
基于机器学习的外汇新闻情感分析
2020-06-12 09:18:08戚天梅王吉祥王志宏
计算机工程与设计 2020年6期
戚天梅,过 弋,2+,王吉祥,王志宏,成 舟
(1.华东理工大学 信息科学与工程学院,上海 200237;2.大数据流通与交易技术国家工程实验室 商业智能与可视化技术研究中心,上海 200237;3.中汇信息技术(上海)有限公司 开发三部,上海 201203)
0 引 言
互联网中的海量数据传达了重要信息[1],因此分析文本情感、挖掘意见观点越来越重要[2,3]。目前大多数的情感分析是针对电商评论数据,缺乏对外汇新闻的意见挖掘。外汇新闻的情感分析尚处在初级阶段[4],仍有许多难题需要解决,如:①外汇新闻覆盖范围广,不仅有货币对如“人民币/美元”的形式,还有原材料如“原油”,国家政策如“三农”等因素,影响着外汇市场的交易。②外汇新闻中影响情感强度的词形式不一,种类繁多,例如“美联储讲话后,黄金涨幅扩大至1.36%,上涨逾18美元,刷新日高至1344.85美元。”影响情感强度的词可以是1.36%、18、1344.85等数值形式,还可以是表示程度的“扩大”,表示机构影响力的“美联储”等形式。
为有效挖掘外汇新闻的情感,提出了融合情感词权重的方法分析情感倾向;提取外汇新闻的特征,研究情感强度。
1 相关工作
情感分析在实际应用中发挥了重要作用。从粒度上,情感分析可以分为粗粒度和细粒度[5]。本文基于细粒度情感分析,研究外汇新闻的情感倾向和情感强度。现有的情感分析研究,为文本意见挖掘提供了重要的基石。
1.1 情感倾向研究
情感倾向是细粒度情感分析非常重要的一步。张仰森等[6]通过构建情感词典和表情符号词典,利用级联方式,计算情感倾向的二级分类方法,再利用朴素贝叶斯设计三级分类方法,使得分类结果取得了较好的效果。江腾蛟等[4]针对不同词性和在句子中担任不同成分的情感词,构成(评价对象,情感词)对,但还需要考虑没有情感词的句子。Xu等[7]构建了一个扩展词典,结合Hownet和NTUSD以及从新浪微博和豆瓣获取的网络流行词构建词典,并设计了情感极性的计算规则研究文本情感。Chen等[8]提出了一种结合卷积神经网络和区域注意力机制的分析模型,将一个句子以评价目标为中心,向左右两边扩展一定长度,切割句子,利用SemEval2016的餐馆、笔记本电脑数据集和汽车领域的数据集来分析情感。
Maia等[9]采用NLP技术对金融领域的舆情进行分析,将一个复杂的句子依照句法形式简化为较短的句子,然后根据极性和远距离的监督来分析情感倾向。Lu等[10]使用影评数据,提出了结合词典的注意力机制,分析情感。Lu等在计算情感词注意力值时,设计了Consultation Vector用于检验注意力值分配的合理性,从而达到更好的分类效果。李阳辉等[11]采用的是降噪自编码器来对文本进行无标记特征学习并进行情感分类,分析实验获得最佳的参数设置。对有噪声数据的处理效果高于SVM和ME。Kamal等[12]提出了基于时间的情感分析,并实现自动提取和处理文本数据,得到数据中的情感信息。
1.2 情感强度研究
情感强度一般基于统计学或人工标注的方法。吴江等[13]在情感强度分析方面对实验结果和专家标注值进行差值平均,取得了较好的结果。张雪英等[14]通过严谨的实验获得情感强度的数据集,并对数据集进行分析,证明了情感强度的合理性。王秀芳等[15]挖掘微博话题与时间的关系,提出了结合时间序列和情感词分析情感。Li等[16]提出了3层CRF模型,融合了程度词、情感词、语气词以及词性,分析商品评论数据的情感倾向和强度。
从以上研究可以发现,情感分析已经引起了学者们的广泛关注,但大多数是基于电商评论、微博评论等方面,还未广泛应用于外汇领域。Wan等[17]指出基于情感词典的情感倾向分析,情感词典的完善程度影响情感倾向分析的结果。另一方面,机器学习能够学习知识提高自身性能,且已经广泛应用于诸多领域。因此,本文使用机器学习结合情感词典的方法对文本进行细粒度情感倾向分析;在分析情感强度方面,大多数文献只考虑了情感词或者程度词,缺乏领域的特点。因此,本文将充分考虑新闻中多种影响情感强度的词,如机构的权威性、重要会议、百分数、基点等。
为了更加准确地分析出每个情感所表达的对象,本文采用了细粒度的方式分析情感。最后,形成基于机器学习的外汇新闻细粒度情感分析模型。
2 细粒度情感分析
本节构建了基于外汇新闻的细粒度情感分析框架,对比了4种机器学习方法在情感倾向方面的分类效果。另一方面,根据外汇新闻的特点,提取影响情感强度的特征,分析情感强度。
2.1 模型架构
本文的情感分析模型主要分为以下几个步骤:①数据采集与处理;②评价对象和属性提取;③情感词典的构建和情感倾向分析;④情感强度分析。最后得出情感分析元组(评价对象,属性,情感强度)。其中情感强度是一个包含情感倾向的值(正或负),正值代表正向情感的强度,负值代表负向情感的强度。情感分析模型总体框架如图1所示。
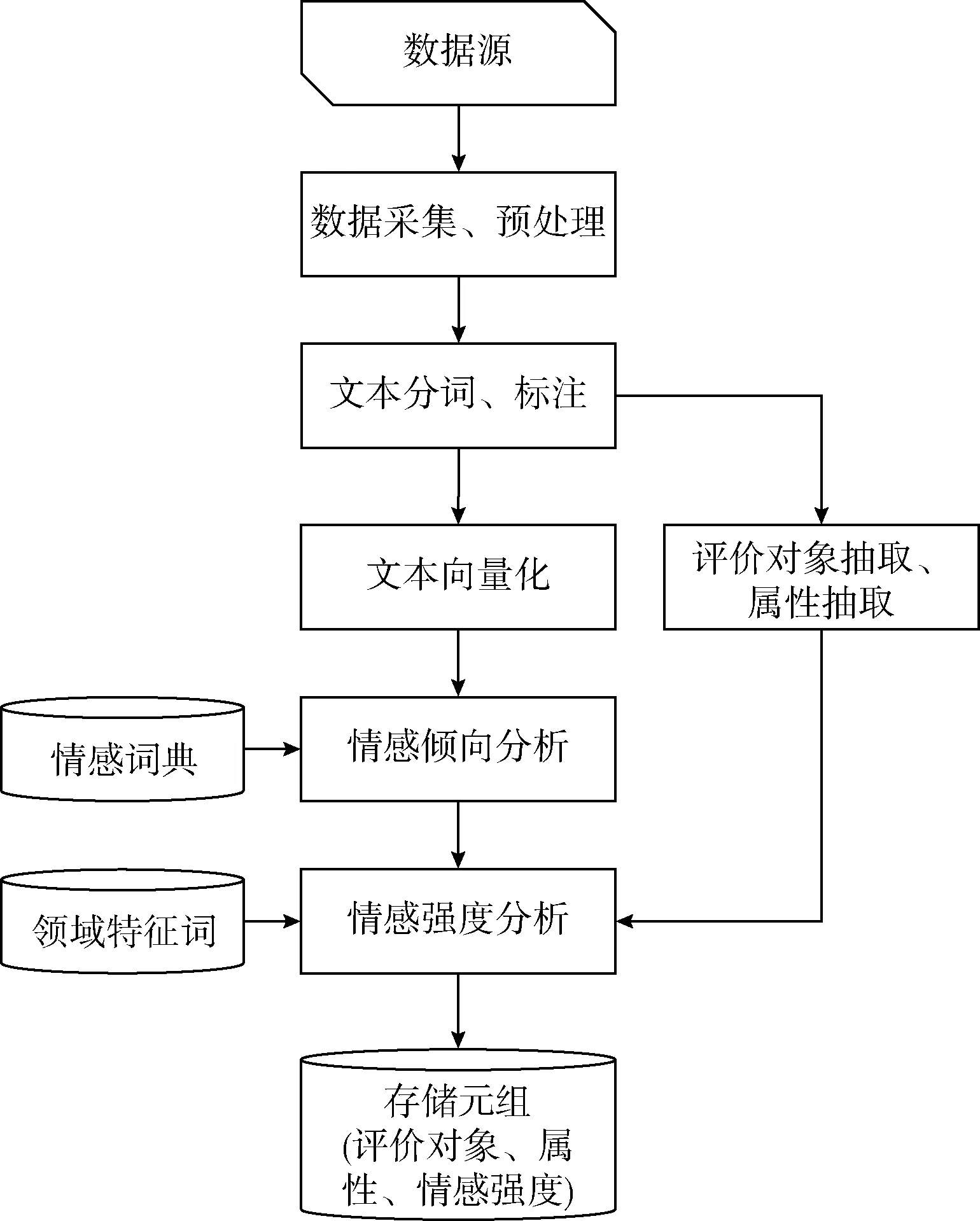
图1 情感分析模型框架
2.2 数据采集与处理
本文利用Python爬虫技术获取华尔街见闻(https://wallstreetcn.com)的外汇新闻数据,并对获取的数据进行处理。利用结巴分词工具对新闻进行分词和词性标注。
2.3 评价对象和属性提取
在细粒度情感分析方面,需要识别评价对象和属性[18,19]。评价对象是指情感描述的对象。例如:“黄金价格上涨5%”,其中的评价对象是“黄金”,属性是“价格”。本文在评价对象识别方面建立了基于专家经验词汇的评价对象和属性词典,评价对象包含了美元指数、黄金、沪指等;属性有价格、收益率、成交量等词汇。
2.4 情感词典的构建和情感倾向分析
情感倾向很大程度上依赖于情感词汇,一个良好的情感词典会使情感分析达到事半功倍的效果。建立情感词典的方法有很多种,例如台湾大学中文情感极性词典(NTUSD)、清华大学李军中文褒贬义词典(TSING)、知网情感词典(HOWNET)[20]。本文在知网情感词典的基础上加入了外汇领域情感词,建立情感词典,为情感倾向分析得到更好的实验效果做准备。
本文在情感倾向分析实验中,分析了两种情况下使用朴素贝叶斯(NB)、逻辑回归(LR)、随机森林(RF)和支持向量机(SVM)4种方法的实验结果。两种情况为:①对文本向量化(T_vec),分析情感倾向;②在文本向量化的基础上,融合情感词权重(FW_vec)。本文使用词向量模型对文本进行向量化处理。其中,融合情感词权重的方法,如式(1)所示
TxtVector=
(1)
其中,wordi表示句子中的情感词,vword表示某个词的向量化结果,W表示给情感词设置的权重,最后得到具有情感词权重的词向量化结果TxtVector。
融合情感词权重的情感倾向分析算法设计如下:
(1)输入标注好的新闻文本news和词典。
(2)对新闻内容进行分词words。
(3)利用word2vec模型和情感词典对分词words进行向量化处理。
(4)利用NB、LR、RF、SVM对处理好的数据进行训练。
(5)分析模型的性能。
(6)输出情感倾向分析模型。
根据上述得到的情感倾向分析模型,选择NB、LR、RF、SVM这4种方法中分类效果最好的方法,用于情感强度分析。
2.5 情感强度分析
情感强度是指新闻中情感倾向的强度。外汇新闻中可以用来分析情感强度的词本文分成3种类别:第一类是术语词,如机构名(美联储)、有影响力的人(央行行长)、重要会议(中央经济工作会议)等;第二类是程度词,根据Hownet词典将其分为6种类别;第三类是新闻中的百分数、基点的数值形式。对于第一类本文采用了外汇领域专家经验词汇,分为高影响词、中影响词、低影响词3种。第二类程度词,本文根据Hownet程度词典的划分方法,将程度词分为6种子类别,分别是“及其”、“超”、“很”、“较”、“稍”、“欠”,并结合Hownet程度词典和外汇新闻词汇构建程度词典。第三类百分数、基点形式从新闻本文中获取。表1给出了部分3种类别的词。
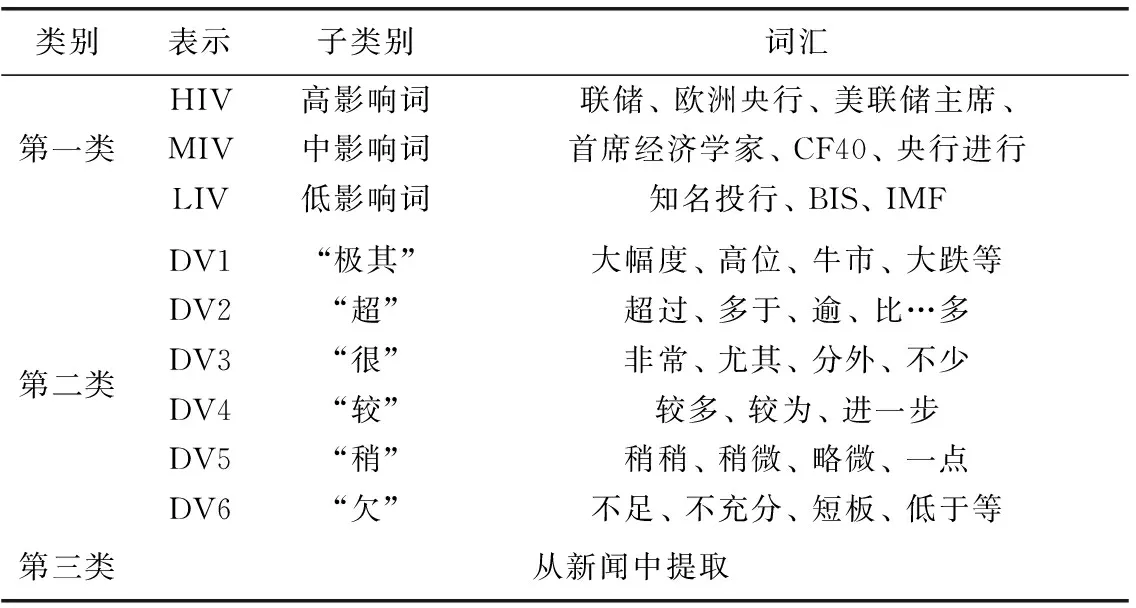
表1 3类影响情感强度的词
本文用HIV表示高影响词、MIV表示中影响词、LIV表示低影响词。DV1、DV2、DV3、DV4、DV5和DV6分别表示6种类别的程度词。
通过上述分析,设计了两组实验对比分析新闻的情感强度。实验一分析了基于程度词情况下的情感强度,并采用了冉杨帆等[21]的程度词权重,见表2。

表2 程度词权重
考虑到程度词并不会存在每一条新闻中,所以本文设计了一个基本的权重值(BV)。实验一设计表示为式(2)
(2)
其中,SAIi表示第i条新闻的情感强度,Pi表示第i条新闻的情感倾向,W程度词表示程度词的权重。
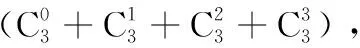
SAIi=Pi*W程度词*W术语词*Ri
(3)
其中,W术语词表示第一类词的权重,Ri表示从第i条新闻中抽取出的第三类词。
3 实验评测方法
3.1 实验数据集
实验数据来自华尔街见闻网站的新闻。本文利用Python技术爬取了70 000条新闻数据。为了使标注数据的合理性,本文针对每个评价对象选取100条新闻,由于有些评价对象出现的次数不足100条,最后得到标注数据2800条。我们邀请了两位外汇领域专家标注新闻的情感倾向和情感强度。其中情感倾向包含两种(-1、1),-1代表负向情感、1代表正向情感。情感强度标注为离散的值。
标注结束后,对标注结果进行一致性分,得到情感倾向的一致性为91.4%。可以看出两者对外汇新闻的情感倾向的一致度较高。实验数据选取情感倾向标注一致的数据,并在此基础上计算两者情感强度的均值作为情感强度的标注结果。根据以上标注结果最后选取实验数据见表3。

表3 实验数据集
3.2 情感倾向评测方法
本文在情感倾向评测中选择了查准率(Pre)、查全率(Rec)和F值(F1)这3个指标。查准率能够反应分类器对类别的区分能力,查全率反映了分类器的泛化能力,F值是查准率和查全率的调和均值,能够综合考虑分类器的性能[13]。
为了进一步分析分类器效果,本文使用混淆矩阵来观察分类器在各个类的分类情况。混淆矩阵中的每行之和代表该类的样本数,每列的各个值代表被分到该类的值,可表示为式(4)
(4)
其中,n代表类别数,Dij代表第i类被分到第j类的样本数,即第i行第j列的值,Si代表第i类样本的总数,即第i行的和。
本文以比率的形式显示混淆矩阵中各个类的预测结果。混淆矩阵中每个值的计算方法为式(5)
percentageij=Dij/Si
(5)
其中,Dij表示第i行第j列的值,Si表示第i行的和。percentageij表示为第i类被预测到第j类的概率。
3.3 情感强度评测方法
在情感强度评测方面,本文将实验得到的情感强度SAIi与专家标注的情感强度Ei进行差值平均,如式(6)所示
(6)
由式(6)可知,Y越小说明实验得到的情感强度与专家标注的情感强度越接近,越大则越偏离专家标注的情感强度[13]。因此,可较好分析实验的结果。
4 实验结果分析
4.1 情感倾向实验结果分析
本节对比分析了NB、LR、RF和SVM这4种方法在①文本向量化;②在文本向量化的基础上融合情感词权重,两种情况下的实验结果,如表4和图2所示。
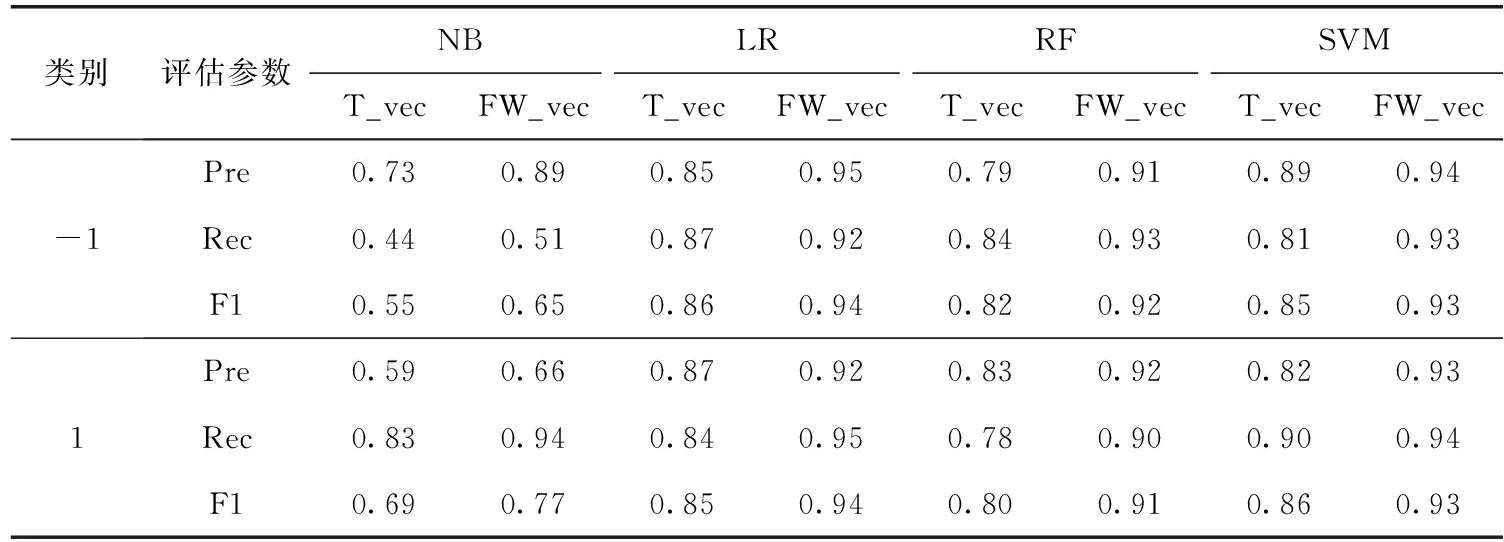
表4 情感倾向实验结果
由表4可以看出,NB在FW_vec情况下的-1和1分类的F1值比T_vec情况下的F1值分别高0.1和0.08;LR在FW_vec情况下的-1和1分类的F1值比T_vec情况下的F1值分别高0.08和0.09;RF在FW_vec情况下的-1和1分类的F1值比T_vec情况下的F1值分别高0.1和0.11;SVM在FW_vec情况下的-1和1分类的F1值比T_vec情况下的F1值分别高0.08和0.07。同理,可以分析出Pre和Rec的对比结果。
图2显示了4种方法在T_vec和FW_vec两种情况下的混淆矩阵,进一步分析实验的预测结果。其中,第一行4个混淆矩阵代表在T_vec情况下NB、LR、RF和SVM的分类结果;第二行4个混淆矩阵代表在FW_vec情况下的分类结果。混淆矩阵主对角线的值代表了被正确预测的概率,NB从T_vec的(0.44,0.83)提升到了FW_vec的(0.51,0.94);同理LR从(0.87,0.84)提升到了(0.92,0.95);RF从(0.84,0.78)提高到了(0.93,0.90);SVM从(0.81,0.90)提高到了(0.93,0.94)。通过对比混淆矩阵可以看出,FW_vec的实验结果,主对角线的数值相较于T_vec的高,副对角线的数值比T_vec的低。说明融合情感词权重能够提高预测的准确性,降低错误分类。
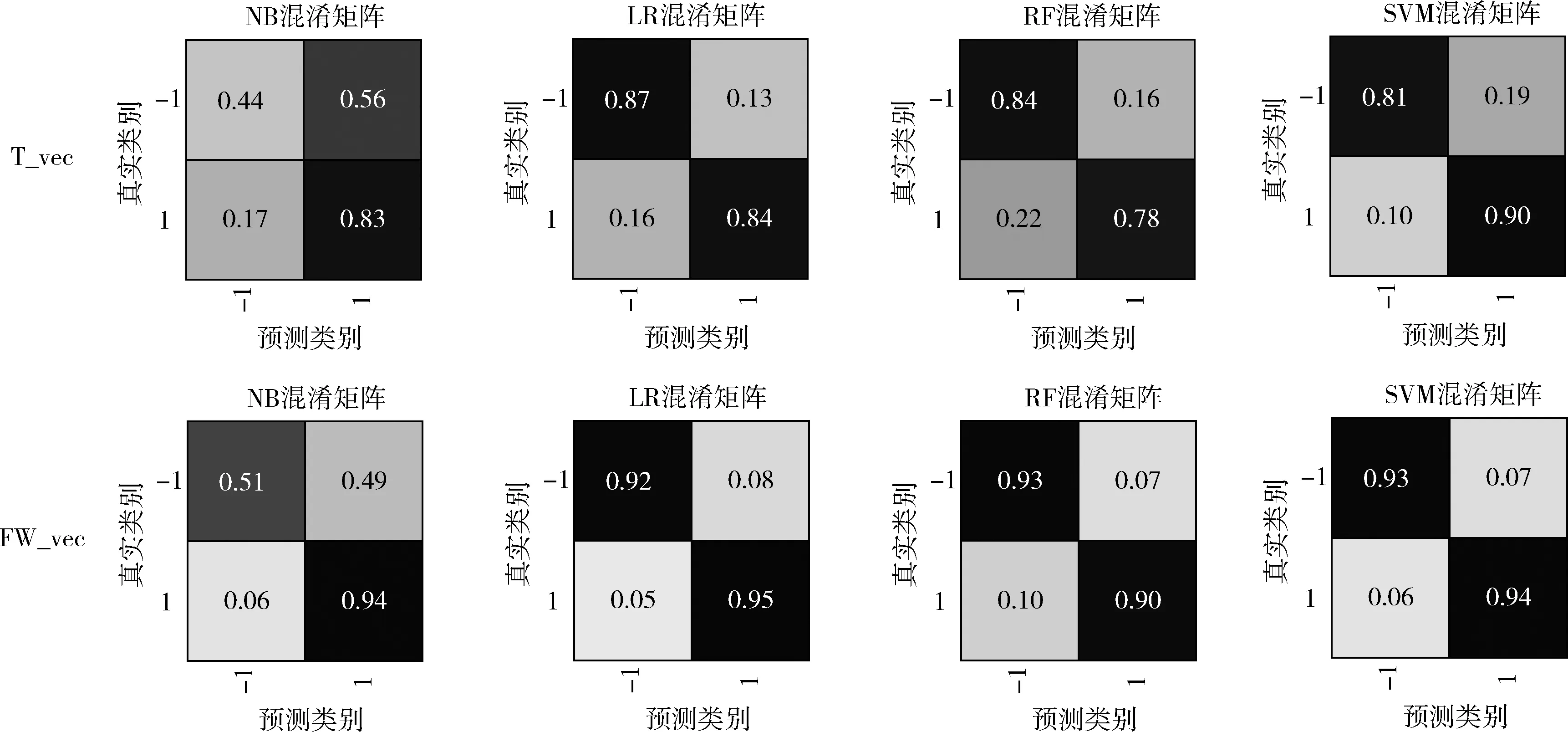
图2 混淆矩阵对比
通过表4和图2的分析可知,融合情感词权重的实验结果优于文本向量化的实验结果。因为情感词在情感倾向分析中具有重要位置,因此融合情感词权重能达到更好的分类结果。
图3给出了4种方法在两种情况F1值的对比折线图,展示了负向分类和正向分类。
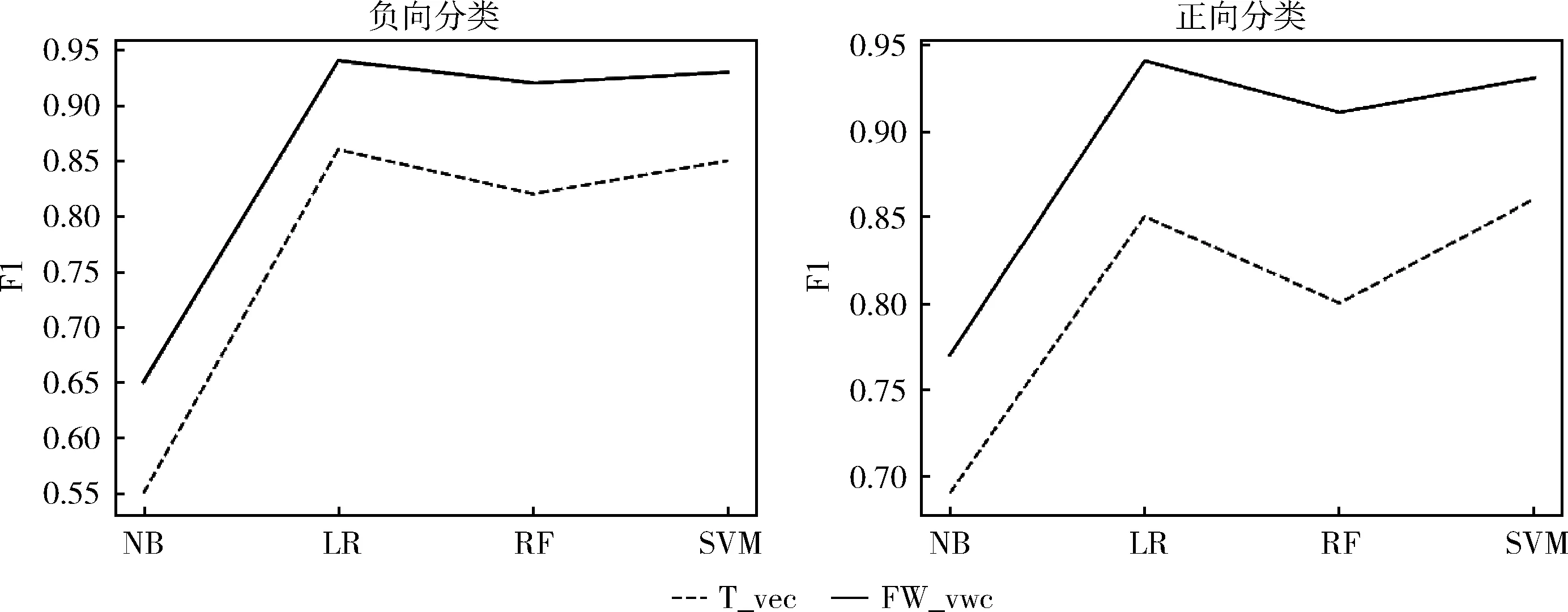
图3 T_vec和FW_vec的F1对比
图3中负向分类和正向分类的实线总是位于虚线上方,进一步说明了融合情感词权重的效果优于文本向量化。
基于图3的FW_vec,NB的分类效果在4个方法中的分类能力较低;其次是RF;SVM略低于LR。通过分析算法的实现原理可知,NB在特征假设方面具有较强的独立性,灵活性不高,从而限制了分类效果。RF是通过多个决策树的结果来分类进行决策;由于在构建决策树时可能存在多个相同的决策树,导致决策结果不准确;另一方面可能是由于数据不充分。LR在特征假设方面具有较强的灵活性,即使特征之间没有相关,逻辑回归也可以找到最优参数。SVM使用支持向量,即和分类最相关的一些点来学习分类器。
通过图3以及表4和图2的分析,这里选择了LR用于后续情感强度实验。
4.2 情感强度实验结果分析
由情感倾向实验结果可知,LR的分类效果在4种机器学习方法中表现较好,因此在情感强度分析部分,使用LR预测情感倾向。根据情感强度设计的计算规则,实验结果见表5。
在实验二中通过网格搜索方法搜索术语词的最佳权重为1.9、1.6、1.5(分别对应HIV、MIV、LIV)。从表5可知实验二的Y值比实验一的Y值小,说明实验二的分析结果更接近专家标注的情感强度。另一方面说明,将外汇新闻的特点融合到情感强度计算中比仅考虑程度词的结果更理想。图4给出了部分实验结果。
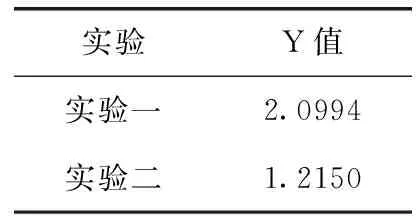
表5 情感强度实验结果
图4中横轴代表新闻,纵轴代表情感强度,数据显示了实验二的情感强度比实验一的情感强度更接近专家标注值。
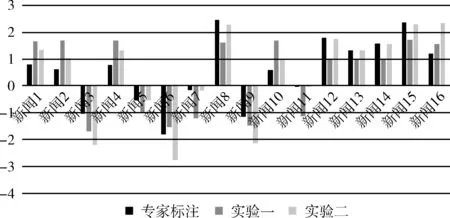
图4 情感强度实验对比结果
最后,本文综合上述对外汇新闻情感倾向和情感强度的分析,得出外汇新闻的细粒度情感分析元组,见表6。

表6 情感分析元组
表6中情感元组的第一列代表新闻中的评价对象,第二列代表评价对象的属性,第三列代表情感强度(正负表示情感倾向)。
5 结束语
本文基于机器学习的方法研究外汇新闻的情感倾向和情感强度。在情感倾向方面,利用朴素贝叶斯、逻辑回归、随机森林和支持向量机挖掘外汇新闻情感。通过分析文本向量化和融合情感词权重两种情况下的实验结果,并结合混淆矩阵,得出融合情感词的分类效果优于文本向量化的分类效果。在情感强度分析方面,设置了两个对比实验,实验结果表明,情感强度结合新闻中的程度词和外汇领域的特征词更接近专家标注的情感强度。本文对外汇新闻情感倾向和情感强度的分析,为外汇领域资产定价、风险评估和汇率预测提供了参考价值。
由于本文的情感强度是针对外汇新闻,对其它领域的适用性有待提高。如何构建更高效,可扩展性强的情感强度分析方法,是未来工作的一个研究重点。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
高技术通讯(2021年1期)2021-03-29 02:29:24
文苑(2019年24期)2020-01-06 12:06:50
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电脑与电信(2018年11期)2018-02-16 05:41:32
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
