
基于机器学习算法的LTE高投诉小区预判方法
2020-06-10 01:00曹丽娟程新洲徐乐西贾玉玮中国联通网络技术研究院北京100048
邮电设计技术 2020年5期
曹丽娟,程新洲,徐乐西,张 涛,贾玉玮,成 晨(中国联通网络技术研究院,北京 100048)
0 引言
移动通信网络技术的不断发展催生了日益复杂的移动网络环境,对运营商的网络优化提出了新的挑战。
用户投诉数据是用户意见的直接反馈,运营商通过多渠道获得了大量用户投诉数据,其中蕴含了大量有价值的数据和信息[1]。通过投诉处理可以及时有效地了解网络与业务中的不足,第一时间跟进处理,从客户投诉/用户感知入手,提升网络整体支撑保障能力与客户感知,提升网络优化效率[2]。然而,当前运营商处理用户投诉主要停留在投诉事后的处理过程,缺乏投诉的预判和防范,投诉处理过程相对复杂,障碍申告和网络优化的实时性不强。针对传统的运营商投诉处理过程中的不足和局限性,本文提出了一种基于机器学习的系统化和自动化的4G 网络投诉预判分析系统。
论文组织如下:首先介绍了运营商投诉处理的传统流程,归纳了这种方法可能存在的缺陷;随后论述了本方案的核心流程,包括数据采集及预处理、数据入库及中间表建立、决策树构建剪枝以及可视化的流程;最后从具体实施的角度,介绍了此方案的部署和应用,并对本方案进行了陈述及总结。
1 传统的运营商投诉处理流程
投诉处理是局部网络优化的重要手段,是改善局部网络覆盖质量的重要参考,因此投诉处理在网络优化工作中有重要的指导意义。运营商的典型投诉处理流程可以简单描述为:
a)投诉信息收集:一线客服平台收集用户的咨询及投诉。用户将投诉的位置、具体现象和表征进行描述,一线客服人员对这些现象和表征进行提取汇总,获取具体、详尽、完备的投诉信息。
b)电子运维系统派发工单:客服人员将投诉详单录入电子运维系统,并对用户投诉的问题进行初步分类(如网络制式分类:2G/3G/4G;投诉类型分类:服务相关投诉/通信质量相关投诉)。筛选出通信质量相关投诉,并通过电子运维系统对已发生的用户投诉进行工单派发。
c)投诉处理:相关网格的运维人员将用户投诉映射到网络问题,结合设备告警等进行投诉原因定位。结合投诉地点的实际情况,对可能存在的问题进行实地排查和测试,进而对相应的问题(网络覆盖、网络资源、网络性能、网络结构、网络稳定性等)采取相应措施进行解决。
通过以上投诉处理流程,用户投诉可以得到被动的事后解决。但这样的投诉处理模式停留在投诉的事后处理上,缺乏投诉预判和事前防范,问题的解决有不可控的时延,无法保障用户体验;与此同时也产生了较高的投诉处理成本。
针对以上问题,本文利用大数据及机器学习算法,挖掘投诉相关的网络性能指标,建立网络投诉预测模型及系统,对潜在的客户投诉进行预判。旨在协助运营商改善服务质量,系统化和自动化地提高投诉预判及防范能力,有效提升用户感知及自身竞争力。
2 基于决策树的高投诉小区预判方法
机器学习在网络优化和运维工作中得到了广泛的应用[3-5]。分类决策树属于监督学习,可以根据特征值递归得到,将输入空间(即特征空间)划分为有限个类别。它的优点在于:一、计算复杂度低,且模型容易可视化;二、算法完全不受数据缩放的影响,由于每个特征单独处理,且数据划分并不依赖缩放,因此决策树无需特征预处理。与此同时,当尺度不同的特征同时存在时,不影响决策树的效果。缺点在于可能会出现过拟合,泛化性较差。针对这个缺点可以通过剪枝或者组合树来对决策树进行优化。
本方案将LTE KPI 作为特征集,将高投诉小区作为分类标签,构建CART(Classification And Regression Tree)分类决策树。具体步骤如图1所示。

图1 基于决策树的高投诉小区预判流程
2.1 KPI特征选择
LTE KPI 数据作为衡量4G 网络质量、性能和业务质量的标杆,是网络监控、分析、评估与优化工作的重要指标[6]。KPI 能够一定程度上量化网络质量及用户感知,反应端到端的网络质量,在本质上与用户投诉中的问题有很强的相关度。合理地选择KPI作为决策树模型的特征集合,有助于更精准地构建基于网络性能的投诉预测模型。LTE 性能指标主要涉及接入性、保持性、移动性、完整性、资源负荷等五大类关键指标。经过对KPI 指标进行特征筛选,本方案中选取9个KPI指标作为决策树的特征指标,如表1所示。
2.2 数据采集及预处理
2.2.1 特征数据集
采集特定地(市)的LTE KPI 数据并入库,并以省份、地(市)、小区、天、小时为维度对KPI 完成数据计算,然后筛选上述9 项KPI 作为特征指标。为了提高预测模型的准确性,输入数据样本的准确性和有效性显得非常重要,需对数据进行清洗和预处理。
2.2.2 标签数据
从电子运维系统中采集与KPI对应日期的投诉数据,筛选出网络制式为4G,投诉类型为通信质量大类的投诉记录,并根据相同的维度(省份、地(市)、小区、天、小时)统计投诉数。对于评估所在的地(市)、日期范围内,第d天第h小时c小区的用户数Ud,h,c,因通信质量原因的投诉数记为Cd,h,c。平均用户投诉数可表示为:
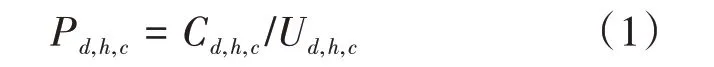
将“是否为高投诉小区”作为标签数据,在此根据Pd,h,c占比判断是否为高投诉小区,其中T0为判决门限,其中Flagd,h,c=1记为高投诉小区。
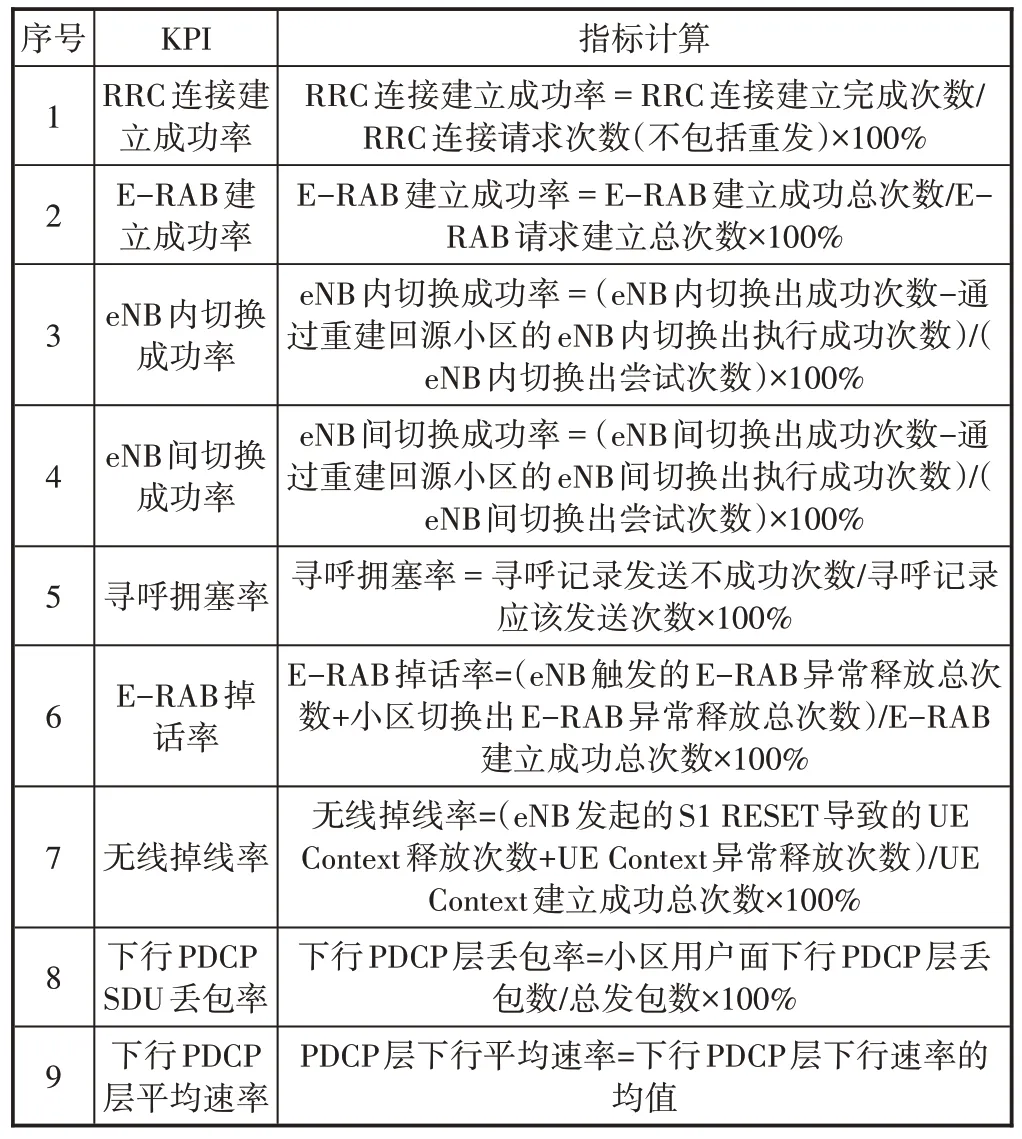
表1 KPI特征集
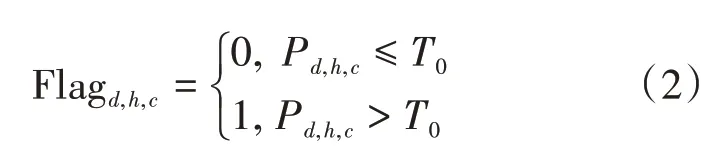
经过上述步骤,特征数据集和标签数据集整理如表2所示。
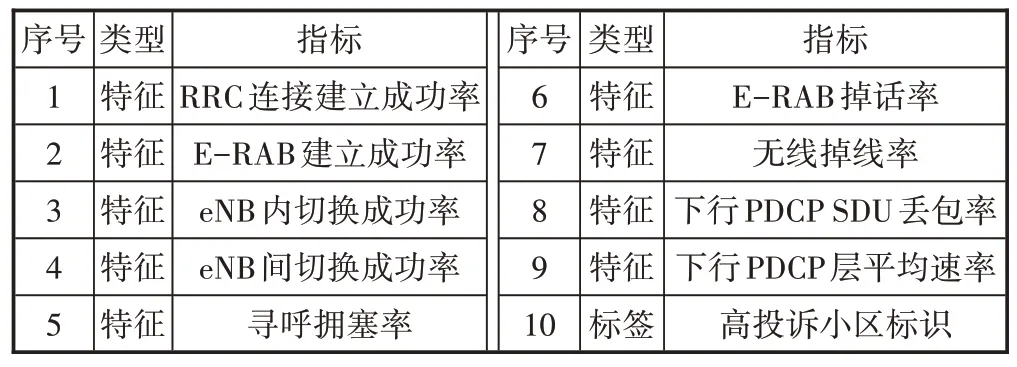
表2 数据集
2.3 决策树建立与剪枝
在表2 中选取10 000 个数据样本,拆分为训练集与测试集,使用整个数据集的80%作为训练集,20%作为测试集。使用训练集对决策树进行训练,而后将测试集作为输入得到预测的标签集合。随后针对本文的二分类问题,通过混淆矩阵的方式分别统计分类模型归错类、归对类的观测值个数,评估模型最终的效果。最后使用graphviz将决策树可视化(见图2)。
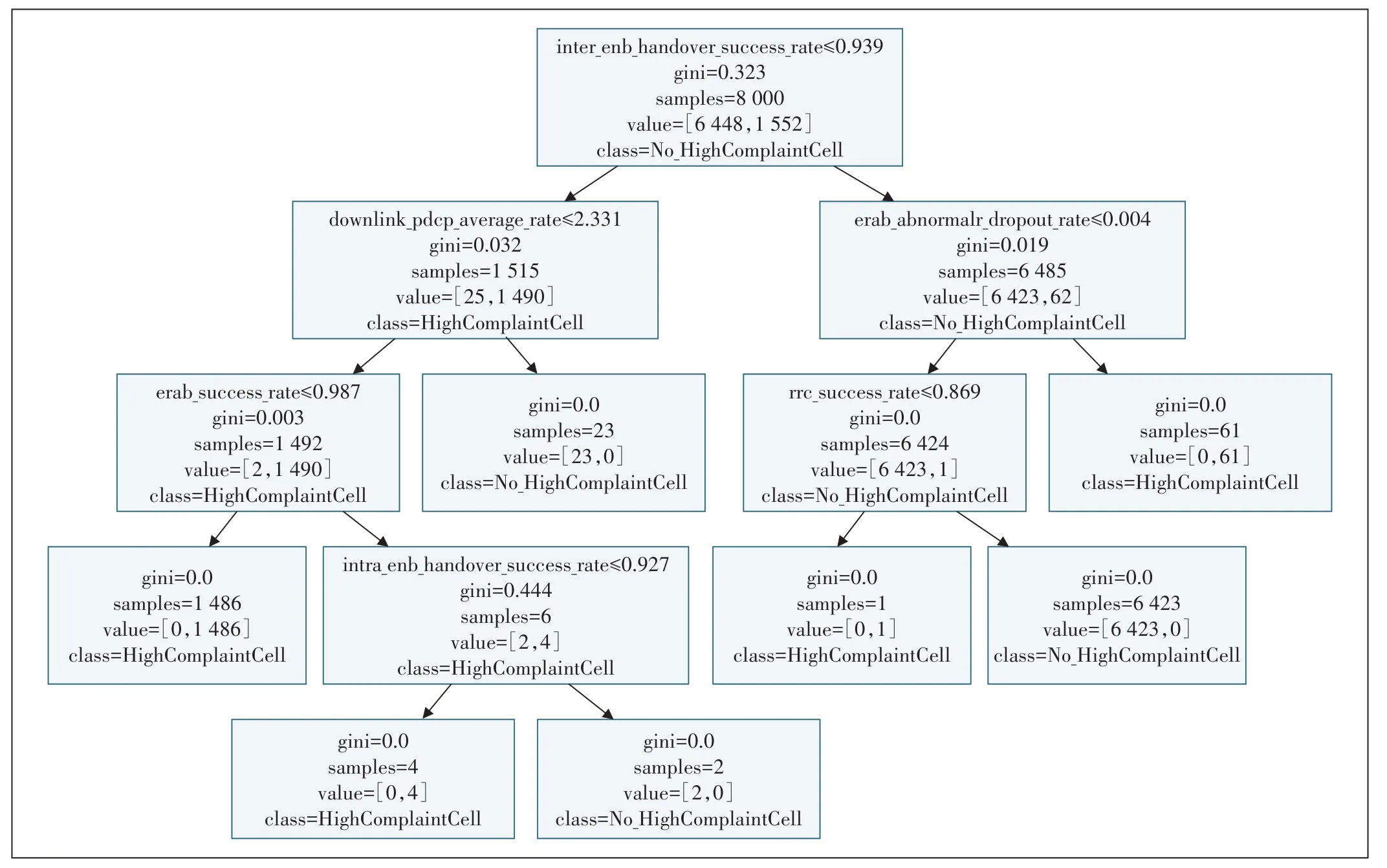
图2 决策树可视化
为了防止决策树过拟合,这里采用预剪枝的方法。预剪枝的限制条件包括限制树的最大深度、限制叶结点的最大数目,或者规定一个结点中数据点的最小数目来防止继续划分等,这些在DecisionTreeClassifier的参数中进行设置(见表3)。
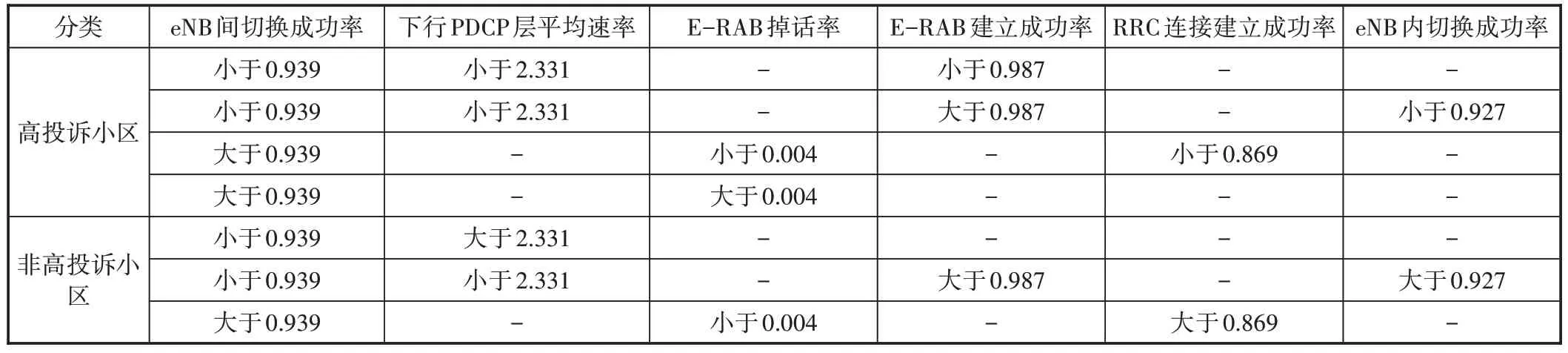
表3 模型数据
3 方案部署及应用
从具体实施的角度,本方案部署在网络中还需要在运营商电子运维系统基础上部署2 个关键的子系统:数据采集及处理子系统和策略判决及执行子系统。具体的方案如下。
数据采集及处理子系统,对于网络KPI 进行实时采集和处理,按照指定维度对各特征KPI 进行数据输出。数据进入策略判决及执行子系统后,该子系统会依据现存的静态策略,对各小区是否为疑似高投诉小区进行预判,如果该小区满足高投诉小区的特征,则将其纳入高投诉小区名单。最终策略判决及执行子系统将生成的高投诉小区名单输出给电子运维平台或者网优平台,由相关网优或者运维人员对目标小区进行问题定位及解决(见图3)。

图3 方案部署及应用
与此同时,通过结合当前模型的预测和实际网络问题,对模型进行反馈调节,通过迭代提高预报模型的效率和精度。
4 总结
本文构建了基于网络性能的投诉预测模型,对潜在的客户投诉进行预测。建立一套打通KPI与前端投诉数据的分析体系,统筹分析网络的用户感知数据,使前后端通过数据的分析能够联动起来,通过数据的联合分析结果,对市场、客服、建设、维护多个方面起到支撑作用。改善投诉处理业务流程,降低企业投诉处理成本,提高运营商的服务质量和竞争力。
猜你喜欢
进出口经理人(2021年8期)2021-02-12
出版人(2020年5期)2020-11-17
中国交通信息化(2019年5期)2019-08-30
今日农业(2019年14期)2019-01-04
电子制作(2018年16期)2018-09-26
能源(2018年8期)2018-09-21
能源(2017年11期)2017-12-13
山东工业技术(2016年15期)2016-12-01
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
