
单目视觉下基于三维目标检测的车型识别方法综述
2020-06-05 12:18唐心瑶宋焕生张朝阳
小型微型计算机系统 2020年6期
王 伟,唐心瑶,宋焕生,张朝阳
1(长安大学信息工程学院,西安710064)
2(安徽科力信息产业有限责任公司,合肥230088)
1 引 言
车型是指车辆的类型或型号.在无人驾驶领域,通过检测三维车辆目标空间信息及获取准确的车型,可以精确的预判和规划车辆的行为和路径,避免碰撞和违规[1];而在智能交通中,车辆准确的三维信息获取及精细的车型分类,可以更精确的进行车流检测与统计[2]、超速检测与处罚[3,4]、车辆稽查[5,6]等,对于深入理解车辆目标有重大的意义.
目前已有的车型识别方法主要有两类:1)基于二维目标检测的方法.近年来已有大量的文献采用该类方法进行车型识别[7-13],该类方法一般是使用局部特征作为车型识别的依据,如:车牌、车灯、车标或车脸信息,通常采用深度学习方法大量训练这些局部特征,获得深度学习网络训练模型,然后对于输入的车辆局部特征进行网络模型识别继而获得车型识别结果,如图1(a)和图1(b)所示,二维目标检测方法仅能检测识别出车辆目标的存在性、粗略的型号分类等信息,其它可获取的信息非常有限,很难做到精细化描述;2)基于三维目标检测的方法.三维目标检测相比二维类方法可获取的信息更为丰富,如图1(c)所示,相比二维检测,三维目标检测消除了图像成像的透视形变,不受视角变化的影响;再者由于三维目标检测对车辆绘制的三维包络框更加贴合车辆目标,并且能在物理尺度上描述车辆信息,因此可以识别车辆位姿、车辆轮廓的三维尺寸等信息,因此更加适合交通场景下车辆的细粒度描述.由于透视形变及投影造成的信息损失,直接通过单目相机(Monocular camera)获取车辆目标的三维信息有一定的难度,而单目相机一直是视频监控系统中的主流应用,与其他类别的相机如深度相机(RGB-D camera)[14-16]、激光相机(Laser camera)[17,18]相比,由于其视野范围大且处理速度快等优势,在目前的车型识别应用中最为常见.综上所述,单目场景下基于三维目标检测的车型识别是非常重要的研究课题.

图1 车辆目标检测分类方法示意图(图1(c)来自于文献[48])Fig.1 Schematic diagram of object detection methods(fig.1(c)is from literature[48])
当前国内对于单目场景下基于三维目标检测的车型识别问题研究较少,而随着深度学习和SLAM 技术的不断发展,近年来,国外对于基于单幅图像的车辆三维检测识别算法呈上升趋势,目前该类方法一般可分为以下两类:1)车辆粗粒度识别(coarse-grained recognition);2)车辆细粒度识别(finegrained recognition).车辆粗粒度识别,即是对车辆做出精确的三维包络,可获取相应的长宽高等物理尺寸信息,然而在车型识别上仅能把车辆分为小轿车、货车和卡车等粗略的类别;而车辆细粒度识别,则在粗粒度识别的基础上,结合车辆三维特征和神经网络等算法识别出更为精准的信息,包括车辆产地、型号和生产年份等车辆的细节信息.

图2 单目视觉下基于三维检测的车型识别方法流程图Fig.2 Flow chart of vehicle recognition based on 3d object detection in monocular scene
如图2 所示,为当前流行的单目视觉下基于三维车辆检测的粗/细粒度车型识别的流程图,大致可以分为两大类方法:1)基于车辆CAD 三维模型的检测识别方法.车辆三维模型主要有固定模型和可变模型两种,为初始提供的车辆三维信息,将其投影至图像,并比对与二维图像的贴合程度,可以完成车辆的粗粒度识别,然后结合车辆目标的二维平面图像和三维模型上的局部特征,可以进一步实现车辆的细粒度识别,本文后续将会进行分类介绍;2)基于二维目标与相机标定的三维构建方法.二维目标检测主要目的是在图像中确定目标的二维矩形包络框,传统的方法为混合高斯背景建模(GMM)[19],近年来随着深度学习的流行尤其是YOLO 模型的公开[20-23],越来越多的文献采用深度学习进行二维目标检测.对于交通场景下的摄像机标定,近年来涌现出一大批优秀的自动标定算法[24-28],可以利用场景中标识信息,自动获得较高精度的标定结果.利用相机的标定结果,结合二维目标与几何约束信息求取三维目标的包络[29],实现车辆的粗粒度识别,然后对展开平面进行深度学习训练,进一步可以实现车辆的细粒度识别,本文后续将会做详细介绍.如图1(c)第二行所示为车辆的三维目标包络示意图,第三行为车辆CAD 三维模型示意图.
2 单目视觉下三维检测车型识别研究进展
2.1 基于三维检测的车型粗粒度识别研究
所谓车辆CAD 三维模型,是在初始目标坐标系中定义关键特征点的物理坐标,如图3 所示,为使用参数定义的车辆三维模型示意图.
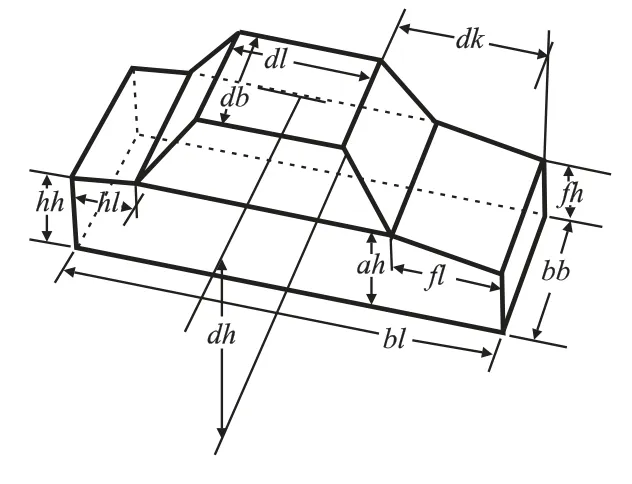
图3 车辆三维模型示意图Fig.3 Schematic diagram of 3d vehicle model
在基于三维目标检测的车辆粗粒度识别方面,1965 年L.Roberts 在文献[30]中第一次提出让机器对物体进行三维感知的概念,在此之后基于三维目标检测的车型识别工作取得了突出的成就.
1)固定模型算法
早期,基于三维目标检测的主流算法都是基于固定模型,主要思路为提取图像中诸如边缘点、边缘线和顶点等二维几何特征来描述图像,并用这些提取出来的特征与固定模型进行匹配,从而完成车型识别.为了提高匹配效率,很多研究人员采用了树搜索、属性图搜索、广义霍夫变换、视角限制[31-34]等方法确定二维与三维之间的关系.然而此类方法对于固定模型要求严苛,效率低下,在实际应用中十分受限.
2)固定模型优化算法
由于固定模型的缺陷,逐渐出现了另外一种思路.给定一个初始的车辆三维模型,将其投影到图像平面比较图像与投影之间的贴合程度,通常使用点到点、点到线、线到线之间的距离来评价贴合程度,这种方法[35-39]将其简化为一个优化问题.车辆的形状近似是个多面体,并且交通场景下有很多先验信息,因此车型识别问题非常适合使用基于模型的方法.三维模型能否准确描述真实车辆的几何信息是评价这个模型是否可靠的重要标准.然而固定模型有它固有的缺陷,由于真实世界中的车辆种类太多,制作一个包含所有类型车辆的模型库是一件非常艰难的任务,而且在庞大数据的模型库中进行双向匹配检索,车型识别的处理时间也会随着模型数量的呈指数级增长.
3)可变模型算法
在固定模型及其优化算法的基础上,为了更好地适应不同类型的车辆,1993 年 D.KOLLER 在文献[40]中第一次提出使用可变模型的方法进行车辆跟踪,通过参数定义的方式定义了3D 通用模型来代表交通场景下不同类型的车辆,并且提出了一种匹配算法,将3D 模型的边缘线段与2D 图像边缘线段进行匹配,采用最大后验概率MAP 的状态更新步骤实现三维目标检测,该模型同时也可以实现5 种车型(轿车、掀背车、货车、小型货车、皮卡)的识别和速度测量.
1995 年 J.Ferryman 在文献[41]中第一次将可变模型真正意义上应用于车型识别,该模型主要用于识别3 种常见车型(轿车、掀背车、旅行轿车),与图3 三维车辆模型相同,该模型也使用参数定义的方式,共定义了29 个参数,通过主成分分析PCA 的方法,选出6 个最强的特征向量,实验结果表明,97%的车辆目标都可使用这6 个最强的特征向量代表,该方法虽然很稳定并且准确率较高,但这些可变模型需要求解的参数数量有29 个之多,导致求解过程效率较低.
为了提高可变模型参数的求解效率,2012 年,Zhaoxiang Zhang 等人在文献[42]中提出一种仅使用12 个模型参数的基于可变模型的车型识别方法,该方法可以识别轿车、掀背车、公交车等常见的8 种车型.该方法首先利用二维车辆投影的HOG 特征,设置初始参数生成初始的三维车辆模型,然后将三维模型投影到图像平面,评价模型的投影与原图像之间的贴合程度,调整参数获得最佳的三维模型,从而完成车辆粗粒度识别.实验结果表明,该方法有效提高了模型参数的求解效率,并且对于车辆的遮挡和截断也有较好的适应能力.
为了适应不同场景中车型识别的需求,及解决道路中的视野相互遮挡而造成的车辆识别失效,2017 年,Eduardo R.Corral-Soto 等人在文献[43]中提出一种在拥挤高速公路下的基于三维可变模型的车型识别方法,该方法还可以统计交通流量和估计车辆的物理尺寸.首先通过混合高斯背景建模(GMM)的方法,提取出车辆目标的前景,对提取出的前景根据蒙特卡洛方法和马尔科夫链方法(MCMC)沿着车道线方向滑动模型来获取最贴合的三维模型,接着采用交并比(intersection over union,IOU)的机制对多车辆目标进行分割,实验结果表明,该机制能够较好地解决车辆之间相互遮挡的问题,在遮挡严重的数据集下,对于车辆识别的准确度高达88%.
2.2 基于三维检测的车型细粒度识别研究
传统的车辆细粒度识别方法大多基于二维图像的局部特征,如车脸、车灯等信息,但是这种方法易受视角限制,对于不同视角及尺度下的局部特征信息需要大量的训练数据集.而三维目标检测方法可以消除视角的影响,如图4 所示,为二维与三维目标检测的对比图,可以看出,三维目标检测可以将目标的位置统一到相同的世界坐标系下,校正了透视形变并加入了物理尺寸等信息,因此基于三维目标检测的车型识别适用于更多的应用空间.
在基于三维目标检测的车辆细粒度识别方面,使用较多的方法是基于三维CAD 模型[44-48]的方法,近年来随着深度学习的不断发展,应用于车辆的细粒度识别,取得了突出的成就.

图4 二维与三维目标检测对比图(图4 来自于文献[50])Fig.4 Comparison of 2d and 3d object detection(fig.4 is from literature[50])
1)三维CAD 模型+局部特征算法
2009 年,J.Prokaj 在文献[49]中第一次将三维 CAD 模型应用于车型细粒度识别,但是这种方法中仍保留了之前二维图像局部特征的思想,首先提取车辆二维图像上的SIFT 特征点,对应于不同视角下的三维CAD 模型上的特征点,然后通过特征点匹配完成车型细粒度识别.虽然这种方法能够克服视角限制,但是对于模型制作和数量要求较高,并且计算量较大,不适合对实时性要求较高的应用场景.
在J.Prokaj 之后,许多研究人员仍然继承了二维图像局部特征的思想,但是对三维 CAD 模型进一步作了改进.Krause 在2013 年的文献[50]中提出了一种综合数据法,使用车辆目标的形状和几何信息作为综合数据,而不是原始的外观特征,通过这些数据训练出一个能够将二维图像和三维模型在几何与视角上进行对齐的DPM 分类检测器,该分类器可以识别如福特、丰田等14 种不同型号的车辆,并且可以进行三维几何信息推断.
Y.-L.Lin 在 2014 年的文献[51]中提出了一种三维CAD 模型的优化算法,通过主成分分析PCA 的方法生成三维可变模型.首先通过DPM 分类器对输入图像中的车辆获取粗略的车辆特征点信息,然后将这些信息作为特征送入预训练的回归模型估计出特征的具体位置,接着将这些特征作为拟合最佳三维模型的依据,使用HOG 特征描述这些特征点,并且使用支持向量机SVM 作为车型细粒度识别的分类器.该方法能够在优化车辆三维模型的同时实现车型的细粒度识别.但是该方法多少都会受到视角的限制,而且还需要一些先验的车辆三维模型信息.
为了克服三维CAD 模型方法中的视角限制问题,进一步提升车型细粒度识别的准确度,Hsiao 在2014 年的文献[52]中提出一种将三维CAD 模型与特征相结合的车型细粒度识别方法,首先提出了一种3D 曲线模型,将检测到的车辆轮廓使用该曲线模型表示,然后使用三维斜面匹配技术,与车辆的三维CAD 模型进行对齐,并且增加了车辆尾灯的特征作为附加条件.实验结果表明,该方法在很大程度上避免了视角限制,并且能够准确快速地适应复杂场景的情况.
2)三维包络盒+机器学习
虽然基于车辆的CAD 模型匹配结合局部特征,在CAD模型库完善及待判别目标车辆型号较少时可以取得较好的识别效果,但随着当前车辆型号越来越繁杂,车辆型号CAD 模型差异越来越细微,因此,一方面很难建立全产线的所有车辆型号,再者随着CAD 模型数量的增加,匹配速度及效率将会变得低下,最后,CAD 模型尺寸相近的车辆容易造成误识别.因此,近年来提出了一类基于三维包络盒及机器学习结合的车辆细粒度识别新方法,该类方法的主要思路是先获取车辆的三维包络盒,然后将包络盒展开获取车辆多个侧面的逆投影面,最后将逆投影面进行机器学习训练,获取车辆细粒度识别的网络模型.本类方法关键是获取精确的车辆三维包络盒,近年来有一批优秀的算法,在单目场景下,利用场景中的几何约束及车辆二维目标约束,利用深度学习算法及SLAM 技术,可以实现自适应的车辆精确三维包络[53-56],由于篇幅限制,这里就不具体展开.
2016 年Dominik Zapletal 等首先在文献[57]中提出单目视觉下将车辆三维包络盒的在逆投影空间中展开,继而进行训练做精细化识别的思路.在无任何先验条件下获取车辆的三维包络,该算法采用文献[58,59]提供的自动标定算法获取相机标定信息,继而利用标定信息及灭点约束对于车辆做三维包络.对于展开的逆投影空间包络面,利用HOG 特征及颜色直方图进行描述,最后利用SVM 算法进行训练识别,获取车辆的细粒度识别结果.由于采用的是传统的特征识别方法,在较复杂的数据集下,该算法的识别准确率并不高,仅能达到60%的准确率.
2018 年布尔诺科技大学的研究人员Jakub Sochor 在文献[60]中基于先前的工作[61]提出一种基于三维目标检测的车辆细粒度识别方法,该方法完全基于自标定,既不受视角的限制,也不需要先验模型信息,只需要一段交通场景的监控视频,通过三个互相正交的消失点即可完成三维目标的检测.将检测到的三维车辆目标作为一个立方体按前面、侧面和顶面分别展开(unpack),并且标准化(normalization)成一张同时包含车辆前面、侧面和顶面的二维平面图像,对该二维平面图像进行标注后,通过深度学习训练网络的方式,学习到车辆细粒度识别的模型,整体过程如图5 所示.由于训练数据集的数量限制,需要进行数据增广以提高识别的准确率,具体的实施方法有:随机交替改变车辆的颜色、给车辆加上随机噪声.实验结果表明,该方法识别的精确度高达83.2%,并且具有较好的实时性.

图5 三维目标检测及展开进行车辆细粒度识别示意图(图5 来自于文献[61])Fig.5 Schematic diagram of 3d object detection and unpack(fig.5 is from literature[61])
表1 总结了单目场景下基于三维目标检测的车型识别的代表性方法并对它们的特点作了描述.

表1 单目场景下基于三维目标检测的车型识别方法总结Table 1 Summary of vehicle recognition methods based on 3d object detection in monocular scene
3 数据集
下面介绍主流应用的车型检测公开数据集,由于本文着重于基于车辆三维检测的车型识别,因此,选取的数据集侧重于包含车辆的3D 信息.
1)KITTI 数据集
KITTI 数据集[62]由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集.该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D 物体检测(object detection)和3D 跟踪(tracking)等计算机视觉技术在车载环境下的性能.KITTI 包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15 辆车和30 个行人,还有各种程度的遮挡与截断.整个数据集由389 对立体图像和光流图,39.2km 视觉测距序列以及超过200k 3D 标注物体的图像组成,以10Hz 的频率采样及同步.
2)BIT-Vehicle 数据集
BIT-Vehicle 数据集[63]是由北京理工大学所收集,其车辆图片来源于道路监控.此数据集包含9580 张车辆图片,共6 类车型:客车、小型客车、小型货车、轿车、城市越野以及卡车(bus,microbus,minivan,sedan,SUV,truck).各类车型图片的数量是 558,883,476,5922,1392 和 822.图片的尺寸分为 2种:1600* 1200 和1600* 1080,它们的取样在不同时间地点(包含白天与夜晚)的2 个摄像头所获取.
3)CompCars 数据集
CompCars 数据集[64]是由美国斯坦福大学计算机科学学院创立的一个用于车型识别的数据集,最大的特点是加入了三维模型信息.它包括了196 类车辆的16185 张车辆图片,这些数据被分为8144 张训练图片和8041 张测试图片,类别信息主要包括品牌、生产年份和制造地.
4)NYC3Dcars 数据集
NYC3Dcars 数据集[65]是由美国康奈尔大学图形与视觉项目组创立的一个用于三维重建、车型识别的数据集,它包括了标注好的超过2k 来自网络的纽约市的照片,图像来自不同的视角和时间段.与以往的数据集不同的是,NYC3Dcars 数据集不仅包含了车辆的位姿和详细的车型信息,还包括了车辆周围环境中道路、建筑物的几何信息.
5)FG3Dcar 数据集
FG3Dcar 数据集[51]是由台湾大学创立的一个用于车辆细粒度识别的数据集,它包括不同视角下的30 多种车辆模型的300 多张图片数据.
6)BOXCARS116K 数据集
表2 单目场景下车型识别数据集及其简介Table 2 Datasets of vehicle recognition in monocular scene
BOXCARS116K 数据集[66]是由捷克布尔诺科技大学创立的一个用于车辆细粒度识别的数据集.包含116k 张标注好的不同视角下的车辆图片数据.
表2 从数据集的内容和特点两个方面对以上介绍的数据集进行了总结.
4 存在的问题及未来发展方向
4.1 存在的问题
目前单目视觉下基于三维目标检测的车型识别技术已取得较大的进展,但是仍存在很多亟待解决和优化的问题.对目前车型识别存在的问题总结如下:1)主流基于三维检测的车型识别算法大都需要CAD 模型库,并且需要预先知道相机的标定信息,因此限制了应用场景.近年来,基于三维包络盒与机器学习的方法为车型细粒度识别提供了一种新思路,摒弃了CAD 模型库,并可利用场景信息自动获取标定信息与车辆三维信息,但识别精度及车型种类的丰富度需要提高;2)大部分基于三维目标检测车型识别容易受到车辆之间互相遮挡及环境光照的影响,部分算法还受到视角限制,因此,需要提高各类算法在复杂环境中的鲁棒性;3)虽然对于三维车辆型号的数据库近年来逐渐增多,种类也丰富起来,但由于车辆型号众多繁杂,目前还没有一个综合的数据库对于三维车辆型号进行总结分类,不利于后续更为精确的车辆细粒度车型识别的算法模型训练.
4.2 未来的发展方向
随着交通视频监控数据量的不断增加,实时对车辆目标进行三维检测,进而实现车型识别的需求迫在眉睫.对车型识别未来的一些发展方向的构想如下:
1)考虑使用更加精简高效的三维模型.使用精简高效的三维模型有利于提高车型识别的效率,且模型本身容易维护.目前基于三维模型的车辆粗粒度识别所需求解的模型参数仍然偏多,并且精确度不高,未来可以通过简化模型、提取更丰富的车辆特征信息来提升识别效率和精度.
2)考虑使用多信息融合的方法.目前车型识别的方法大多停留在某一类方法的应用,如图像处理中的特征提取和自标定等方法,具有一定的局限性,未来可以使用不同的传感器,如雷达、红外等,配合图像处理、三维模型等方法,搭建一套完整的多信息融合识别框架,进一步提高车型识别的精准度,并且在一定程度下应对遮挡及视角限制造成的不利影响.
3)建立一套更加开源的三维车辆型号数据库,建立完善的分类机制,鼓励各个组织或者个人上传通过各种手段采集的三维车辆型号信息,以便拥有跟多的训练数据集,方便研究者设计训练出更加完善的识别网络模型.
5 结束语
车型识别在智能交通领域是目前研究的热点问题,具有广阔的研究前景.本文针对单目场景下基于三维目标检测的车型识别的研究现状进行了介绍,总结了车型识别的两类问题,详细说明了每类问题中使用的代表性算法及它们的优缺点,并且对每类问题中常用的数据集作了简明阐述,最后对单目场景下基于三维目标检测的车型识别目前还存在的问题和未来的发展方向做出了总结及构想.
猜你喜欢
车主之友(2022年4期)2022-08-27
车迷(2022年1期)2022-03-29
环球时报(2022-03-09)2022-03-09
汽车与驾驶维修(汽车版)(2020年5期)2020-07-24
小太阳画报(2018年3期)2018-05-14
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
汽车观察(2016年11期)2017-06-03
科技资讯(2017年7期)2017-05-06
