
基于深度双向LSTM网络的说话人识别
2020-06-12 09:18:12王华朋
计算机工程与设计 2020年6期
王华朋
(中国刑事警察学院 声像资料检验技术系,辽宁 沈阳 110854)
0 引 言
研究说话人识别[1]的文献非常多,目前主流的方法是基于i-vector或者GMM-UBM的说话人识别[2,3],并且逐渐出现了传统方法与深度神经网络(deep neural networks,DNN)相结合的研究[4],获得成功的研究之一是使用局部连接网络(locally connected networks,LCN)实现文本相关的说话人识别[5]。深度神经网络也被用来作为语音特征提取器来表示说话人模型[6,7],有学者使用受限玻尔兹曼机[8]、深度置信网络[9]等来开展说话人识别研究。鉴于CNN在计算机视觉方面获得的巨大成功,不少学者使用CNN来提取语音的声谱图特征,进行类似于图像识别的方法,进而进行文本相关的说话人识别[10-12]。但是CNN不能充分提取序列数据的特征,对于处理时序数据的能力不如循环神经网络(recurrent neural networks,RNN)。在RNN的诸多结构设计中,LSTM神经网络是应用最广泛的RNN之一。目前,LSTM广泛应用于语种识别[13]、语音情感识别[14,15]、音素分类[16]、语音识别[17,18]、唇语识别[19]等领域。在说话人识别领域,文献[6]使用LSTM进行文本相关的说话人识别,本文提出使用双向LSTM深度网络进行文本无关的说话人识别,据作者调研,目前尚无应用深度双向LSTM网络进行说话人识别研究报道。
1 RNN与双向LSTM
与前馈网络相比,RNN是循环的,按照时间步进行反馈,这使得RNN特别适合学习序列信息,因为RNN按照时间顺序提供了一种记忆模式。经典的RNN在当前的时间步和之前的时间步建立了直接连接,但是,当时间步跨度很大的情况下,这种直连不能有效学习时间序列之间的关系。因为,这种架构的网络具有很多的反向传播设置,当时间步数目较大的时候,就会导致梯度消失和爆炸的问题,目前,Hochreiter和Schmidhuber提出的LSTM是解决时间序列的最好方法[20]。许多其他学者也指出,使用嵌入记忆单元LSTM网络结构来保存信息,对于处理较大范围的信息关联具有更好的性能[17,21]。
1.1 LSTM循环神经网络
图1描述了LSTM网络的记忆单元。在循环神经网络中,通过下面的公式的迭代,从时间步1到时间步T,对输入向量序列x=(x1,…,xT),计算隐层向量序列h=(h1,…,hT)和输出向量序列y=(y1,…,yT)
ht=φ(Wxhxt+Whhht-1+bh)
(1)
yt=Whyht+by
(2)
其中,W表示权重矩阵,比如Wxh表示输入层到隐含层的权重矩阵,b表示偏置向量,比如bh表示隐层偏置向量,φ为隐层函数。φ函数的运算通过下面的公式来实现
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(3)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(4)
ot=σ(Wxoxt+Whoht-1+Wcoct-1+bo)
(5)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(6)
ht=ottanh(ct)
(7)
其中,σ为logistic sigmoid函数,i、f、o和c分别为输入门、遗忘门、输出门和记忆单元激活向量,它们和隐层向量h具有相同的大小。从记忆单元到门的权值矩阵(比如Wci)为对角矩阵。
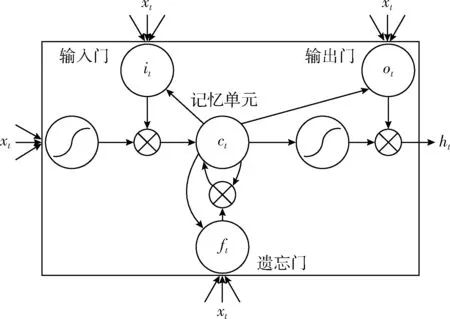
图1 LSTM记忆单元
1.2 双向LSTM神经网络
(8)
(9)
(10)
组合双向RNN和LSTM即可得到双向LSTM,该网络可处理较大范围的双向输入数据。

图2 双向循环神经网络结构
2 实验设置
2.1 实验步骤
(1)配置实验环境。实验采用Matlab2018B软件运行环境,硬件配置采用i7-6700HQ处理器,8 GB内存,单GPU NVIDIA GeForce 940MX显卡;
(2)建立具有标签的音频数据库;
(3)去除语音文中的静音段和非语音片段;
(4)提取语音特征序列;
(5)基于特征序列训练LSTM网络;
(6)在训练集上测量和可视化分类器准确度;
(7)创建测试语音库,对完成训练的LSTM网络进行性能评测;
(8)去除测试数据库中的非语音段,产生特征序列并通过训练好的网络,通过比较预测标签和说话人真实标签,生成训练网络的测试识别率。
2.2 数据库
数据库包含60名20岁左右年龄相仿(年龄差5岁以内)的男性说话人,每人录音2次,录音间隔约为30天,录音方式为说话人朗读指定的文本内容。录音信道为固定电话线路,音频经去除静音段处理后,被分割成5 s时长的音频文件,采样率为8000 Hz,每名说话人录音包含约10个左右的5 s时长的音频文件,共790个音频文件。从中随机选取70%(550个)的音频文件作为训练LSTM网络的样本,剩余的30%(240个)音频文件作为测试语音。
2.3 语音特征提取
本文提取了Mel-frequency cepstrum coefficients (MFCC)、Delta MFCC、Delta-Delta MFCC、基频和谐波能量占比作为训练LSTM的语音特征。MFCC的特征维度为13维,即13维的MFCC、13维的Delta MFCC和13维的Delta-Delta MFCC,加上基频和谐波特征,共41维语音特征。在语音特征提取过程中,选择窗的长度为30 ms的汉宁窗,窗之间的重复度为75%,每40帧语音特征组成一个序列。
2.4 双向LSTM网络设置
本文提出的深层双向LSTM网络结构如图3所示。网络第一层为序列输入层,输入数据的大小为特征的维度,即41;第二层为具有100个隐层节点的双向LSTM网络,用来传递信息到下一层;第三层为Relu层,第四层为具有100个隐层节点的双向LSTM网络,用来输出序列的最后一个元素;第五层为全连接层,节点数目为说话人的数量;第六层为Softmax层;第七层为分类层。
网络的迭代周期输入设置为50,MiniBatchSize设置为128,即网络一次训练128个训练数据;Shuffle设置为’every-epoch’,即每个周期训练前都会随机选择训练数据;LearnRateSchedule设置为‘piecewise’,即每5个训练周期,学习速率按确定因子0.5降低。选择ADAM(adaptive moment estimation)算法作为深度双向LSTM网络训练算法,因为它比随机梯度下降算法(stochastic gra-dient descent with momentum,SGDM)在RNN网络训练中具有更好的性能。

图3 基于双向LSTM的深度神经网络结构
3 实验结果及分析
图4显示的训练过程的识别准确度变化曲线,即每次处理完mini-batch的分类准确度。图5显示的是训练损失大小变化曲线,为每次处理完mini-batch的互熵函数值。分析上述两图可得,在迭代30个周期后,上述两曲线即进入收敛状态,识别准确率稳定在100%附近,互熵函数值稳定在最小值附近,说明本网络还可以容纳更大规模的说话人识别,对于组建大规模数据库识别具有良好的潜力,从另一个方面也反映出该网络不容易出现梯度爆炸或消失等问题,具有良好的稳定性。测试结果的识别准确率为97.92%,这对于只有5 s时长的短语音说话人识别是非常高的结果,并且本文数据库只是年龄接近的男性话者录音,如果在实际应用中扩大年龄段范围或存在女性录音,识别结果应该更高。
为清晰显示训练结果,本文以10人的混淆矩阵为例对结果进行说明,如图6所示,纵轴表示真实类,横轴表示预测类结果,图中数字代表序列预测结果的个数,比如左上角234,表示有234个序列的预测结果为“0001 白天明”,每一行数字之和,表示某一个时长5 s的音频去除静音段后组成序列的个数,如果位于对角线上的数字越大,代表有越多的序列被正确归类。图7是按照“多数决定规则(majority rule)[22]”的训练结果,对角线上的数字代表参与训练的音频文件的个数,按照多数决定规则,所有的训练音频都被正确分类。图8、图9为对应的测试集结果,按照多数决定规则,所有音频文件的分类结果都是正确的,未出现梯度爆炸或消失的情况。
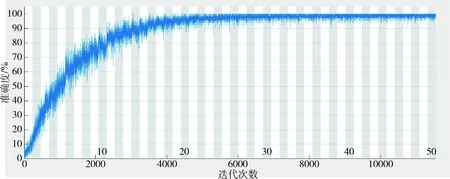
图4 训练过程的识别准确度变化曲线
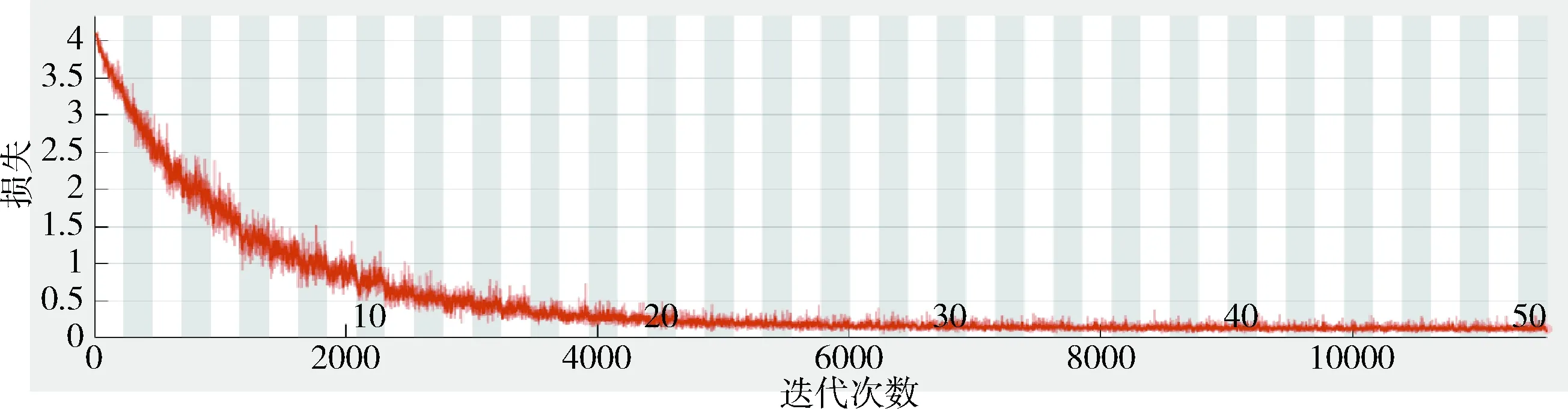
图5 训练过程损失函数互熵值变化曲线
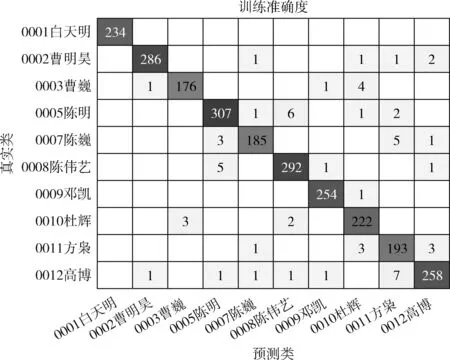
图6 训练集序列结果的混淆矩阵
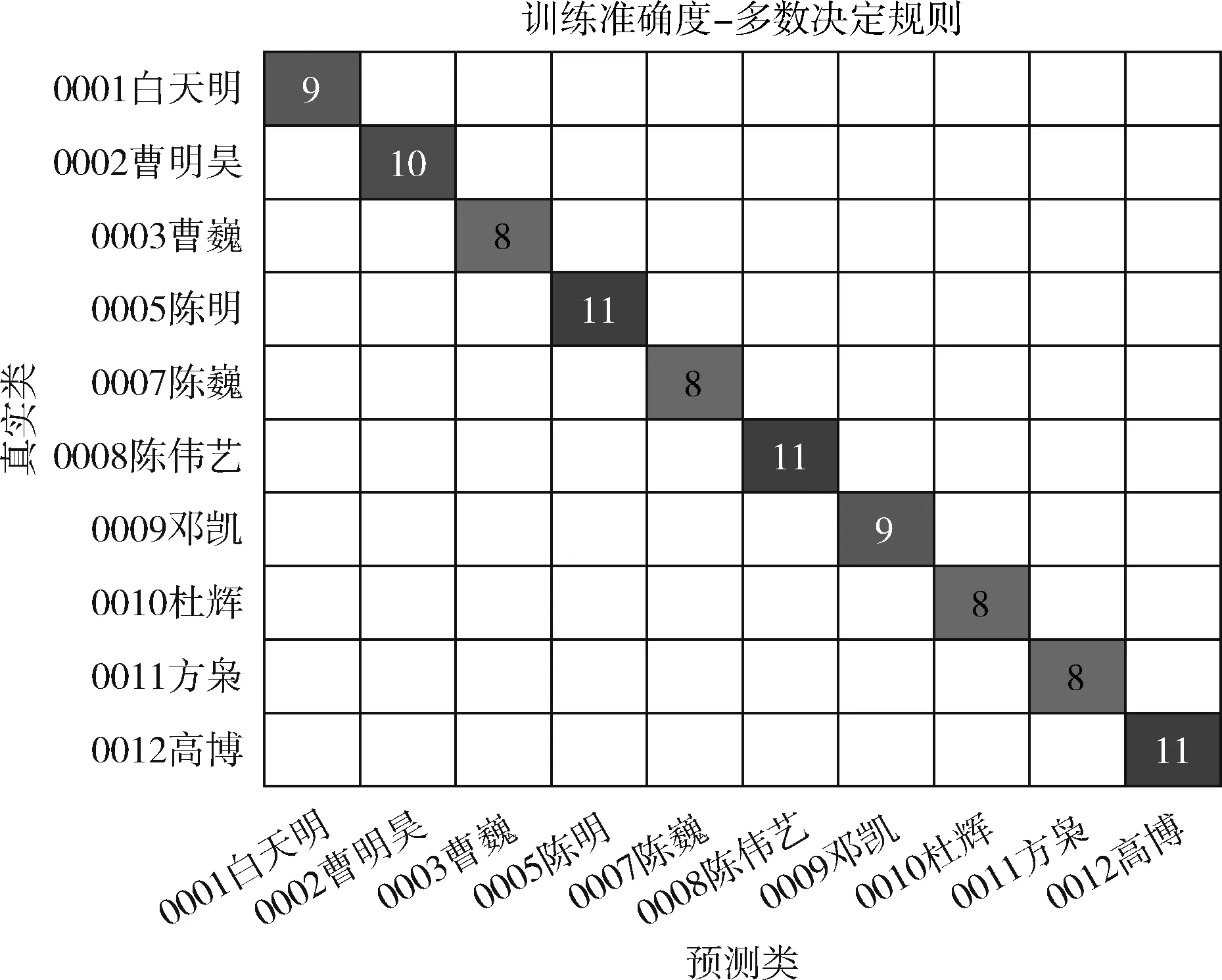
图7 训练集单个音频文件的混淆矩阵
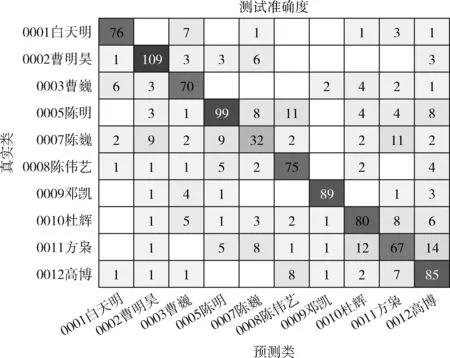
图8 测试集序列结果的混淆矩阵
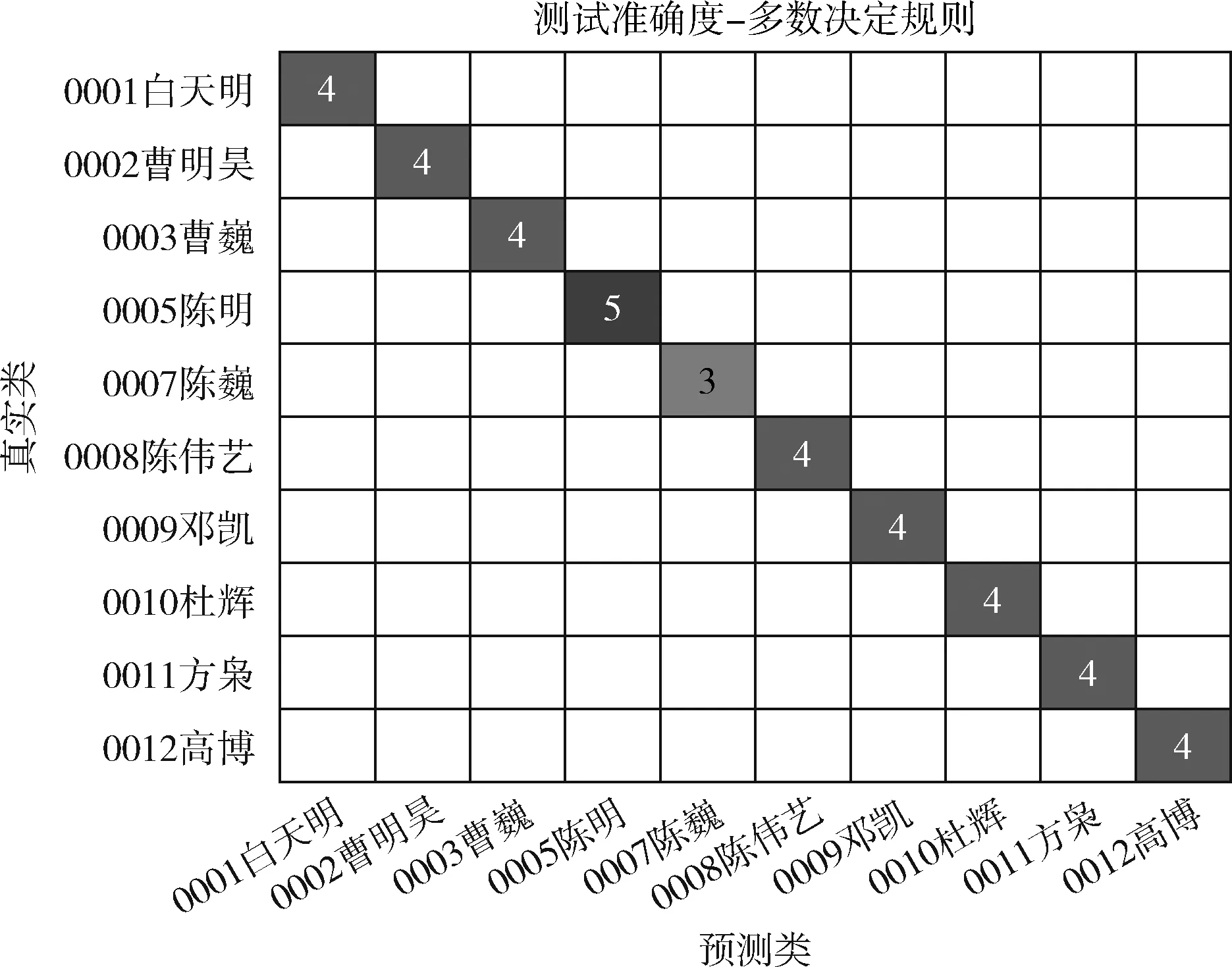
图9 测试集单个音频文件的混淆矩阵
为评估该网络的抗噪声干扰特性,本文对数据库中所有音频文件分别加入不同程度的白噪声进行测试,表1为不同信噪比条件下的测试结果。在普通办公室环境(未加入白噪声)下,准确率为97.92%,比使用相同数据库文献[23]中GMM-UBM方法的准确率提高1.92%。在信噪比为20 dB的条件下,准确率为95.83%,在信噪比为10 dB的条件下,准确率为94.17%,在信噪比为0 dB的条件下,准确率下降为72.92%。分析可得,只要语音的信噪比在10 dB以上,都可获得令人满意的结果,这对于只有5 s时长的短语音说话人识别,具有良好的实用价值。
测试结果得分为预测为某一个说话人的概率,其中,包含240个相同说话人语音样本比对,14 160个不同说话人语音比对样本。在相同人语音样本测试中,97.5%的测试样本的预测概率大于30%,绝大部分测试样本的预测概率在70%以上,如图10所示,说明预测结果能为实际应用提供更大的置信度;在14 160个不同说话人语音样本比对中,预测概率大于10%的仅占0.4%,最高值为30%左右,绝大部分的预测概率都极低,说明错误认定的几率非常小,能保证不同人不会被错误的认定为同一个人,适合在法庭说话人确认领域应用。

表1 不同信噪比白噪声影响下网络的正确识别率/%
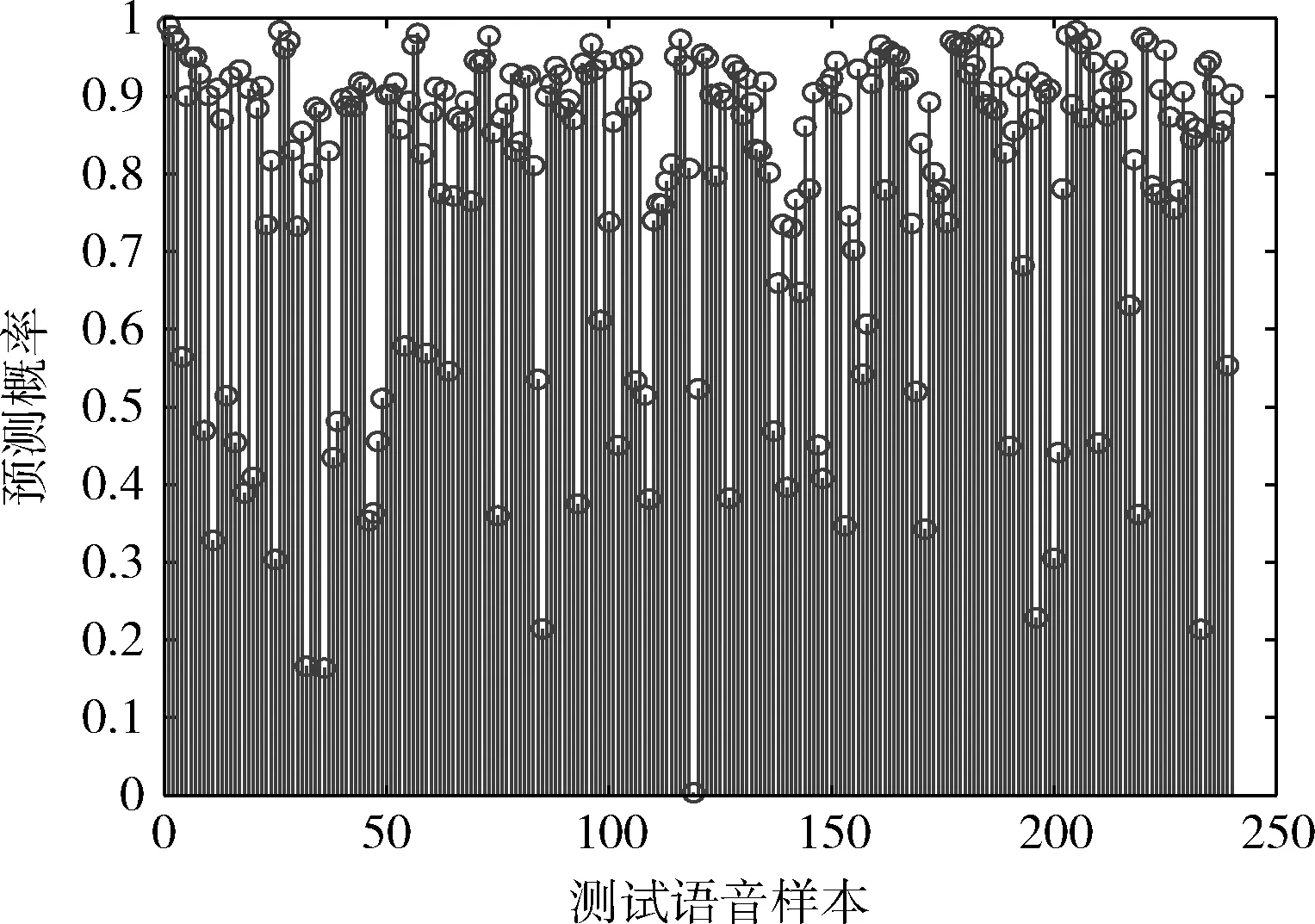
图10 相同说话人语音对预测概率分布
4 结束语
为拓展深度学习在说话人识别领域的应用,本文提出了一种端到端的基于深度双向LSTM网络结构的说话人识别方法。该网络可充分使用语音序列数据的前后时间步的信息,增强了网络上下层之间的联系。在年龄相仿的60人男性汉语数据库中,使用5 s时长的短语音,取得了97.92%的正确识别率。实验结果表明,该网络还具有更大的容积能力,适合进行大规模数据库的说话人识别任务,并且对白噪声表现出较强的鲁棒性。鉴于基于深度学习的说话人识别的强大学习能力和抗干扰能力,为进一步让深度学习技术在说话人识别领域走向实际应用,实际情况下常见的混合信道说话人识别是未来的研究方向。
猜你喜欢
出版人(2022年11期)2022-11-15 04:30:18
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
网络安全技术与应用(2017年11期)2017-03-10 19:37:54
通信电源技术(2016年5期)2016-03-22 01:09:37
电脑爱好者(2015年5期)2015-09-10 07:22:44
电源技术(2015年9期)2015-06-05 09:36:07
黄河水利职业技术学院学报(2014年2期)2014-12-02 03:01:18
