
基于深度学习的红外舰船目标识别
2020-06-05 06:28吴钟建金代中周国家
红外技术 2020年5期
杨 涛,戴 军,吴钟建,金代中,周国家
基于深度学习的红外舰船目标识别
杨 涛,戴 军,吴钟建,金代中,周国家
(西南技术物理研究所,四川 成都 610041)
本文采用深度学习技术中的YOLOv3(You Only Look Once Version 3)目标识别算法对红外成像仪从海面采集的红外图像中舰船进行识别。红外成像仪采集图像的频率高达50帧/s,为了能减少网络计算时间,本文借鉴YOLOv3的一些思想,采用全卷积结构和LeakReLU激活函数重新设计一个轻量化的基础网络,以此加快检测速度。输出层根据采集回来的红外图像的特点采用Softmax算法回归,在提高检测速度的同时,也兼顾了检测精度。
红外图像;目标识别;深度学习;YOLOv3
0 引言
近年来我国军事实力取得了巨大的进步,尤其是从辽宁舰成功服役后,我国的海军力量上了一个新的台阶,在现在的海上战争中,要有效地削弱敌方海军的战斗力,精确识别对方舰船并采用精确制导技术摧毁对方的舰船是现代战争常用的方式,但精确识别敌方舰船是一个难点,我们需要高效的目标识别算法才能准确地锁定对方的舰船。不仅如此,我国海岸线长达18000多公里,不仅是防止敌人入侵的重点地带,也是偷渡、走私、贩毒等违法犯罪的高发场所,要在如此之长的海岸线上重点监测海岸附近的海面船只也是一个难点,为了维护海洋资源的可持续发展,我国在1995年制定了“伏休制度”,在此期间,对海面船只的监控也是一件非常棘手的事。为了解决这些问题,我国在一些海岸线上安装了监控摄像头,但早期的摄像头都是可见光成像,只能在白天才能有效工作。随着红外成像技术的发展,红外成像由于其成像距离远、不受白天和夜间限制等优点得到了广泛的应用,但是红外成像只能得到灰度图像,再加上海天线、鱼鳞波、船只等目标航向姿势状态等干扰因素的影响,要在红外图像上高效地识别出舰船是行业一大挑战。
为了解决这个难题,学者们进行了大量的研究,许多优秀的目标识别算法被学者发明并得到了广泛的应用,在这些目标识别算法中,大致流程可分为图像预处理、图像特征提取、使用分类器对特征进行分类。传统的目标识别算法中,特征提取方法基本都是通过手工的方式设置参数提取特征,针对不同的图像检测任务,往往要设计许多不同的特征提取方法,如为了使检测系统适应图像尺度、旋转的变化,尺度不变特征变换(scale-invariant feature transform,SIFT)[1],方向梯度直方图变换(Histogram of oriented gradient, HOG)[2]被学者提出并得以广泛的应用。然而,这些传统的算法往往是在某些特定的场景下能获得很好的效果,但换一种场景可能就表现的很差。
随着近几年来神经网络的飞速发展,深度学习算法在计算机视觉领域得到广泛的应用,特别是目标识别中,大量的算法被提了出来,从R-CNN[3]到Faster-RCNN[4-7]等一系列基于提取候选区域(region of interests)的算法到YOLO[8](you only look once)、SSD[9-10](single shot multibox detector)等端到端的检测算法大量涌现。其中YOLOv3[11-12]以其速度快,准确率高得到了大部分人的青睐,在VOC2012数据集上,YOLOv3在网络输入为416×416,IOU阈值设置为0.5时,检测平均精度值(mean average precision,mAP)达到了57.9,超越了传统的目标识别算法。本次任务是要检测海面上过往的船只,目标成像达到5×10以上分辨率的目标。由于目标像素分辨率较小且经常存在一张图上有多个小目标的情形,YOLOv3对小目标有良好的表现效果且计算开销相对较小。但是YOLOv3计算开销比较大,在嵌入式平台上实现实时检测成本太高,所以本次实验选择了YOLOv3作为基本算法进行改进。重新对YOLOv3提取特征的基础网络进行了设计,通过减少网络层数,减少卷积核的大小,借鉴YOLOv3的思想,采用全卷积和LeakReLu激活函数,增强网络拟合能力并减少计算开销,实现高效的舰船识别。
1 YOLOv3检测的原理
1.1 YOLOv3(You Look Only Once Version3)
YOLOv3把一张图经过一系列卷积或池化计算后,输出3个不同感受野××[+(×5)]的特征图。为输出特征图的长和宽,为预测类别数量,表示网格内是属于哪一类物体的置信度,为每个网格最多预测目标的个数。5表示网格预测每个目标的位置信息和位置的置信度的参数个数:每个目标的信息应该包含目标位置的中心坐标和目标尺寸信息,这里用(,)(、)来表示,这4个参数可以得到一个框,得到目标所在的区域。在YOLOv3中,目标中心位置(,)是相对于当前网格左上角顶点的偏移值,而(、)则是相对于整幅图像宽度和高度,都被归一化到(0,1)区间。得到3个特征图后,再把低分辨率的特征图采样到高分辨率的特征图上,这相当于把图片划分为了×个网格,如果目标物体的中心落入了某个网格,则这个网格就负责检测该物体。较高分辨率的特征图用来检测较小分辨率的目标,较小分辨率的特征图主要负责检测较大分辨率的目标,这大大提高了目标检测的准确率,每个网格还要预测目标位置信息的置信度(Confidence),即预测的框的准确率通过公式(1)计算得到,之后通过图像交并比(intersection-over-union, IOU)和非极大值抑制(non-maximum suppression, NMS)来排除重复的目标。IOU为预测区域与物体真实区域(ground truth)的交集与两者并集之比。Confidence和IOU的计算公式如下:
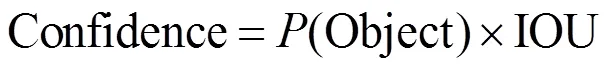
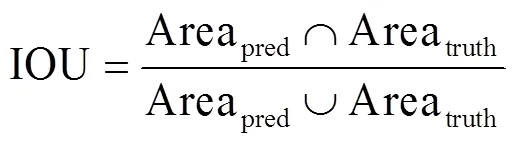
式中:(Object)为预测边界框包含目标物体的概率,如果目标中心落在边界框之内,则置信度为1,相反,如果网格中不存在目标,则(Object)=0;Areatruth为基于训练样本标注的目标真实区域的面积;Areapred为预测的目标物体的边界框的面积。目标位置的置信度表示为预测目标与真实目标的IOU(检测框和真实框的重叠程度)值乘以目标概率,最后再对输出的目标框使用非最大值抑制得到最后的结果,YOLOv3实现了端到端的检测。YOLOv3算法示意图如图1,YOLOv3的网络结构如图2。
YOLOv3的检测速度在TitanX上图像输入分辨率为416×416时检测帧率为35fps,在日常生活应用中,达到了实时性要求,但在普通计算芯片上,远远达不到这个速度。在检测精度方面,以mAP为评价参数,YOLOv3达到了55.3%,已经远远地高于传统的算法。
1.2 改进YOLOv3的红外舰船检测
YOLOv3在目标检测中表现出了非常好的性能,但是,其网络结构比较复杂,卷积层数很深,这样可以使网络拟合能力大大增加,从而可以进行多种目标的检测,原作者是在COCO数据集上设计的基础网络,总共需要检测91种目标,计算开销特别大,特别是在普通CPU上无法实现实时性,但是在本次实验中,原则上只需要检测舰船这一种目标,但是为了减少海天线和鱼鳞波带来的干扰,我们实际检测了3种目标,即舰船、海天线、以及鱼鳞波。由于检测目标种类数变少了,所以网络的拟合能力可以不需要那么强,本文将对YOLOv3网络结构进行重新设计,使得在满足检测精度的同时,减少计算开销。在YOLOv3网络中,作者放弃了池化采样计算,采用全卷积计算,在对特征图下采样时采用了步长为2的卷积计算,变成了全卷积网络。本文拟借鉴原作者的思想,用全卷积网络作为特征提取层,为了减小计算开销,采用小卷积核,在13×13,26×26,52×52三种尺寸的特征图上做预测。对采集回来的数据作分析,红外舰船图像背景相对比较简单,除了海面,天空外,基本只有海天线和鱼鳞波的干扰。在很多情形下,一张图片上存在多个舰船目标的情况,目标大小相差很大而且还存在舰船之间相互遮挡的问题。针对本次数据的特性,在数据集中特意增加了海天线和鱼鳞波类别,增强了该网络在鱼鳞波和海天线干扰下的鲁棒性,减少了虚警率。改进网络包括以下几点:
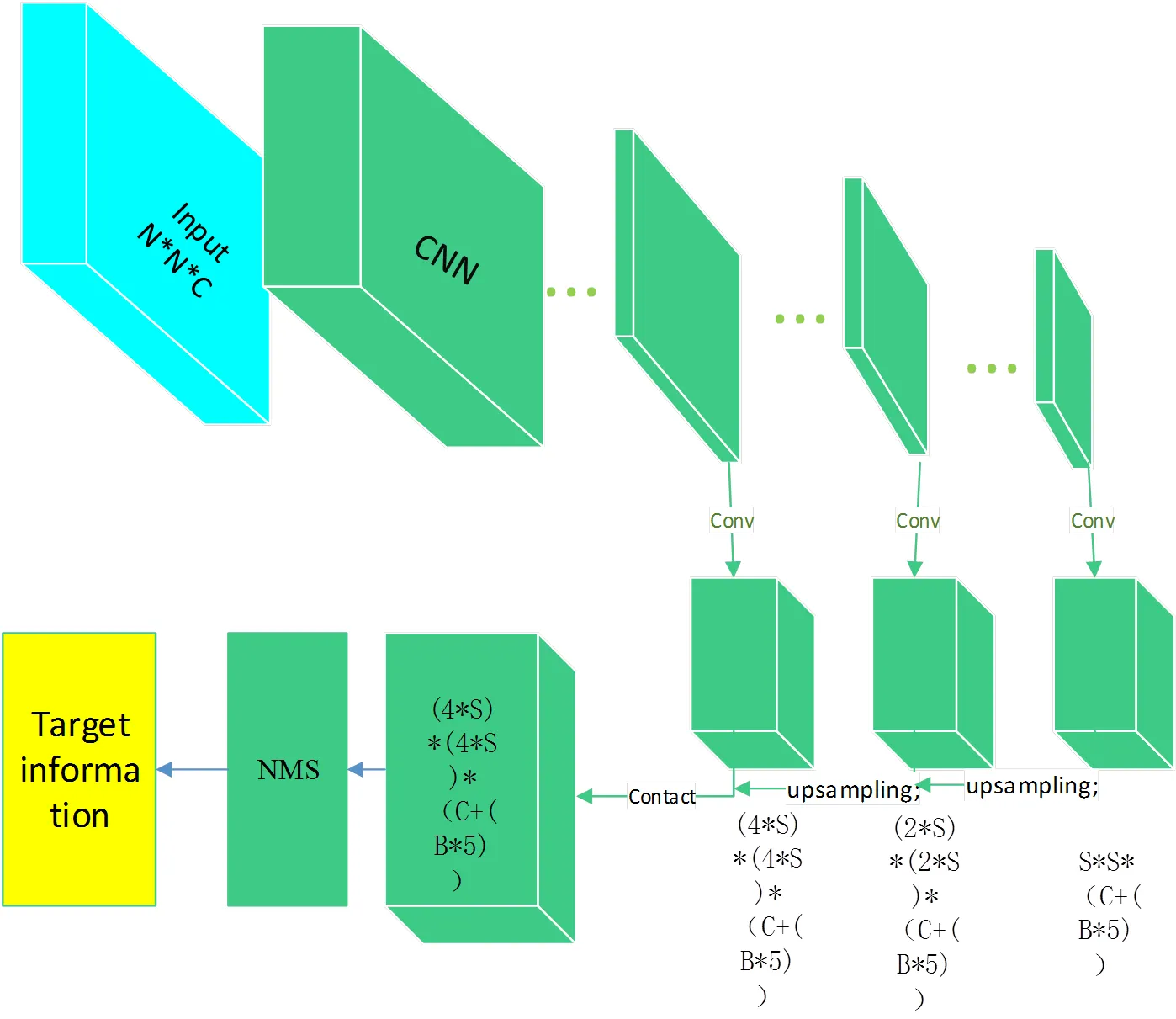
图1 YOLOv3算法示意图
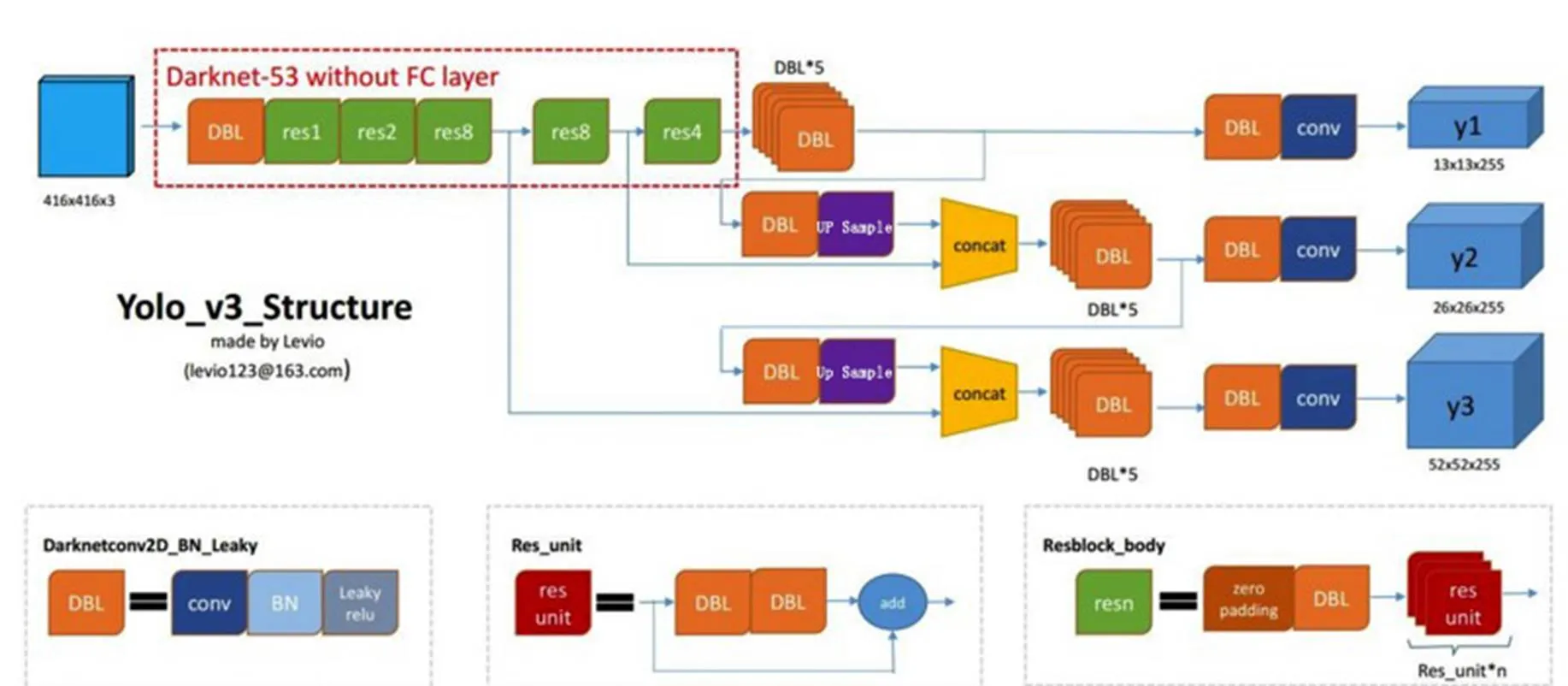
图2 YOLOv3网络结构图(特征提取网络为Darknet-53)
1)全网络激活函数采用LeakReLU激活函数,其数学计算公式如下:
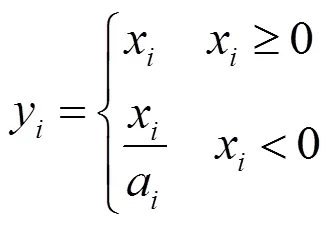
2)采用全卷积网络
本文借鉴了YOLOv3的原理,网络结构采用了全卷积和多尺度的思想,下采样采用控制卷积步长的方法来实现,增加了网络的拟合能力。
3)重新设计一个卷积网络,使其在保证精度的情况下减少计算开销,提高检测速度。整个网络的结构如图3所示:其中Con2_BatNor_LR包含3个连续的算法,卷积(Convolutional)、Batch Normalization,Leak ReLU。
①卷积计算
对图像进行卷积计算,提取图像特征,其中fileter为卷积核的个数,Size为卷积核的尺寸,Stride为卷积计算式的步长,如图3所示,本次采用1×1,2×2,3×3三种不同大小的卷积核,这3种卷积核尺寸都比较小,相比与5×5或7×7的卷积核,可以大大减小计算量。
②Batch Normalization
在训练神经网络时,使用标准化输入可以提高训练的速度。方法是对训练数据集进行归一化的操作,把原来的数据减去其均值后,再除以其方差。这种标准化输入只是对输入进行了处理,中间的隐藏层没有什么变化。在神经网络中,第层隐藏层的输入就是第-1层隐藏层的输出,如果对层的输出进行标准化处理,从原理上来说可以提高l和l参数的训练速度和准确度。这种对各隐藏层的标准化处理就是Batch Normalization。其计算公式如下:z表示层的输出的第个参数,是为了防止分母为零,可设一个非常小的值,如10-10。Batch Normalization计算由以下3步完成:
1)计算输出层输出的均值,如式(4):
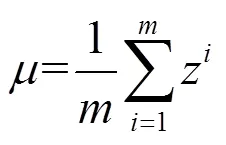
2)计算层输出的方差2¢,如式(5):
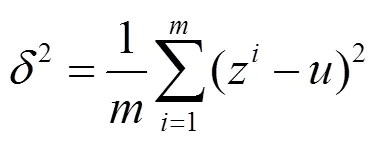
3)归一化输出,如式(6):
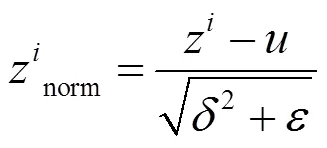
式中:表示层输出参数的个数。
③Leaky Relu函数
在早期的神经网络中,激活函数多用ReLu函数,ReLu函数是将所有的负值都设为零,然而Leaky ReLu函数是给所有负值赋予一个非零斜率。LeakyReLU函数在ReLu的基础上把小于零的数给一个很小的乘积因子,在近两年新提出的网络结构中,LeakyRelu被广泛使用。其计算表达式如下:
式中:a是属于(1,+¥)上的常数。在输出的处理中如图3所示,依然拼接融合了3个不同尺度的特征层做最后的特征输出。
2 检测结果及性能分析
2.1 仿真平台介绍
此仿真平台操作系统为64位的Windows 7,采用了Tensorflow深度学习框架搭建的改进YOLOv3网络,硬件方面CPU为Intel Pentium G2030,GPU采用了GeForce GTX 1050。本次实验中红外舰船的图片数据共有1330张图,其中1200张为训练集,130张为验证集。本次采用的损失函数为YOLOv3原有的损失函数,图4为训练过程中的损失下降过程,图5为验证集损失曲线图,可以看到数据迭代到3000次左右时模型趋于稳定,验证方式为每训练10次验证一次。
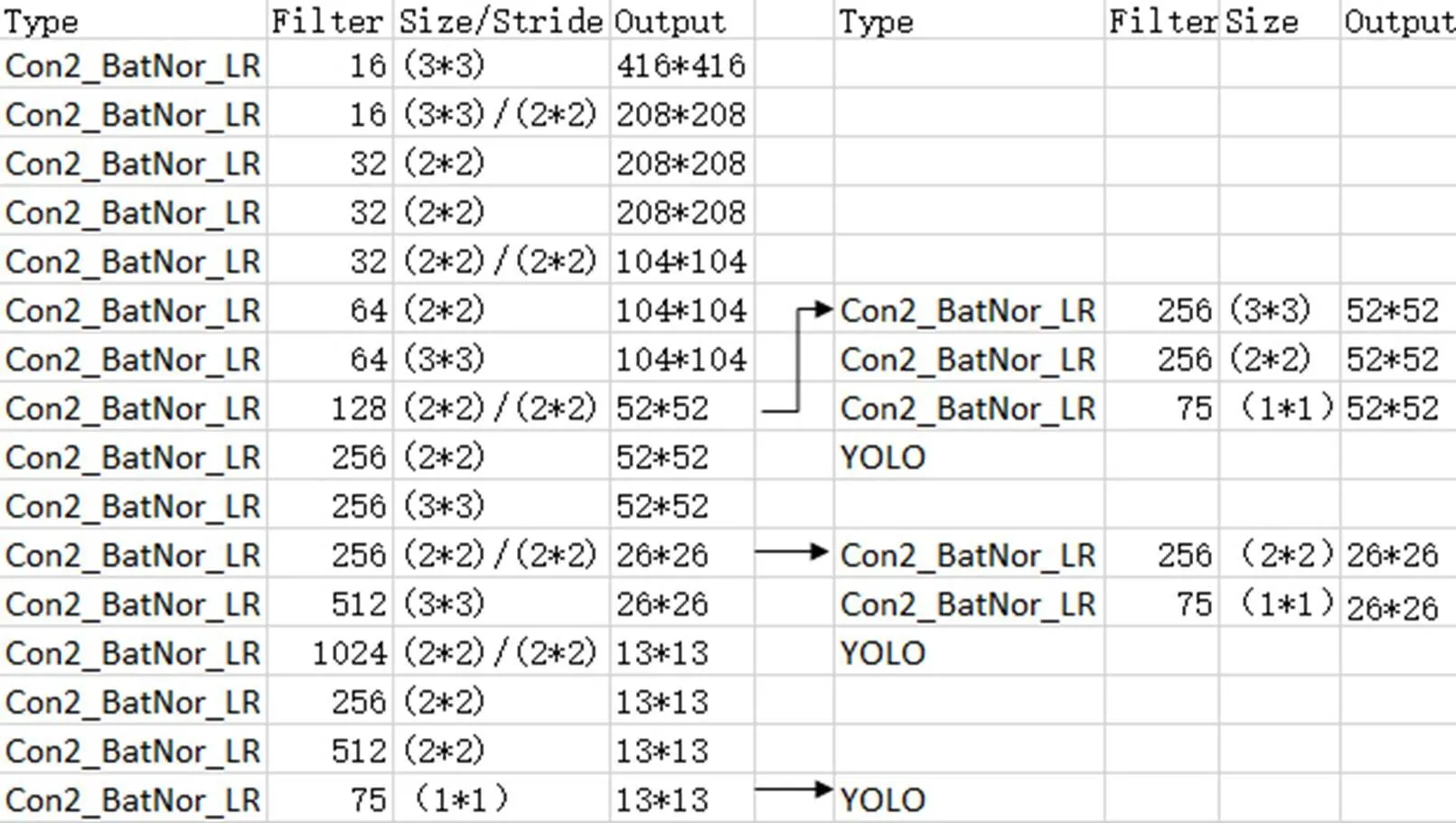
图3 改进YOLOv3的网络结构图
注:Type为计算流程,Con2_BatNor_LR前面有介绍,Size/Stride为卷积核的大小和卷积计算的步长,卷积步长为空是为默认值1,Output是卷积输出的Feature Map的尺寸大小。
Note: Type is the computational process. It has been introduced before. Size/Stride is the kernel size of the convolution and step. Default value is 1 if the convolution step is empty. Output is the Feature Map’s size.
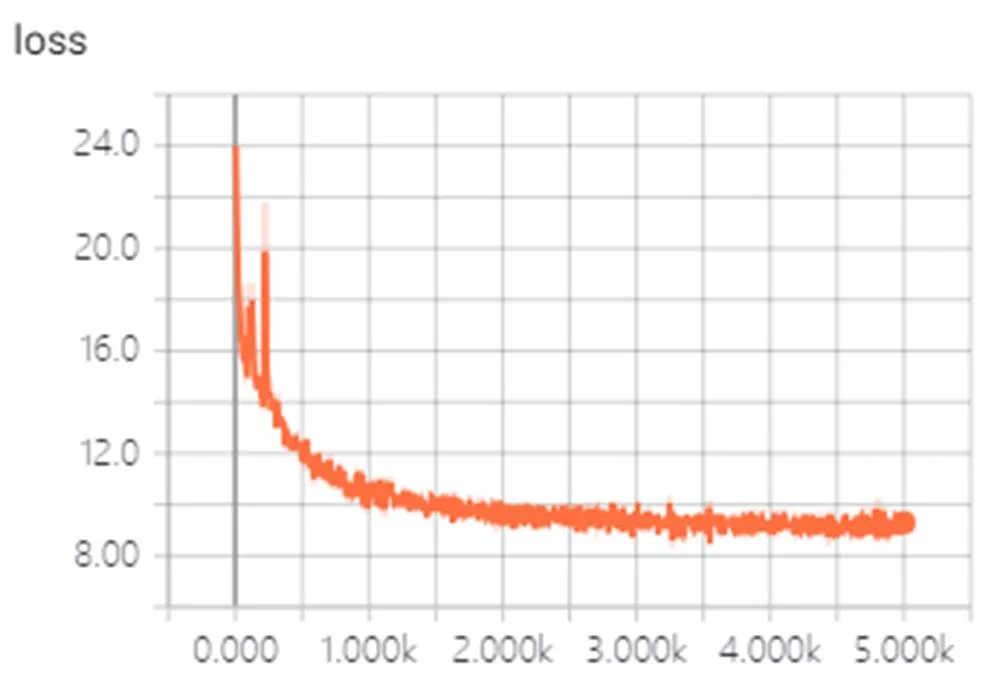
图4 训练损失下降曲线图
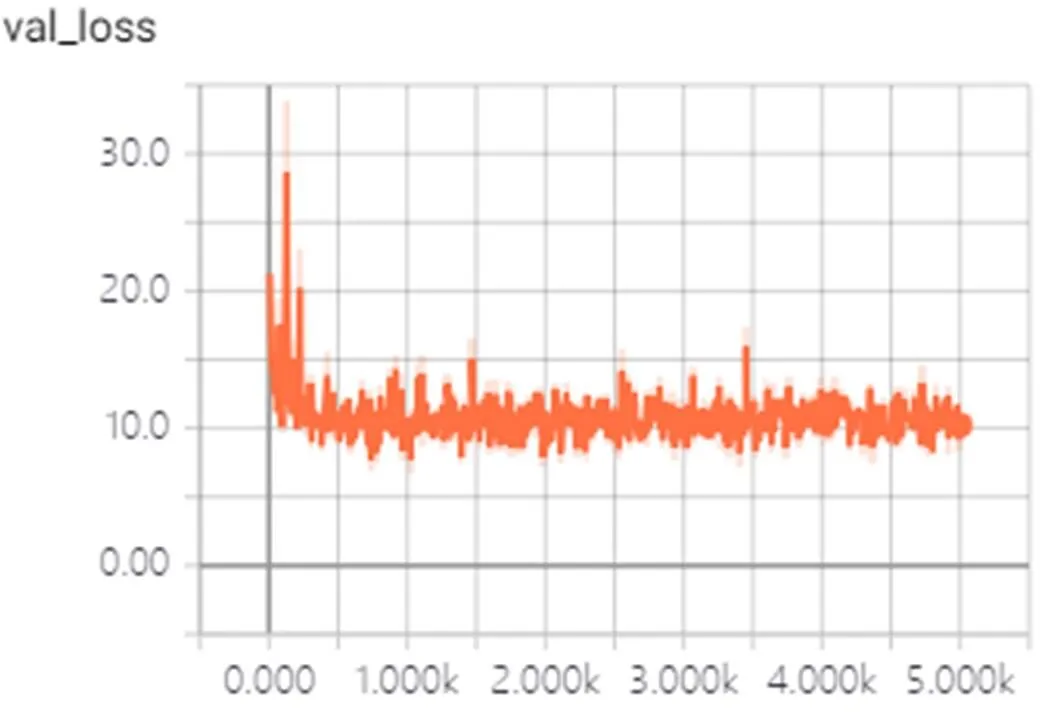
图5 验证集损失下降曲线图
2.2 测试结果
本次测试集总共有130张红外图片,包含248个舰船目标,还有一段视频,用于测试该网络的检测帧率。如图6、图7所示,该网络在该平台上检测视频的速度高达18fps,而YOLOv3只有6fps,整整提高了3倍。该网络对于海杂波遮挡和海天线的干扰也有很强的抗干扰性,图8、图9、图10。对测试图片检测后部分统计结果如表1、表2所示,其中confidence是YOLOv3输出时使用非极大值抑制的阈值,Total nums为模型检测目标的总数,Ground True是测试数据上真实目标总数,True是检测目标数和实际目标在能匹配上的数量,即可以认为检测出的目标是真实目标的数量。

图6 改进YOLOv3视频检测

图7 YOLOv3视频检测

图8 改进YOLOv3(左)和YOLOv3(右)对海杂波的抗干扰

图9 改进YOLOv3(左)和YOLOv3(右)对遮挡情况下的抗干扰

图10 改进YOLOv3(左)和YOLOv3(右)对海天线的抗干扰
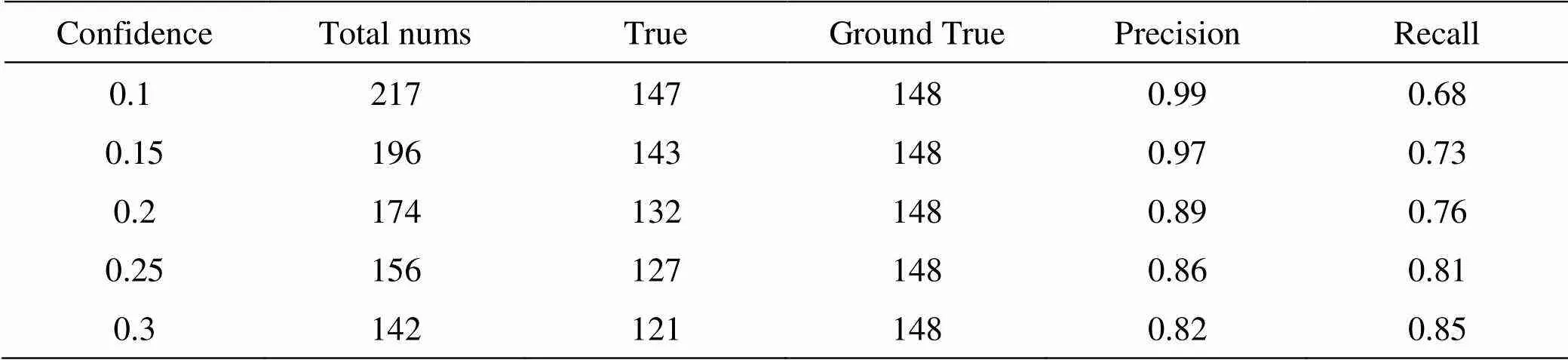
表1 改进YOLOv3在IOU=0.3测试数据
YOLOv3在测试集的统计结果如表3、表4所示。通过表1,表3对比,表2和表4的对比,我们可以看出,改进后的YOLOv3和YOLOv3检测精度的差距很小,为了更为直观地表达,我们使用表1和表3,的数据绘制了准确率(Precision)和召回率(Recall)的-曲线(IOU=0.3),如图11所示。从图中我们可以看出,改进YOLOv3和YOLOv3在检测精度上确实相差很小,大约只有1%的检测精度损失。
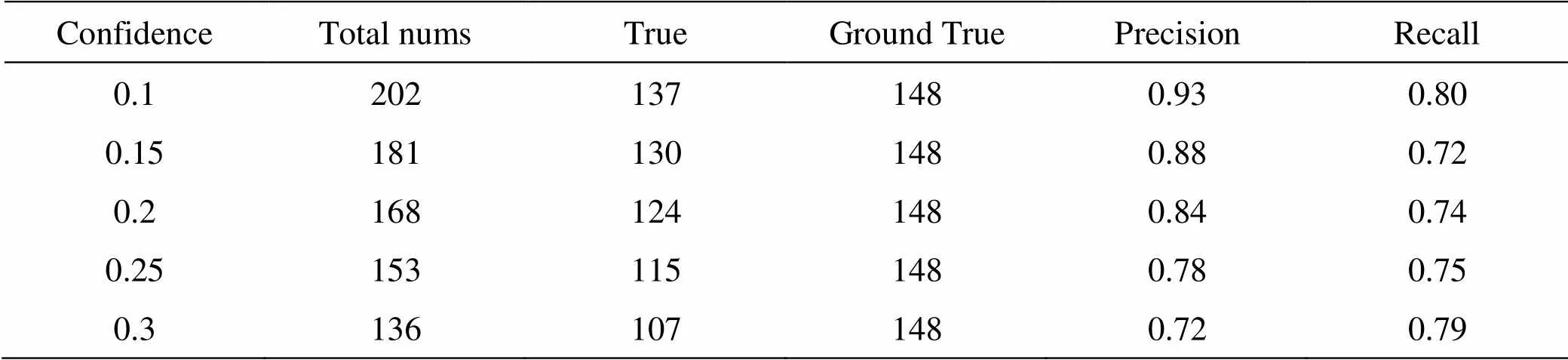
表2 改进YOLOv3在IOU=0.5测试数据
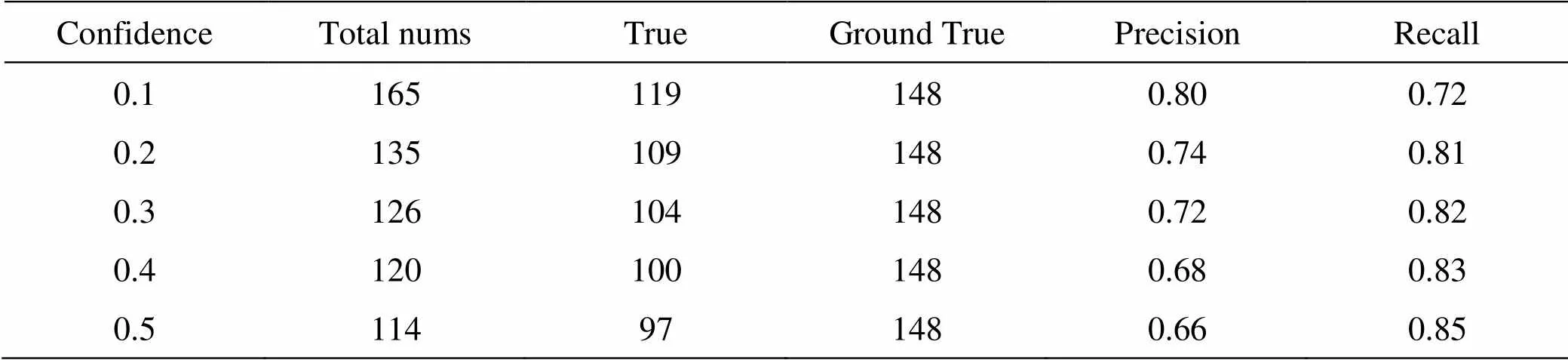
表3 YOLOv3在IOU=0.3测试数据
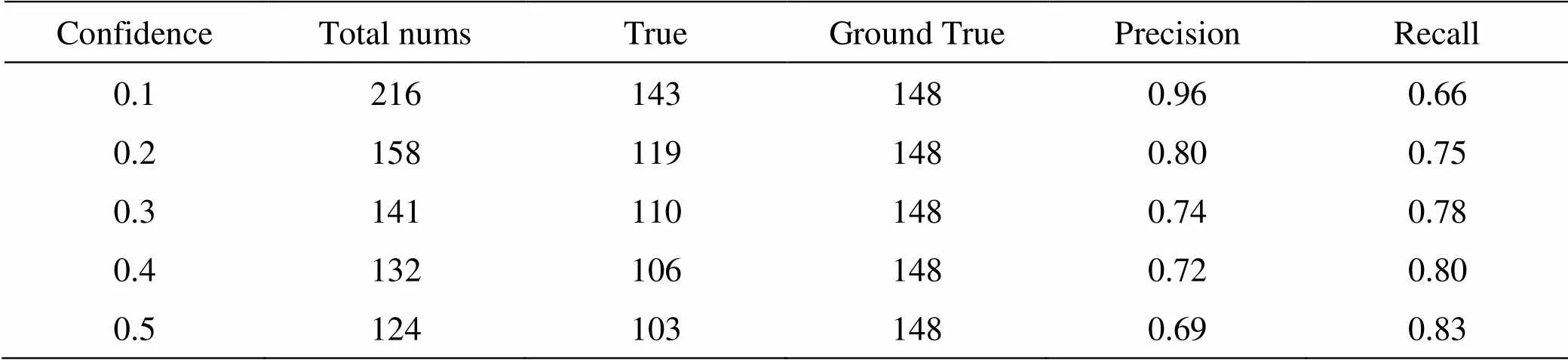
表4 YOLOv3在IOU=0.5测试数据
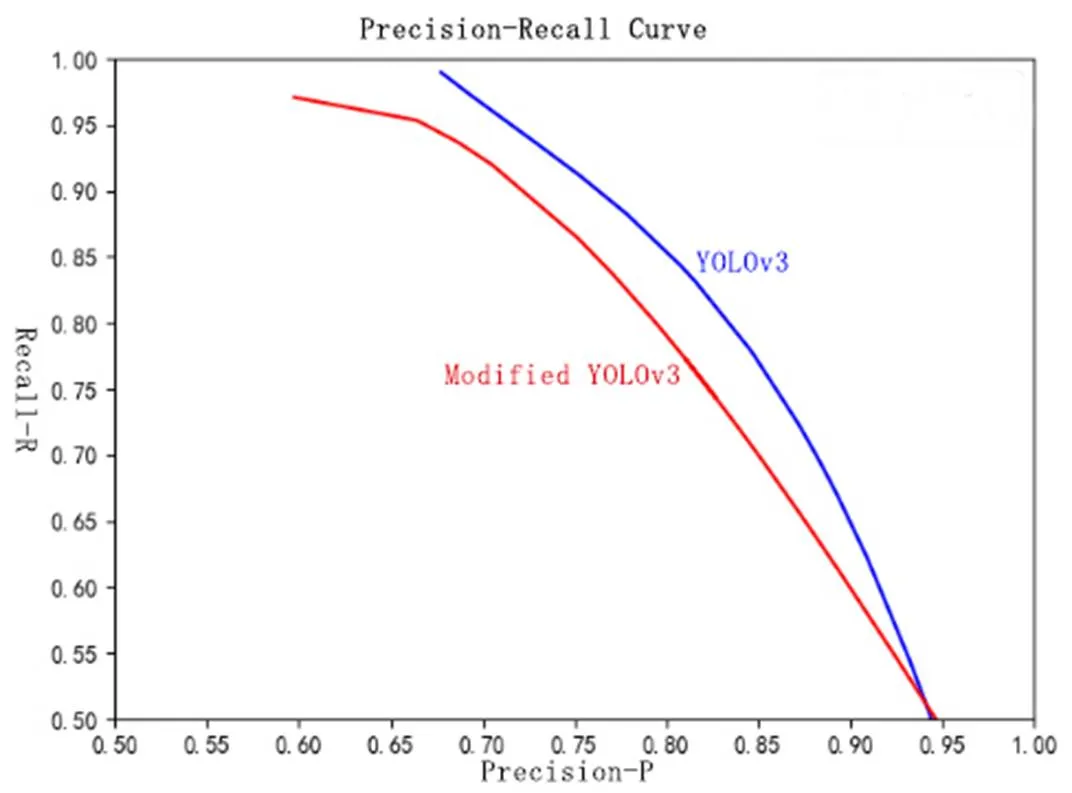
图11 改进YOLOv3和YOLOv3的P-R曲线
3 结论
通过数据可以看出,改进YOLOv3的精度和原YOLOv3相差不大,改进YOLOv3比YOLOv3精度小于1%,相差不大,但是改进YOLOv3在此平台上能实现18fps的速度,而原YOLOv3只有6fps,速度提升了3倍,模型参数从原YOLOv3的235MB减少到了23.5MB,这对于模型移植到嵌入式系统或者一个GPU实现多路视频检测非常有利。从结果来看,改进的YOLOv3在红外舰船目标检测应用中性能有了很大的改善,特别是速度和对硬件资源的要求方面有了很大的提升,对于工程化应用而言,在大大节约成本的同时,又可以提供可靠的实时性保障。此外,由于红外舰船图像数据稀缺,用于本文实验的图像数据总共只有1330张,这对于深度学习而言,实在是太少了,相信如果有足够的数据来训练网络,实验结果还会有所提升。
[1] ZHAN J P, HUANG X J, SHEN Z X, et al. Target tracking method based on mean shift and Kalman filter[J].: Science and Technology, 2010, 24(3):76-80.
[2] 张世博, 李梦佳, 李乐, 等. 基于方向梯度直方图的行人检测与跟踪[J].北京石油化工学院学报, 2013, 21(4): 37-40.
ZHANG Shibo, LI Mengjia, LI Le, et al. Human detection and tracking based on HOG descriptor[J]., 2013, 21(4): 37-40.
[3] 张鹏. 基于卷积神经网络的光学遥感图像中机场目标识别研究[D]. 长沙: 国防科学技术大学, 2016.
ZHANG Peng. Airport Detection in Optical Remote Sensing Images with Convolution Neural Network[D]. Changsha: National University of Defense Technology, 2016.
[4] Girshick R. Fast R-CNN[C]//, 2015: 1440-1448.
[5] REN S, HE K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//s, 2015: 91-99.
[6] 戴陈卡, 李毅. 基于Faster RCNN 以及多部件结合的机场场面静态飞机检测[J]. 计算机应用, 2017, 37(s2): 85-88.
DAI C K, LI Y. Aeroplane detection in static aerodrome based on faster RCNN and multi- part model[J]., 2017, 37(s2): 85-88.
[7] REN S, HE K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]., 2017, 39(6): 1137-1149.
[8] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real- time object detection[C]//, 2015: 779-788.
[9] LIU W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//, Springer International Publishing, 2016: 21-37.
[10] CAO Shuo, ZHAO Dean, LIU Xiaoyang, et al. Real-time robust detector for underwater live crabs based on deep learning[J]., 2020: 172.
[11] Redmon J, Farhadi, A. YOLOv3: an incremental improvement[Z/ OL][2018-04]. https://www.researchgate.net/publication/324387691_ YOLOv3_ An_Incremental_Improvement.
[12] ZHANG Xiang, YANG Wei, TANG Xiaolin, et al. A fast learning method for accurate and robust lane detection using two-stage feature extraction with YOLOv3[J]., 2018, 18(12): 4308.
Target Recognition of Infrared Ship Based on Deep Learning
YANG Tao,DAI Jun,WU Zhongjian,JIN Daizhong,ZHOU Guojia
(,610041,)
In this study, the You Only Look Once Version 3 (YOLOv3) target recognition algorithm in deep learning technology is used to identify the ship in an infrared image collected using an infrared imager from the sea surface. The infrared imager captures images at a frequency of up to 50 frames per second. To reduce network computing time, a few ideas are generated based on YOLOv3; additionally, a full convolution structure and the LeakReLU activation function are used to redesign a lightweight basic network to accelerate detection. The output layer uses the softmax algorithm to regress according to the characteristics of the collected infrared images, which improves the detection speed and accounts for detection accuracy.
infrared image, target recognition, deep learning, YOLOv3
TN957.52,TP18
A
1001-8891(2020)05-0426-08
2019-06-18;
2019-07-22.
杨涛(1992-),男,硕士研究生,主要从事目标检测、深度学习方面的研究。E-mail:304778654@qq.com。
吴钟建(1967-),硕士,副研究员,硕士导师,主要从事目标跟踪、目标检测等方面的研究。E-mail:wjz209@126.com。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
环球时报(2022-05-23)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
金桥(2021年4期)2021-05-21
舰船科学技术(2021年12期)2021-03-29
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
北京航空航天大学学报(2018年1期)2018-04-20
