
互联网不良信息监控在电信运营商的研究与应用
2020-06-09 07:52:20时镇军
江苏通信 2020年2期
时镇军
中国移动通信集团江苏有限公司
0 引言
近年来,随着互联网技术的迅猛发展和用户规模的快速扩大,在巨大的市场规模和非法利益的驱使下,网络不良信息泛滥。据统计,互联网上12%的网站涉及不良信息,25%的搜索关键词涉及不良信息,35%的网络下载涉及不良信息,每秒钟2.7 万用户正在观看不良信息。这种现象严重败坏了社会风气,社会各界对此深恶痛绝。
为加强互联网不良信息监控,构建绿色文明的互联网络,我国出台了一系列法律法规,2006 年颁布了《信息网络传播权保护条例》,2012 年出台了《关于加强网络信息保护的决定》《互联网信息服务管理办法》,2016 年颁布了《中华人民共和国网络安全法》。除了需要法律支撑外,在实际网络不良信息监控中还需要依靠技术手段。世界各国在互联网管理过程中,均是采用“政府立法+技术过滤”的管制模式。如韩国要求公共上网场所安装过滤软件,保证未成年人获取健康信息,还限制青少年的深夜网络游戏行为;芬兰教育部在全国学校和图书馆的电脑上安装拦截软件,过滤和屏蔽不良网站;芬兰电信运营商也为家长提供“家长网上监控”服务,通过过滤器过滤掉网上不健康的内容;澳大利亚的“互联网安全计划”要求网站加强个人认证;英国设立了专门网站,向家长提供最新的网络安全信息。
为严厉打击利用互联网传播不良信息的行为,全国“扫黄打非”工作小组办公室、国家互联网信息办公室、工业和信息化部、公安部每年开展一次“扫黄打非”净网专项行动。其公告第三项“各互联网站、基础电信运营企业、网络接入服务企业立即开展自查自纠,主动清理网上淫秽色情信息或链接”。
为落实国家相关部委及集团总部关于互联网资源信息安全的治理工作考核要求,本文将研究不良信息监控平台及在运营商中的应用,实现对不良信息的智能监测与管理,解决互联网用户绿色上网的问题。
1 系统架构
平台通过主动爬虫获取用户网络中的文字、图像、视频数据,利用计算机视觉相关技术(包括文字匹配算法、模式识别、深度学习、图像指纹技术等)对网络中的文本、图像、视频进行自动检测与识别。识别的目标包括:黄色文字、图像与视频、暴力恐怖图像、反动图像与视频等。平台对发现不良信息内容进行预警,同时为用户提供扫描检测报告和相关的统计分析和管理功能。

图1 系统架构图
如图1 所示,系统包括数据采集和预处理、内容识别、应用四个主要部分。
(1)采集层
通过镜像、网络爬虫或者数据共享接口获取待处理的文字、图像、视频数据。网络爬虫采用分布式并行处理方式,负责对所有的网站按照一定的周期进行深度遍历与抓取,包括采集任务调度、网站内容遍历、视频下载、集群运行状态监控等模块。
(2)预处理层
通过协议还原、内容解析、内容去重等方式对采集的数据进行预处理。
(3)处理层
主要对采集并预处理后的数据进行识别分析,包括文字识别、图像视频模式识别、图像视频指纹比对识别三个主要功能。
(4)应用层
主要实现垃圾彩信监测分析功能、不良信息审核功能、黑白名单管理、违规内容告警、系统自学习、IP/域名自动归并、域名模糊封堵、网址位置精确定位、网站内容分析识别策略管理。
2 主要技术
2.1 爬虫采集
通过对数据进行基础协议解析及处理,并按照支持的协议范围,对数据包中的文本、图片数据进行还原,实现对网络出口高速流量的数据内容爬取,同时解析出关联的URL 域名、访问URL 的源IP 地址、目的IP 地址、源访问端口、目的端口、访问时间等信息以供后续处理使用。主要包括域名爬虫、URL 爬虫、IP 段爬虫。
域名爬虫:对添加到系统的网站地址进行主动爬取,并通过自动链接提取模块完成子任务的提取,从而实现深度遍历式爬取,支持文本、图片、视频、各类附件。
URL 爬虫:需要与访问日志端建立连接获取URL 接口,通过URL 爬虫对接收的URL 进行扫描获取内容,以供后续处理使用。
IP 段爬虫:使用IP+端口号方式爬取网站内容。
2.2 内容去重
根据互联网长尾效应,80%的访问请求20%的内容,因此为了节约系统资源,需要对采集的数据预处理,去除重复信息。主要采用方法如下:
URL 级别去重:MD5 比对法、Hash 表配合URL 压缩法、Bloom Filter 去重。
文件唯一编码级别的去重:一般通过文件MD5 进行相同文件的去重。
文件特征的去重:使用特征提取和比对技术进行文件相似性比对去重。
图像特征由全局描述子和局部描述子两部分组成。全局描述子用于建立数据库索引,系统利用全局描述子快速地从数据库中筛选出可能相似的图像,然后利用局部描述子进一步计算检索图像与筛选出来的候选图像的相似度,然后根据相似度从高到低将结果返回。
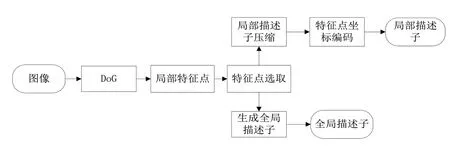
图2 图像特征的提取过程图
2.3 文本识别
关键字过滤:对采集获取的文本数据编码进行UTF8转码;对转码后的文本数据进行关键字/关键字组合的搜索;将搜索到的关键字/关键字组合进行标记并计算权重。
语义分析:对采集获取的文本数据编码进行UTF8 转码;对进行转码后的文本数据进行分词;对分词结果进行统计,生成特征向量;将特征向量输入到文本分类模型进行识别,得到文本是否为不良文本的识别结果,并将文本传送至后台。
2.4 图像识别
第一层(指纹库):利用视频图像指纹库技术,建立分类指纹库,包括黄色、反动、暴力、敏感事件等。对于系统采集的数据,首先进行指纹快速比对,发现与指纹库中的数据相似的数据,则直接进行过滤处理。
第二层(特定模式识别库):对网络中不同来源的数据进行分级处理,对于一些特殊的图片网站(如电商、人物写真),利用模式识别技术,采集相关的样本进行针对性的学习与训练,在完成指纹识别后,先使用针对性的图像库训练模型进行识别。
第三层(机器学习):利用基于肤色特征的SVM 分类器进行快速过滤。互联网中的图像大部分是正常图像。肤色特征过滤器能快速过滤那些明显非黄色的图像。在不降低识别率的情况下,保证系统能快速识别正常图像,提升系统的处理性能。
第四层(深度学习):利用世界领先的深度学习算法,对画面中的内容进行识别,当前系统支持数万种特定正常场景的图像识别。
第五层(人脸检测):对于泳装照片的识别,利用人脸识别算法识别出人脸的区域,同时对人脸周边区域的相关分析,降低系统的误判。
2.5 视频识别
通过指纹特征提取及指纹比对检索,实现对图像视频的监测。图像视频匹配的核心问题是将同一目标在不同时间、不同分辨率、不同光照、不同位姿情况下所成的图像相对应。具体为:
(1)构建尺度空间:这是一个初始化操作,通过生成尺度空间来创建原始图像的多层表示,以保证尺度不变性。
(2)LoG 近似:使用Laplacian of Gaussian 能够很好地找到图像中的兴趣点。
(3)找到关键点:利用近似我们可以找到特征点,它们是Difference of Gaussian 图像的极大、极小值。
(4)除去不好的特征点:边界和低亮度区域是不好的特征点,除去它们以使算法有效和鲁棒,在这里使用近似Harris Corner 检测器。
(5)给特征点赋值一个方向:为每个特征点计算一个方向,依照这个方向做进一步的计算,这个操作有效地取消了方向的影响,使得算法具有旋转不变性。
(6)生成特征:利用位置上的尺度和旋转不变性,能够生成一个表示,它能帮助唯一地识别特征。通过这个表示,我们可以很容易地识别寻找的特征。
(7)指纹比对检索:相似的图像或视频在经过变化后的检索匹配。
图3 图像识别特征生成过程
3 平台功能
3.1 互采集功能
平台需支持移动互联网GRE、HTTP、WAP1.x、WAP2.0、MMS、SMTP、POP3、FTP、Telnet 等多种协议的业务信息进行采集和识别,并且可以根据内容类型(文字、图片、音视频)进行分类识别。
3.2 内容预处理
将互联网流量中大部分的重复访问进行去重处理。经过去重分析处理后的记录在数据库中减少90%,经过黄色图片智能识别系统审核后的嫌疑图片占总数的1%左右,低于识别门限的小图片被自然过滤。
3.3 内容识别功能
实现对文本、图片、视频、不良网址的分析,通过文本内容比对、图片不良特征匹配、视频指纹特征提取及比对检索,识别不良信息。
3.4 应用功能
(1)垃圾彩信监测分析功能
在WAP不良信息监控系统上实现垃圾彩信监测分析功能。
(2)不良信息审核功能
系统应支持审核配置管理功能,通过关键字匹配、色情图片识别和样例图片识别技术,提取出网站中疑似的内容违规信息,由人工对疑似违规数据进行确认审核。
(3)黑白名单管理
网站黑白名单库,减少系统资源消耗。
(4)违规内容告警
系统支持发现违规内容时自动提供网页方式的告警功能,提示审核人员及时处理。
(5)系统自学习
内容匹配识别引擎可实现分类内容的自动识别匹配,通过人工反馈机制实现匹配算法的学习。
(6)IP/域名自动归并
系统可以自动整理出雷同域名的IP 地址,并提出对IP 地址进行封堵。
(7)域名模糊封堵
系统可以自动归并出有害域名的最亲父节点,通过与现网已建设的移动互联网恶意程序监测封堵系统联动,对这个父节点实施模糊封堵。
(8)网址位置精确定位
通过DNS 逆向解析功能,系统可以精确定位每一个URL的真实IP 地址,并通过查询得到网站的物理位置。
(9)网站内容分析识别
内容识别策略包括关键字库策略、图像特征库策略、不良网址库策略。
4 应用方案
4.1 组网方案
基于现有上网日志留存系统或上网导航系统,获取上网话单中的URL 数据,进行互联网页面爬取,并基于现有系统已汇聚后的彩信流量,从彩信中心近端交换机镜像流量到新增的彩信专用采集机上,在云平台资源部署不良监测系统进行监控。
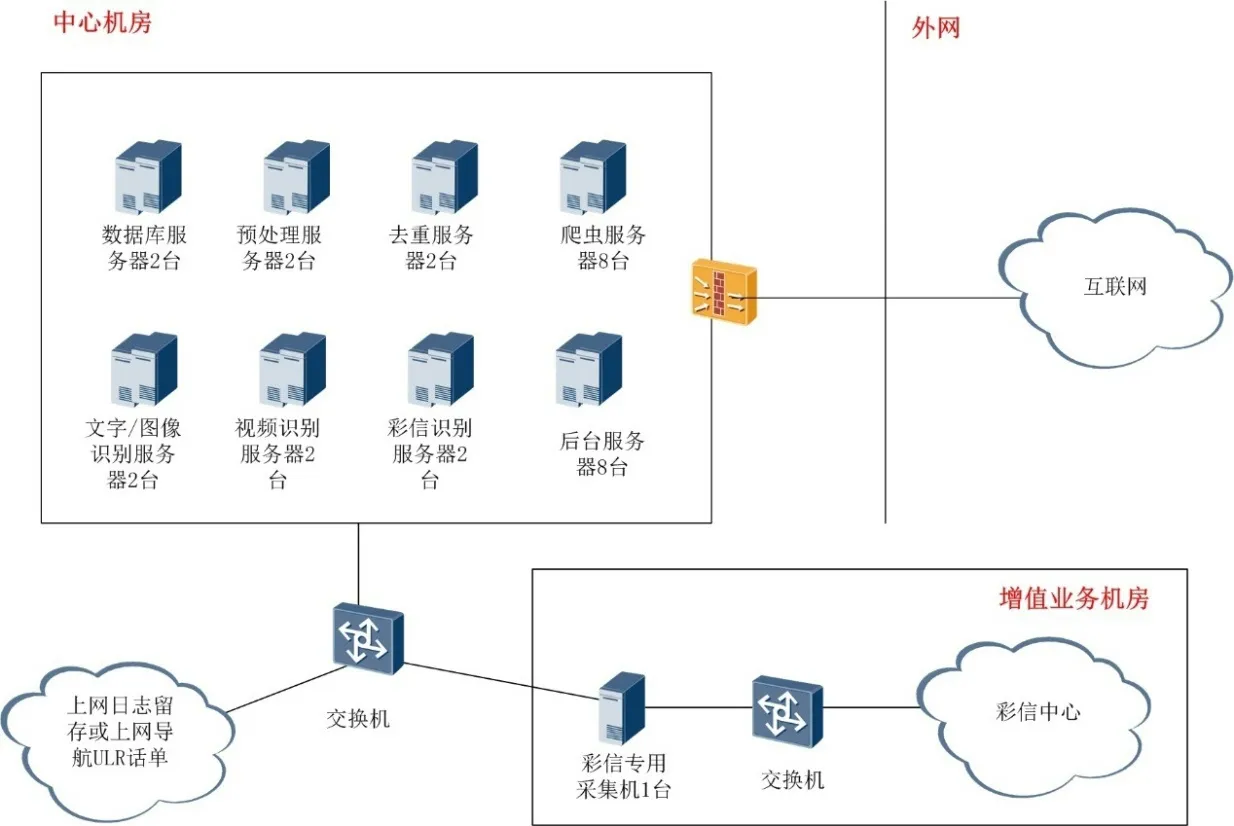
图4 不良信息监控平台系统组网图
4.2 接口方案
(1)DPI 接口
不良信息监控系统从DPI 设备中获取指定协议的会话信息、所有被还原的文本、图片,以及文本与图片对应的会话关联信息。
前端采集机与后台通过SFTP 进行通信,其中前端采集机为SFTP 客户端,大区后台为SFTP 服务器端。若传输失败,采集机定时(可配置周期)重传。包括数据传输接口、XDR上传接口、策略同步接口、时钟同步接口。
(2)时钟同步接口
支持通过NTP 时钟同步服务器从指定平台同步时钟。
(3)网管接口
在网络管理需求上,系统前端设备网管接口支持SNMP、FTP 等管理协议,即数据网设备提供SNMP、FTP、Telnet、数据库接口中的三种网络管理接口。
5 结束语
本文针对互联网不良信息泛滥的问题,研究了不良信息监控平台及其在运营商的应用方案。监测系统的总体目标是对用户管辖范围内的目标网站进行爬虫搜索监测,针对互联网网页,系统能自动爬行页面所有下级链接页面,标记其中链接信息,抓取页面中的相关内容,并对这些内容进行监测,包括信息采集和分类管理、信息内容(包括文本、图片等)监测和匹配识别,并建立管辖范围内的互联网监测信息基础数据库,对违规信息进行统计分析,为互联网信息的监测工作提供高效的技术手段,并为互联网信息数据进行特定应用挖掘提供基础数据。
本文结合工程实际情况提出不良信息监控平台建设的功能架构和接口方案,为运营商构建类似系统提供一些借鉴和参考。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
小哥白尼(趣味科学)(2021年11期)2021-02-28 08:35:00
小天使·一年级语数英综合(2020年10期)2020-12-16 02:57:11
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
自动化学报(2016年8期)2016-04-16 03:39:00
小学教学参考(2015年20期)2016-01-15 08:44:38
