
基于Python和OCR的仪表信息识别技术
2020-06-13 07:07刘丽媛刘宏展郝源吴一
电子技术与软件工程 2020年2期
文/刘丽媛 刘宏展 郝源 吴一
(华南师范大学信息光电子科技学院 广东省广州市 510006)
1 前言
在工业和检测领域,数字仪表因具有精度高、读取方便、易设置等优点而被广泛的应用。但是在复杂工业环境下,部分仪器仪表并没有提供与计算机进行数据通信的接口,需要人工读数来实现数据分析[1],这极大增加了作业负担且存在读数误差[2]。在科技发展迅速、智能化程度极高的今天,使用智能化技术代替人工读数的工作十分必要。
因此,本文提出了一种新的仪表信息识别技术,运用Python语言编程实现仪表信息的获取。Python语言[3]是一种面向对象的解释型计算机程序设计语言,也是当下非常热门的一种编程语言,主要具有简单易学、可移植性较好、扩展性较强、资源免费等优点[4]。基于Python和OCR的仪表信息识别技术的主要过程是对仪表图进行图像预处理,继而请求调用文字识别接口进行OCR识别。同时利用此技术对预处理方法和识别接口这两个影响因素进行了实验对比和分析。
2 研究技术
在复杂的工业工程环境中,通常通过图像信息处理系统提取出仪器仪表的有用信息,但获取仪表信息面临着图像背景复杂、拍摄角度和光线强弱等众多因素造成的分辨率低、对比度和亮度不均匀等多种问题[5]。
针对获取复杂环境下仪器仪表中彩色图像信息困难的问题,本文提出并完成了一种基于Python和百度OCR的仪表信息识别技术,主要研究过程可分为两大部分:图像预处理和图像识别。研究对象是使用相机采集仪器仪表被测目标所得到的彩色仪表原图。此技术的具体流程如图1所示。主要是先对彩色仪表原图进行仪表图像的预处理,包括加权平均法的灰度化和大律法的二值化,得到待识别图,继而请求调用百度的文字识别API接口对待识别样本图进行OCR识别,最后输出识别结果。
2.1 基于Python的图像预处理
在复杂机械工业环境下,由相机所拍摄得到的仪表图片的质量必然会受到光线明暗,是否聚焦,拍摄角度是否适当等外部环境的影响,而导致图像出现阴暗,模糊,倾斜等问题,这些关系到识别的准确性。因此,首先需要对所拍摄的仪表图像进行预处理,再识别,尽可能地降低这些不好的影响,以提高后续信息识别的准确率[6]。
预处理部分是对仪表图片进行灰度化,通过相机所采集的仪器仪表图像都是彩色的,对彩色图像进行灰度化处理能够极大减少图像信息。因为和彩色图像相比,灰度图中没有色度,同时也大大减少了信息计算量,并且有利于后续的操作处理和计算[7]。所以使用YUV颜色空间编码方法来实现图像灰度化,YUV是一种像素格式,其中Y为亮度信号,U和V为色度信号。它将亮度参量和色度参量分开表示,可以避免相互干扰,保证了在提取图像亮度信息、获得需要的灰度图像时可以不受色度参量的干扰。我们在彩色仪表图像中提取了每个像素的颜色信息,即R、G、B值,然后将每个像素的R、G、B值通过公式转换为相应的亮度信息,从而得到灰度图像。三个颜色分量R、G、B与灰度值Y的关系为[8]:
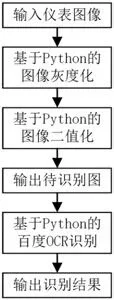
图1:流程框图

对仪器仪表图像进行灰度化的数字图像处理时,采用的灰度化方法如公式1所示[9]。将实验中仪表原图经灰度化预处理后得到待识别图。以下是在Python下使用Opencv[10]库进行灰度化操作时的部分代码:
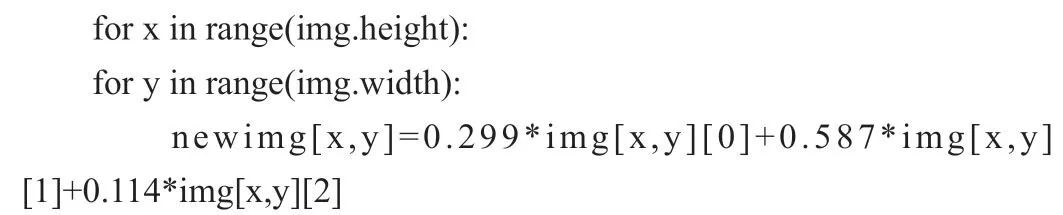
对彩色仪表原图进行上述灰度化方法的预处理后,得到了待识别样本图,接下来最关键的是请求百度文字识别API接口,对待识别样本图进行OCR识别。
2.2 基于Python的OCR识别
目前传统的图像文字识别技术大多采用传统光学字符识别(Optical Character Recognition,OCR)[11],光学字符识别在金融、医疗以及海关等众多领域中得到越来越广泛的应用,有良好的发展前景。同时,百度智能云是面向Cloud2.0的云计算服务商,其中人工智能的图像技术应用包含多个文字识别的API接口可进行通用场景文字识别。百度OCR能够适应不同业务场景对识别精度、识别速度的需求,针对图片模糊、倾斜、翻转等情况进行了优化,鲁棒性强,识别速度快,且支持2W+大字库,准确率高。百度智能云开放了API、SDK等调用方式,可以体验不同应用的实际效果[12]。

图2:基于Python和百度OCR的仪表信息识别过程图
识别部分首先是环境准备,需要登录百度云的控制台界面,创建通用文字识别的应用来获取密钥;然后在Python中创建Client实例来获取Region ID、AccessKey ID和AccessKey Secret;最后在Python中通过输入密钥来请求调用文字识别API接口,将经上述灰度化预处理后的待识别样本图作为图片参数,完成API请求的创建和参数设置,并发起请求、处理应答或异常。最终将图像信息还原成文本信息实现OCR识别,得到识别结果。
3 实验结果与分析
利用上述技术分别对单张彩色仪表原图、多张彩色仪表原图进行仪表信息识别实验。实验对象是使用相机采集仪器仪表被测目标所得到的彩色仪表原图。同时为进一步研究此技术,结合研究过程和实验来讨论图像灰度化、不同二值化预处理方法,以及采用不同版本的百度OCR接口API对图像识别结果的影响,对其各自的识别效果进行实验对比与分析。
3.1 单张、多张仪表图像的实验结果
采用上述研究技术对单张仪表图像进行识别实验,图2为基于Python和百度OCR的仪表信息识别过程示意图,其中图2(a)为彩色仪表原图,图2(b)是经上述预处理后得到的待识别图,识别结果如图2(c)所示,其识别准确率为90.8%。
通过上述实验表明,本技术对单张彩色仪表图像的识别准确率为90.8%。考虑到复杂环境下相机所采集的彩色仪表图像的差异性会影响其识别准确率,因此,加大仪表测试样本图的数量尽可能来减小误差,用此技术对50张不同复杂环境下所获取的彩色仪表图像进行相同的预处理和图像识别,对识别准确率进行平均值统计,如表1所示。
如表1所示,将50张彩色仪表图像的识别准确率进行平均值统计,平均识别率为90.7%。
3.2 不同预处理方法的实验结果与分析
在上述图2的识别过程中,待识别的测试样本图是彩色仪表图像经灰度化的图像预处理后得到的。然而通过对本技术的原理进行综合考虑可知,经不同的预处理方法后得到的不同的待识别样本图,对后续的图像识别有一定的影响。
灰度化是其他预处理操作的基础。灰度化后的仪表图像仍可以选择继续进行二值化的预处理,可使图像包含更少的信息量,更简单[13],但它也会影响后面字符识别的准确率。二值化是在图像处理中的一种经典的图像分割技术,能够迅速区分图像的前景与背景,凸显出目标的轮廓,获取有效信息。二值化方法主要有全局迭代算法、大律法(OTSU算法)、最大熵方法等[14]。由于大律法具有特点明显、处理快速、效果较好等优点,所以本文采用全局阈值法中的大律法进行二值化处理。该方法的基本原理是,设一个阈值将图像分成目标部分和背景部分两类,如果该阈值使得类内方差最小且类间方差最大,则此阈值为最佳阈值[9]。OTSU算法的实质是自动找出图像灰度直方图中波谷对应的灰度值,然后将其作为阈值[15]。本实验是在 Python 环境下实现OTSU二值化算法,采用Opencv[10]库中的cv.threshold()函数,传入cv.THRESH_OTSU参数。因此,实验中使用OTSU算法来完成二值化的图像预处理,核心代码如下所示:

因此,在图像预处理过程中,把仪表测试样本图经三种不同的图像预处理后可得到三种待识别样本图,分别为仪表图像的原图、灰度化后图、二值化后图,本实验由10张仪表测试样本图分别依次得到各自对应的三种待识别样本图,并用同样的通用文字识别API接口对其进行了OCR识别。对比研究不同预处理方法对识别准确率影响的实验结果如表2所示。
由表2可知,由10张测试样本图分别经三种不同的预处理后得到各样本对应的原图、灰度化后图、二值化后图,对这些待识别样本图进行识别,平均识别率分别为86.80%,90.64%,85.63%。由此可见,在保证其他实验条件相同的情况下,图像的预处理方法对后续的OCR文字识别是有影响的。由实验结果可知,在保持识别部分一致的实验前提下,经灰度化预处理后样本图的平均识别率最高,原图和二值化后图的识别率相差不大。
对于复杂环境下的仪器仪表来说,所采集到的仪表图像是彩色的,包含信息量大,在处理时会需要很大的存储空间和很长的运算时间。然而在实际工程应用中,仪表图像的处理需要小的存储空间和快速的操作。灰度图没有颜色信息,只有图像亮度信息,并且每个灰度图像仅需要一个像素,与彩色仪表原图相比,它具有存储空间小,处理速度快的优点。因此256级灰度图像用于图像预处理的颜色处理,表示效果是最好的。此外,在类似工厂的实际应用场合中,仪表图像采集的环境很差,采集到的图像会因为光线、角度等原因偏暗和模糊,而灰度化后清除了原图的无关信息,增强了有用信息的可检测性和简化性,因此,灰度化图的识别准确率比原图稍高。
图像在拍摄采集时因外部环境的影响导致其包含了一定前景与背景,在获取有效信息的特征区域、抓取目标的时候,二值化算法需要根据灰度特性上的均匀性找到最佳阈值T对图像的目标和背景像素来进行判别区分,如果某一像素点的灰度值大T则将其重置为255,反之将其灰度值重置为0,所以阈值的设定直接决定二值化的效果[16]。如果阈值过大,则造成图片噪音过多和目标不明显;若阈值过小,则会导致特征区域信息大量丢失,不能真实反映原图片特征信息。这些情况都会影响后续仪表图像识别的准确性。在本实验中,由于仪表彩色图像的复杂性需要进行多次二值化才能得到最佳阈值,其直接影响了目标和背景的区分,因此,与灰度化图相比,二值化不仅增加了复杂度,而且因为仪表图像的复杂性较难找到最佳阈值来准确的区分背景和目标,从而使部分有用信息可能被误判为背景,或者无关信息被误判为目标,所以灰度化图的识别率比二值化图稍高。
对上述实验结果进行分析与总结,图像预处理的方法对仪表图像的识别准确率是有影响的。将实验数据对比可知,经灰度化的预处理后得到待识别样本图,其识别准确率最高。
3.3 不同OCR接口的实验结果与分析
实现基于Python和百度OCR的仪表信息识别技术的关键是调用百度OCR的通用文字识别接口实现文字识别。在识别部分,百度智能云的人工智能图像技术应用中包含多个API接口可进行通用场景文字识别,图像识别的API接口提供了通用文字识别、高精度版、含位置信息版、高精度含位置版、含生僻字版五种版本。在前面的方法中调用的API接口是通用文字识别版。而高精度版在通用文字识别的基础上,提供更高精度的识别服务,并将字库从1w+扩展到2w+,能识别所有常用字和大部分生僻字。由于在仪器仪表的信息获取中不需要位置信息,因此在保证图像预处理部分和其他实验条件相同的情况下,调用通用文字识别和高精度版这两个API接口进行识别,来研究不同接口对仪表信息识别的影响。用基于Python和百度OCR的仪表信息识别方法对20张经相同灰度化预处理后的待识别样本图分别进行两种接口的OCR识别,识别准确率如表3所示。
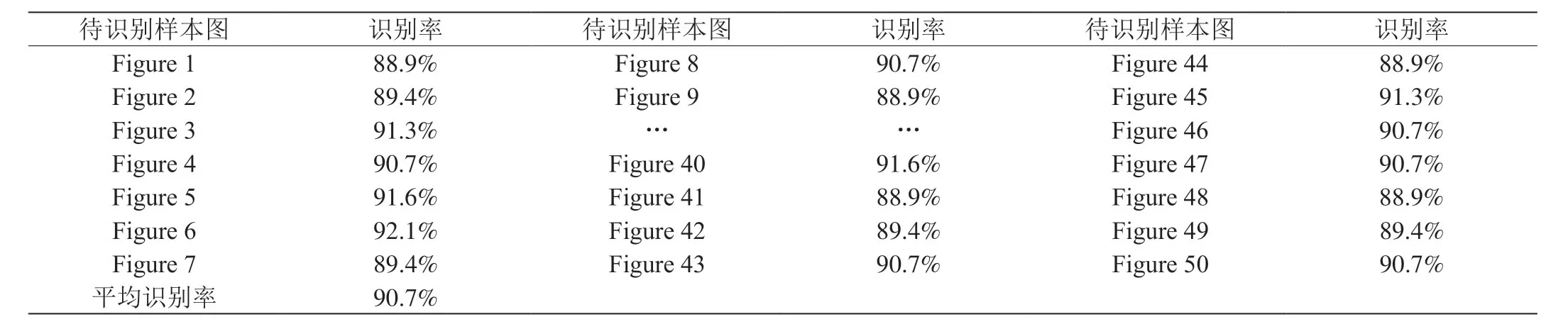
表1:50张仪表测试样本图的识别准确率

表2:三种不同预处理后待识别样本图的识别率

表3:两种接口的仪表测试样本图的识别准确率
对经相同灰度化预处理后的待识别样本图分别进行通用文字识别和高精度版这两个API接口的OCR识别,由表3可知,对两种接口的识别准确率进行平均值统计,平均识别率分别为90.64%,92.56%。由实验结果可以得到高精度版识别接口的识别准确率是比通用文字识别接口的稍高的,因为高精度版在通用文字识别的基础上,提供更高精度的识别服务,并增加了字库。
综合上述对预处理方法和识别接口的实验研究与分析,两者对仪表图像的识别结果都是有一定影响的。最后综合考虑两个影响因素,本方法最佳的识别过程是对复杂环境下彩色仪表图像进行灰度化的图像预处理,继而调用百度OCR的高精度版通用文字识别API接口进行识别,其准确率可达92.56%,识别效果更佳。
4 结论
本文提出并实现了一种基于Python和百度OCR的仪表信息识别技术,主要过程是对仪表图像进行灰度化的图像预处理得到待识别样本图,从而调用百度OCR通用文字识别的高精度版接口来获取仪表信息,其识别准确率可达92%以上,而且识别复杂度低。此外,还讨论了图像灰度化、不同二值化预处理方法,以及采用不同版本的百度OCR接口API对图像识别结果的影响。因此,本文对仪器仪表的图像信息处理有一定参考意义。但在复杂工业工程环境下,相机所采集的仪表图像质量很差,导致本方法离百分之百的识别率仍有一定差距,需进一步提升。
猜你喜欢
建筑与预算(2023年2期)2023-03-10
建筑与预算(2022年5期)2022-06-09
建筑与预算(2022年2期)2022-03-08
Defence Technology(2020年4期)2020-07-02
数位时尚(幼儿教育)(2017年12期)2018-01-05
中国医学人文(2015年6期)2015-06-08
太空探索(2014年4期)2014-07-19
单片机与嵌入式系统应用(2014年9期)2014-03-11
测绘科学与工程(2014年6期)2014-02-27
电讯技术(2010年8期)2010-08-08
