评论时间。MongoDB允许不同集合间出现关联关系,使得数据库存储结构清晰,模型关系如图2所示。
3.2.3 爬取策略制定
京东评论数量和商品数量巨大,本文只爬取部分数据,爬取最大页数通过settings.py设置,每次爬取完一个页面page+1。爬取商品搜索结果时,提取访问详情页URL,使用Ajax技术加载商品评论及整体评价,让爬虫向对方服务器发送请求,得到数据反馈后再提取数据。
3.2.4 反爬虫处理机制
提高爬取成功率需让爬虫模拟浏览器行为。浏览器每次向服务器发送请求时会携带User-Agent头部信息,在middlewares.py文件的中间件内部定义一个包含常用浏览器信息的数组:

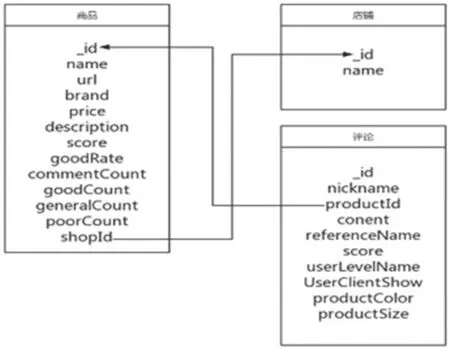
图2:爬虫数据模型关系
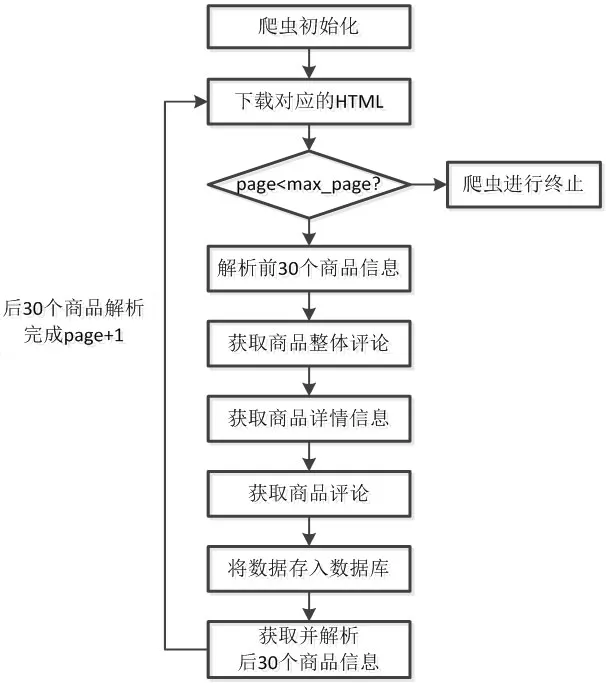
图3:爬虫执行流程
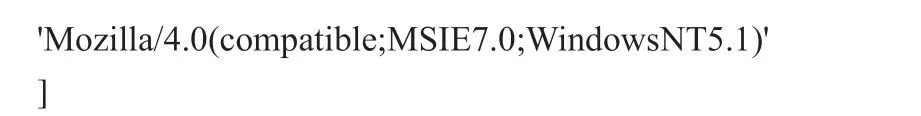
随后在中间件钩子函数process_request中,使用随机取值方法取出一个列表项,通过request对象设置请求头,最后在settings.py设置启用该中间件,即可使爬虫模拟浏览器。当访问商品详情页时,服务器会检测Referrer请求头,该请求头值为跳转详情页之前的上一页面。当请求详情URL时,在Scrapy的Request中设置Referer为当前URL,即可以获取商品详情页的数据。
为防止爬取某页面时突然中止,将每个商品id保存到数组中,当页面爬取完成时调用对应URL,并将id作为参数向服务器发送请求加载剩下的数据进行解析,再翻页处理、爬取下一页。爬虫执行流程如图3所示。

表2:目录下文件和文件夹作用
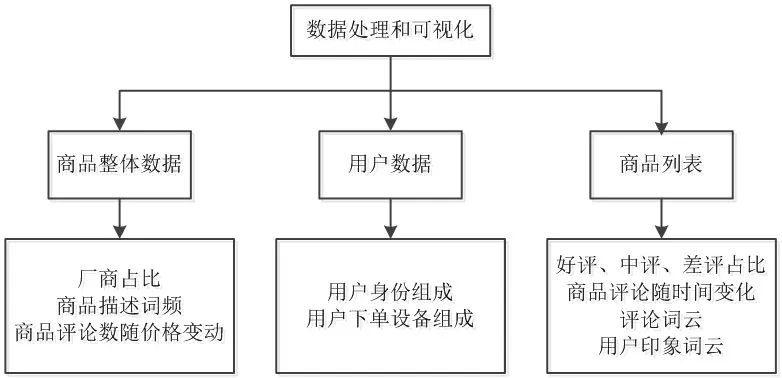
图4:界面架构
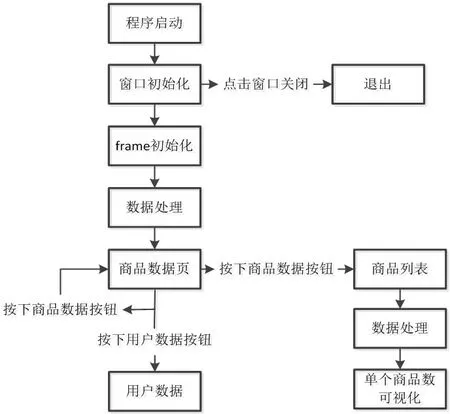
图5:数据处理及可视化模块运行流程
3.3 数据处理和可视化模块
3.3.1 项目初始化
创建名为Analysis目录文件夹,在该目录下新建如表2所示的文件或文件夹。
3.3.2 界面设计
使用Tkinter开发界面,界面窗口包括商品整体数据、用户数据、商品列表三部分,默认页是商品数据页,通过UI顶部按钮切换。在UI主类Application中定义了一个属性frames,数据结构为字典,然后将三个页面存储进字典中并让其重叠,仅最上面可见,通过改变各页面的z轴顺序切换页面。图表的显示由Tkinter画布和Matplotlib相结合绘制。界面架构如图4所示。
3.3.3 商品整体数据
(1)厂商占比。读取数据库中Products集合,由Pandas将其转换为DataFrame,调用grouby函数按brand分组,然后对commentCount列调用sum函数求和,统计出各品牌评论总数,再处理DataFrame提取品牌(brand)和评论数(commentCount)并作为元组返回,最后通过Matplotlib在Tkinter中绘制。
(2)商品描述词频。统计前十的描述词,Pandas读取商品信息后获取description信息并转换为列表数据,然后使用Jieba中文分词工具对商品描述进行精确分词,再用Pandas将其转换为DataFrame,调用agg并结合Numpy的size统计相关词频并排序,取前10结果转换为字典返回,通过Matplotlib在Tkinter中绘制。
(3)商品评价数量随价格变动。Pandas读取商品数据,将price字段换为数值类型,分别统计0-1000、1000-2000、2000-3000、3000-5000、5000-6000、6000以上的评论数并返回数据,在通过Matplotlib在Tkinter中绘制。
3.3.4 用户数据
(1)用户身份。Pandas读取所有评论,groupby函数按userLevelName字段分组,调用size求和统计并返回数据,通过Matplotlib在Tkinter中绘制。
(2)下单设备构成。Pandas读取评论后按userClient
Show字段分组,占比小于1%的字段相加,归为Others并返回数据,通过Matplotlib在Tkinter中绘制。
3.3.5 商品列表
(1)商品列表显示。Tkinter的treeview组件从数据库读取商品数据显示在列表中,列表添加双击事件,事件触发时显示对该商品的数据可视化。
(2)好、中、差评占比。从数据库中读取数据并返回,通过Matplotlib在Tkinter中绘制。
(3)评论数量随时间变动。Pandas读取数据后转换为datetime对象,再转化成year-month形式,按时间分组排序返回数据,通过Matplotlib在Tkinter中绘制。
(4)评论词频和词云。Pandas读取评论内容后转化为list,Jieba对评论精确分词,排除停用词并统计词频返回,在main.py文件中调用函数得到词频,选出排名前十的词绘制词频统计表。词云使用WordCloud读取词频,将词云显示出来。
数据处理和可视化模块工作流程如图5所示。
4 系统功能测试和市场分析
4.1 爬虫测试
settings.py设置关键词为“手机”,最大商品页数为2,最大评论页数为20。排除预约阶段的产品,启动爬虫等待一段时间,爬虫运行完毕打开MongoDB可视化工具,连接数据库找到爬虫保存的数据。抓取到的商品数量为46个,评论数量为9800条,店铺数量为18家。该结果对于设置最大页数2页、最大评论页数20页、排除部分预约商品而言完全符合预期。
4.2 市场分析
4.2.1 商品整体数据分析
爬虫执行完成后,数据库已存在必要数据,设置好待连接的数据库,启动程序显示商品数据的可视化分析。图6分别为前两页厂商评论数占比和商品描述词频。分析可见,Apple、华为、小米占据了销售前三甲,手机网络、机身、拍照功能、内存和配置是厂商宣传的卖点。
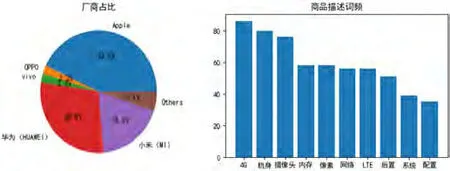
图6:厂商评论占比及商品描述词频
4.2.2 用户数据分析
抓取的9800条评论中,数量最大的是PLUS会员。PLUS会员是京东推出的会员服务,这类用户注重购物体验,常购物且更乐于发表评论。评论用户身份组成如图7所示。
4.2.3 单一商品数据分析
切换到商品列表页,买家评论和评论趋势是评论数据中的重要信息。以华为P30为例,双击该记录,弹出该商品的数据可视化图表如图8所示。分析可见,用户非常认可这款产品,好评率达98.1%,差评1.2%;评论数在2019年8-10月最高,一定程度反映商品发布几个月后打折促销,销量较高。
商品词频和词云反映用户体验,如图9所示。分析可见,用户体验主要体现在系统流畅度、外观、信号方面。
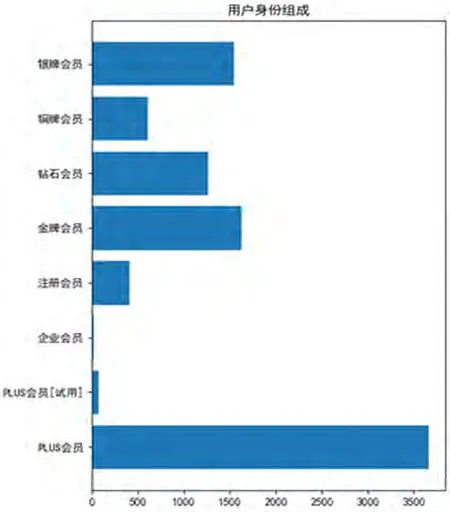
图7:评论用户身份组成
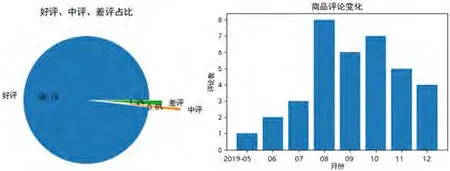
图8:评论占比及高品评论变化趋势
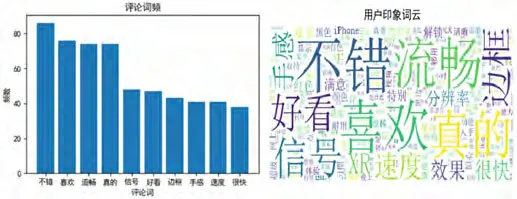
图9:评论词频和用户印象词云
5 结束语
数据是企业无形的竞争力,大数据处理已彰显不可估量的价值。本文基于爬虫技术,以京东网站的手机数据作为数据源,采用Python语言下Scrapy框架开发爬虫程序,爬取数据存入非关联数据库MongoDB,通过实例演示数据挖掘并将数据以直观、易读的方式可视化呈现。一方面可以让消费者直观享受消费过程,另一方面帮助销售商提炼用户信息、把控用户喜好、培养用户习惯,实现精准营销。
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
房地产导刊(2022年10期)2022-10-18 08:03:52
园林科技(2021年3期)2022-01-19 03:17:48
现代信息科技(2021年21期)2021-05-07 02:54:12
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
