
基于多特征子空间的行人重识别
2020-06-08 16:25:34徐大林
指挥控制与仿真 2020年3期
李 韬,李 捷,徐大林
(江苏自动化研究所,江苏 连云港 222061)
行人重识别(Person Re-identification,Re-ID)是一个重要的计算机视觉任务,其目的是跨摄像头检索同一身份的行人。由于在不同摄像机视角下行人的视觉表达有剧烈的变化,因此,行人重识别是一个极具挑战的任务。如何找到一个具有高辨识度的特征表达是这个任务的关键之一。
多任务学习(Multi-task Learning,MTL)是机器学习中的一种学习范式,其目的是利用多个相关任务的有用信息使得所有任务相互受益[1]。在多层特征空间模型中,任务是相关的,很自然就想到的一种方式是所有子任务共享低层特征空间[1]。这种共享的特征空间比单独任务的特征空间具有更强的表达能力。
在最近的行人重识别领域中,许多模型使用了多任务的思想来提高模型的性能。文献[2]通过引入批量特征图遮挡的任务来提高模型的泛化能力。文献[3]通过大量的实验表明了联合训练softmax损失函数和triplet损失函数能够显著提升模型性能。文献[4]所提出的模型使用了多个损失函数,并且可以被看作联合了姿态任务和分类任务。
然而,本文中我们考虑从全局特征空间中提取多个特征子空间,并把联合训练多个特征子空间看作一个多任务学习。具体而言,首先,在初始全局特征空间中提取多个特征子空间,然后,联合训练这些特征子空间来提高最终全局特征空间的表达能力。所提的模型之所以使用特征子空间,是因为特征子空间更容易学习细粒度特征,从而使得最终的全局特征空间拥有更多的细粒度特征[5]。这一现象的本质类似于随机擦除,随机擦除通过遮挡部分区域构造新的数据,其作为一个数据增强的方法能够有效提高模型的泛化能力。在我们的方法中,特征子空间可以被看作一个被遮挡的全局特征空间,从而迫使特征子空间学习更多细粒度特征而提高泛化能力。注意,本文中使用了两种方法来获得特征子空间:一种是对原始特征空间进行分割,另一种是对原始特征空间进行不同的池化。与随机擦除通过遮挡特征图所有通道的部分区域相比,我们的方法可以看作是遮挡某层特征图的部分通道。
我们在Market-1501数据集和DukeMTMC-reID数据集上进行了大量的实验。实验结果表明基于多任务学习的多特征子空间方法能够显著提升行人重识别的性能。
1)我们为行人重识别问题提出了一个新的简单的多任务方法,该方法是基于多特征子空间和多softmax损失函数的。
2)基于上述方法,我们提出了一个新的叫作多特征子空间(Multiple Feature Subspaces,MFS)模型,该模型显著提升了行人重识别性能。
3)在Market-1501和DukeMTMC-reID数据集上做出了大量的实验。
1 多任务学习
在行人重识别领域,近年来许多方法采用卷积神经网络来提取特征。随着越来越多的卷积网络模型的提出[6-7],许多工作致力于将这些新的模型融合到行人重识别中[8]。此外,许多工作也在研究深度度量学习。例如,triplet损失函数[9]是来自于度量学习的一个普遍而有效的损失函数,其通过拉大类间距离并缩小类内聚类来增强模型的表达能力。
多任务学习利用多个相关任务来提高所有任务的泛化能力。事实上,多层的前馈神经网络就是一个天然的多任务学习模型。其输入层和隐藏层可以看作是多个任务共享的部分,输出部分可以看作许多子任务的并列所得。此外,文献[10]提出了一个交互学习模型,该模型中一组学生模型在训练期间通过相互学习来提升自己。
事实上,多任务学习在行人重识别中也是广泛应用的。许多行人重识别方法可以被看作多任务模型。例如,对行人分割后使用多个损失函数来约束相应部分的方法就是其中一个,并已经被证实能够显著提升模型的性能,所以该方法在最近几年中得到了大量关注和改进。Zhao等人[11]探索了对人体多个部件建模并联合表达的方法。文献[12]提出了作者提出了一个联合局部特征选择和全局特征选择的方法。文献[13]提出了一个基于姿态的深度模型,该模型利用人体部件线索来提升模型性能,这就要求模型在学习特征表达的同时使用姿态点。Sun等人提出了一个基于人体部件的模型[14],其通过划分特征图和重新分配异常点的方法来实现自动划分人体部件。文献[15]提出了一个多粒度网络模型,该模型探索了行人重识别中的全局特征和局部特征的表征。Zhang等人[16]使用多个损失函数和一个金字塔模型来学习从粗粒度到细粒度的特征。Dai等人[17]在批量特征图上遮挡部分区域来减少模型的过拟合。文献[18]在基于softmax损失函数和triplet损失函数的基础模型上使用许多技巧(tricks),从而使得模型性能达到了较高的水平,作者提到triplet损失函数和softmax损失函数具有相互促进的优点,并加以改进。
综上可以看到,在行人重识别领域中,许多模型都使用了多任务学习的思想。然而,这些方法没有考虑全局特征空间在通道上的划分。在本文中,我们探索了如何使用多个特征子空间和softmax损失函数来增强全局特征空间的表达能力。通过对原始的全局特征空间在通道上进行划分,我们可以得到大量的特征子空间,并且,每个特征子空间都要由一个softmax损失函数来约束以保障其能学习到特征表达。
2 融合多任务学习的多特征子空间模型
本文提出了多特征子空间模型(MFS),模型结构如图1所示。
2.1 行人重识别定义
行人重识别通常被视为一个图像检索问题,其主要目的是从数据集中找到相同身份的人的图像。我们的主要目的是找到一个编码函数f(·)和一个度量函数D(·,·),其中,f(·)将输入的图像x映射为一个高维特征向量f(x),之后,度量函数D(·,·)度量特征向量f(x)和f(y)的相似性。
本文中,我们训练一个神经网络来学习一个好的编码函数f(·),并利用欧几里得距离充当度量函数D(·,·)。通常,我们首先把具有C个类的数据集X划分为训练集Xtrain和测试集Xtest,然后,我们设计一个神经网络,并通过在Xtrain上训练该网络得到编码函数f(x),然后,我们计算测试集Xtest上所有的编码特征,并根据比较,找出前K个最接近所给的询查图像q的图像集,最后,如果所找到的K个图像的身份和询查图像q的身份一致率越高,那么,我们认为所训练的神经网络越成功。
2.2 MFS模型的描述
根据多任务学习的理论,单个任务学习不能使得模型忽视噪声的影响,从而减弱了模型的泛化能力。然而,多任务学习中的多任务有不同的噪声模式,所以,同时学习两个任务的模型能够减弱噪声影响,并学习一个更泛化的特征表达。所以,我们的主要问题是如何构建多个有用的多任务。在本文中,我们考虑特征子空间更容易学习细粒度特征,所以,把单个特征子空间的训练看作一个子任务,将问题具体为如何在原始全局特征空间中提取多个特征子空间。
规范化描述上述思想,我们定义一个全局特征F,f(x)∈F。然后使用两种方法来提取特征子空间,一个方法是使用平均池化和最大池化得到两个池化特征子空间,F={Favg,Fmax},另一个是方法是把特征子空间按通道划分为多个特征子空间,每个特征子空间所得通道在本文中是相同的。因此,我们能够得到两种级别的特征子空间。

图1 MFS模型结构
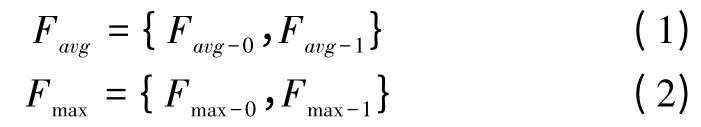
最终我们得到具有两个级别的六个特征子空间,如下所示:
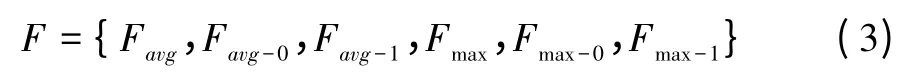
其中{Favg-0,Favg-1,Fmax-0,Fmax-1}构建第一个最终全局特征空间,{Favg,Fmax}构建第二个最终全局特征空间。
在训练阶段,我们为每一个特征子空间分配一个softmax损失函数,然后联合训练这六个任务。注意,对{Favg,Fmax}两个特征子空间的训练是必要的。如果我们抛弃{Favg,Fmax},那么余下模型相当于四个完全一样的小网络组成的模型,小模型所学习的特征相同而没有互补性,更不用说细粒度特征。换句话说,只有在{Favg,Fmax}存在的条件下,余下的四个任务才具有差异性。
2.3 模型结构
基于上述方法,我们为行人重识别提出了一个多特征子空间模型,所提出的多特征子空间模型MFS如图1所示。我们的MFS模型把原始全局特征空间划分为多个特征子空间,然后通过联合训练使得它们能够相互受益,从而得到一个更好的全局特征空间。
接下来,我们将把图1所示的模型详细说明。我们的模型结构主要被划分为四个部分:骨干网络(Backbone Network,BN),平均池化的多子空间模块(Multi-Subspace Block,M-SBK),最大池化的多子空间模块(M-SBK)和最终的全局特征空间模块(Final Global Feature Space Block,F-FBK)。此外,池化多子空间模块可以分为三个子空间模块(Subspace Block,SBK)。
1)骨干网络
本文采用ResNet-50[6]作为骨干网络来进行特征提取。骨干网络摒弃第四阶段开始时的下采样,所以接下来的特征图会变大。ResNet-50的四个阶段完成后,对特征图进行全局平均池化操作,从而得到一个2048维度的特征向量,称这种类型的骨干网络为平均池化骨干网络(Average Pooling Backbone,AP-BN)。我们称由AP-BN所得的特征空间为平均池化空间(Average Pooling Space,APS)。如果把最后的全局平均池化替换为全局最大池化,那么将此类骨干网络称之为最大池化骨干网络(Maximum Pooling Backbone,MP-BN)。同样,我们称由MP-BN所得的特征空间为最大池化空间(Maxmum Pooling Space,MPS)。
2)子空间模块
此模块的主要作为是特征压缩。此模块跟随在骨干网络之后,骨干网络输出的高维特征向量由此模块的(Batch Normalization,BN)和一个全连接层(Fully Connected Layer,FCL)压缩为低维的特征向量。我们称这种压缩组合为子空间模块。
注意子空间模块的输出可以是任意低于2048维度的特征向量。
3)多子空间模块
多个子空间模块的组合即为多子空间模块。本文中,多子空间模块为三个子空间模块组合而成。具体地,由骨干网络所输出的2048维特征向量经过同等划分操作生成两个1024维特征向量,最终得到三个特征向量。每一个特征向量都追加一个子空间模块,所以得到三个子空间模块,这种组合称为多子空间模块。
可以看出,本文主要添加了两个低维度的特征子空间模块。这样做的原因是低维度的特征子空间在高维空间存在的背景下能够学习更多细粒度特征。高纬特征子空间模块的主要作用是充当全局空间,一方面能够学习全局特征,另一方面能够避免两个低维度特征子空间模块失去差异性。
4)全局特征空间模块
全局特征空间模块主要指的是图1中模型的最终输出模块。事实上,本文从图1中得知最终模型有6个特征子空间,为了避免重复,相应组合成了两个最终全局特征空间,但我们只使用其一。
5)平均池化分支和最大池化分支
根据池化方式不同而组合了不同的特征空间。通常,骨干网络的特征向量是全局平均池化所得,但是这种方式得到的特征向量只保留了平均池化的信息而丢失其他信息。因此,本文采用另一种全局最大池化来捕获最大池化信息作为补充,故最终得到了两种池化分支。平均池化分支(Average Pooling Branch,APB)由平均池化骨干网络和平均池化多特征子空间模块组合而成。相应地,最大池化分支(Maximum Pooling Branch,MPB)由最大池化骨干网络和最大池化多特征子空间模块组成。
6)基础网络
选择平均池化分支并只保留2048维特征子空间就组合成了基础网络。通过使用随机擦除、热启动、包括翻转和剪切的数据增强方法,我们的基础网络模型在Marknet-1501数据集上达到了77.95%的Map和91.42的Rank-1。
7)MFS模型结构
MFS模型如图1所示。由平均池化分支和最大池化分支组成,两个分支共享低层网络。通过训练网络,本文得到了6个特征子空间。如图1所示组成了两个最终的全局特征空间,由于第一个和第二个高度重合,所以只使用第一个全局特征空间进行下一步度量计算。
8)损失函数
尽管在度量学习中存在各种各样的损失函数,但是为了更好地探索、更加广泛使用softmax损失函数,我们只采用softmax损失函数。
正如网络结构中所描述的,我们的MFS模型有两个分支,每个分支包含三个损失函数,所以我们最终的模型共有6个softmax损失函数。单个softmax损失函数的公式为

其中,fi是第i个特征,Wk对应第k类的权重向量,C代表训练数据集中有C个类别,N代表训练一个批量图像有N张。我们最终的损失函数如下
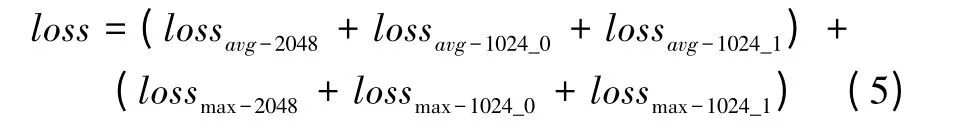
其中,avg代表平均池化,2048和1024分别代表2048维向量和1024维向量。
3 实验
本文使用Resnet-50作为骨干网络,所以最终得到的特征图有2048个通道,把这2048通道特征图当作原始的全局特征空间。对于此特征空间的压缩,通常使用全局平均池化来减少特征空间的维度,但是这样只能获得平均池化带来的信息。本文中不仅仅使用全局平均池化得到平均池化的信息,也使用全局最大池化得到最大池化带来的信息。引入最大池化特征子空间的目的有两个,一个是它能给平均池化特征子空间带来增益,另一个是它能为最终的全局特征空间带来新的信息,从而使我们能够充分利用原始的全局特征空间。此外,我们能继续划分上一步所得的两个池化的特征子空间,即把池化的特征子空间划分为两个维度相同的部分,所以可以再多得四个特征子空间。最终,对于共有的六个特征子空间,分别为其添加softmax损失函数,并联合训练。
3.1 数据集和实验设置
本文测试了两个广泛使用的行人重识别数据集,一个为Market-1501[22],另一个为DukeMTMC-reID[23]。生成训练集和测试集的策略和我们最近的一些工作[17-18]一致。
在最近的工作中,输入图像的分辨率一般为384×128或者为286×128。本文采用286×128的分辨率。
3.2 评估度量
我们的实验在评估阶段只进行了单查询评估,并且没有使用re-ranking[24]来提升模型性能。对于评价指标,本文使用了常用的Rank-1指标和mAP(mean Average Precision)指标。
测试阶段,选择第一个最终全局特征进行度量计算。
3.3 数据增强
为了测试所提出的改进方法是否对高性能的基础模型有益,我们对基础模型增加了一些trick来增强模型,这些trick有热启动、随机擦除、设置第四层的下采样stride为1来扩张特征图,水平翻转和随机裁剪。通过使用这些trick和数据增强方法,我们的基础网络模型在Rank-1达到了91.42%,在mAP达到了77.95%。
3.4 优化设置
在我们的模型中,骨干网络的权重来自于基于ImageNet.[25]的预训练网络权重,初始学习率设置为0.01,且每40个轮回下降10倍。然而,所有特征空间模块和分类器的学习率在每个轮回中比骨干网络高10倍。我们在前5个轮回中使用了热启动。模型共训练100个轮回。优化方法是批量随机梯度下降(Mini-Batch Gradient Descent),批量为16。
3.5 MFS模型与其他模型方法相比
对我们的MFS模型和其他模型在market-1501和DukeMTMC-reID数据集上的评价指标进行比较,比较结果如表1中所示。
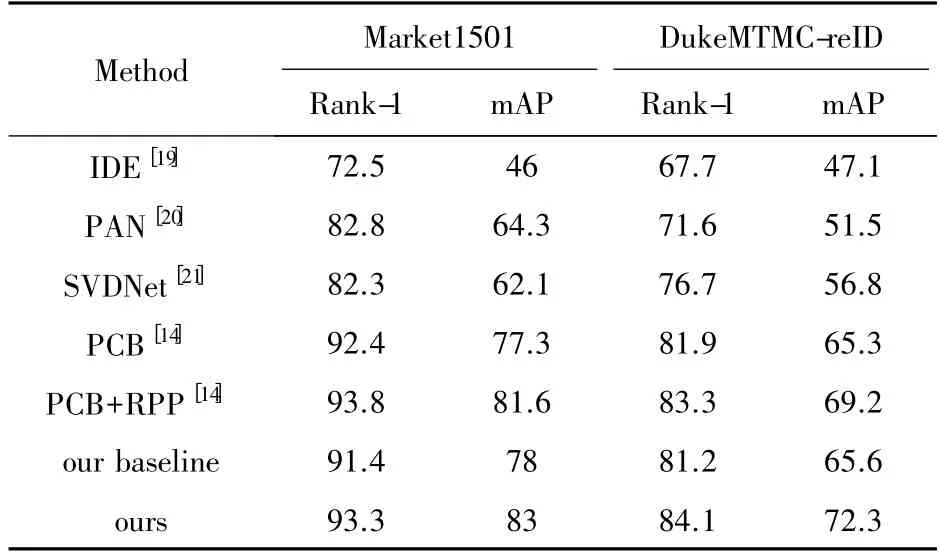
表1 与其他行人重识别方法比较
本文模型在Market-1501数据集上达到了93.3%的Rank-1和82.8%的mAP,在DukeMTMC-reID数据集上达到了84.1%的Rank-1和72.3%的mAP。这表明我们最终的全局特征空间拥有更好的性能。
本文进行了一些实验来展示我们模型的可视化结果,如图2所示。前两行是正确的结果,剩下两行是失败的结果。
这些性能的增益是因为两个原因,一个是基于多个特征子空间的多任务学习改善了每个特征子空间的性能,另一个是最大池化操作采样到了新的特征从而丰富了最终的全局特征空间。在消融实验中,本文将通过逐个消融的方法来验证我们的猜想。
3.6 消融实验
最终的全局特征空间性能得到提升,有两个原因,一个是多任务学习造成的性能增益,另一个是添加的最大池化操作采样到了新的信息。为了验证上述猜想,本文主要进行了如下三个部分实验,第一部分和第二部分主要针对第一个猜想,第三部分设计的实验针对第二个猜想。

图2 MFS模型结果可视化
1)平均池化子空间(基础网络)的增益
大量的实验在Market-1501数据集上进行,从而研究是否基于多特征子空间的多任务学习能改善基础网络模型的性能。正如前文所述,基础网络的特征子空间仅仅为平均池化分支抛弃划分所得的两个特征子空间后剩余的2048维度特征子空间。我们主要探索了多特征子空间模块对其的影响和最大池化子空间(同样抛弃划分所得的特征子空间)模块对其的影响。实验结果如表2所示,+代表添加某一个模块后,基础网络的平均池化空间的性能。MSBK代表多特征子空间模块,MP代表最大池化子空间模块。
我们发现,无论添加哪个模块都能使得基础网络的空间性能得到提升。根据表2的结果所示,如果只添加多特征子空间模块,平均池化子空间的性能在mAP上提升了2.6%和在Rank-1上提升了1.2%,这表明平均池化子空间从其他特征子空间的学习中获得益处。此外,如果只添加了最大池化子空间,那么平均池化子空间在mAP上提升了1.6%,在Rank-1上提升了0.4%。这表明平均池化子空间从最大池化子空间的学习中获得益处。如果同时增加多特征子空间模块和最大池化子空间模块,那么平均池化子空间在mAP上提升了3.8%,在Rank-1上提升了1.3%。

表2 其他子任务对平均池化子空间的影响
2)最大池化子空间的增益
既然平均池化所采样的信息和最大池化所采样的信息是不同的,那么有必要探究最大池化子空间的情况。最大池化子空间的性能情况如表3所示。同样地,+代表在最大池化子空间上添加模块,MSBK代表多特征子空间模块,AP代表平均池化分支(剔除了划分所得的特征子空间),MPS代表最大池化特征子空间。
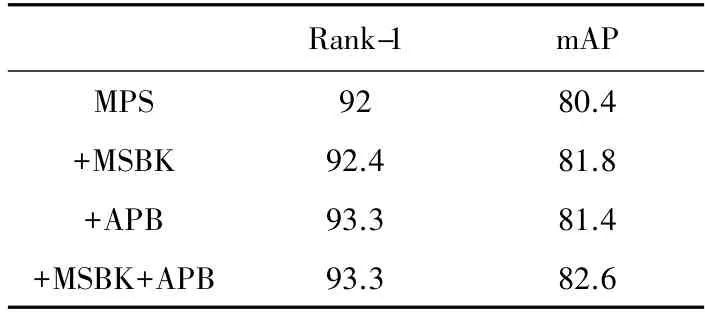
表3 其他子任务对最大池化子空间的影响
在MSBK的帮助下,最大池化子空间在mAP上增加了1.4%并在Rank-1上增加了0.4%。在AP的帮助下,最大池化子空间在mAP和Rank-1上分别增加了1.0%和1.3%。最终同时增加两个模块,最大池化子空间的mAP和Rank-1分别增加了2.2%和1.3%。
综上两个部分,多特征子空间能相互学习确实是成立的,第一个实验猜想得到了验证。
3)最大池化空间带来的新特征
最后,我们主要关注最大池化空间所带来的新信息。为了消除多任务学习带来的影响而仅仅研究采样新信息的增益,我们直接训练一个只有平均池化子空间和最大池化子空间的模型。首先,计算所得的平均池化子空间的性能,然后,计算平均池化子空间和最大池化子空间所合并的全局特征空间的性能,它们的差就代表新信息增益。实验结果如表4所示,可以看到,合并的全局特征空间比受多任务影响的平均池化子空间在mAP和Rank-1上分别增加了1.9%和1.3%。这表明第二个丰富全局特征空间的猜想是正确的,最大池化操作确实丰富了全局特征空间,增添了新信息。
4)多种池化比较
在全局池化中,有多种池化方法,其中最常见的有全局随机池化(Stochastic pool)、全局LP范数池化(L2_norm pool)、全局softmax池化(Softmax pool)、全局混合池化(Mix pool)、全局平均池化(Average pool)和全局最大池化(Max pool)。其中,本模型把全局平均池化作为基本池化,其他池化作为开拓子空间之用。为了选择较好的池化来开拓子空间,进行了大量实验对常见池化进行了比较,比较结果如表4所示,可以发现不同池化有不同效果,但是差别不大。随机池化效果最低,L2范数池化效果最好。鉴于最大池化是常用的池化,所以把全局最大池化加入了模型MFS中。

表4 多种全局池化方法对比
4 结束语
本文为行人重识别提出了一个新的基于多特征子空间的多任务学习模型。这个模型把原始的全局特征空间划分为多个特征子空间,利用多任务学习的思想同时训练多个子空间。实验结果表明,多特征子空间学习过程中相互受益,并且所拼接得到的最终全局特征空间获得了新信息,因此使得模型更加鲁棒。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
软件导刊(2022年3期)2022-03-25 04:45:04
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
计算机技术与发展(2019年1期)2019-01-21 00:56:38
金桥(2018年4期)2018-09-26 02:24:54
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
