
基于自注意力的扩展卷积神经网络情感分类
2020-06-12 09:17:50陆敬筠
计算机工程与设计 2020年6期
陆敬筠,龚 玉
(南京工业大学 经济与管理学院,江苏 南京 211816)
0 引 言
近些年,对文本情感分析[1,2]中,以深度学习的卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)为主要方法,同时以注意力机制(Attention mechanism)对上述的模型进行优化[3]。虽然,文本情感分析取得相较于机器学习算法的准确率得到很好的信息,但是现有LSTM、GRU模型只关注局部特征,未结合未来的信息,在文本中体现为未结合上下文进行分析,同时还存在对文本训练时间过长的问题[4]。卷积神经网络中将词或者字符编码矩阵转化为向量过程中包含位置信息较少,同时现有注意力方式缺少词在句子整体的语义信息。
本文针对上述问题提出了一种基于自注意力-扩展卷积神经网络模型,来丰富句子中词或者字符的位置信息,编码矩阵转化为向量过程中变得更加准确,同时引入自注意力机制增加词在句子中的语义信息,同时减少训练时间,为了学习到未来的信息在本文模型中引入双向GRU网络。
1 相关研究
文本情感分析属于自然处理一个分支,其主要目标是识别文本的情感倾向。随着深度学习在自然语言处理中取得不错发展,将文本情感分析推到一个新的发展高度[5]。刘秋慧等摈弃情感词典方式,仅以少量人工标注,采用递归神经网络中将句子包含词语标签联系起来,从而对文本情感分类[6]。Giatsoglou等利用现有分词Word2Vec将上下文和词典情感分析结合,以词嵌入方式来将情感词与上下文相结合[7]。王业沛等以模糊匹配方式从裁判文书抽取实体,将结果通过LSTM模型进行情感倾向性判别[8]。Ruder等提出双层双向的LSTM网络进行文本情感分析,以不同方向LSTM学习句子内部和句子之间的特征来进行学习,从而对文本包含的属性进行判别[9]。张玉环等利用LSTM和变形GRU相结合构建文本情感分析的模型,在实验阶段创新性采用伪梯度下降来调整模型参数,实验结果表明在较短时间内得到较高正确率[10]。
最近,Attention在深度学习领域流行起来,其最早是由谷歌公司应用在图像分类中,其将RNN(循环神经网络)和Attention相结合来构建模型。Attention机制在自然语言领域也取得长足的发展[11]。Yin等尝试CNN和Attention机制相结合,分别进行3种实验:CNN的输入之前加入Attention;在CNN对特征提取之后,和池化层之前加入Attention机制;上述两种方式相结合的Attention机制[12]。曾义夫等根据循环网络学习序列能力得到语句编码,利用Attention机制从中提取带有情感表达语句编码,构建出两个外部记忆分别用来获取语句编码和词语级别信息,设计出一个解码器,从中选择情感语义信息[13]。程艳等利用卷积层学习词向量之间的关联,再将得到的结果输入到RNN中层次化Attention来判断其情感倾向[14]。
2 理论与模型
2.1 扩展卷积神经网络
CNN卷积神经网络在文本中应用也越来越广泛。一般CNN将词或者字符转化为向量形式,需要经过不同卷积核的卷积、池化、激励函数等不同的操作来得到向量输出[4]。一般CNN可以获取句子中不同词和字符之间的关系,以多个不同卷积核来达到该目标,该方法除了卷积时间和操作量,还存在内存“爆炸”的可能性。本文采用扩展CNN以两层等长扩展卷积来表示,除了提高运行速度和降低计算参数外,还可以增加该词在该位置上的词义上的信息。图1表示3*3扩展卷积核结构图:第一层卷积核感受野为3个词或者字符的信息,第二层卷积核感受野为6个词或者字符的信息,边缘以padding进行补足,保证矩阵长度和词向量长度一致性。图2表示扩展CNN卷积编码结构图,在本文中通过扩展CNN对词和字符进行编码,编码前提是需要分词后句子矩阵分词后词向量的维度保持一致。当前表示文本中第j句子,其中词的位置在i上,则该词可以表示为xij∈Rd,其中,d表示在d维空间中。句子中每个分词结果都可以学习到Pij位置编码。每个词bij的编码公式如式(1)所示
bij=xij+Pij
(1)
卷积核Cn∈Rs*d(n=1,2,3,…,d)对词产生的编码矩阵操作。其中,s代表卷积核大小,n代表的是卷积核数量,卷积核数量为分词数量的2倍。

图1 3*3扩展卷积核
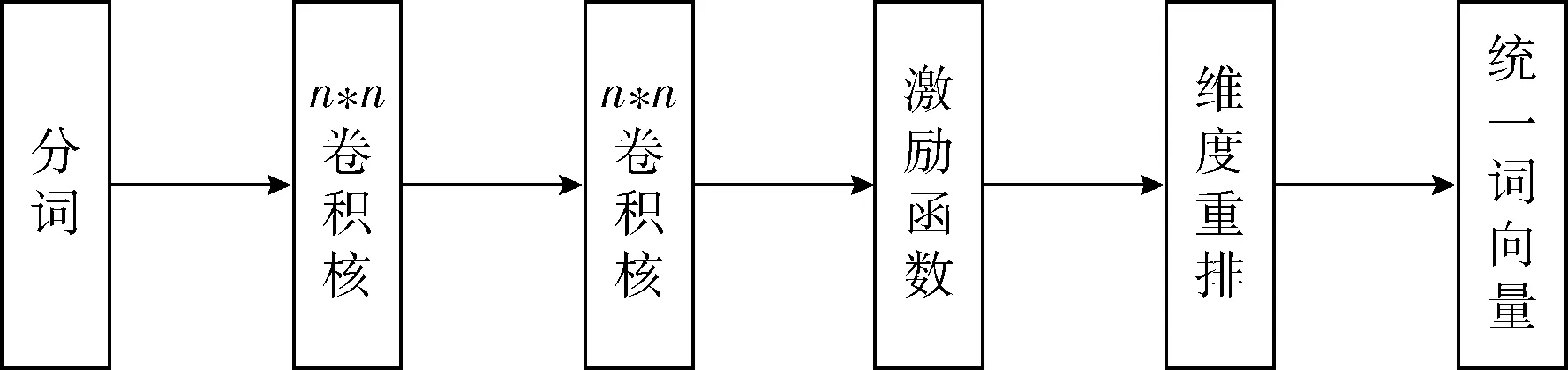
图2 扩展卷积结构
bij词编码在两层扩展卷积和激励函数后得到编码向量表示形式为
(2)
对其中元素计算公式如式(3)所示
(3)
式(3)中表示对词位置编码矩阵元素进行点乘后求和。f函数表示非线性函数。文本中第j个句子经过扩展卷积的序列表示形式zjw。其中,w∈[1,W],W表示句子中分词总数。
2.2 双向GRU网络
LSTM在自然语言处理中广泛应用中,存在着梯度回传速度过慢,训练困难,结构过于复杂等缺点。Cho提出GRU网络将LSTM网络中输入门、输出门和遗忘门转变成更新门、重置门,从而减少网络中的参数,收敛速度加快,网络结构也变更加简单。GRU网络的更新门作用是控制前一个时刻输出隐藏层的状态对当前时刻输出神经元的状态影响状况。更新门的值越大,前一时刻对当前时刻神经元输出值影响程度越大。重置门的作用是控制着前一时刻中神经元包含信息的忽略程度。GRU网络的结构模型如图3所示。
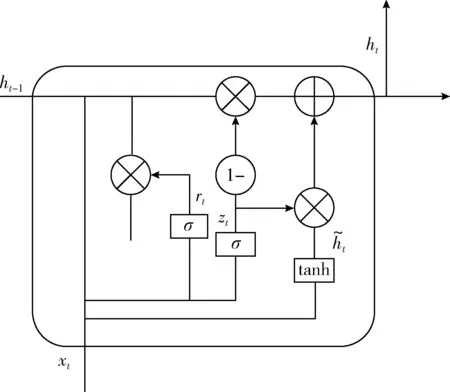
图3 GRU网络结构
GRU网络中是由重置门r和更新门z组成,控制着网络中神经元的读写操作计算公式如式(4)-式(7)所示
(4)
(5)
(6)
(7)

GRU网络模型是从上文开始向下文读取,导致下文产生词比上文词权重比更大。下文词的信息无法传递,GRU网络神经元应该是由前向传输值和后向传输值共同计算的结果。双向GRU网络结构模型如图4所示。
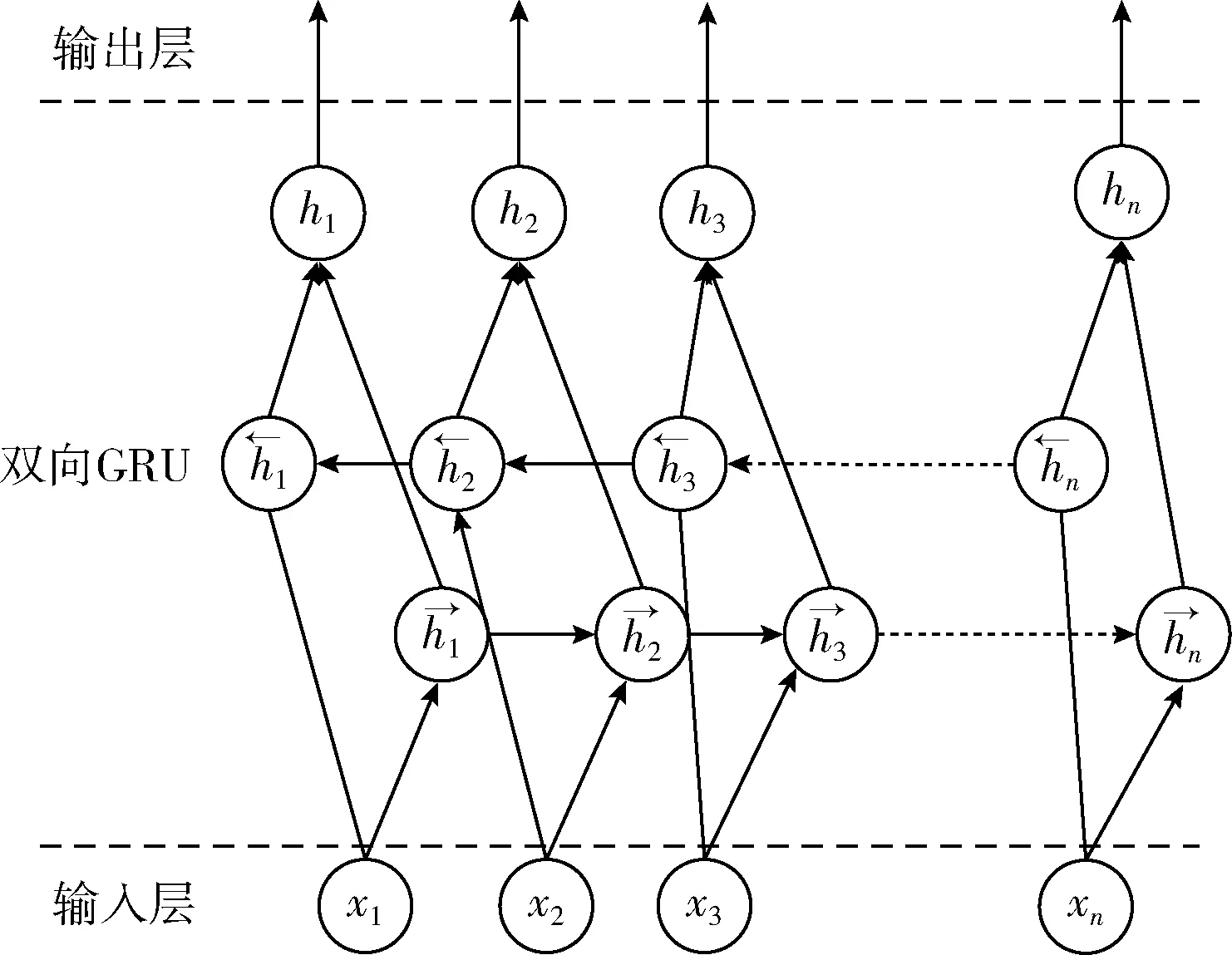
图4 双向GRU网络
2.3 自注意力机制
2014年(Bahdanau)Attention机制应用在机器翻译中,后来广泛使用在知识图谱、语音识别等方向。Attention机制可以作为网络单独使用,可以混合到其它模型层混合。混合其它模型使用,将文本以编码矩阵形式输入到其它网络中经过训练后,对得到的数据通过Attention机制给予不同词和字符编码矩阵权重。Attention机制将不同位置上词或者字符联系起来,同时突出重点词,从而改变系统性能。Attention机制产生是模拟人的观察事件的能力,其对关键信息在进行分配时候,增加其关键信息的权重。Attention 机制基本结构模型一般分为两种模块,分别是编码器和解码器。输出值yi计算公式如式(8)所示
yi=F(Ci,y1,y2…,yi-1)
(8)
其中,Ci是对输出语义编码,该语义编码器受输入分布的影响,语义编码器如式(9)所示
(9)
其中,E(xi)表示输入神经元中的数据编码,n表示输入词或者字符的数目。E(xi)表示输入i对输出yi的注意力分配率,计算公式如式(10)和式(11)所示
(10)
eij=Vtanh(Whi+Usj-1+b)
(11)
其中,eij表示在输入的第i个词或者字符对j个输出的影响。hi表示输入的第i个词或者字符的编码,sj-1表示上一个神经元输出的编码矩阵,W、U和V表示是在训练过程中学习到的参数。b表示是函数的偏置。本文采用是的自注意力机制加入情感分析网络。自我注意力机制通过引入权重向量A控制对词或字符的影响。比如,在句子“我喜欢这家餐馆饭菜”中,“我”和“喜欢”组合对这句话有情感帮助,需要给予前者更多的注意力,后者给予更小的注意力。自注意力结构模型实现如图5所示。
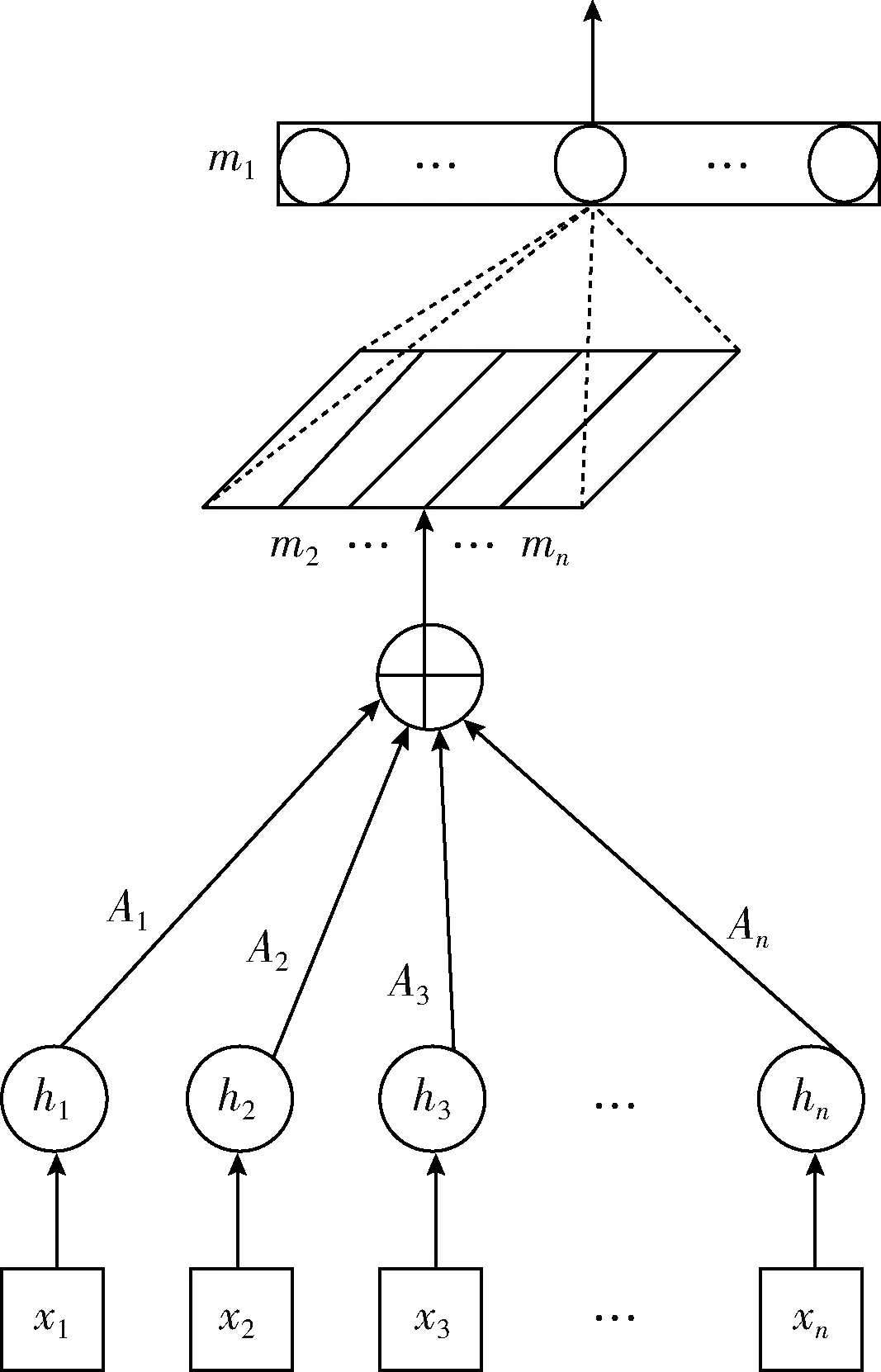
图5 自注意力模型
2.4 基于自注意力的扩展卷积网络结构
j∈[1,l]本文在提出扩展卷积的基础上引入双向GRU和自注意力机制的文本情感分析网络模型。该模型先采用扩展卷积网络操作对词或者字符初始化的模块,模型结构如图6所示。在图6中将句子中通过扩展卷积网络转化为序列向量的形式。文本a中包含l个句子,将第j个句子转化成n个单词或者字符,即转化形式为:Wj={wj1,wj2,…,wjn},其中j∈[1,l]。扩展卷积网络对词或者字符编码矩阵转化为统一向量维度。双向GRU网络是由前向和反向GRU两部分组成。通过GRU网络可以充分学习上下文之间的关系,可以充分学习上下文关系进行编码,计算公式如式(12)所示
hjn=BiGRU(vjn)
(12)

图6 基于自注意力的扩展卷积网络
完成上下文关系学习后,加入自注意力制来给每个词或者字符分配权重,进一步提取语句中关键的词或者字符,尤其是长句学习(两个子句的连接),所以需要将注意力放到不同部分进行多次注意,生成注意权重矩阵A形式如式(13)所示
A=softmax(Ws1tanh(Ws2HT))
(13)
其中,HT表示输入的向量,Ws1和Ws2表示学习到的参数,softmax函数是对结果归一化。式(13)将嵌入向量转变成嵌入矩阵M。隐藏状态层状态HT和权重矩重相乘得到句子嵌入矩阵式(14)
M=AH
(14)
最后经过softmax层进行情感分析计算结果如式(15)所示
p=softmax(Ws3+b)
(15)
其中,Ws3表示是参数矩阵,b表示的是偏置矩阵。最小化损失函数如式(16)所示
(16)
其中,d表示句子j对应的情感标签。
3 实验分析
验证自注意力-扩展卷积模型的有效性,选择公开IMDB和SSTB数据集进行验证。训练集和测试集按照8∶2的标准划分,划分详细情况见表1。
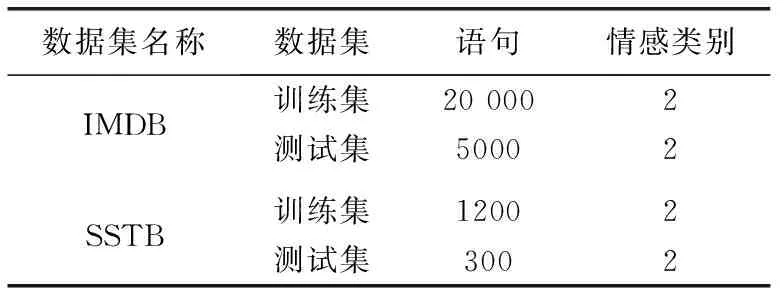
表1 数据集详细情况
对自注意力-扩展卷积网络模型训练中设置卷积核大小为3*3,词向量维度和卷积层输出通道数量相同,对实验中超参数设置见表2。

表2 模型参数情况
3.1 对比实验
本文对自注意力-扩展卷积网络模型的评价指标:准确率(Precision)、召回率(Recall)和迭代时间。表3表示二分类的混淆矩阵(confusion matrix),TP(true positive)表示文本情感分类为正类,模型实际预测的文本情感为正类的数量。FN(false negative)表示文本情感分类为负类,模型实际预测的文本情感为负类的数量。FP(false posositve)表示文本情感分类为负类,模型实际预测的文本情感为正类的数量。TN(true negative)表示文本情感分类为正类,模型实际预测的文本情感为负类的数量[15]。
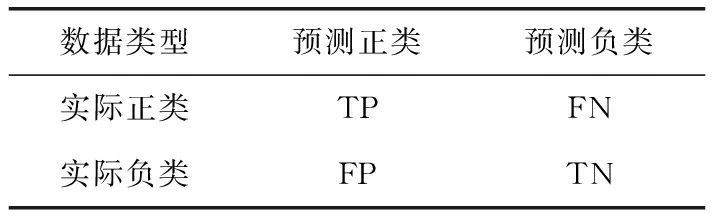
表3 二分法混淆矩阵说明
文本的准确率计算式(17)
(17)
文本的召回率计算式(18)
(18)
迭代时间计算以10次迭代过程中每次的时间进行加权后取平均数。
自注意力-扩展卷积模型与现有模型对比情况如下:
(1)BiLSTM-CNN模型。李洋等通过CNN卷积神经网络和BiLSTM模型相结合,分为3层:词嵌入层,卷积层提取局部特征,最大池化操作[16]。
(2)BiGRU-Attention模型。王伟等提出BiGRU-Attention模型划分为输入层、隐含层和输出层。其中,输入层是将文本向量化,隐藏层是由BiGRU、Attention、Dense这3部分组成。BiLSTM-Attention模型是将BiGRU-Attention模型中隐藏层BiGRU变为BiLSTM[17]。
(3)ASC模型。Rozental等采用双向的Bi-LSTM对文本特征处理和对数据降维,加入最大池化层对文本中影响情感信息进行突出,从4个维度对得到的信息处理,最后加入softmax层分类的网络模型[18]。
(4)DB-LSTM-RNN模型。刘建兴等采用分布式方法来对词嵌入的方法表示,用DB-LSTM对文本序列学习,在池化层学习到深层次表示后,输入到分类器中分类[19]。
3.2 实验结果分析
本次实验10次迭代过程,在测试集上的准确率为模型的准确率,测试集上的召回率为模型的召回率,测试集上的迭代时间为模型的迭代时间,本文自注意力-扩展卷积网络模型(Self-Attention-KCNN)。
(1)本文将自注意力-扩展卷积网络模型与BiLSTM-CNN模型、BiGRU-Attention模型、BiLSTM-Attention模型、ASC模型、DB-LSTM-RNN模型在训练集上训练后,然后在测试集上测试,得到准确率、召回率与迭代次数之间关系,如图7和8所示。

图7 迭代次数与准确率
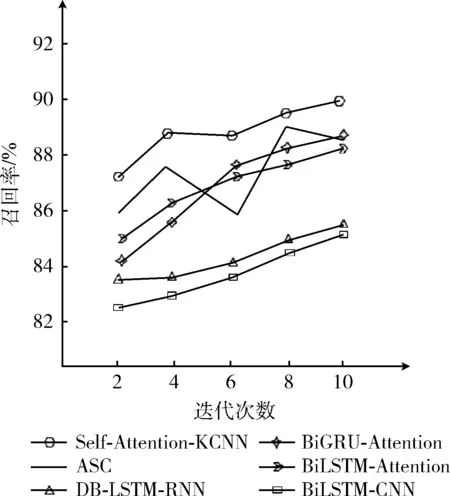
图8 迭代次数与召回率
从图7和图8中可以看出模型之间从下往上看准确率和召回率的值不断提高,其中,本文自注意力-扩展卷积神经网络准确率和召回率的值最高。本文Self-Attention-KCNN模型准确率高于BiGRU-Attention模型,突出自注意力相比注意力的优越性,词或者字符可以获取全局语义信息,KCNN模型相比较CNN可以扩展感受野,增加词或者字符的位置信息,从而获得深度的文本特征,提高准确率和召回率。Self-Attention-KCNN模型迭代次数越多,其召回率和准确率越高。从总体上看,Self-Attention-KCNN模型在准确率和召回率较高,但是值变化幅度较大。从ASC模型上来看不是迭代次数越高,训练数据效果越好。从本模型上看,Self-Attention-KCNN模型多次迭代是可以提高准确率和召回率。
(2)迭代时间是指在完成一次迭代时间,从图9中给出在相同时间下进行迭代所花费的时间趋势。

图9 代价时间和迭代次数
从图9中可以看出,各个不同模型在不同迭代时间总体上平滑,一般经过多次迭代后,再次训练之后,代价时间趋于稳定;BiGRU-Attention模型完成一次迭代时间最短,模型收敛速度最快,与隐藏层采用BiGRU和Attention有关。BiGRU-Attention和BiLSTM-Attention模型区别在于BiGRU和BiLSTM不同引起,二者迭代时间不同,表明BiGRU模型收敛速度更快、需要计算的参数更少。DB-LSTM-RNN模型最高是因为RNN收敛速度慢,参数较多,收敛速度较慢。本文Self-Attention-KCNN模型慢于BiGRU-Attention模型在于增加扩展卷积网络增加训练时间。
本文将Self-Attention-KCNN模型与BiLSTM-CNN、BiGRU-Attention、BiLSTM-Attention、ASC、DB-LSTM-RNN模型对比,将不同迭代次数相加取平均值结果见表4。

表4 不同模型对比结果
从表4中可以看出,本文所提出基于Self-Attention-KCNN模型在准确率、召回率和迭代时间值远远优于其余5种模型。
4 结束语
本文提出了一种基于自注意力-扩展卷积神经网络模型,比目前广泛使用的卷积神经网络和注意力模型的混合模型,可以提高准确率和召回率,同时降低迭代时间。从网络结构说明,一方面扩展卷积网络比卷积神经网络,通过设置并行卷积核将输入词和字符的编码矩阵转化为向量增加更多位置编码,得到效果更佳。另外一方面说明Attention模型和Self-Attention模型效果更佳,可以取得更好词和字符的语义编码。本文模型在IMDB和SSTB数据集上性能评价的准确率、召回率和迭代时间优于其它模型。本文情感分析只是进行二分类,现实生活中的情感存在多样化,采用本文的自注意力-扩展卷积神经网络进一步研究文本多分类的情况。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
传媒评论(2017年3期)2017-06-13 09:18:10
