
Hadoop+JavaWeb大数据分析可视化系统
2020-06-08 09:48焦向雨黄康辉卢峥
中小企业管理与科技·下旬刊 2020年2期
焦向雨 黄康辉 卢峥
【摘 要】论文提出的大数据分析可视化系统主要处理实时性要求不高,但对决策很重要的离线数据,如同种岗位不同地区工资对比情况,各热门岗位数量统计,对顾客购买记录进行统计等。利用大数据平台进行海量数据的存储、分析,提高客户对事件的决策准确率,将分析得出的数据结果以可视化的形式在浏览器上呈现,以便用户直观看到数据的变化结果。
【Abstract】The big data analysis visualization system proposed in this paper mainly deals with the off-line data which is not required to be real-time, but is very important for decision-making, such as the contrast situation of the same post in different regions, the statistics of the number of various popular posts, the statistics of customer purchase records, etc. Using the big data platform to store and analyze the massive data can improve the accuracy of user's decision-making for the event, and present the data results in the form of visualization in the browser, so that users can see the change results of the data directly.
【关键词】大数据;分布式;Hadoop;可视化
【Keywords】big data; distributed; Hadoop; visualization
【中图分类号】TP393 【文献标志码】A 【文章编号】1673-1069(2020)02-0151-02
1 概要设计
1.1 框架设计
1.2 设计思路
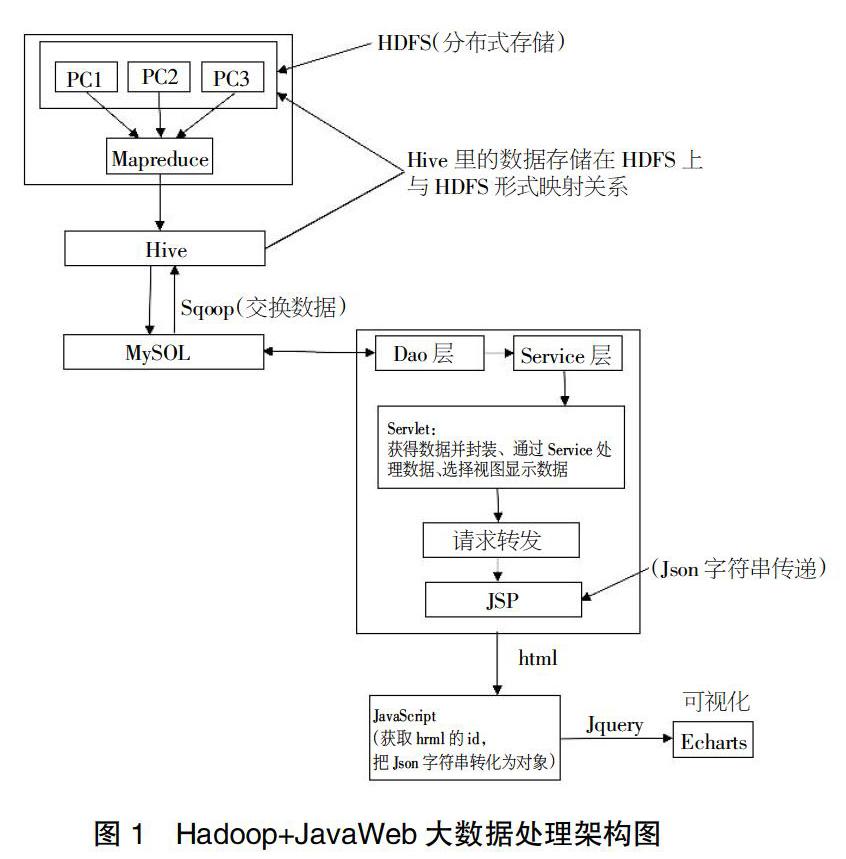
此架构即Hadoop+JavaWeb(MVC模式)的结合用于模拟大量数据处理方式。通过利用Hadoop的特性进行分布式存储,目的在于突破IO存储瓶颈问题。项目的模拟数据主要为结构化数据,假设结构化数据超过单机容量的范围,那么便采用Hadoop生态圈进行架构设计[1]。使用Hadoop集群的HDFS进行分布式存储(HDFS便于管理和维护以及具有较高容错性),采用Mapreduce(离线计算)进行数据的清洗与筛选。当需要使用这些数据进行决策,可用Hive进行数据的清洗、提炼和分析之后存于HDFS中。由于Hive提供SQL功能,并且Hive-SQL可转化为Mapreduce,因此,Hive可以对大量数据进行分析与处理[2]。
Hive是基于Hadoop的一个数据仓库,还可以将结构化数据映射成一张表,在本项目中,Hive与MySQL映射成一张表,通过Sqoop使Hive与MySQL进行数据交换。本着OLTP的思想,可以使HDFS为主(分布式存储文件),MySQL为辅,通过Hive传递的实时性要求不高,但对决策很重要的数据(如同种岗位不同地区工资对比情况,各热门岗位数量统计,对客户购买记录进行统计等)传递至MySQL。由于关系型数据库维护方便、使用方便,支持SQL,可用于复杂查询,便于满足使用者的不同需求[3]。结合MVC思想,程序通过将Model和View代码分离,实现了前后端的分离,其使Java后台开发人员集中精力于业务逻辑,前端程序员集中精力于表现形式,使项目开发的分工更加明确,程序的测试更加简便,提高了开发的效率[4]。
1.3 模块设计
1.3.1 Hadoop模块组成部分
HDFS、Hive、Sqoop、Mapreduce、MySQL。
1.3.2 JavaWeb模块组成部分
Dao、Domain、Service、Utils。
1.3.3 前端模塊组成部分
HTML、JavaScript、Echarts、JSP(前后台数据交互)、JSON(数据传输)。
2 详细设计
2.1 上述架构可拆分成两部分设计
2.1.1 Hadoop平台架构组件的搭建
①分布式文件系统:HDFS;②分布式计算引擎:Mapreduce;③数据分析引擎:Hive;④数据交换工具:Sqoop;⑤关系型数据库:MySQL;⑥需注意的地方:当主节点发生故障时,整个系统便会瘫痪,为了解决此问题,可选用ZooKeeper搭建HA。
2.1.2 JavaWeb平台架构组件的搭建
本次JavaWeb的开发采用MVC设计模式(Model View Controller)。Model表示应用程序的数据核心,View表示数据显示层,Controller表示控制层。MVC模式同时提供了对HTML、CSS和JavaScript的控制。其中,Model是应用程序中用于处理应用程序数据逻辑的部分。通常模型对象负责在数据库中存取数据。View是应用程序中处理数据显示的部分。通常视图是依据模型数据创建的。Controller是应用程序中处理用户交互的部分,通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。MVC分层的同时也简化了分组开发,不同的开发人员可同时开发视图、控制器逻辑和业务逻辑[5]。
2.2 架构的整合说明
架构Hadoop+JavaWeb(MVC模式)的结合可以模拟大量数据处理的方式,通过三台虚拟机搭建Hadoop分布式集群,基于Hadoop的特性进行分布式存储,有效解决了IO存储的问题。由于Hadoop的HDFS存储数据种类繁多(具有较高容错性),可采用Mapreduce(支持离线大量数据的处理)进行数据的清洗与筛选。本项目的样本数据主要是结构化数据。因此,选用Hive作为数据分析引擎。Hive是基于Hadoop的一个数据仓库工具,本身没有专门的数据存储格式,也没有为数据建立索引,所以数据存储在HDFS上。Hive支持SQL查询,能将SQL查询转换为Mapreduce的job在Hadoop集群上执行,并且其可以将结构化数据映射成一张表。
但Hive不支持复杂语句查询,为了满足各种复杂的业务离线查询需求,在本项目中,Hive与MySQL映射成一张表,通过Sqoop使Hive与MySQL进行数据交互,形成以HDFS存储为主,以MySQL查询、Hive查询为辅的设计结构。
结合面向对象的思想,由于结构化数据可看成一个个对象,便可引入JavaWeb作为前后端交互的平台,通过request发起查询信息后,JavaScript调用Service层,之后Dao层的数据传输到Service层,以JSO的格式封装Service的集合数据吗,并传递到JSP中,最后JavaScript获取到JSP中HTML的id,把JSON字符串转化为对象,以Jquery作为中介呈递数据给Echarts进行可视化[6]。
3 安装及使用
大数据集群环境配置:①电脑配置至少12G运行内存;②关于虚拟机问题:准备三台Linux虚拟机,每台至少分配2G运行內存,主节点至少分配50G磁盘空间,从节点至少分配30G磁盘空间;③必须考虑各个组件的软件兼容性;④Tomcat为v7.0版本;⑤在搭建大数据集群时,先配置Hadoop,再配置Hive,最后配置Sqoop。
4 项目总结
在设计架构时,还需要考虑架构的延伸和扩展,为此,在JavaWeb端采用MVC模式。采用这个模式后期方便重写代码,可采用SSM(Spring+SpringMVC+MyBatis)对整个程序进行解耦,简化开发过程,提高开发效率。当然在Hadoop集群也留有扩展的余地,除了使用离线计算的框架外,还可以搭建Spark,加快数据处理的速度。
关于项目的模块拆分有三大部分,即大数据端、Java后端、前端。在开发过程中,大数据模块最为复杂,需要协调好各个组件的兼容性,并且需要了解一定的分布式概念,还需对数据结构、操作系统、计算机网络、数据库有一定的了解。而Java后端和前端比较简单,Java只需要专注于业务逻辑,前端只需要会使用Echarts可视化框架即可。
在本次项目的制作中,目前还没有发挥出全部的功能,在制作时并没有考虑程序整体的解耦,如果把MySQL换成其他数据库,那么所有的接口将要被重新实现,造成了维护不便的问题。
在整个项目设计的过程中,没有添加用户接口,不能获取用户的真正需求,整个制作流程到实现也只是处于一个假设状态,因此,在制作时只模拟了一个统计岗位数量的业务逻辑。在此项目的基础上,后续会不断改进。
【参考文献】
【1】王卫锋,杨林.基于Hadoop的邮政寄递大数据分析系统设计与实现[J].中国科学院研究生院学报,2017,34(3):395-400.
【2】杨晓燕.大数据下智慧图书馆研究领域的可视化分析[J].河南图书馆学刊,2020,40(02):94-96.
【3】杨恒,田坤,常亮,等.基于大数据分析的可视化预测性运维系统实现[J].冶金自动化,2020,44(01):44-47+73.
【4】张文斐,陈酌灼,洪梓铭.移动终端应用数据分析用户体验改进技术[J].信息技术与信息化,2019(07):34-37.
【5】李晓颖,赵安娜,周晓静,等.基于大数据分析与挖掘平台的个性化商品推荐研究及应用[J].电子测试,2019(12):65-66+81.
【6】陈海拔,顾全,董羊城,等.基于大数据的电网调度控制智能告警系统[J].电子设计工程,2019,27(11):91-95.
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
海洋信息技术与应用(2020年1期)2020-06-11
传媒评论(2019年4期)2019-07-13
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
