
基于中层特征的细粒度的车型识别
2020-06-12 09:18:02宋岩贝何冰倩
计算机工程与设计 2020年6期
宋岩贝,魏 维,何冰倩
(成都信息工程大学 计算机学院,四川 成都 610255)
0 引 言
随着我国经济发展水平的不断提高,汽车数量不断增加,在给人民带来极大便利的同时也为社会的管理治理提出了更高的要求。以智能停车场系统为例,该类系统拍摄的照片大都以车辆正面图片为主,因此本文以车辆的正面图片作为研究的出发点。目前基于视频图像的车型识别方法主要分为3个方向:①基于模型;②基于浅层特征;③基于深层特征。
基于模型的车型识别方法核心思想是对车辆的二维图片进行重新建模,然后使用模型进行车型匹配,如3D模型[1,2]、线框模型、示意图模型等。但由于这些模型只能反映出不同车型之间的形状差异,因此大多只能用于粗粒度车型分类[3],如货车、轿车、摩托车等。
对于细粒度车型识别[4,5],以SIFT[6]、SURF[7,8]等特征描述子为代表的浅层特征[9,10]和以卷积神经网络为基础的深层特征是细粒度分类主要用到的两种方法。浅层特征的缺点是其表示性不好,使得识别准确率不高,而深层特征的提取往往需要借助额外的语义标注才能取得较好的效果。因此本文提出了一种基于中层特征的细粒度车型识别算法,所提取的中层特征表示性好于浅层特征,同时又不需要高层特征所需的额外的标注,能够有效地提高细粒度车型识别的准确率,非常适合计算资源较为紧张的情景。
1 车脸定位
本文采用基于Adaboost的车脸定位算法。Adaboost算法最早由Viola等运用在人脸识别检测[11]领域,并取得了很好的效果。近年来也有许多学者将其用于车脸定位。该算法的核心是训练多个弱分类器,然后将多个弱分类器组合成一个强分类器。
首先初始化训练样本的权重,设总共有N个样本,第i个样本的权重Wi如式(1)
(1)
弱分类器hk定义如式(2)下,p表示阈值
(2)
某分类器在训练集上的误差ek如式(3)所示
(3)
根据误差计算该分类器的权重ak,式(4)
(4)
更新权重分布如式(5)所示,Zk为归一化常数
(5)
最后按权重组合弱分类器,如式(6)所示。车脸定位的效果如图1所示
(6)

图1 车脸定位效果
2 中层特征提取
图像的特征按层次可分为低层特征,中层特征和高层特征[12]。低层特征像如SIFT,SURF等一些特征描述子。虽然这些算子在绝大多数的分类场景中可以取得很高的准确率,但其也有明显的不足。这些算子只能描述当前这个像素点周围很小范围内的变化情况,无法描述该区域在全局中的重要性情况,无法在车辆型号的精细划分的任务中取得令人满意的效果。而高层特征与低层的纹理、颜色等特征是没有直接关系的,若要使用则需要对图像进行语义等相关特殊标记,需要数据集的支持,由于我们所用的数据集为自己采集的各个品牌车辆的正面照,并不包含相关的标记,所以这里我们将低层特征进行了一些组合使其成为更具全局性的中层特征-patch。
图2列举了5类车型经过本文算法提取到的patch组合,每组取了5个作为展示。

图2 重要性patch
首先为每一幅经过车脸定位的图片建立其图像下采样金字塔,提取每个样本的多尺度patch,这样就形成了patch候选集。接下来的主要工作将是如何从候选集中选取有价值的patch。
要解决这个问题,首先要定义何为重要。对于车辆的前脸图片而言,虽然车型不同,但有许多外观特征是共有的,例如会有较大面积的纯色色块,这些特征会极大影响分类的准确性,应当去除。相反,对于那些每个系列车型独有的特征应当充分重视,所以我们寻找patch的原则有两点:①同类型中频繁出现;②不同类型中几乎不出现。在实现过程中这两点必须是同时满足的。换言之,重要性patch的定义:①簇内高频性;②簇间差异性。
根据patch的定义,首先要满足簇内高频性,最常用也是最直接的方法就是Kmeans聚类,将每一类样本的所有patch放到一起单独进行聚类,找出K个具有代表性的patch簇,很容易就可以满足patch高频性的要求。对于簇间差异性的要求,我们的方法是使用分类解决,将上一步聚类聚成的K个簇使用支持向量机训练出K个特征检测器。训练的正样本为该簇的簇内成员,负样本为除本类样本外的其它类样本patch。假设目前的K个监测器是最理想的K个,那么就可以使用这K个检测器提取本类最具代表性和鉴别意义的特征。
一次聚类后会有多个无效簇,因此需要对其进行一定的筛选。由于进行聚类的样本是来自同类车型的样本,所以理想状况下每个簇内的patch应当只来自本类的图片且囊括本类型的所有样本。因此可以从以下两个方面对簇进行优化:①去除来自同一幅图片的成员;②去除成员类别过于杂乱的簇。
patch的提取流程如图3所示。本文使用简单阈值法和交叉验证相结合的方法进行patch筛选。首先把原始数据集分为D1、D2两部分。在D1使用一次kmeans将所有patch聚成K个簇,对聚成的K个簇进行个数检测,去除个数小于4的簇,该方法可以去除60%的无效簇。然后将过滤后的簇使用SVM训练成检测器。将D1中训练出的检测器放到D2中运行,在D2中生成新的簇成员。使用新的簇训练新的检测器。再送入D1中运行,如此迭代运行直至收敛。每一次迭代需要更新该簇的鉴别分数,鉴别分数的定义为
(7)
Nneg为该簇在其它类patch中的响应次数,Nall为该簇在所有样本中的响应次数。该分数越高说明当前簇的鉴别意义越大。最后根据每个簇的分数,对所有检测器进行排序,选择每类中鉴别分数高的N个检测器作为特征。算法流程见表1。
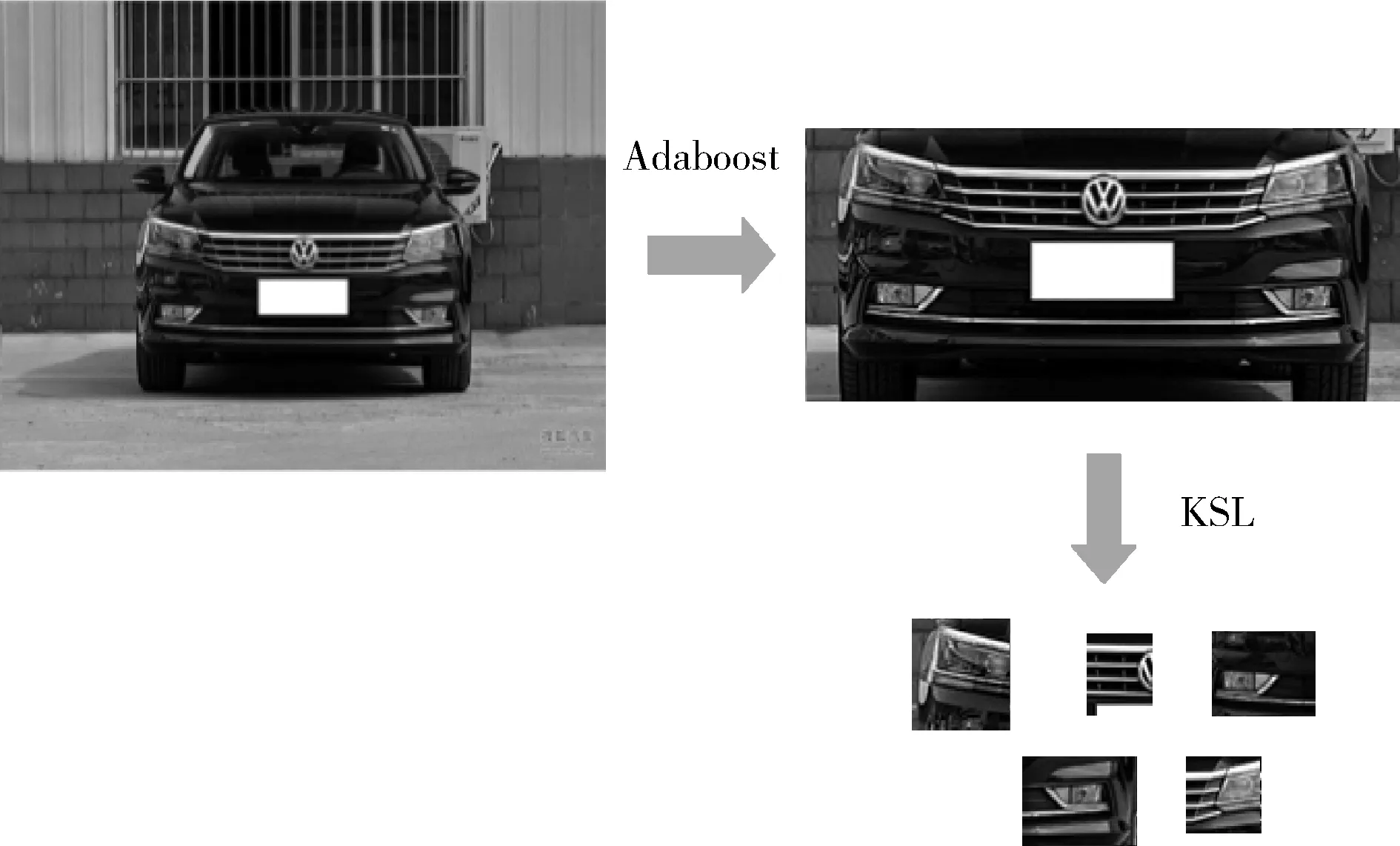
图3 patch提取过程

表1 算法详解
3 特征编码
现有比较典型的特征编码方式有BOW词包算法,SPM空间金字塔匹配等。词包算法(Bag of words)[13]最初应用于文本检索领域,后被引入计算机视觉领域。其核心思想是在全局范围内找出K个具有代表性的视觉词组成视觉词典,然后分区域统计响应直方图,用1*K的一维向量表示一幅图片。但是这种方法有很明显的缺陷,对于整幅图片来说,所有的位置信息都被丢弃了,所以在BOW的基础上,S-Lazebnik等提出了一种新的方法空间金字塔匹配[14](spatial pyramid matching),这种方法将图片分为大小不同的金字塔状的块,然后分别统计每个子块的特征,最后再将所有子块的特征拼接成一个一维向量。因此我们前面在patch筛选的时候结合了这两种算法的思想,既考虑到代表性同样兼顾位置信息。那么在学习到有效的patch之后,如何利用这些patch呢?
假设总共有C类车系,每类车系各有k的检测器,设特征向量为:Vi(1,2,3,…,C*k),默认值为0。每一列的数值对应一个检测器。向量Vi可以理解为某个样本对于C*k个检测器的响应程度,若某个检测器产生响应,则将向量Vi对应位置上的值置为1,否则为0。这样统计每个样本的对C*k个检测器的相应程度,所有训练样本的矩阵可表示为V=[V1,V2,…,VC*M]。最后使用Linear-SVM分类。
4 实验结果与分析
本文所用的数据集为从各大汽车论坛搜集到的各类品牌车型的正面照,主要涉及大众和奥迪两个品牌,其中,大众包括桑塔纳、捷达、速腾、polo、高尔夫、朗逸、宝来、帕萨特8种车型,奥迪包括A3、A4、A6这3种车型,如图4所示。之所以只选择这两个品牌是因为奥迪和大众两个品牌的家族化设计语言相比于其它品牌要强烈的多,两个品牌旗下各个系列车型间的外观差距也较其它车型之间小的多,更具代表性,可以更好检测我们算法的有效性。数据集中共有11种车型共1100张图片。每类车型取60%用于训练,40%进行测试。

图4 训练数据
车脸定位选取5000张仅含有不同品牌车脸的图片作为正样本,负样本为5000张不包含汽车的任意自然图片,将所有样本归一化为100*200。在windows环境下,CPU为i3-8100,内存16 G,使用opencv自带的训练器,使用Haar特征,训练17个周期。
将经过车脸定位的图片的大小统一设置为200*500*3,对于图像的金字塔特征,设置patch的大小最小为80*80,最大不得超过图像的大小,步长为8,提取每个patch的HOG特征。
在使用K-means进行聚类时。遇到的第一个问题是中心个数的设置,所以本文首先测试不同个数的中心对系统系能的影响,选取了中心个数分别为20、70、120、170、220这5组进行测试,实验效果如图5所示,横坐标1-5分别代表5组不同个数的实例,由图可知不同个数的中心和预测准确性影响不大,原因是因为特征向量是由C*k个检测器拼接而成,检测器的区分性才是影响准确率的重要因素之一。而且随着中心数量的增多,处理每张图片的耗时从0.22 s增长到1.79 s,时间复杂度大幅增加。但对准确率的变化影响不大,因此从时间效率的角度考虑,本文在实验中将中心个数设为20。
在提取图像的金字塔特征时,首先规定patch的大小,最小为60*60,最大为200*500。其次是金字塔的层数,不同层数的金字塔下系统的准确性和时间效率的表现如图6所示。x轴表示的是金字塔的层数。在3层时准确性达到95%,仅耗时0.4 s。在增加到6层后,准确率提升了1%,编码耗时增加到了0.6 s。在多于6层后准确性不断下滑,原因是特征维数随金字塔层数的增加而不断增加,导致了模型的过拟合。综合考虑金字塔的层数设为6。

图5 中心个数对系统效率影响
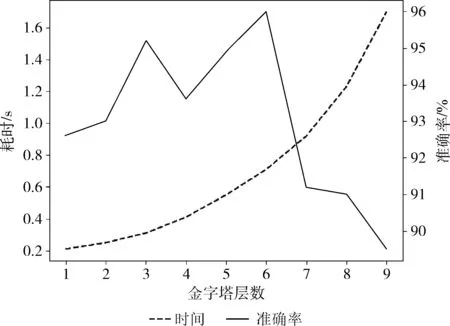
图6 金字塔层数对系统效率影响
为了进一步验证本文算法的有效性,引入了6组对比实验,分别是:词包算法(BOW)、空间金字塔匹配(SPM)、改进的SPM算法、基于稀疏编码的空间金字塔(ScSpm)、局部约束线性编码(LLC)和CNN。
详细的实验数据见表2,ScSpm算法主要是使用稀疏编码替代K-means并引用Max pooling替代SPM的Ave-rage pooling。LLC则认为局部性比稀疏性更重要。因此引入了局部约束的概念。
CNN模型使用的是Jie等提出的模型,由一个包含5个卷积层,3个池化层和3个全连接层的CN模型结合SVM进行分类。为了满足CNN模型大数据集的要求,对现有数据集进行增强,分别使用随机对比度变化、随机饱和度变化、随机色域变化和增加高斯噪声4种方法。将数据集扩充为35 200张。
原始的BOW和SPM算法准确率极低,改进后的SPM在加大了车灯和散热栅格区域的权重后表现有所提高。引入稀疏编码[15,16]后,ScSpm的准确率比改进后的SPM算法提高了3%,与原始SPM相比提高了13%。与Jie等[17]提出的CNN模型相比,本文提出的算法在识别准确率更高。
表2的实验数据主要是基于两个品牌不同的子的系列车型进行识别,除此之外,还进行了不同品牌间车型识别的实验见表3。可见Jie等的算法在对不同品牌间的车辆识别时有较高的准确率,但在同一品牌子系列车型的识别准确率比本文算法低了7%。
相比于前6种算法,本文算法的识别准确率有巨大的提升,平均准确率达到了95.65,同时本算法的时间复杂度并没有过大,平均每个样本的编码时间为0.82 s,识别耗时0.0032 s。
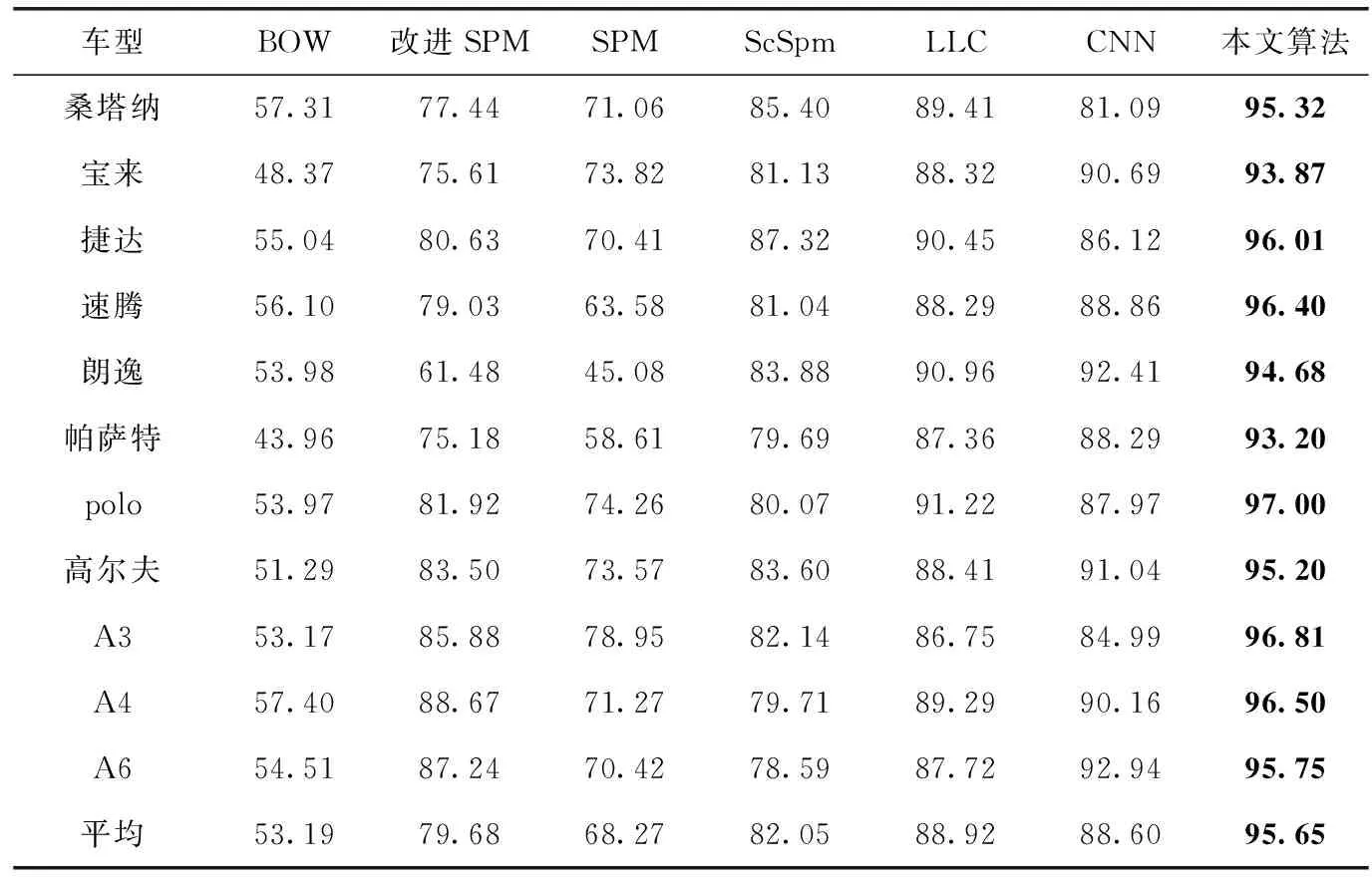
表2 实验表1/%
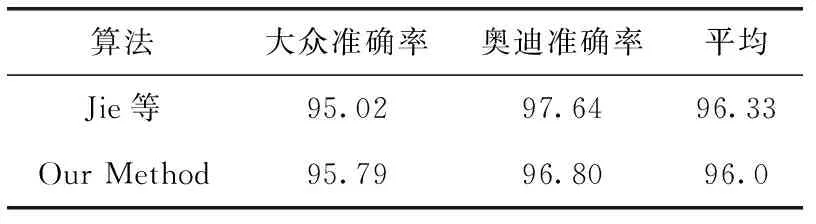
表3 实验表2
5 结束语
本文以车辆的前脸图片为出发点,以智能停车场等作为应用场景,主要针对同一品牌不同车系的车型分类进行了研究,对于不同车系之间差距小、特征选择难的问题,提出了一种基于中层特征的特征自动筛选(KSI)算法,该算法能自适应选取各类车系的最具标识性的特征,在细粒度车型分类的任务中取得了高于主流深度学习方法的准确率,尤其在智能停车场、智能交通监控等计算资源不足的情况下,本文的方法更具可实施性。
猜你喜欢
环球时报(2022-09-19)2022-09-19 17:19:22
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
电子测试(2018年1期)2018-04-18 11:52:35
中国交通信息化(2017年9期)2017-06-06 07:14:57
童话世界(2017年11期)2017-05-17 05:28:25
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
工业设计(2016年11期)2016-04-16 02:49:43
电测与仪表(2014年15期)2014-04-04 12:05:20
