
基于深度学习的SSD模型尾矿库自动提取*
2020-06-05 12:02:10闫凯沈汀陈正超闫弘轩
中国科学院大学学报 2020年3期
闫凯,沈汀,陈正超†,闫弘轩
(1 中国科学院遥感与数字地球研究所, 北京 100094; 2 中国科学院大学电子电气与通信工程学院, 北京 100094)
尾矿库是由筑坝拦截谷口或围地建成,用于堆放选矿中的尾砂或其他工业废渣的场所[1]。尾矿库的存在有助于尾砂中矿物成分的再回收、水资源循环利用,但其结构决定了它是一个高势能的危险源,具有溃坝的风险,同时尾砂中的重金属在雨水的冲刷下也有污染土壤和地下水系的可能[2]。为保障尾矿库周边人民的生命财产安全,国家应急管理部《遏制尾矿库“头顶库”重特大事故工作方案》中确定了“一库一档”、“一库一策”的工作目标。
对于尾矿库这类分布广泛且不均匀,实地调研困难的地物,已有不少科研工作者借助遥感图像实现尾矿库监测与统计分析。2012年,郝利娜等[3]借助WorldView-2图像对鄂东南尾矿库结构特征、分布特征、光谱特征、纹理特征进行分析,通过人机交互的方式目视解译该区域内572个尾矿库;2013年,中国煤炭地质总局航测遥感局的强建华[4]借助SPOT-5、RAPIDEYE等卫星遥感数据解译陕西省尾库矿库分布情况,并对其存在的环境问题进行分析;2015年,高永志等[5]基于中国遥感14号、24号、5号和高分2号等卫星提供的高分辨率遥感图像解译出山东省内585个尾矿库,并分析这些尾矿库的分布位置及其潜在的危害。上述主要借助目视解译的方法,依据先验知识人工判读,尾矿库提取速度慢,主观性强,难以从大区域内快速获取尾矿库分布信息。
深度学习[6]是一种通过构建网络模型实现计算机模拟人脑对大量数据进行分析、统计去解译分析图像、语音等信息的技术,随着深度学习的蓬勃发展,越来越多的网络模型被应用在自然语言处理[7]、图像识别[8]、目标检测[9]、语音辨识[10]等领域;此外,在遥感领域利用神经网络获取地表发射率[11]、SAR图像的目标识别[12]、遥感图像的色彩校正[13]等研究也在与日俱增,并为尾矿库的自动获取提供了解决思路。
2013年加州大学伯克利分校的Krizhevsky等[14]提出R-CNN算法将PASCAL VOC数据集的检测精度从35.1%提升到53.7%;2014年,He等[15]提出SPP-Net算法,减少了计算的冗余程度;2015年,微软研究院的Girshick[16]借鉴SPP-Net算法,提出一种改进的Fast R-CNN算法;2015年,Redmon等[17]提出YOLO算法,将目标检测问题转换为回归问题;2016年12月北卡大学教堂山分校的Liu等[18]针对YOLO算法定位精度差以及对小目标检测精度差等问题提出SSD算法,将YOLO的回归思想和Faster R-CNN的anchor box机制相结合,在整幅图像上各个位置用多尺度区域的局部特征图边框回归,保持YOLO算法快速特性的同时,也保证了边框定位效果和Faster R-CNN[19]类似,是当前最优秀的目标检测算法之一。对于尾矿库目标而言,通常由坝体、尾砂、废水3部分组成(如图1所示),但不同类型的尾矿库又具有差异,尺寸大小不一,通常为50~3 000 m,分布广泛且不均匀,相对于传统的目标检测算法,基于卷积神经网络的目标检测模型往往是最佳的选择。因此,本文利用SSD模型实现尾矿库的自动提取。
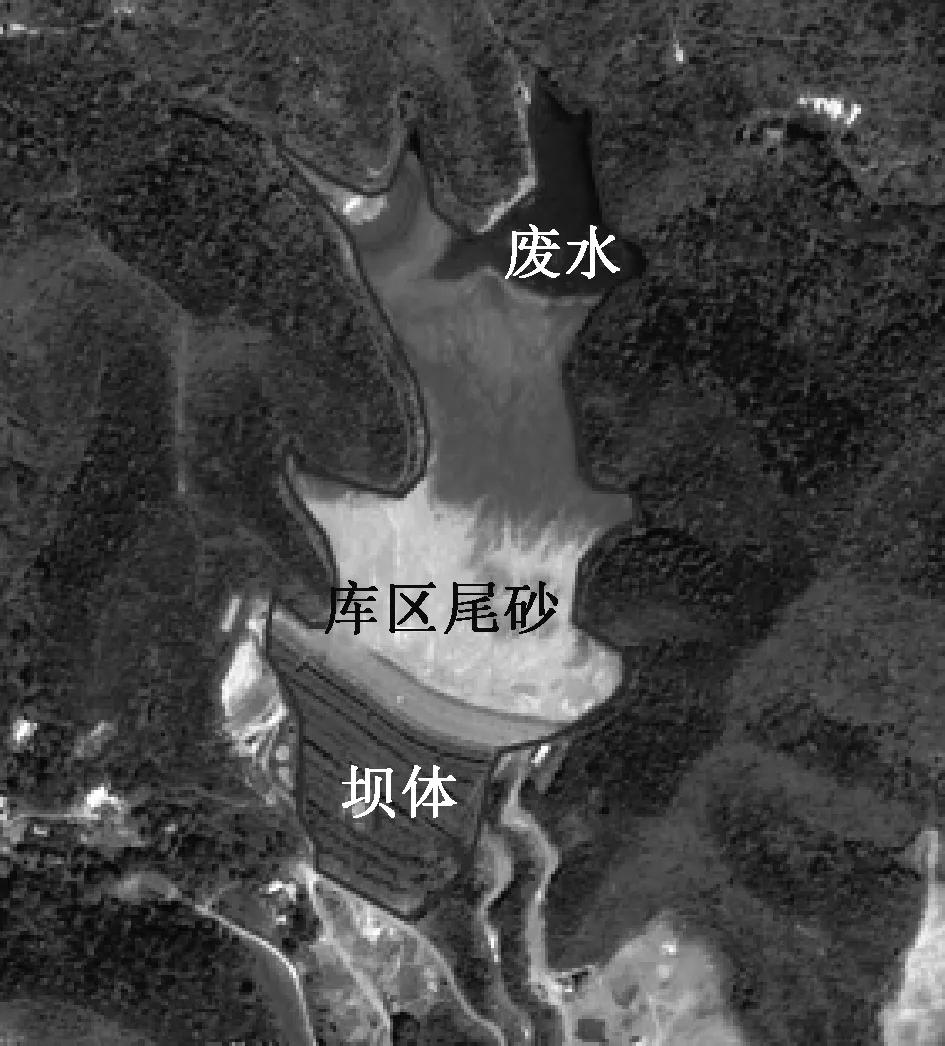
图1 尾矿库结构图Fig.1 Structural chart of tailing pond
为实现尾矿库目标的自动提取,本文主要贡献有:1)首次完成华北地区尾矿库样本库的制作,其中包括制定出尾矿库的训练样本标准,标记出2 000个尾矿库样本,随机挑选1 500个作为训练样本,剩余500个样本作为测试样本验证尾矿库检测的精度;2)首次将深度学习应用于尾矿库检测领域,成功验证了SSD模型提取遥感图像中尾矿库目标的可行性;3)针对尾矿库的特殊性,改进原始SSD模型结构提高尾矿库的检测精度。
1 目标检测算法
本节详细介绍基于卷积神经网络SSD目标检测模型的结构及其理论,分析原始SSD模型相对于尾矿库这类地物目标存在的问题,提出增加CONV12_2卷积层和增加CONV1_2层卷积核步长的改进策略,以此提高SSD模型对尾矿库大型目标地物的检测精度。
1.1 SSD模型简介
Liu等提出的SSD(single shot detector)模型[18]参考YOLO模型的思想,不同于生成候选区域之类的网络模型,将目标检测问题转换为目标坐标位置以及对应类别置信度的回归问题,以VGG-16为基础网络提取图像特征,如图2所示。将VGG-16最后2个全连接层修改为卷积层[20]即CONV6和CONV7,中间还夹杂有池化层[20],并在最后增加4个卷积层构成目标检测网络,分别对应图2中的CONV8_2、CONV9_2、CONV10_2、CONV11_2。所谓卷积是指特定大小的n×n的卷积核在图像的相应位置乘积求和,卷积运算的目的是提取输入图像的不同特征。浅层的卷积提取一些低级的特征如边缘、线条和角等层级,更深层次的卷积能从低级特征中迭代提取更复杂的特征,卷积运算后获得图像称为特征图(feature map)。在不同层次的特征图上预测目标矩形框的位置以及类别信息从而保证不同尺度下目标的检测精度。
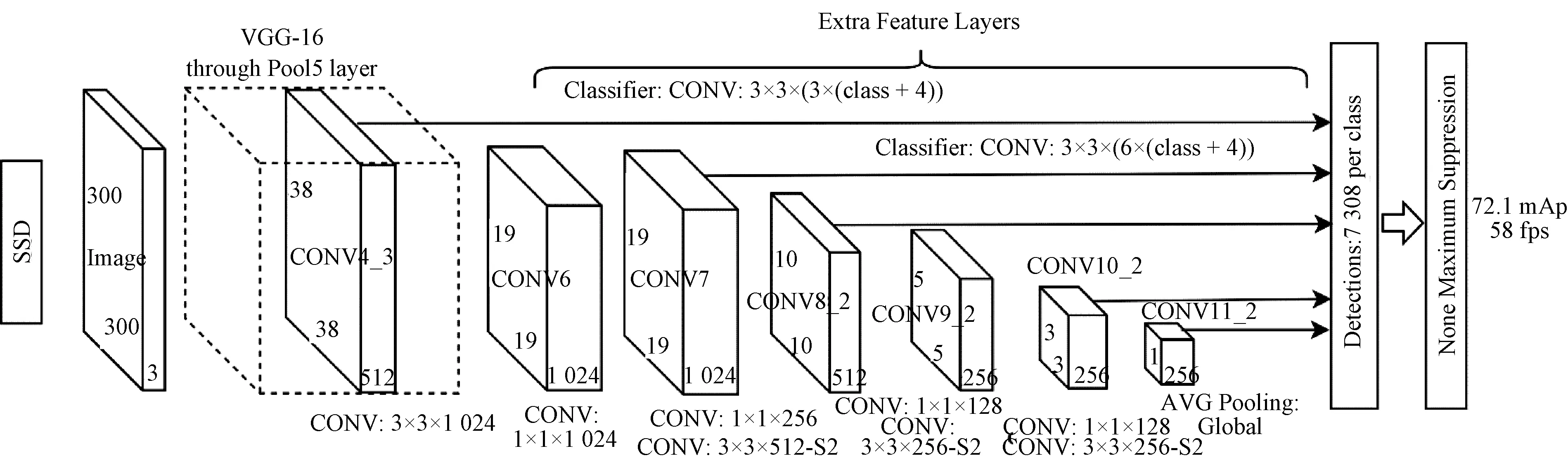
图2 SSD模型结构图Fig.2 Structural chart of SSD model
特征图其本质仍是图像,组成图像的最小单元称为像元,组成特征图的单个像元又记为cell[18]。在SSD模型中参与预测目标位置及类别信息的卷积层包括CONV4_3、CONV7、CONV8_2、CONV10_2、CONV11_2共5层,这些卷积层生成的特征图中每个像元预设不同比例大小的预设框(default box)[18],如图3所示,图3(a)是训练样本图像,左侧框标记猫的真实位置,右侧框标记狗的真实位置,图3(b)、3(c)分别是8×8、4×4,即特征图分辨率为8×8、4×4,特征图中虚线标记的是不同比例的预设框,左侧加粗虚线框为预设框与猫的真值框最佳匹配的,右侧加粗虚线框为预设框与狗的真值框最佳匹配的。设特征图的大小为m×m,每个像元位置处有k个预设框,则该特征图总的预设框个数为m×m×k。SSD模型中不同卷积层特征图对应的预设框大小和宽高比例不同,参与检测目标位置和类别的特征图共m个,每个特征图对应的预设框大小计算公式如下
(1)
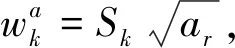
模型训练过程中输入样本图像的真值与特征图中的预设框相匹配,每个预设框与输入样本的真值框匹配时,只要二者的jaccard overlap[21]大于阈值即为匹配成功,匹配成功的预设框作为正类参与迭代训练,未匹配成功的预设框设为负类或背景。关于jaccard overlap的计算公式如下
(2)
式中:A、B分别对应图4中A、B,jaccard overlap为真值框和预设框的交集与并集的比值。
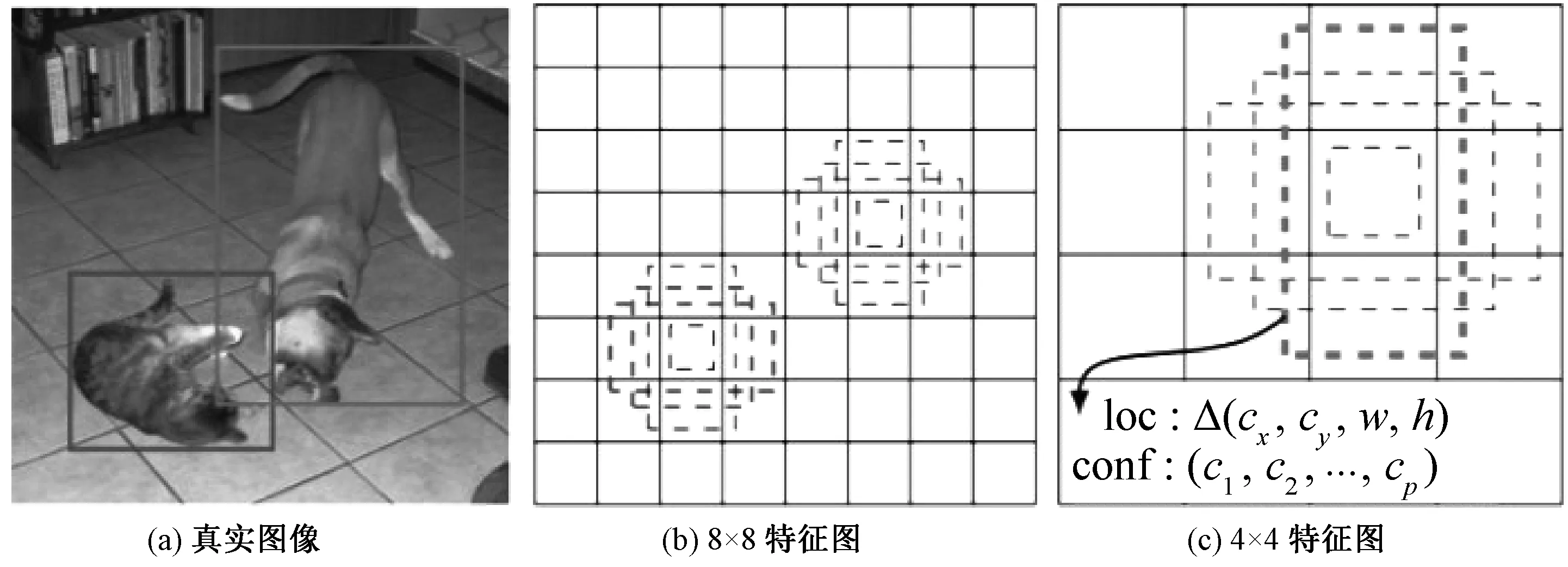
图3 特征图中的预设框示意图Fig.3 The default box in the feature maps

图4 区域A与区域B的匹配演示Fig.4 The matching demonstration between region A and region B
(3)
式中:N是匹配预设方框数量,如果N=0,那么loss=0;权重项α一般设为1用于交叉验证;Lloc(x,c)位置损失是预测框与真值框的Smooth L1损失,包括预设方框中心点(cx,cy)的偏移以及宽高(w,h);Lconf(x,c)置信度损失是所有类别置信度的softmax损失[18]。模型训练过程中通过梯度下降确定损失函数最小的各种参数即得到最终的目标检测模型。
1.2 SSD模型改进
原始的SSD模型中利用CONV4_3、CONV7、CONV8_2、CONV10_2、CONV11_2卷积层从输入图像中提取特征输出相应的特征图,特征图的单个像元对应原始输入图像的像元个数称为感受野,即通过特征图单个像元值描述原始图像中一定范围内的特征,通过特征图与标记样本真值的匹配最终确定目标矩形框位置信息以及所属类别的置信度。当感受野的尺度无法覆盖完整的提取目标时将会导致卷积层提取的目标特征不完整,无法用足够完整的特征描述目标,进而导致目标检测精度降低。
对于本文所检测的尾矿库目标而言,输入图像大小为1 500×1 500个像元,谷歌图像16级产品的空间分辨率为2 m,尾矿库大小尺度为30~3 000 m,即尾矿库可能占用的像元个数为15~1 500;此外,为了使模型预测不同的形状、大小尺寸的图像时拥有更强的鲁棒性,训练样本图像在输入后会随机地将图像切割成包含目标对象的小图像块,并且重采样成1 500×1 500像元大小的图像,这就导致训练样本中有大量的大尺度目标。原始的SSD模型中CONV11_2层对应的感受野大小只有740个像元,即CONV11_2层输出的特征图单个像元对应的原始输入图像大小为740×740,无法完全覆盖所有尺寸的尾矿库目标,导致大型尾矿库提取精度差,进而影响整体目标提取精度。
经过上述分析,本文提出增加额外的卷积层CONV12_2,并修改原始SSD网络中的CONV1_2层卷积步长为2的策略以增大特征图的感受野,如图5所示。SSD模型修改前后对应卷积层特征图的分辨率和感受野的变化表1所示。通过修改模型结构,将原始SSD模型最大感受野740个像元提升到2 499个像元,此外每一层卷积层的特征图感受野都得到一定程度的增大,提高卷积层对大型尾矿库完整特征的捕获能力,以此优化SSD模型对尾矿库这类地物的提取精度。
2 数据准备与精度评价
本章节以数据准备为主,详细分析研究区选择华北地区的重要意义,依据尾矿库尺寸分布特征,将Google图像切割成1 500×1 500像元大小,并介绍样本标记方法、流程以及最终使用样本的分布;此外,还详细介绍用于目标检测精度评价的精确率、召回率以及在不同置信度下的目标监测精度的评价。

在原始SSD模型的基础上增加额外的卷积层,即图中虚线框标记位置。图5 修改后SSD模型结构图Fig.5 Structural chart of the modilied SSD model

VGG+SSDCONV4_3CONV7CONV8_2CONV9_2CONV10_2CONV11_2CONV12_2修改前修改后分辨率187×187103×10352×5226×2613×137×7—感受野92260292356484740—分辨率93×9356×5628×2814×147×74×42×2感受野17951557970796314752499
2.1 研究区域选择
本文选择的研究区域是华北地区,包括北京市、天津市、河北省、山西省和内蒙古自治区共5个省级行政单位。该区域矿产资源丰富,其中内蒙古发现矿产128种,矿产地达786处,稀土矿产更是世界之冠;山西矿产地765处,煤、铝土矿、铁、耐火黏土等保有储量居全国首位;河北是中国矿产资源大省,有40 余种矿产储量位居全国前11 位[22]。全国的尾矿库在地理位置上分布不均匀,主要集中在华北、东北、华中地区,而尾矿库数量最多的应数河北省、山西省。以华北区域尾矿库作为研究对象,包含的尾矿库类型复杂,提取的尾矿库更加具有代表性和普遍性。此外,华北地区属于暖温带大陆性季风气候,降水在年内分配高度集中且多暴雨,这种降水特征增加了尾矿库溃坝的风险性,因此研究华北区域的尾矿库目标格外重要。
2.2 样本标记
本文使用的数据是覆盖华北区域的Google图像16级产品,空间分辨率为2 m,将图像裁剪成1 500×1 500像元大小的图像后导入RS-label软件进行样本标记。RS-Label软件是利用python语言开发的专门用于目标检测样本标记和样本筛选的工具,通过软件中的矩形工具框选出图像中的尾矿库,完成标记后在xml文件路径下自动生成对应的xml文件,xml文件名字与图像的名字相同,后缀为.xml,存储矩形框相对于图像的位置信息。xml文件中,filename为图像文件的名字,size标签中的width为图像宽度,height为图像高度,depth为图像波段数,本文中使用的图像是三波段真彩色合成图像,即depth值为3。已知尾矿库目标的尺寸大小为30~3 000 m,而Google图像16级产品空间分辨率为2 m,因此制作目标检测样本时将图像切割为1 500×1 500大小,即图像的宽度和高度都是1 500个像元。bndbox标签中的xmin、ymin、xmax、ymax分别对应样本标记过程中画的矩形框相对于图像的位置,矩形左上角点的列数、行数,右下角点的列数、行数,利用左上角点和右下角点的坐标即可确定图像中尾矿库的位置信息。标记完成后共标记尾矿库正样本2 000个,从中随机挑选500个样本作为测试集,剩余1 500个样本作为训练集,样本分布如图6所示。
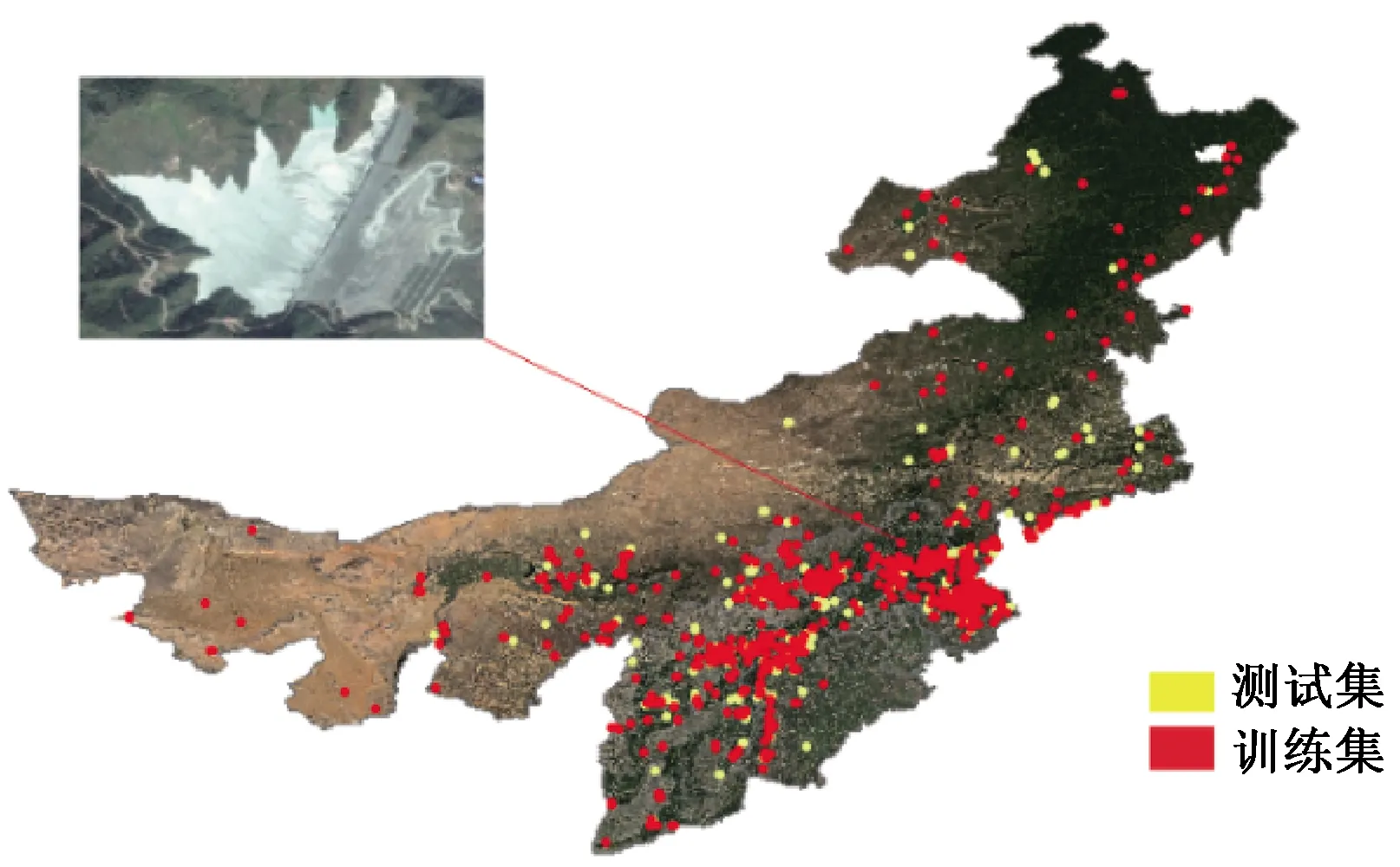
红色标记为训练集分布情况,黄色标记为测试集分布情况。图6 华北地区尾矿库样本Fig.6 The tailing pond samples in North China
2.3 精度评价方法
尾矿库的目标检测本质上是二分类问题,即尾矿库目标作为一类地物,图像中的其余地物目标作为背景一类。对于目标检测精度评价常用的评价因子主要是精确率和召回率,而要计算这两个评价因子首先需要统计的是混淆矩阵。
混淆矩阵[23]中横轴True class是测试集中样本标记的数量统计,纵轴Hypothesized class是模型预测结果的数量统计,如图7所示。p为测试集样本中标记为尾矿库的个数,n为测试集样本中标记为非尾矿库的个数;Y为测试集样本预测为尾矿库的个数,N为测试集样本预测为非尾矿库的个数;TP(true positives)为测试集样本标记为尾矿库并且模型预测结果也为尾矿库的个数;FP(false positives)为测试集样本标记为非尾矿库,但模型预测结果为尾矿库的个数,即误检数;FN(false negatives)为测试集样本标记为尾矿库,但模型预测结果为非尾矿库的个数,即漏检数;TN(true negatives)为测试集样本标记为非尾矿库并且模型预测结果也是非尾矿库的个数。有了上述混淆矩阵的统计信息,就可以很方便地计算尾矿库检测的精确率和召回率。
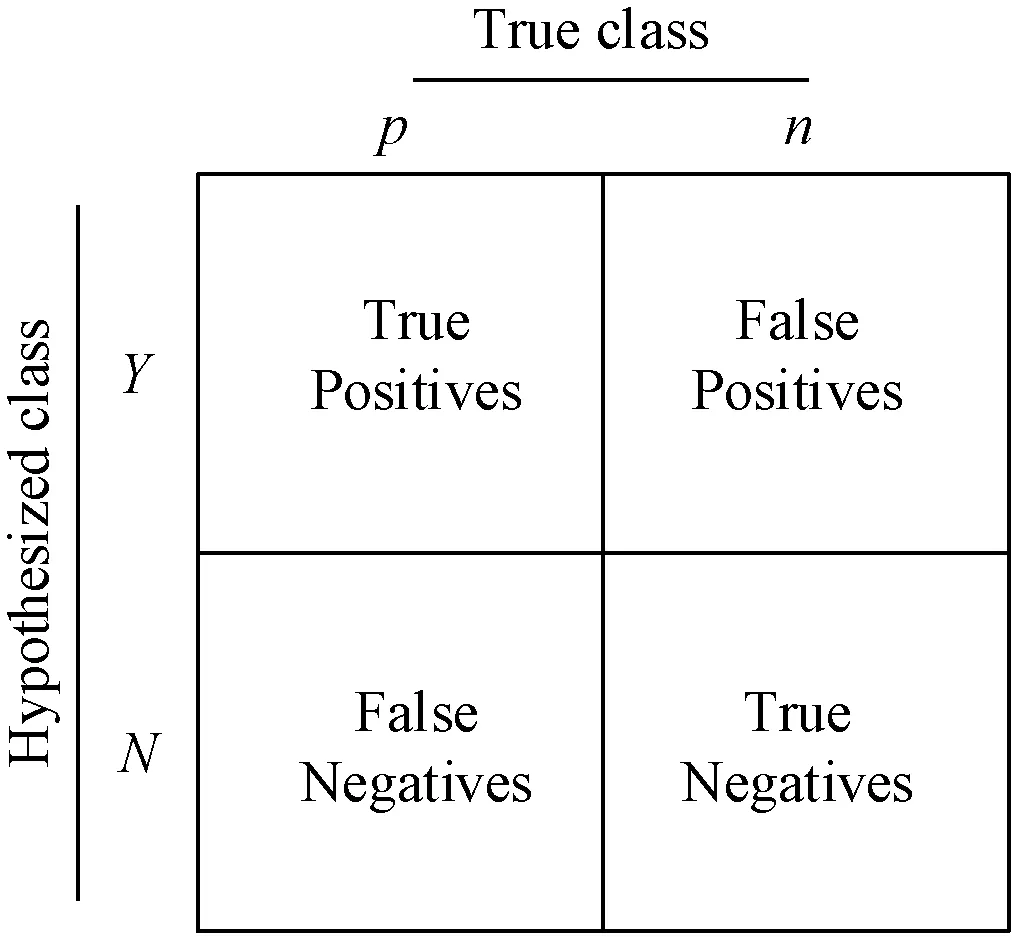
图7 混淆矩阵Fig.7 The confusion matrix
精确率(precision)描述的是识别出来的样本中,TP的个数所占的比重,即样本标记为尾矿库并且被准确预测为尾矿库在所有预测为尾矿库中的比重。计算公式为
(4)
召回率(recall)描述的是所有的预测样本中,TP所占的比重,即预测样本中所有标记为尾矿库的个数中,被准确预测为尾矿库的个数所占的比重。计算公式为
(5)
目标检测结果中除尾矿库目标的位置标记信息外,还包含预测尾矿库的置信度,即模型将目标判定为尾矿库的可能性大小。不同的置信度阈值下,模型检测出尾矿库的个数不同,随着置信度阈值的不断增大,检测出的尾矿库正检的个数TP会减少,误检的个数FP也会减少,漏检的个数FN则会增加,对应的精确率和召回率也会发生相应的变化,在同等置信度阈值下精确率、召回率大的模型则判断为优。为了更加整体和全面地对比评价改进后的模型与原始SSD模型的检测精度,本文统计了阈值为0.1、0.2、0.3、0.4下尾矿库检测的正检个数、误检个数、漏检个数、精确率和召回率。
3 结果与分析
本文共标记2 000个尾矿库样本,从中随机挑选500个作为测试样本,测试集样本中共有842个尾矿库目标。分别利用原始SSD模型和改进后的SSD模型迭代训练100 000次后获得的模型预测测试集中的图像,图像中预测出的尾矿库中按照不同的置信度进行筛选,置信度大于0.1、大于0.2、大于0.3、大于0.4分别对应的正检个数TP,误检个数FP,漏检个数FN以及精确率和召回率如表2所示。
置信度阈值是SSD模型判定目标地物为尾矿库的可能性,是一个概率值。通过表2的统计信息可以看出,随着置信度阈值的增大,修改前后的SSD模型预测出的尾矿库逐渐减少,正检与误检的尾矿库同样在减少,漏检的尾矿库则会随之增加,伴随着尾矿库检测精确率和召回率的变化。通过对比多组不同置信度阈值,发现置信度阈值为0.3时,精确率与召回率有较好的平衡。对比修改后SSD模型检测测试集的统计结果发现,在相同置信度阈值下,修改后的SSD模型正检、误检、漏检个数都优于原始SSD模型的检测结果;当置信度阈值为0.3时,改进后的模型相较于原始模型,检测精确率提高10.0%,召回率提高14.4%。由于本文在原始SSD模型结构的基础上增加额外的卷积层以及修改了CONV1_2层卷积步长,导致模型训练过程中计算量有所增加。
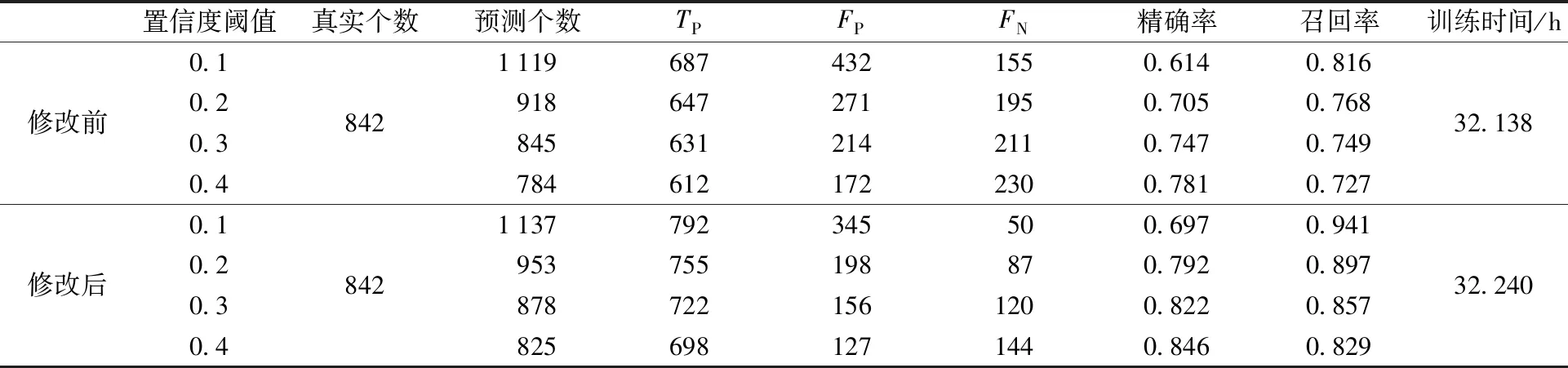
表2 SSD模型修改前后训练和检测结果Table 2 The training and detection results of SSD model before and after modification
本文统计了 SSD模型修改前后的训练所需时间,修改后的模型相对于原始模型训练时间仅增加0.112 h。
除去定量分析,本文还对原始SSD模型预测结果与改进后预测结果以人工解译的方式目视对比分析,图8所示为预测结果。其中图8(a)、8(c)为原始SSD模型的预测结果,而图8(b)、8(d)为修改后模型相对应图像的预测结果,红色矩形框为目标检测模型检测出的尾矿库在图像中的位置。

图8 SSD模型预测测试集结果图Fig.8 SSD model prediction results for test set
通过对比可以发现,对于这种大型的尾矿库目标,原始的SSD模型受最大感受野的限制无法将整个目标捕获到,仅仅捕获到的局部特征导致原始SSD模型会将单个大型的尾矿库识别为多个尾矿库目标;而改进后的模型,因为增加卷积层并修改CONV1_2层的步长,增大了特征图感受野,因此提高了模型对大型尾矿库目标的检测精度。
4 结论
本文首次利用RS-label软件标记华北区域2 000个尾矿库样本,其中1 500个样本作为训练样本参与模型训练,将基于深度学习的目标检测模型应用于遥感图像尾矿库目标检测中,实现尾矿库目标的自动提取。针对原始SSD模型对大型尾矿库目标误检、漏检严重的问题,本文修改原始SSD模型的结构,在网络模型最后增加额外的卷积层,修改CONV1_2卷积层的步长,增大了参与预测的特征图的感受野尺寸,使得特征图单个像元可以从图像更大范围内提取特征,减少了大型尾矿库目标检测时的漏检和误检情况,提高了尾矿库这类大型地物目标的检测精度。本文改进的SSD模型精确率达0.882,召回率达0.857,相比原始SSD模型,精确率提高10.0%,召回率提高14.4%。
基于深度学习的SSD模型自动提取目标时,通过分析目标在图像中所占像元范围改进SSD模型以达到调整特征图感受野的效果,进而提高相应尺度下目标的检测精度。本文获取的尾矿库目标检测模型训练样本是华北区域的Google图像,而不同的研究区域、不同的遥感图像中尾矿库尽管结构差异性很小,但尾砂组成成分、废水含量、色调等差异较为明显,当更换不同的遥感图像或研究区域,用该模型检测图像中的尾矿库目标精确率和召回率会受到影响。为了使该模型在尾矿库检测应用中具有更强、更稳定的泛化能力,将该模型推广到全国范围内、多元遥感图像中尾矿库目标检测将成为后续研究目标。
猜你喜欢
卫星应用(2023年1期)2023-02-21 06:51:16
云南化工(2021年5期)2021-12-21 07:41:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
电子制作(2019年11期)2019-07-04 00:34:38
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
劳动保护(2018年8期)2018-09-12 01:16:22
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
