
反向梯度优化深度学习的病毒数据对抗方法
2020-06-12 11:42:14赵荷,盖玲
计算机工程与设计 2020年6期
赵 荷,盖 玲
(1.成都东软学院 计算机科学与工程系,四川 成都 611844;2.上海大学 管理学院,上海 200444)
0 引 言
随着信息技术的普及,第三方在线服务普遍采用学习算法从海量用户数据中提取有价值信息[1]。然而,若用户数据遭受病毒攻击(如数据篡改、数据丢失等),病毒攻击者只需要控制并操纵小部分训练数据便足以破坏学习算法执行的过程和结果[2]。因此,为了评价学习算法对病毒数据的鲁棒性,生成数据病毒攻击样本显得非常有必要。
数据病毒攻击样本的生成算法本质上是一个双层优化问题,即外部优化问题需最大化清洁未受病毒攻击的验证集的分类错误,而内部优化问题则需利用病毒数据对学习算法进行训练。如文献[3]提出一个提取多步骤攻击场景的方法,该方法可有效模拟了部分数据病毒攻击场景,但采研究的数据病毒攻击方法无法覆盖所有的攻击场景,即算法适用性有待考虑。文献[4]对大规模数据库的高危攻击数据进行挖掘,提出基于粒子群优化的关联规则映射挖掘算法,但粒子群算法对离散型优化问题处理不佳,且易陷入局部最优。文献[5]提出基于蚁群算法与粒子群相结合的网络安全评估的攻击图生成方法,但蚁群算法存在收敛速度慢的缺点,对于规模庞大的用户数据而言,蚁群算法可能存在问题无解的风险。文献[6]提出了基于安卓系统的代码隐藏类规避技术检测框架,但仅针对特定类的恶意软件进行讨论,算法适用性不强。
基于上述分析,提出了一种基于反向梯度优化的深度学习算法实现病毒数据样本生成方法,主要创新点为:
(1)在总结归纳病毒数据攻击场景的基础上,提出了一种通用病毒数据样本生成模型,涵盖了多种类型病毒攻击场景,从而生成的数据病毒攻击样本的适用范围得到扩大。
(2)引入反向传播机制,通过逆向自动微分机制计算用户兴趣梯度,同时对底层学习进行反向训练以实现神经网络参数的优化调整,从而实现了在较小数量的训练迭代次数的前提下获取最优的病毒数据样本。
1 提出的病毒数据攻击样本生成算法
1.1 病毒数据攻击场景分析
在提出针对在线服务学习算法的数据病毒攻击样本生成算法之前,首先分析数据病毒种类、攻击场景,从而制作响应的攻击样本以实现对本文所提深度学习检测算法的训练。根据发动数据病毒攻击的阶段不同,可分为训练时攻击和测试时攻击两类,常被称为中毒攻击和逃避攻击[7,8],但总体上攻击场景则可分为以下两种基本类型:一般性病毒攻击方式和特定的病毒攻击方式。其它攻击方式则是这两类基本场景的衍生。
(1)一般性病毒攻击。作为数据病毒攻击最常见场景,其可导致例如双标签学习算法失效而出现拒绝服务。根据是否影响特性系统或特定用户的正常功能,该攻击场景可自然扩展到一般的多标签分类学习算法。其攻击模型如式(1)和式(2)所示
(1)
(2)
(2)特定性病毒攻击。特定性病毒攻击场景希望学习算法出现攻击方指定的最终分类结果,此类场景可用如式(3)所示的通式表示
(3)
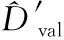
1.2 梯度下降病毒样本生成算法基本原理
对于数据病毒攻击,基于深度学习的检测算法具有较高的检测精度,但传统深度学习算法依赖于复杂的梯度计算过程[9]。
为降低问题求解难度首先作如下假设,只有一个病毒数据xc,且对应的初始标签yc由攻击者选定并始终保持不变,则病毒数据检测问题可简化为
(4)
(5)
式中:函数Φ为病毒数据xc的约束,包括其值的上限和下限。所提出的基于反向梯度的病毒数据攻击检测方法如下:通过计算函数A梯度(即损失函数L)的下降梯度,以检测病毒攻击,基于链式规则,函数A的梯度计算公式为
(6)
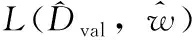
(7)
假设隐式函数是可微分的,则式(7)为一线性系统。
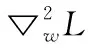
(8)
算法1:病毒攻击样本生成算法
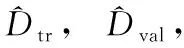
(1)i←0 (迭代计数)
(2)重复
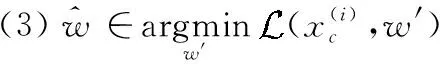
(5)
i←i+1

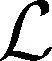
(9)
(10)
虽然这种方法可以更有效地使学习算法中毒,但它需要求解精确解,这意味着平稳性条件必须达到令人满意的数值精度。但在收敛阈值设置地过于宽松的情况下,这些问题的解只能得到有限精度,可能会使梯度▽xcA不够精确,从而影响攻击检测效果。
因此在实践中,这种方法不能用于攻击诸如神经网络和深度学习架构等学习算法的病毒数据样本生成,因为它可能不仅难以导出涉及所有参数的适当平稳性条件[10],还可能因为计算要求太高,无法以足够的精度正确计算梯度▽xcA。
1.3 基于反向梯度优化的病毒样本生成算法
为克服基于传统梯度病毒攻击检测方法的局限,提出改进的反向梯度算法。基本思想是利用学习算法执行一组迭代以替代内部迭代优化,从而更新学习参数w。所提方法允许从内部问题的不完全优化(即在有限次T迭代之后)获取参数wT来计算外部问题的期望梯度。具体内容为,设内部迭代T次后,采用反向传播的思想来计算外部目标函数的梯度,因此与传统的基于梯度的方法相比,仅需要针对学习算法进行较少数量的训练迭代,从而有效降低了大型神经网络和深度学习算法的运时间复杂度。但如果学习算法运行迭代的次数T过多,此过程可能对内存要求也会极高,特别是参数w的数量很大时(如在深度神经网络中),为了避免存储整个训练轨迹w1,…,wT和所需的前向梯度,选择在反向传递期间直接计算参数。传统梯度下降算法和所提反向梯度算法的计算流程分别如算法2和算法3所示。
算法2:传统梯度下降算法
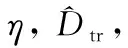
(1)Fort=0,…,T-1do
(3)wt+1←wt-ηgt
(4)Endfor
输出: 训练参数wT
算法3: 提出的反向梯度下降算法
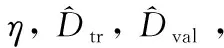
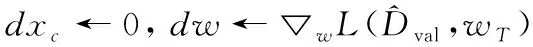
(1)Fort=T,…,1do
(5)wt-1=wt+αgt-1
(6)Endfor
输出:▽xcA=▽xcL+dxc
2 实验结果与分析
为验证所提算法对不同场景的适应性,首先对比分析传统梯度下降算法[9]和本文所提反向梯度优化算法的性能优劣性,并通过设置垃圾邮件过滤、恶意软件检测和手写数字识别等3个应用场景,再次对比研究通用性攻击方式和特定性攻击方式下典型的机器学习算法在不同应用场景下的表现性能。实验结果较为明显地显示基于所提出的反向梯度优化算法在病毒数据检测和识别上较传统梯度下降算法具有更好性能和准确性,通过不同攻击方式的对比分析还发现,所提方法对不同攻击方式下的数据识别检测具有良好的适用性,因此相较于传统方法具有更广泛的适用范围。
2.1 反向梯度优化算法性能分析
以病毒攻击3类逻辑分类器为例进行阐述,训练样本选择为100个,验证样本则选择为31个,采用所提反向梯度优化算法时迭代次数T选择为60。图1示出了通用性攻击(第一行)和特定性攻击(第二行)两种场景下的分类结果。
在特定性攻击中,攻击者目标将灰色标记的数据错误地分类为黑色标记的数据,但同时保留其它数据点的标签。图1中第一列为清洁数据的分类结果,而第二列为病毒数据攻击后的分类结果,第三列为传统梯度优化算法[9]的损失函数,而第四列为所提反向梯度优化算法的损失函数。横向对比第三列和第四列,对于通用性攻击,所提反向梯度优化算法的损失误差比传统梯度下降算法低58.7%;对于特定性攻击,所提反向梯度优化算法的损失误差比传统梯度下降算法[9]低71.2%。根据前文中损失函数定义,表明所提反向梯度优化算法能够有效降低病毒数据对清洁数据的影响。而纵向对比图1第三列和第四列,可知无论是传统梯度下降算法还是所提反向梯度优化算法,在特定性攻击场景下,病毒数据对清洁数据的影响程度都更为严重。
2.2 垃圾邮件过滤和恶意软件检测
在垃圾邮件过滤和恶意软件检测两个应用场景下,实验考虑两个不同的数据集:Spambase数据集[11]和Ransomware数据集[12],分别进行上述两个场景下的算法适用性研究分析。Spambase数据集是一个包含4601封电子邮件的集合,其中包括1813封垃圾邮件,每封电子邮件都被编码为一个由54个二进制特征组成的特征向量,每个特征都表示电子邮件中是否存在某个特定单词;Ransomware数据集包含530个勒索软件样本和549个benign应用程序,具有400个二进制特征,可在软件执行器间进行不同的操作任务、API调用以及文件系统和注册表项中的修改。
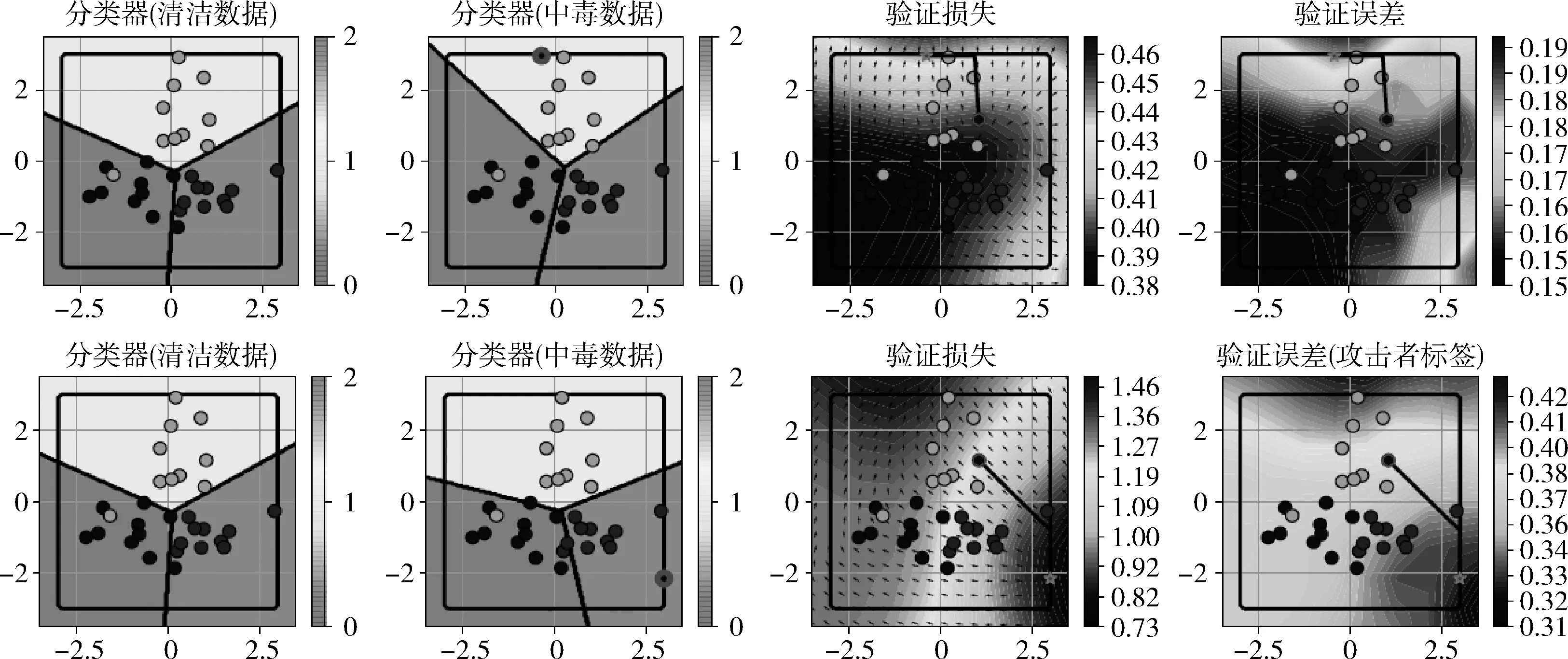
图1 针对多类逻辑分类器的3类合成数据集的通用性和特定性病毒攻击
此外,实验同样考虑了不同深度学习算法下采用所提反向梯度优化算法的性能。选用3种常见算法进行分析:①多层感知器(multi-layer perceptron,MLP)[13],其中隐含层由10个使用双曲正切激活函数的神经元组成,而输出层则使用Softmax函数;②Logistic回归(Logistic regression,LR)[14];③Adaline神经网络[15]。而式(4)中损失函数的选择,对于MLP和LR算法,采用交叉熵作为损失函数,对于Adaline神经网络,采用均方误差作为损失函数。

图2示出了PK攻击方式下,测试样本的误差率随攻击点在训练集中的分数的变化情况。可以看到,病毒攻击会严重影响所有分类算法的性能。无论是垃圾邮件过滤算例还是恶意软件检测算例,各学习算法对病毒数据的影响十分敏感,即便攻击者只控制了15个训练数据样本,也会导致3类学习算法发生超过15%的分类误差。但从图2中也可发现,对于垃圾邮件过滤算例,Adaline算法抵抗数据病毒攻击能力强于MLP和LR算法,而对于恶意软件过滤算例,MLP算法虽然在病毒样本较少时误差率较高,但随着病毒样本的增大,LR算法和Adaline算法的误差率会高于MLP算法,故MLP算法对数据病毒攻击的抵抗能力总体强于LR算法和Adaline算法。

图2 PK病毒攻击的结果
类似地,分析LK-SL攻击场景下,不同学习算法对数据病毒攻击的鲁棒性能。图3示出了Spambase数据集和Ransomware数据集下随病毒数据对3类典型深度学习算法的影响。可见,随着病毒数据的增多,测试样本的分类误差随之增大。
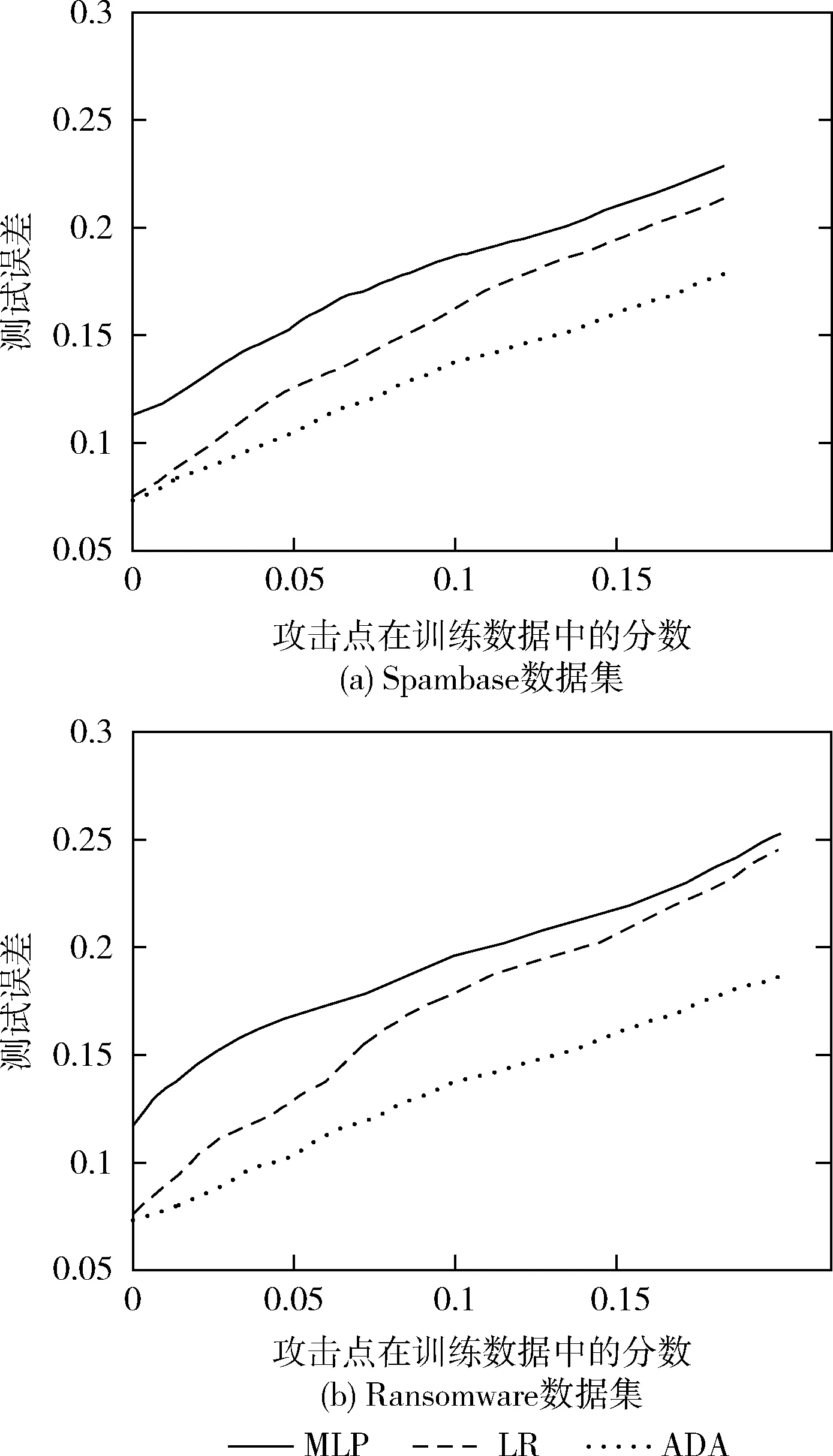
图3 LK-SL病毒攻击的结果
2.3 手写数字识别
进一步考虑手写数字识别场景下,生成的病毒数据样本对识别结果的影响。其中,分类器需要识别0到9共计10个数字,采用MNIST数据集[16]作为样本,每个类别中的数字图像由28×28=784个像素,范围从0到255的灰度图组成。每幅图像的像素值进行归一化处理,均除以255作为其特征。分类函数采用Softmax激活函数,并采用对数函数作为损失函数来评估通用性数据病毒攻击和特定性数据病毒攻击对多类分类器的影响。设置本实验的目的在于,验证病毒数据对深度学习算法的适用性,进而验证所提样本生成算法适用范围广泛性。为此,选用两个常用的针对图像检测的深度学习检测算法:①卷积神经网络(convolutional neural network,CNN)算法;②Logistic回归(Logistic regression,LR)算法。
为便于分析,实验中仅考虑识别数字1、5和6。采用1000个样本进行训练,8000个样本进行测试,采用本文所提反向梯度优化算法生成病毒样本时(即计算反向梯度▽xcA),迭代次数T=60。图4和图5分别示出了不同识别算法对病毒样本的识别结果。从图中可见,无论是CNN算法还是LR算法,均对病毒数据敏感,即含病毒数据的样本对手写数字识别的最终结果具有较为明显的影响。

图4 针对CNN的病毒样本

图5 针对LR的病毒样本
此外,纵向对比图4和图5可知,相同病毒数据攻击下,LR分类算法对图像的识别准确度高于CNN算法。换言之,LR算法对病毒样本的抵抗性要强于CNN算法。因此,所提病毒数据样本生成算法能够有效检测图像辨识算法的有效性,即适应性较强。
3 结束语
在线服务通过学习算法虽然能够通过用户数据分析提取有价值的信息,但用户数据易受到病毒攻击风险,从而对最终分析结果的准确性造成不利影响。通用性强的病毒数据样本对评价不同算法的鲁棒性至关重要。本文提出了一种基于反向梯度优化的深度学习算法病毒样本生成算法,通过自动反向微分机制以降低算法空间复杂度和时间复杂度。垃圾邮件过滤、恶意软件检测和手写数字识别等应用算例结果显示,所提病毒数据样本能够有效地开展对不同深度学习算法检测性能的评估。
未来将进一步深入研究考虑病毒数据攻击时各类深度学习算法准确度提升问题,即通过设计考虑病毒数据攻击时的深度学习算法训练机制,进一步提升算法鲁棒性,从而提高深度学习算法的准确率。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
应用数学(2020年2期)2020-06-24 06:02:50
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学学习与研究(2017年3期)2017-03-09 18:12:42
